Recognition: 2 theorem links
· Lean TheoremGenerative Diffusion Prior Distillation for Long-Context Knowledge Transfer
Pith reviewed 2026-05-13 02:26 UTC · model grok-4.3
The pith
A diffusion generative prior supplies partial time-series classifiers with distributions of restorative long-context targets from full-sequence teachers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GDPD treats short-context student features as degraded observations of full-context teacher features. A diffusion-based generative prior is learned over the teacher features; posterior sampling then produces target representations that best explain the missing long-range information in each student feature. The student is optimized to minimize degradation relative to these targets, thereby receiving a distribution of task-relevant long-context knowledge that benefits learning on the partial classification task.
What carries the argument
The diffusion-based generative prior over teacher features, used to draw posterior samples of restorative target representations that explain missing long-range information in student features.
If this is right
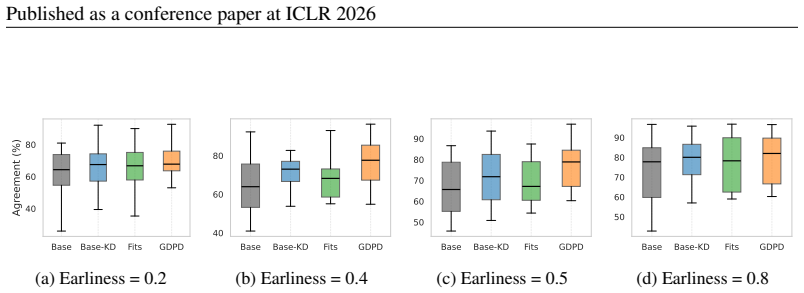
- Student models achieve higher accuracy on partial inputs across multiple earliness settings and datasets.
- The approach works for different student and teacher architectures without requiring architectural changes.
- Supervision is supplied as a distribution of targets rather than a single overwhelming full-context signal.
Where Pith is reading between the lines
- The same degradation-and-restoration framing could be applied to other partial-observation settings such as truncated video or audio clips.
- Performance gains may depend on how well the learned prior captures class-discriminative long-range patterns rather than generic sequence statistics.
Load-bearing premise
Short-context student features can be treated as degraded observations of full-context teacher features such that diffusion posterior sampling reliably supplies useful restorative targets.
What would settle it
Running the same partial-classification experiments with GDPD replaced by direct teacher-feature matching or no distillation and finding no accuracy gain on held-out prefix sequences across the tested datasets and architectures.
Figures


read the original abstract
While traditional time-series classifiers assume full sequences at inference, practical constraints (latency and cost) often limit inputs to partial prefixes. The absence of class-discriminative patterns in partial data can significantly hinder a classifier's ability to generalize. This work uses knowledge distillation (KD) to equip partial time series classifiers with the generalization ability of their full-sequence counterparts. In KD, high-capacity teacher transfers supervision to aid student learning on the target task. Matching with teacher features has shown promise in closing the generalization gap due to limited parameter capacity. However, when the generalization gap arises from training-data differences (full versus partial), the teacher's full-context features can be an overwhelming target signal for the student's short-context features. To provide progressive, diverse, and collective teacher supervision, we propose Generative Diffusion Prior Distillation (GDPD), a novel KD framework that treats short-context student features as degraded observations of the target full-context features. Inspired by the iterative restoration capability of diffusion models, we learn a diffusion-based generative prior over teacher features. Leveraging this prior, we posterior-sample target teacher representations that could best explain the missing long-range information in the student features and optimize the student features to be minimally degraded relative to these targets. GDPD provides each student feature with a distribution of task-relevant long-context knowledge, which benefits learning on the partial classification task. Extensive experiments across earliness settings, datasets, and architectures demonstrate GDPD's effectiveness for full-to-partial distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Generative Diffusion Prior Distillation (GDPD), a knowledge distillation framework for time-series classification. It trains a diffusion-based generative prior over full-context teacher features and uses posterior sampling to generate task-relevant long-context targets for short-context student features, treating the latter as degraded observations of the former. This is claimed to provide progressive and diverse supervision that improves student generalization on partial inputs, with experiments across earliness settings, datasets, and architectures.
