Recognition: 2 theorem links
· Lean TheoremCausal inference with ordinal outcomes: copula-based identification, estimation and sensitivity analysis
Pith reviewed 2026-05-13 02:15 UTC · model grok-4.3
The pith
A parametric copula with fixed association parameter turns the unidentifiable probability that one potential ordinal outcome exceeds another into an identified functional of the observed data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
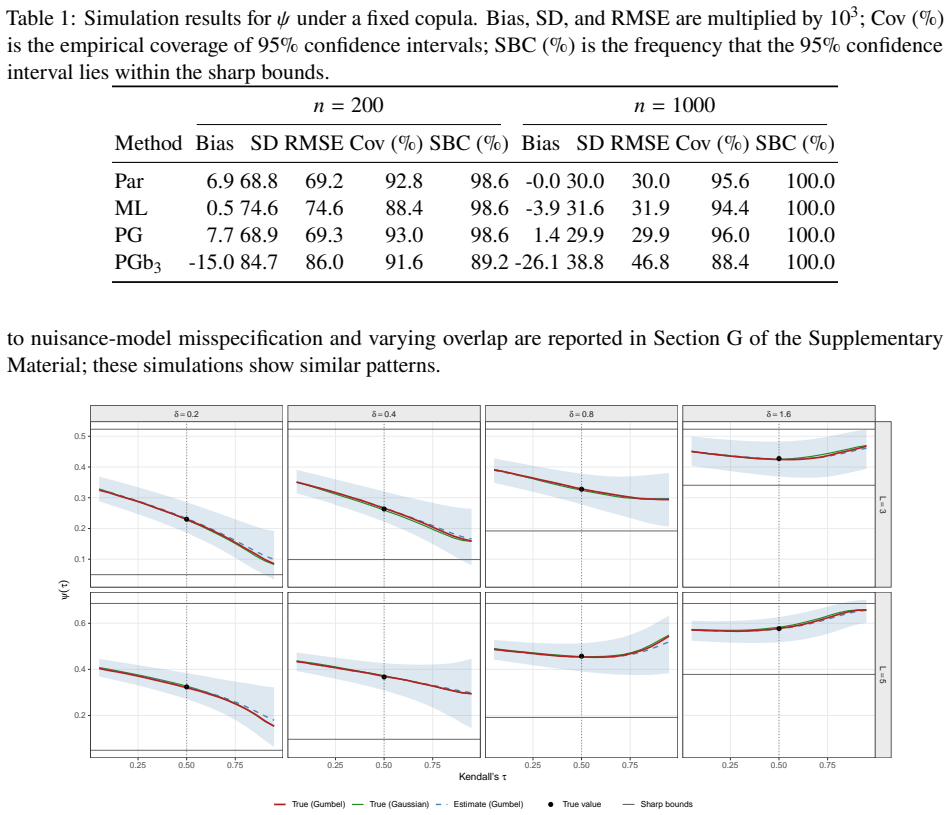
With a fixed copula parameter, the estimands become identified functionals of the observed data. Working under unconfoundedness, the authors derive the efficient influence function in the nonparametric model and construct one-step estimators that accommodate flexible nuisance estimation. The resulting procedure is rate-doubly-robust and attains the semiparametric efficiency bound under standard conditions. Varying the copula parameter yields a sensitivity curve with point-wise confidence bands that typically lie within the sharp bounds, providing an interpretable bridge between partial identification and point estimation.
What carries the argument
A parametric copula family that links the two identifiable marginal distributions of the potential outcomes, with its association parameter held fixed as the sensitivity parameter that controls the strength of dependence.
If this is right
- Causal probabilities comparing potential ordinal outcomes become point-identified and estimable once the copula association parameter is fixed.
- One-step estimators built from the efficient influence function are rate-doubly-robust and achieve the semiparametric efficiency bound when nuisance models converge at standard rates.
