Recognition: 2 theorem links
· Lean TheoremWhat Do EEG Foundation Models Capture from Human Brain Signals?
Pith reviewed 2026-05-15 06:14 UTC · model grok-4.3
The pith
EEG foundation models recover most of their clinical performance edge from a 63-feature hand-crafted lexicon.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
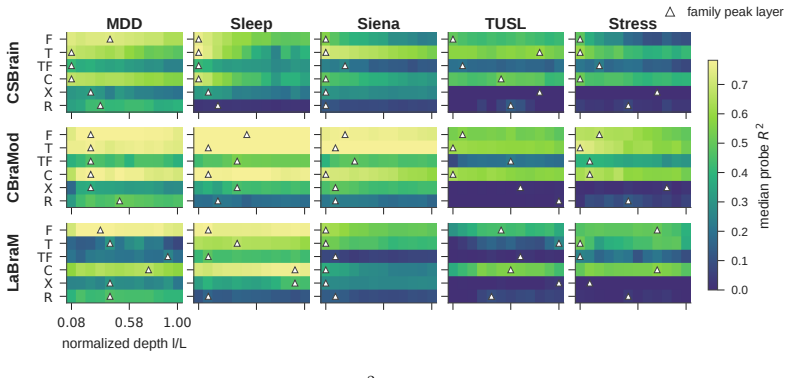
Of 945 (model, task, feature) combinations, 648 are representation-causal and 199 are encoded-only. Fifty features appear as universal candidates with strong causal support across multiple tasks. Frequency-domain features supply the largest causal mass, yet every other family contributes measurable causal signal. When the confirmed causal features are retained and all others erased, they recover 79.3 percent of the foundation models' advantage over the random baseline, with task-wise recovery ranging from approximately 0.99 on MDD to 0.56 on Stress.
What carries the argument
Layer-wise ridge probing combined with LEACE-style cross-covariance subspace erasure applied to a fixed 6-family, 63-feature EEG lexicon.
If this is right
- Frequency-domain features carry the largest causal weight inside the models.
- Fifty features qualify as universal candidates with causal support in at least two tasks across all three architectures.
- Tasks near ceiling performance are almost fully recovered by the existing lexicon.
- Harder tasks such as Stress retain a non-trivial residual, identifying a concrete target for new concept discovery.
- The same audit procedure can be repeated on future foundation models to track how their internal representations evolve.
Where Pith is reading between the lines
- The residual performance on harder tasks suggests that new, currently unlisted EEG features may exist and could be discovered by inspecting what remains after the 63-feature erasure.
- Because the lexicon already recovers most of the advantage, hybrid models that explicitly inject these features could improve both accuracy and clinical interpretability.
- The clean gradient of recovery across tasks offers a natural benchmark for measuring whether newer foundation models close the remaining gap without simply memorizing the same lexicon.
Load-bearing premise
The chosen 63-feature lexicon is complete enough that any information the models actually use must appear inside it.
What would settle it
If an expanded or differently constructed feature set, or an alternative probing method, recovers substantially more than 79.3 percent of the performance gap on the same models and tasks, the claim that the lexicon captures what the models use would be falsified.