Significance. If the central mechanism holds, GDPD could meaningfully advance early time-series classification by enabling principled transfer of long-range discriminative information without requiring full sequences at inference. The use of diffusion priors for generating restorative targets is a novel angle on feature-level KD that avoids direct matching of mismatched full vs. partial representations.
major comments (2)
- [Method / GDPD framework description] The method section (and abstract description of posterior sampling) treats short-context student features as degraded observations of full-context teacher features to enable diffusion posterior sampling, but no explicit degradation operator A (with tractable p(y|x)) is defined. When teacher and student use different encoders or capacities, truncation of the input series does not induce a well-defined mapping in feature space, rendering the posterior p(teacher_feature | student_feature) heuristic rather than principled; this directly undermines the claim that sampled targets reliably supply missing long-range information.
- [Experiments section] The abstract asserts 'extensive experiments across earliness settings, datasets, and architectures' demonstrating effectiveness, yet provides no quantitative results, ablation studies, or error analysis. Without these (e.g., accuracy deltas vs. standard KD baselines, sensitivity to diffusion steps, or failure cases on specific datasets), the central claim that GDPD 'benefits learning on the partial classification task' cannot be verified as load-bearing.
minor comments (1)
- [Method] Notation for student/teacher features and the diffusion prior could be clarified with explicit equations early in the method to avoid ambiguity in how the generative prior is conditioned.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method / GDPD framework description] The method section (and abstract description of posterior sampling) treats short-context student features as degraded observations of full-context teacher features to enable diffusion posterior sampling, but no explicit degradation operator A (with tractable p(y|x)) is defined. When teacher and student use different encoders or capacities, truncation of the input series does not induce a well-defined mapping in feature space, rendering the posterior p(teacher_feature | student_feature) heuristic rather than principled; this directly undermines the claim that sampled targets reliably supply missing long-range information.
Authors: We agree that an explicit degradation operator A is not formalized in the current text. The framework learns an unconditional diffusion prior over teacher features and performs conditional posterior sampling guided by student features; the conditioning implicitly treats the student representation as a degraded observation without requiring a closed-form likelihood for every encoder pair. When encoders differ, the mapping from input truncation to feature space is indeed not strictly defined and the procedure is heuristic. We will revise the Method section to (i) introduce a formal (if approximate) degradation model based on temporal masking projected through the encoder, (ii) explicitly state the assumptions under which the posterior supplies restorative targets, and (iii) add a short discussion of the heuristic nature and its empirical consequences. These changes will make the presentation more precise while preserving the core technical contribution. revision: yes
-
Referee: [Experiments section] The abstract asserts 'extensive experiments across earliness settings, datasets, and architectures' demonstrating effectiveness, yet provides no quantitative results, ablation studies, or error analysis. Without these (e.g., accuracy deltas vs. standard KD baselines, sensitivity to diffusion steps, or failure cases on specific datasets), the central claim that GDPD 'benefits learning on the partial classification task' cannot be verified as load-bearing.
Authors: The manuscript reports experimental results across multiple datasets, earliness ratios, and architectures, but we acknowledge that the current version lacks sufficient quantitative detail and supporting analyses to fully substantiate the claims. We will expand the Experiments section with (i) tables reporting concrete accuracy deltas versus standard feature-matching KD baselines, (ii) ablation studies on the number of diffusion steps and guidance strength, and (iii) a dedicated error-analysis subsection that identifies datasets and earliness settings where GDPD shows limited or no improvement. These additions will allow readers to directly verify the load-bearing nature of the proposed mechanism. revision: yes
Circularity Check
No significant circularity; GDPD introduces an independent generative prior and sampling procedure.