- Sensitivity curves obtained by varying the association parameter lie inside the sharp bounds and come with pointwise confidence bands.
- The same framework supports joint sensitivity analysis to both the copula family and possible violations of unconfoundedness.
Where Pith is reading between the lines
- The method offers a tunable compromise between the uninformative width of sharp bounds and the strong assumptions needed for full point identification.
- Because the estimators remain valid under slower nuisance convergence, they can be paired with modern machine-learning fits for the propensity score and conditional outcome distributions.
- The accompanying R package allows direct application to common ordinal endpoints such as Likert-scale responses or ordered disease stages.
Load-bearing premise
The chosen parametric copula family accurately represents the dependence structure between the two potential outcomes at the selected association value, and there is no unmeasured confounding so that the marginal distributions are correctly recovered from the observed data.
What would settle it
Compute the copula-based point estimate for a range of association parameters and check whether any of those estimates fall outside the sharp partial-identification bounds derived from the same data; consistent violation for plausible copulas would contradict the identification claim.
Figures
read the original abstract
In causal inference with ordinal outcomes, several interpretable estimands are functions of the probability that the potential outcome under one treatment is larger than that under another treatment for the same unit. This probability depends on the joint distribution of both potential outcomes and is generally not identifiable. Existing work has focused on sharp bounds of this probability based on partial identification, but bounds are often too wide to be informative. We propose a copula-based method that links the identifiable marginal distributions of the potential outcomes via a parametric copula, treating the copula association parameter as a sensitivity parameter. With a fixed copula parameter, the estimands become identified functionals of the observed data. Working under unconfoundedness, we derive the efficient influence function in the nonparametric model and construct one-step estimators that accommodate flexible nuisance estimation. The resulting procedure is rate-doubly-robust and attains the semiparametric efficiency bound under standard conditions. Varying the copula parameter yields a sensitivity curve with point-wise confidence bands that typically lie within the sharp bounds, providing an interpretable bridge between partial identification and point estimation. We further provide a comprehensive sensitivity analysis with respect to both the copula specification and the unconfoundedness assumption. We develop an associated R package \texttt{ordinalCI}.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a copula-based method for causal inference with ordinal outcomes. It links the identifiable marginal distributions of potential outcomes Y(1) and Y(0) under unconfoundedness using a parametric copula, treating the association parameter as a sensitivity parameter. This renders estimands such as P(Y(1) > Y(0)) as identified functionals of the observed data. The authors derive the efficient influence function in the nonparametric model and construct one-step estimators that are rate-doubly robust and attain the semiparametric efficiency bound. The work includes sensitivity analysis over the copula parameter and unconfoundedness violations, supported by an associated R package ordinalCI.
Significance. If the EIF derivation and double-robustness claims hold, the paper makes a useful contribution by providing more informative point estimates and inference than wide partial-identification bounds while explicitly acknowledging dependence assumptions via sensitivity analysis. The rate-double robustness under flexible nuisance estimation and the efficiency bound attainment are technically notable strengths. The provision of software and comprehensive sensitivity tools adds practical value for applied work with ordinal data in causal settings.
major comments (2)
- Section on identification and EIF (around the claims in the abstract and estimation section): The central claim that fixing the copula association parameter yields identified functionals with rate-doubly-robust one-step estimators attaining the efficiency bound is load-bearing. The explicit form of the efficient influence function and the verification of double robustness under the nonparametric model should be presented in full detail, as the abstract states these are derived but the provided text does not allow direct verification of the algebra or conditions.
- Sensitivity analysis section: While varying the copula parameter is a strength, the construction of point-wise confidence bands around the sensitivity curve must explicitly account for estimation of the marginals and the fixed association parameter; otherwise the bands may not correctly reflect uncertainty when the copula family is misspecified.
minor comments (3)
- Abstract: The term 'rate-doubly-robust' is used without a brief parenthetical explanation or reference; adding one sentence would improve accessibility for readers outside semiparametric theory.