Figures



read the original abstract
Clinical electroencephalogram (EEG) analysis rests on a hand-crafted feature catalog refined over decades, \emph{e.g.,} band power, connectivity, complexity, and more. Modern EEG foundation models bypass this catalog, learn directly from raw signals via self-supervised pretraining, and match or outperform feature-engineered baselines on most clinical benchmarks. Whether the two representations align is an open question, which we decompose into three sub-questions: \emph{what does the model learn}, \emph{what does the model use}, and \emph{how much can be explained}. We answer them with layer-wise ridge probing, LEACE-style cross-covariance subspace erasure, and a transparent classifier benchmarked against a random-feature baseline. The audit covers three foundation models (CSBrain, CBraMod, LaBraM), five clinical tasks (MDD, Stress, ISRUC-Sleep, TUSL, Siena), and a 6-family 63-feature lexicon. Of the $945$ (model, task, feature) units, $648$ ($68.6\%$) are representation-causal and $199$ ($21.1\%$) are encoded-only. Across tasks, $50$ features qualify as universal candidates with strong support (all three architectures RC) in two or more tasks. Frequency-domain features dominate, but the other five families each contribute substantial causal mass. Confirmed features recover, on average, $79.3\%$ of the foundation model's advantage over the random baseline, with a clean task gradient (MDD $\approx 0.99$ down to Stress $\approx 0.56$): tasks near ceiling are almost fully recovered by the lexicon, while harder tasks leave a non-trivial residual that pinpoints a concrete target for future concept discovery.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript audits three EEG foundation models (CSBrain, CBraMod, LaBraM) against a fixed 6-family 63-feature lexicon across five clinical tasks (MDD, Stress, ISRUC-Sleep, TUSL, Siena). Using layer-wise ridge probing and LEACE-style cross-covariance erasure, it classifies 945 (model, task, feature) units as representation-causal (68.6%) or encoded-only (21.1%), identifies 50 universal causal candidates, and reports that confirmed features recover on average 79.3% of each model's advantage over a random-feature baseline, with a task gradient from near-complete recovery on MDD (≈0.99) to lower recovery on Stress (≈0.56).
Significance. If the lexicon completeness and erasure fidelity assumptions hold, the work supplies a concrete, quantitative bridge between decades of hand-crafted EEG features and modern self-supervised models, pinpointing both recoverable causal content and residual gaps that can guide targeted concept discovery. The transparent classifier benchmark and task-wise breakdown are particularly useful for clinical EEG interpretability.
major comments (3)
- [Abstract and §4] Abstract and §4 (Results): the headline figures 68.6% representation-causal and 79.3% recovery are stated as point estimates with no error bars, bootstrap intervals, or statistical tests; given the 945 units and the reported task gradient, absence of these quantities prevents assessment of whether the differences (e.g., MDD vs. Stress) are reliable.
- [§3.2] §3.2 (Lexicon and erasure pipeline): the 63-feature catalog is treated as a fixed, exhaustive basis; no ablation study, coverage analysis, or synthetic-data validation is presented to test whether higher-order or cross-feature interactions outside the lexicon are mis-attributed to the residual, which is load-bearing for the claim that the residual on Stress (≈0.56) represents genuinely novel model behavior.
- [§3.3] §3.3 (LEACE-style erasure): the method assumes that linear cross-covariance removal isolates causal use without compensatory shifts in the remaining representation; no sensitivity analysis or controlled simulation is reported, yet any violation would systematically inflate the unexplained residual precisely on the harder tasks where recovery is lowest.
minor comments (3)
- [Figure 3] Figure 3 (task-gradient plot): add error bars or shaded intervals corresponding to the per-task recovery values to match the quantitative claims in the text.
- [§2] Notation: define 'RC' (representation-causal) and 'encoded-only' explicitly on first use in the main text rather than only in the abstract.
- [Table 1] Table 1 (model/task summary): include the exact number of subjects or trials per task to allow readers to gauge statistical power for the reported percentages.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Results): the headline figures 68.6% representation-causal and 79.3% recovery are stated as point estimates with no error bars, bootstrap intervals, or statistical tests; given the 945 units and the reported task gradient, absence of these quantities prevents assessment of whether the differences (e.g., MDD vs. Stress) are reliable.
Authors: We agree that providing uncertainty estimates and statistical tests would improve the assessment of reliability. In the revised version, we will compute bootstrap confidence intervals for the key percentages (68.6% and 79.3%) and task-specific recovery rates. We will also add statistical comparisons (e.g., using bootstrap tests) for the observed task gradient, particularly MDD vs. Stress. These will be incorporated into §4 and referenced in the abstract. revision: yes
-
Referee: [§3.2] §3.2 (Lexicon and erasure pipeline): the 63-feature catalog is treated as a fixed, exhaustive basis; no ablation study, coverage analysis, or synthetic-data validation is presented to test whether higher-order or cross-feature interactions outside the lexicon are mis-attributed to the residual, which is load-bearing for the claim that the residual on Stress (≈0.56) represents genuinely novel model behavior.