full rationale
The paper's core derivation treats student features as degraded observations and learns a diffusion prior over teacher features to enable posterior sampling of restorative targets. This modeling choice is an explicit assumption rather than a self-referential definition or fitted quantity renamed as a prediction. No equations reduce the claimed benefit (distribution of long-context knowledge) to the input features by construction, and no load-bearing step relies on a self-citation chain or uniqueness theorem from the same authors. The framework is presented as a new KD method whose effectiveness is supported by experiments across datasets and architectures, keeping the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Generative Diffusion Prior over teacher features
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe learn a diffusion-based generative prior over teacher features... posterior-sample target teacher representations... optimize the student features to be minimally degraded relative to these targets
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearz_long,T = α z_short + (1-α)ϵ ... reverse process conditioned on z_short
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2012.09816 , year=
Zeyuan Allen-Zhu and Yuanzhi Li. Towards understanding ensemble, knowledge distillation and self-distillation in deep learning.arXiv preprint arXiv:2012.09816,
-
[2]
A., Lines, J., Flynn, M., Large, J., Bostrom, A.,
Anthony Bagnall, Hoang Anh Dau, Jason Lines, Michael Flynn, James Large, Aaron Bostrom, Paul Southam, and Eamonn Keogh. The uea multivariate time series classification archive, 2018.arXiv preprint arXiv:1811.00075,
-
[3]
Minshuo Chen, Song Mei, Jianqing Fan, and Mengdi Wang. An overview of diffusion models: Ap- plications, guided generation, statistical rates and optimization.arXiv preprint arXiv:2404.07771,
-
[4]
Learning to reason: Temporal saliency distillation for interpretable knowledge transfer
Nilushika Udayangani Hewa Dehigahawattage, Kishor Nandakishor, and Marimuthu Palaniswami. Learning to reason: Temporal saliency distillation for interpretable knowledge transfer. In Proceedings of the 28th European Conference on Artificial Intelligence (ECAI 2025), Fron- tiers in Artificial Intelligence and Applications (FAIA), Bologna, Italy,
work page 2025
-
[5]
Distilling the Knowledge in a Neural Network
IOS Press. doi: 10.3233/FAIA251144. Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.3233/faia251144
-
[6]
11 Published as a conference paper at ICLR 2026 Hassan Ismail Fawaz, Benjamin Lucas, Germain Forestier, Charlotte Pelletier, Daniel F Schmidt, Jonathan Weber, Geoffrey I Webb, Lhassane Idoumghar, Pierre-Alain Muller, and Franc ¸ois Petit- jean. Inceptiontime: Finding alexnet for time series classification.Data Mining and Knowledge Discovery, 34(6):1936–1962,
work page 2026
-
[7]
Faithful knowledge distillation.arXiv preprint arXiv:2306.04431,
Tom A Lamb, Rudy Brunel, Krishnamurthy DJ Dvijotham, M Pawan Kumar, Philip HS Torr, and Francisco Eiras. Faithful knowledge distillation.arXiv preprint arXiv:2306.04431,
-
[8]
Nikolaos Passalis, Maria Tzelepi, and Anastasios Tefas. Probabilistic knowledge transfer for lightweight deep representation learning.IEEE Transactions on Neural Networks and learning systems, 32(5):2030–2039,
work page 2030
-
[9]
Revisiting self-distillation.arXiv preprint arXiv:2206.08491,
Minh Pham, Minsu Cho, Ameya Joshi, and Chinmay Hegde. Revisiting self-distillation.arXiv preprint arXiv:2206.08491,
-
[10]
Zengyu Qiu, Xinzhu Ma, Kunlin Yang, Chunya Liu, Jun Hou, Shuai Yi, and Wanli Ouyang. Bet- ter teacher better student: Dynamic prior knowledge for knowledge distillation.arXiv preprint arXiv:2206.06067,
-
[11]
Predicting mortality of icu patients: The physionet/computing in cardiology challenge
12 Published as a conference paper at ICLR 2026 Ikaro Silva, George Moody, Roger Mark, and Leo Anthony Celi. Predicting mortality of icu patients: The physionet/computing in cardiology challenge
work page 2026
-
[12]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020a. Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020b. Samuel Stanton, Pavel...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Sergey Zagoruyko and Nikos Komodakis. Paying more attention to attention: Improving the perfor- mance of convolutional neural networks via attention transfer.arXiv preprint arXiv:1612.03928,
-
[14]
Knowledge distillation based on transformed teacher matching
Kaixiang Zheng and En-Hui Yang. Knowledge distillation based on transformed teacher matching. arXiv preprint arXiv:2402.11148,
-
[15]
13 Published as a conference paper at ICLR 2026 A APPENDIX A.1 RELATEDWORK Knowledge Distillation.KD, introduced by Bucilu ˇa et al. (2006); Hinton et al. (2015), demon- strates that smaller models can achieve comparable or superior performance through knowledge transfer from larger models. This process involves matching the teacher’s softened logits with...
work page 2026
-
[16]
Distillation may not transfer teacher knowledge effectively because of the capacity or architectural gap between teacher and student. To address this, recent studies have proposed inter- mediate “teacher–assistant” models (Mirzadeh et al., 2020; Son et al.,
work page 2020
-
[17]
and student-friendly teacher training (Park et al., 2021; Rao et al., 2023; Cho & Hariharan, 2019)
work page 2021
-
[18]
Knowledge from a single teacher is often not diverse enough, as it reflects only one perspective. To address this, ex- isting works promote diversity through teacher ensembles (Allen-Zhu & Li, 2020; You et al.,
work page 2020
-
[19]
or mutual supervision among student ensembles (Zhang et al., 2018; Furlanello et al., 2018). More recently, Hossain et al. (2025) generate multiple augmented teacher views from a single model by perturbing features with random noise, thereby increasing knowledge diversity while avoiding the cost of retraining multiple models
work page 2018
-
[20]
Knowledge is not always faithful: recent works observe that KD often transfers limited knowledge, leading students to learn predictive distributions very differ- ent from their teachers, which hinders their safe substitution (Stanton et al., 2021; Lamb et al., 2023). To mitigate this, recent studies have proposed transferring properties beyond direct logi...