- Software and reproducibility: The R package ordinalCI is referenced but no installation instructions, GitHub repository, or example code snippet appears in the manuscript; including these would strengthen the practical contribution.
- Notation: Ensure that the symbols for the copula parameter and the ordinal support are defined consistently when moving from the identification result to the sensitivity curves.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive comments, which will help improve the clarity and rigor of the manuscript. We address each major comment below.
read point-by-point responses
-
Referee: Section on identification and EIF (around the claims in the abstract and estimation section): The central claim that fixing the copula association parameter yields identified functionals with rate-doubly-robust one-step estimators attaining the efficiency bound is load-bearing. The explicit form of the efficient influence function and the verification of double robustness under the nonparametric model should be presented in full detail, as the abstract states these are derived but the provided text does not allow direct verification of the algebra or conditions.
Authors: We appreciate this feedback on verifiability. In the revised manuscript we will expand the identification and estimation sections to present the full derivation of the efficient influence function for the target functionals (e.g., P(Y(1) > Y(0))) when the copula parameter is fixed. The expanded derivation will explicitly display the EIF expression in the nonparametric model, show the one-step estimator construction, and verify rate-double robustness by establishing that the estimator is consistent and asymptotically normal whenever the product of the nuisance estimation errors is o_p(n^{-1/2}), while attaining the semiparametric efficiency bound under standard rate conditions on the propensity score and conditional distribution estimators. revision: yes
-
Referee: Sensitivity analysis section: While varying the copula parameter is a strength, the construction of point-wise confidence bands around the sensitivity curve must explicitly account for estimation of the marginals and the fixed association parameter; otherwise the bands may not correctly reflect uncertainty when the copula family is misspecified.
Authors: We agree that the bands must properly incorporate uncertainty from marginal estimation. Our current construction uses the EIF-based one-step estimator, which accounts for estimation of the marginal distributions while holding the copula association parameter fixed for each sensitivity value; the resulting point-wise bands are therefore valid conditional on the chosen copula family and parameter. In the revision we will make this conditioning explicit in the sensitivity analysis section, clarify that the bands do not integrate over uncertainty in the copula family choice itself (as the family is varied deliberately), and add a brief discussion of robustness to copula misspecification via additional simulation checks. revision: partial
Circularity Check
No significant circularity identified
full rationale
The derivation begins from unconfoundedness (standard assumption) to identify marginal distributions of potential outcomes, then links them via a fixed parametric copula whose association parameter is explicitly treated as a sensitivity input rather than estimated from the target estimand. The efficient influence function is derived in the nonparametric model for the resulting functional, and the one-step estimators are constructed to be rate-doubly robust and efficient under standard conditions; these steps follow directly from semiparametric theory for plug-in functionals without any reduction to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The sensitivity curves are presented as a bridge to partial identification bounds, with no ansatz smuggling or renaming of known results. The procedure is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- copula association parameter
axioms (2)
- domain assumption Unconfoundedness (conditional exchangeability)