Authors: The lexicon is presented as a fixed, established set of clinical features rather than an exhaustive basis; we do not claim it captures all possible information. The residual is discussed as a pointer to potential gaps for future work, not as proof of novel behavior. To address the concern, we will add a paragraph in §3.2 and the discussion section noting the limitations of the lexicon and the possibility of unaccounted interactions. A comprehensive ablation study is beyond the current scope but could be noted as future work. revision: partial
-
Referee: [§3.3] §3.3 (LEACE-style erasure): the method assumes that linear cross-covariance removal isolates causal use without compensatory shifts in the remaining representation; no sensitivity analysis or controlled simulation is reported, yet any violation would systematically inflate the unexplained residual precisely on the harder tasks where recovery is lowest.
Authors: We recognize the importance of validating the assumptions of the erasure method. While the LEACE approach is grounded in prior work, we will include a sensitivity analysis in the revised manuscript by testing different erasure parameters and reporting robustness on a subset of the tasks. Additionally, we will add a small-scale simulation study using synthetic representations to demonstrate the method's behavior under known conditions. revision: yes
Circularity Check
No significant circularity; empirical probing and erasure are independent of fitted targets
full rationale
The paper's core claims rest on layer-wise ridge probing, LEACE-style cross-covariance erasure, and classification against a random-feature baseline applied to three external foundation models (CSBrain, CBraMod, LaBraM) using a fixed external 6-family 63-feature lexicon. The 79.3% recovery statistic, RC/encoded-only counts, and task gradients are direct empirical outputs of these measurements; no equation or result is defined in terms of itself, no fitted parameter is relabeled as a prediction, and no load-bearing premise reduces to a self-citation chain. The derivation is therefore self-contained against the stated benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We answer them with layer-wise ridge probing, LEACE-style cross-covariance subspace erasure, and a transparent classifier benchmarked against a random-feature baseline... 6-family 63-feature lexicon
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Confirmed features recover, on average, 79.3% of the foundation model's advantage over the random baseline
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Electroencephalography and Clinical Neurophysiology , year =
Hjorth, Bo , title =. Electroencephalography and Clinical Neurophysiology , year =
- [2]
-
[3]
and Nolte, Guido and Daffertshofer, Andreas , title =
Stam, Cornelis J. and Nolte, Guido and Daffertshofer, Andreas , title =. Human Brain Mapping , year =
-
[4]
Physical Review Letters , year =
Bandt, Christoph and Pompe, Bernd , title =. Physical Review Letters , year =
-
[5]
Richman, Joshua S. and Moorman, J. Randall , title =. American Journal of Physiology-Heart and Circulatory Physiology , year =
-
[6]
Kirschstein, Timo and K. What is the Source of the. Clinical. 2009 , volume =
work page 2009
-
[7]
Smith, S. J. M. , title =. Journal of Neurology, Neurosurgery. 2005 , volume =
work page 2005
-
[8]
Stephansen, Jens B. and Olesen, Alexander N. and Olsen, Mads and Ambati, Aditya and Leary, Eileen B. and Moore, Hyatt E. and Carrillo, Oscar and Lin, Ling and Han, Fang and Yan, Han and Sun, Yun L. and Dauvilliers, Yves and Scholz, Sabine and Barateau, Lucie and H. Neural Network Analysis of Sleep Stages Enables Efficient Diagnosis of Narcolepsy , journal...