work page 2021
-
[21]
(a network primarily composed of convolutional layers), and an InceptionTime network (Ismail Fawaz et al., 2020), which is among the current state-of-the-art for TSC. For experiments involving model compression, we construct smaller variants of LSTM under different compression levels by varying the number of layers and output dimensions. The total number ...
work page 2020
-
[22]
14 Published as a conference paper at ICLR 2026 Table 9: Configuration of networks used for student and teacher models. The output dimension indicates the hidden size for the LSTM and the output dimension of the first convolutional layer for InceptionTime (Ismail Fawaz et al.,
work page 2026
-
[23]
and ResNet (Wang et al., 2017). Network Num. Layers Output Dim. Total Param. Model Size (MB) Inception55-32 55 32 978440 0.9361 Resnet32-64 32 64 2016008 1.9315 LSTM3-100 3 100 812008 0.7744 LSTM2-32 2 32 51976 0.0496 LSTM1-8 1 8 1480 0.0014 Datasets.We conducted our experiments using 12 univariate time-series datasets from the UCR- 2015 archive (Dau et al.,
work page 2017
-
[24]
Details of the selected datasets are provided in Table 10 and Table 11, respectively
and 12 multivariate datasets from the UEA archive (Bagnall et al., 2018). Details of the selected datasets are provided in Table 10 and Table 11, respectively. All series were standardized to length 100 via linear interpolation, z-normalized, and evaluated with the original train/test split with 20% validation. Table 10: Summary of univariate UCR benchmar...
work page 2018
-
[25]
For GDPD students, the warm-up epoch is set toE warm = 300,350, nearly half of the total epochs
and trained with the Adam optimizer using a batch size of64for a maximum of600epochs, with the best weights selected based on validation loss. For GDPD students, the warm-up epoch is set toE warm = 300,350, nearly half of the total epochs. A learning rate decay of0.5is applied at epochs25,30, and35, with initial learning rates set to0.01for the LSTM3-100 ...
work page 2026
-
[26]
Table 12: Default hyperparameters used for implementing GDPD. Parameter Value Diffusion steps (T) 1000 Number of NFEs (sampling steps) 5 Knowledge distillation weight (λKD) Best among{0.1, 1, 10} Task loss weight (λT ask) 1.0 Number of posterior samples (J) 1 Total training epochs 600 Warm-up epochs (Ewarm) Best among{300, 350} Batch size 64 Optimizer Ada...
work page 2021
-
[27]
Table 13: Ablation of distillation ratio: GDPD performance measured in terms of AUC-PRC. Distillation ratio (λKD) 0 0.01 0.1 0.5 1 10 100 AUC-PRC 83.90 86.41 91.91 93.7297.2691.87 88.61 Ablation on Diffusion Controls.We ablate the number of forward diffusion stepsTin Ldiffusion(ϕ)with{100,500,800,1000}, obtaining 93.29, 95.33, 92.49, and 97.26, and setT= ...
-
[28]
cross architectures (Inception55-32→Resnet32-64, Resnet32-64→Inception55-32). Across both settings, GDPD consistently achieves the highest performance gains, measured by average AUC-PRC, lowest aver- age rank, and the greatest number of top-1 wins, demonstrating its effectiveness for both similar- and cross-architecture distillation. Table 18: Summary of ...
work page 2026
-
[29]
20 Published as a conference paper at ICLR 2026 Table 20: Detailed UCR results at earlinesse∈ {0.2L,0.4L,0.5L,0.6L,0.8L, L}forLSTM→ LSTM. Best per row inbold. (a)e= 0.2L Dataset Base Base-KD Fits GDPD CBF 64.0869.2468.44 68.96 Coffee 90.76 98.88 91.0799.34 ECG200 66.08 76.88 79.8180.19 ECGFiveDays 56.78 57.19 56.3257.70 Gun Point 77.38 75.18 81.3884.80 Fa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.