- ad hoc to paper Parametric copula family
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWith a fixed copula parameter, the estimands become identified functionals of the observed data... derive the efficient influence function... rate-doubly-robust one-step estimators
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearAssumption 2. There exists a known copula C_ρ such that pr{Y(1)≤k, Y(0)≤j|X}=C_ρ{F1(k|X), F0(j|X)}
Reference graph
Works this paper leans on
-
[1]
Modeling partial compliance through copulas in a principal stratification framework
Francesco Bartolucci and Leonardo Grilli. Modeling partial compliance through copulas in a principal stratification framework. Journal of the American Statistical Association, 106 0 (494): 0 469--479, 2011
work page 2011
-
[2]
Double/debiased machine learning for treatment and structural parameters, 2018
Victor Chernozhukov, Denis Chetverikov, Mert Demirer, Esther Duflo, Christian Hansen, Whitney Newey, and James Robins. Double/debiased machine learning for treatment and structural parameters, 2018
work page 2018
-
[3]
Bayesian inference of causal effects for an ordinal outcome in randomized trials
Yasutaka Chiba. Bayesian inference of causal effects for an ordinal outcome in randomized trials. Journal of Causal Inference, 6 0 (2): 0 20170019, 2018
work page 2018
-
[4]
Emily J Huang, Ethan X Fang, Daniel F Hanley, and Michael Rosenblum. Inequality in treatment benefits: Can we determine if a new treatment benefits the many or the few? Biostatistics, 18 0 (2): 0 308--324, 2017
work page 2017
-
[5]
Semiparametric doubly robust targeted double machine learning: a review
Edward H Kennedy. Semiparametric doubly robust targeted double machine learning: a review. Handbook of statistical methods for precision medicine, pages 207--236, 2024
work page 2024
-
[6]
Bayesian analysis of treatment effects in an ordered potential outcomes model
Mingliang Li and Justin L Tobias. Bayesian analysis of treatment effects in an ordered potential outcomes model. In Modelling and Evaluating Treatment Effects in Econometrics, volume 21, pages 57--91. Emerald Group Publishing Limited, 2008
work page 2008
-
[7]
Treatment effects on ordinal outcomes: Causal estimands and sharp bounds
Jiannan Lu, Peng Ding, and Tirthankar Dasgupta. Treatment effects on ordinal outcomes: Causal estimands and sharp bounds. Journal of Educational and Behavioral Statistics, 43 0 (5): 0 540--567, 2018
work page 2018
-
[8]
Sharp bounds on the relative treatment effect for ordinal outcomes
Jiannan Lu, Yunshu Zhang, and Peng Ding. Sharp bounds on the relative treatment effect for ordinal outcomes. Biometrics, 76 0 (2): 0 664--669, 2020
work page 2020
-
[9]
Sizhu Lu, Zhichao Jiang, and Peng Ding. Principal stratification with continuous post-treatment variables: Nonparametric identification and semiparametric estimation. Journal of the Royal Statistical Society Series B: Statistical Methodology, page qkaf049, 2025
work page 2025
-
[10]
On causal estimation using U -statistics
Lu Mao. On causal estimation using U -statistics . Biometrika, 105 0 (1): 0 215--220, 2018
work page 2018
-
[11]
Semiparametric efficiency bounds
Whitney K Newey. Semiparametric efficiency bounds. Journal of applied econometrics, 5 0 (2): 0 99--135, 1990
work page 1990
-
[12]
Stuart J Pocock, Cono A Ariti, Timothy J Collier, and Duolao Wang. The win ratio: a new approach to the analysis of composite endpoints in clinical trials based on clinical priorities. European heart journal, 33 0 (2): 0 176--182, 2012
work page 2012
-
[13]
Higher order influence functions and minimax estimation of nonlinear functionals
James Robins, Lingling Li, Eric Tchetgen, Aad van der Vaart, et al. Higher order influence functions and minimax estimation of nonlinear functionals. In Probability and statistics: essays in honor of David A. Freedman, volume 2, pages 335--422. Institute of Mathematical Statistics, 2008
work page 2008
- [14]
-
[15]
Fonctions de r \'e partition \`a n dimensions et leurs marges
M Sklar. Fonctions de r \'e partition \`a n dimensions et leurs marges. In Annales de l'ISUP, volume 8, pages 229--231, 1959