work page 2018
-
[9]
Neuronal Oscillations in Cortical Networks , journal =
Buzs. Neuronal Oscillations in Cortical Networks , journal =. 2004 , volume =
work page 2004
-
[10]
and Edwards, Erik and Dalal, Sarang S
Canolty, Ryan T. and Edwards, Erik and Dalal, Sarang S. and Soltani, Maryam and Nagarajan, Srikantan S. and Kirsch, Heidi E. and Berger, Mitchel S. and Barbaro, Nicholas M. and Knight, Robert T. , title =. Science , year =
-
[11]
Canolty, Ryan T. and Knight, Robert T. , title =. Trends in Cognitive Sciences , year =
- [12]
- [13]
- [14]
-
[15]
Physical Review Letters , year =
Prichard, Dean and Theiler, James , title =. Physical Review Letters , year =
-
[16]
Physica D: Nonlinear Phenomena , year =
Schreiber, Thomas and Schmitz, Andreas , title =. Physica D: Nonlinear Phenomena , year =
-
[17]
Testing for Nonlinearity in Time Series: The Method of Surrogate Data , journal =
Theiler, James and Eubank, Stephen and Longtin, Andr. Testing for Nonlinearity in Time Series: The Method of Surrogate Data , journal =. 1992 , volume =
work page 1992
-
[18]
Tort, Adriano B. L. and Komorowski, Robert and Eichenbaum, Howard and Kopell, Nancy , title =. Journal of Neurophysiology , year =
-
[19]
2024 IEEE International Symposium on Biomedical Imaging (ISBI) , year =
Cui, Wenhui and Jeong, Woojae and Th. 2024 IEEE International Symposium on Biomedical Imaging (ISBI) , year =
work page 2024
-
[20]
Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
Foumani, Navid Mohammadi and Mackellar, Geoffrey and Ghane, Soheila and Irtza, Saad and Nguyen, Nam and Salehi, Mahsa , title =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
-
[21]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Jiang, Wei-Bang and Zhao, Li-Ming and Lu, Bao-Liang , title =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[22]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Jiang, Wei-Bang and Wang, Yansen and Lu, Bao-Liang and Li, Dongsheng , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[23]
Frontiers in Human Neuroscience , year =
Kostas, Demetres and Aroca-Ouellette, Stephane and Rudzicz, Frank , title =. Frontiers in Human Neuroscience , year =. doi:10.3389/fnhum.2021.653659 , archivePrefix =. 2101.12037 , url =
-
[24]
Brandon and Sun, Jimeng , title =
Yang, Chaoqi and Westover, M. Brandon and Sun, Jimeng , title =. Advances in Neural Information Processing Systems 36 (NeurIPS) , year =
-
[25]
The Eleventh International Conference on Learning Representations (ICLR) , year =
Wang, Christopher and Subramaniam, Vighnesh and Yaari, Adam Uri and Kreiman, Gabriel and Katz, Boris and Cases, Ignacio and Barbu, Andrei , title =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[26]
The Thirteenth International Conference on Learning Representations (ICLR) , year =
Wang, Jiquan and Zhao, Sha and Luo, Zhiling and Zhou, Yangxuan and Jiang, Haiteng and Li, Shijian and Li, Tao and Pan, Gang , title =. The Thirteenth International Conference on Learning Representations (ICLR) , year =
-
[27]
Advances in Neural Information Processing Systems 36 (NeurIPS) , year =
Zhang, Daoze and Yuan, Zhizhang and Yang, Yang and Chen, Junru and Wang, Jingjing and Li, Yafeng , title =. Advances in Neural Information Processing Systems 36 (NeurIPS) , year =
-
[28]
Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
Wang, Guangyu and Liu, Wenchao and He, Yuhong and Xu, Cong and Ma, Lin and Li, Haifeng , title =. Advances in Neural Information Processing Systems 37 (NeurIPS) , year =
-
[29]
Advances in Neural Information Processing Systems 38 (NeurIPS) , year =
Zhou, Yuchen and Wu, Jiamin and Ren, Zichen and Yao, Zhouheng and Lu, Weiheng and Peng, Kunyu and Zheng, Qihao and Song, Chunfeng and Ouyang, Wanli and Gou, Chao , title =. Advances in Neural Information Processing Systems 38 (NeurIPS) , year =
-
[30]
Computational Linguistics , year =
Belinkov, Yonatan , title =. Computational Linguistics , year =. doi:10.1162/coli_a_00422 , url =
work page internal anchor Pith review doi:10.1162/coli_a_00422
-
[31]
What you can cram into a single \ &!\#* vector:
Conneau, Alexis and Kruszewski, German and Lample, Guillaume and Barrault, Lo. What you can cram into a single \ &!\#* vector:. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , year =. doi:10.18653/v1/P18-1198 , url =
-
[32]
Advances in Neural Information Processing Systems 36 (NeurIPS) , year =
Belrose, Nora and Schneider-Joseph, David and Ravfogel, Shauli and Cotterell, Ryan and Raff, Edward and Biderman, Stella , title =. Advances in Neural Information Processing Systems 36 (NeurIPS) , year =
-
[33]
Causal Scrubbing: A Method for Rigorously Testing Interpretability Hypotheses , howpublished =
Chan, Lawrence and Garriga-Alonso, Adri. Causal Scrubbing: A Method for Rigorously Testing Interpretability Hypotheses , howpublished =. 2022 , month = dec, url =
work page 2022
-
[34]
Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
Koh, Pang Wei and Nguyen, Thao and Tang, Yew Siang and Mussmann, Stephen and Pierson, Emma and Kim, Been and Liang, Percy , title =. Proceedings of the 37th International Conference on Machine Learning (ICML) , year =
-
[35]
Advances in Neural Information Processing Systems 35 (NeurIPS) , year =
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , title =. Advances in Neural Information Processing Systems 35 (NeurIPS) , year =
-
[36]
Ravfogel, Shauli and Elazar, Yanai and Gonen, Hila and Twiton, Michael and Goldberg, Yoav , title =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =. doi:10.18653/v1/2020.acl-main.647 , archivePrefix =. 2004.07667 , url =
-
[37]
Proceedings of the 39th International Conference on Machine Learning (ICML) , year =
Ravfogel, Shauli and Twiton, Michael and Goldberg, Yoav and Cotterell, Ryan , title =. Proceedings of the 39th International Conference on Machine Learning (ICML) , year =
-
[38]
Ravfogel, Shauli and Vargas, Francisco and Goldberg, Yoav and Cotterell, Ryan , title =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =. doi:10.18653/v1/2022.emnlp-main.405 , archivePrefix =. 2201.12191 , url =
-
[39]
Advances in Neural Information Processing Systems 33 (NeurIPS) , year =
Vig, Jesse and Gehrmann, Sebastian and Belinkov, Yonatan and Qian, Sharon and Nevo, Daniel and Singer, Yaron and Shieber, Stuart , title =. Advances in Neural Information Processing Systems 33 (NeurIPS) , year =
-
[40]
The Eleventh International Conference on Learning Representations (ICLR) , year =
Wang, Kevin Ro and Variengien, Alexandre and Conmy, Arthur and Shlegeris, Buck and Steinhardt, Jacob , title =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[41]
The Twelfth International Conference on Learning Representations (ICLR) , year =
Zhang, Fred and Nanda, Neel , title =. The Twelfth International Conference on Learning Representations (ICLR) , year =
-
[42]
Nahmias, David M. and Kontson, Kimberly L. , title =. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD) , year =
- [43]
-
[44]
Evaluation of the Relation between Ictal
S. Evaluation of the Relation between Ictal. Brain Sciences , year =
-
[45]
Expert Systems with Applications , year =
Lee, Choel-Hui and Ahn, Daesun and Kim, Hakseung and Ha, Eun Jin and Kim, Jung-Bin and Kim, Dong-Joo , title =. Expert Systems with Applications , year =
-
[46]
Frontiers in Human Neuroscience , year =
Nam, Hyeonyeong and Kim, Jun-Mo and Choi, WooHyeok and Bak, Soyeon and Kam, Tae-Eui , title =. Frontiers in Human Neuroscience , year =
-
[47]
Saadatinia, Mehrshad and Salimi-Badr, Armin , title =. IEEE Access , year =
-
[48]
Concept-based Explainability for an
Gj. Concept-based Explainability for an. 2023 , archivePrefix =. 2307.12745 , primaryClass =
-
[49]
Almadhor, Ahmad and Ojo, Stephen and Nathaniel, Thomas I. and Alsubai, Shtwai and Alharthi, Abdullah and Al Hejaili, Abdullah and Sampedro, Gabriel Avelino , title =. Frontiers in Oncology , year =
-
[50]
Behavior Research Methods , year =
Sylvester, Sophia and Sagehorn, Merle and Gruber, Thomas and Atzm. Behavior Research Methods , year =
-
[51]
Depression and Anxiety , year =
Yi, Eun-Gyoung and Shim, Miseon and Hwang, Hyeon-Ho and Jeon, Sunhae and Hwang, Han-Jeong and Lee, Seung-Hwan , title =. Depression and Anxiety , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.