work page 1959
-
[16]
Semiparametric theory and missing data
Anastasios A Tsiatis. Semiparametric theory and missing data. Springer, 2006
work page 2006
-
[17]
Weak convergence and empirical processes with applications to statistics
AW van der Vaart and Jon A Wellner. Weak convergence and empirical processes with applications to statistics. Journal of the Royal Statistical Society-Series A Statistics in Society, 160 0 (3): 0 596--608, 1997
work page 1997
-
[19]
Bounds on the conditional and average treatment effect with unobserved confounding factors
Steve Yadlowsky, Hongseok Namkoong, Sanjay Basu, John Duchi, and Lu Tian. Bounds on the conditional and average treatment effect with unobserved confounding factors. Annals of statistics, 50 0 (5): 0 2587, 2022
work page 2022
-
[20]
Shuxi Zeng, Fan Li, and Peng Ding. Is being an only child harmful to psychological health?: evidence from an instrumental variable analysis of china's one-child policy. Journal of the Royal Statistical Society Series A: Statistics in Society, 183 0 (4): 0 1615--1635, 2020
work page 2020
-
[21]
Identifying and bounding the probability of necessity for causes of effects with ordinal outcomes
Chao Zhang, Zhi Geng, Wei Li, and Peng Ding. Identifying and bounding the probability of necessity for causes of effects with ordinal outcomes. Biometrika, 112 0 (3): 0 asaf049, 2025
work page 2025
-
[22]
Copula-based sensitivity analysis for multi-treatment causal inference with unobserved confounding
Jiajing Zheng, Alexander D'Amour, and Alexander Franks. Copula-based sensitivity analysis for multi-treatment causal inference with unobserved confounding. Journal of Machine Learning Research, 26 0 (36): 0 1--60, 2025
work page 2025
-
[23]
International journal of obesity , volume=
The ‘obesity paradox' may not be a paradox at all , author=. International journal of obesity , volume=. 2017 , publisher=
work page 2017
-
[24]
International journal of obesity , volume=
BMI-related errors in the measurement of obesity , author=. International journal of obesity , volume=. 2008 , publisher=
work page 2008
-
[25]
Obesity paradox does exist , author=. Diabetes care , volume=. 2013 , publisher=
work page 2013
-
[26]
International journal of epidemiology , volume=
Commentary: the paradox of body mass index in obesity assessment: not a good index of adiposity, but not a bad index of cardio-metabolic risk , author=. International journal of epidemiology , volume=. 2014 , publisher=
work page 2014
-
[27]
International journal of obesity , volume=
‘Obesity paradox’misunderstands the biology of optimal weight throughout the life cycle , author=. International journal of obesity , volume=. 2015 , publisher=
work page 2015
-
[28]
The “obesity paradox” explained , author=. Epidemiology , volume=. 2013 , publisher=
work page 2013
-
[29]
Current oncology reports , volume=
The obesity paradox in cancer: a review , author=. Current oncology reports , volume=. 2016 , publisher=
work page 2016
-
[30]
Commentary: selection bias as an explanation for the obesity paradox: just because it's possible doesn't mean it's plausible , author=. Epidemiology , volume=. 2014 , publisher=
work page 2014
-
[31]
Epidemiology (Cambridge, Mass.) , volume=
Collider bias is only a partial explanation for the obesity paradox , author=. Epidemiology (Cambridge, Mass.) , volume=. 2016 , publisher=
work page 2016
-
[32]
Epidemiology (Cambridge, Mass.) , volume=
Obesity paradox: conditioning on disease enhances biases in estimating the mortality risks of obesity , author=. Epidemiology (Cambridge, Mass.) , volume=. 2014 , publisher=
work page 2014
-
[33]
From bad to worse: collider stratification amplifies confounding bias in the “obesity paradox” , author=. European journal of epidemiology , volume=. 2015 , publisher=
work page 2015
-
[34]
Semiparametric theory and missing data , author=. 2006 , publisher=
work page 2006
-
[35]
Statistics in medicine , volume=
Doubly robust estimators of causal exposure effects with missing data in the outcome, exposure or a confounder , author=. Statistics in medicine , volume=. 2012 , publisher=
work page 2012
-
[36]
Journal of the American Statistical Association , year=
Combining multiple observational data sources to estimate causal effects , author=. Journal of the American Statistical Association , year=
-
[37]
Journal of Business & Economic Statistics , volume=
Bias-corrected matching estimators for average treatment effects , author=. Journal of Business & Economic Statistics , volume=. 2011 , publisher=
work page 2011
-
[38]
Minimal dispersion approximately balancing weights: asymptotic properties and practical considerations , author=. Biometrika , volume=. 2020 , publisher=
work page 2020
-
[39]
arXiv preprint arXiv:2110.14831 , year=
The balancing act in causal inference , author=. arXiv preprint arXiv:2110.14831 , year=
-
[40]
The Annals of Applied Statistics , volume=
Covariate balancing propensity score for a continuous treatment: Application to the efficacy of political advertisements , author=. The Annals of Applied Statistics , volume=. 2018 , publisher=
work page 2018
-
[41]
Health Services and Outcomes Research Methodology , volume=
Nonparametric estimation of population average dose-response curves using entropy balancing weights for continuous exposures , author=. Health Services and Outcomes Research Methodology , volume=. 2021 , publisher=
work page 2021
-
[42]
Entropy balancing for causal generalization with target sample summary information , author=. Biometrics , volume=. 2023 , publisher=
work page 2023
-
[43]
Journal of the American Statistical Association , pages=
Independence weights for causal inference with continuous treatments , author=. Journal of the American Statistical Association , pages=. 2023 , publisher=
work page 2023
-
[44]
Journal of Econometrics , volume=
Bellman filtering and smoothing for state--space models , author=. Journal of Econometrics , volume=. 2024 , publisher=
work page 2024
-
[45]
Quantitative Economics , volume=
A unified framework for efficient estimation of general treatment models , author=. Quantitative Economics , volume=. 2021 , publisher=
work page 2021
-
[46]
Journal of Econometrics , pages=
Testing unconditional and conditional independence via mutual information , author=. Journal of Econometrics , pages=. 2022 , publisher=
work page 2022
-
[47]
Journal of Basic Engineering , volume=
A new approach to linear filtering and prediction problems , author=. Journal of Basic Engineering , volume=
-
[48]
Monthly weather review , volume=
Data assimilation using an ensemble Kalman filter technique , author=. Monthly weather review , volume=
-
[49]
Journal of Geophysical Research: Oceans , volume=
Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics , author=. Journal of Geophysical Research: Oceans , volume=. 1994 , publisher=
work page 1994
-
[50]
Dynamic programming , author=. science , volume=. 1966 , publisher=
work page 1966
-
[51]
Causal inference methods for combining randomized trials and observational studies: a review , author=. Statistical Science , volume=. 2024 , publisher=
work page 2024
-
[52]
Robust sample weighting to facilitate individualized treatment rule learning for a target population , author=. Biometrika , volume=. 2024 , publisher=
work page 2024
-
[53]
arXiv preprint arXiv:2301.05491 , year=
Efficient and robust transfer learning of optimal individualized treatment regimes with right-censored survival data , author=. arXiv preprint arXiv:2301.05491 , year=
-
[54]
Journal of the American Statistical Association , volume=
A semiparametric approach to model effect modification , author=. Journal of the American Statistical Association , volume=. 2022 , publisher=
work page 2022
-
[55]
arXiv preprint arXiv:1911.05728 , year=
Balanced policy evaluation and learning for right censored data , author=. arXiv preprint arXiv:1911.05728 , year=
-
[56]
Electronic Journal of Statistics , volume=
Tree based weighted learning for estimating individualized treatment rules with censored data , author=. Electronic Journal of Statistics , volume=. 2017 , publisher=
work page 2017
- [57]
-
[58]
Journal of Econometrics , volume=
ArCo: An artificial counterfactual approach for high-dimensional panel time-series data , author=. Journal of Econometrics , volume=. 2018 , publisher=
work page 2018
-
[59]
Ideal spatial adaptation by wavelet shrinkage , author=. Biometrika , volume=. 1994 , publisher=
work page 1994
-
[60]
Detecting invalid instruments using L1-GMM , author=. Economics Letters , volume=. 2008 , publisher=
work page 2008
-
[61]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Confidence intervals for causal effects with invalid instruments by using two-stage hard thresholding with voting , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2018 , publisher=
work page 2018
-
[62]
Annals of Mathematical Statistics , volume=
Asymptotic Theory for Principal Component Analysis , author=. Annals of Mathematical Statistics , volume=
-
[63]
Stochastic Processes and Their Applications , volume=
Some mixing properties of time series models , author=. Stochastic Processes and Their Applications , volume=
-
[64]
Mixing and moment properties of various GARCH and stochastic volatility models , author=. Econometric Theory , volume=. 2002 , publisher=
work page 2002
-
[65]
Journal of Econometrics , volume=
Synthetic learner: Model-free inference on treatments over time , author=. Journal of Econometrics , volume=. 2023 , publisher=
work page 2023
-
[66]
The Annals of statistics , pages=
On the asymptotics of constrained M-estimation , author=. The Annals of statistics , pages=. 1994 , publisher=
work page 1994
-
[67]
Unpublished manuscript , volume=
Epi-convergence in distribution and stochastic equi-semicontinuity , author=. Unpublished manuscript , volume=. 1999 , publisher=
work page 1999
-
[68]
The Annals of Probability , pages=
A functional central limit theorem for weakly dependent sequences of random variables , author=. The Annals of Probability , pages=. 1984 , publisher=
work page 1984
-
[69]
Annals of statistics , volume=
Average treatment effects in the presence of unknown interference , author=. Annals of statistics , volume=. 2021 , publisher=
work page 2021
-
[70]
The Annals of statistics , volume=
Asymptotics for lasso-type estimators , author=. The Annals of statistics , volume=. 2000 , publisher=
work page 2000
-
[71]
The Adaptive Lasso and Its Oracle Properties , url =
Hui Zou , journal =. The Adaptive Lasso and Its Oracle Properties , url =. 2006 , bdsk-url-1 =
work page 2006
-
[72]
Handbook of Econometrics , volume=
Chapter 36 Large sample estimation and hypothesis testing , author=. Handbook of Econometrics , volume=
-
[73]
The Annals of Statistics , pages=
The asymptotic normal distribution of estimators in factor analysis under general conditions , author=. The Annals of Statistics , pages=. 1988 , publisher=
work page 1988
-
[74]
Annals of Statistics , volume=
Statistical analysis of factor models of high dimension , author=. Annals of Statistics , volume=
-
[75]
Bai, Jushan and Li, Kunpeng and Lu, Lina , journal=. 2016 , publisher=
work page 2016
-
[76]
Bernanke, Ben S and Boivin, Jean and Eliasz, Piotr , journal=. 2005 , publisher=
work page 2005
-
[77]
Journal of the American Statistical Association , volume=
The stationary bootstrap , author=. Journal of the American Statistical Association , volume=. 1994 , publisher=
work page 1994
-
[78]
Valid post-selection inference in model-free linear regression , year =
Kuchibhotla, Arun K and Brown, Lawrence D and Buja, Andreas and Cai, Junhui and George, Edward I and Zhao, Linda H , date-added =. Valid post-selection inference in model-free linear regression , year =. The Annals of Statistics , number =
-
[79]
Post-selection inference , volume =
Kuchibhotla, Arun K and Kolassa, John E and Kuffner, Todd A , date-added =. Post-selection inference , volume =. Annual Review of Statistics and Its Application , pages =
-
[80]
Whitney K. Newey and Kenneth D. West , date-added =. Hypothesis Testing with Efficient Method of Moments Estimation , url =. International Economic Review , number =. 1987 , bdsk-url-1 =
work page 1987
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.