Recognition: no theorem link
FedMM: Federated Collaborative Signal Quantization for Multi-Market CTR Prediction
Pith reviewed 2026-05-13 02:31 UTC · model grok-4.3
The pith
FedMM quantizes collaborative signals with dual codebooks to enable privacy-preserving multi-market CTR prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that deploying an RQ-VAE with dual-layer codebooks per market, where the first layer aggregates a global codebook for universal collaborative patterns and the second uses a local codebook for market-specific semantics, produces discrete codes that integrate general and specific signals. These codes can then be incorporated into CTR prediction models to improve accuracy across markets while ensuring privacy by avoiding transmission of raw data.
What carries the argument
Dual-layer RQ-VAE codebook mechanism, where a global federated codebook captures shared collaborative patterns and a local codebook captures market-specific ones, to quantize embeddings into discrete codes.
Load-bearing premise
The quantized discrete codes preserve sufficient collaborative signal to improve the performance of downstream CTR models, despite information loss from quantization and the challenges of disjoint ID spaces across markets.
What would settle it
If experiments show that a version without the local codebook layer performs equally well as the full dual-layer version on highly heterogeneous market data, the value of separating market-specific semantics would be falsified.
Figures




read the original abstract
Online platforms such as Amazon and Netflix serve users across multiple countries and regions, underscoring the importance of multi-market recommendation (MMR). Most MMR methods adopt a pre-training and fine-tuning paradigm, in which a unified model is first trained on centralized, global data and subsequently adapted to specific markets. However, this approach ignores the privacy of market data. While traditional federated learning preserves privacy, it typically aims to obtain a global model by aggregating model parameters and does not account for significant market heterogeneity. Additionally, because ID spaces are disjoint across markets, embedding-based aggregation strategies become ineffective. To overcome these challenges, we propose a federated collaborative signal quantization (FedMM) method for multi-market click-through rate (CTR) prediction. Our core idea leverages a discrete codebook mechanism to achieve privacy-preserving transmission and align disjoint ID spaces. We further employ a hierarchical codebook structure to capture cross-market shared patterns and market-specific characteristics. Specifically, we deploy a residual quantized variational autoencoder (RQ-VAE) with a dual-layer codebook mechanism for each market to quantize collaborative embeddings. The first layer utilizes a global federated codebook, updated via aggregation to capture universally shared collaborative patterns, while the second layer maintains a local codebook to learn market-specific semantics. Finally, the learned discrete codes, which integrate both general and specific collaborative signals, are incorporated into downstream CTR models to enhance prediction accuracy across all markets. Extensive experiments on benchmark datasets demonstrate that FedMM significantly improves recommendation performance with privacy guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FedMM, a federated collaborative signal quantization method for multi-market CTR prediction. It addresses privacy constraints and market heterogeneity with disjoint ID spaces by deploying a residual quantized VAE (RQ-VAE) with a dual-layer codebook per market: a global federated codebook (updated via aggregation) to capture shared collaborative patterns and a local codebook for market-specific semantics. The resulting discrete codes are incorporated into downstream CTR models. The abstract claims that extensive experiments on benchmark datasets show significant performance improvements while preserving privacy.
Significance. If the central empirical claim holds with rigorous validation, the work would be significant for privacy-preserving multi-market recommendation systems. Traditional federated averaging fails here due to disjoint ID spaces and heterogeneity, and the hierarchical quantization approach offers a concrete mechanism to transmit aligned collaborative signals without sharing raw embeddings or data. The dual-layer design explicitly separates universal and local patterns, which is a targeted extension of RQ-VAE techniques to the federated MMR setting. Credit is due for framing the problem around both privacy and cross-market alignment rather than parameter aggregation alone.
major comments (2)
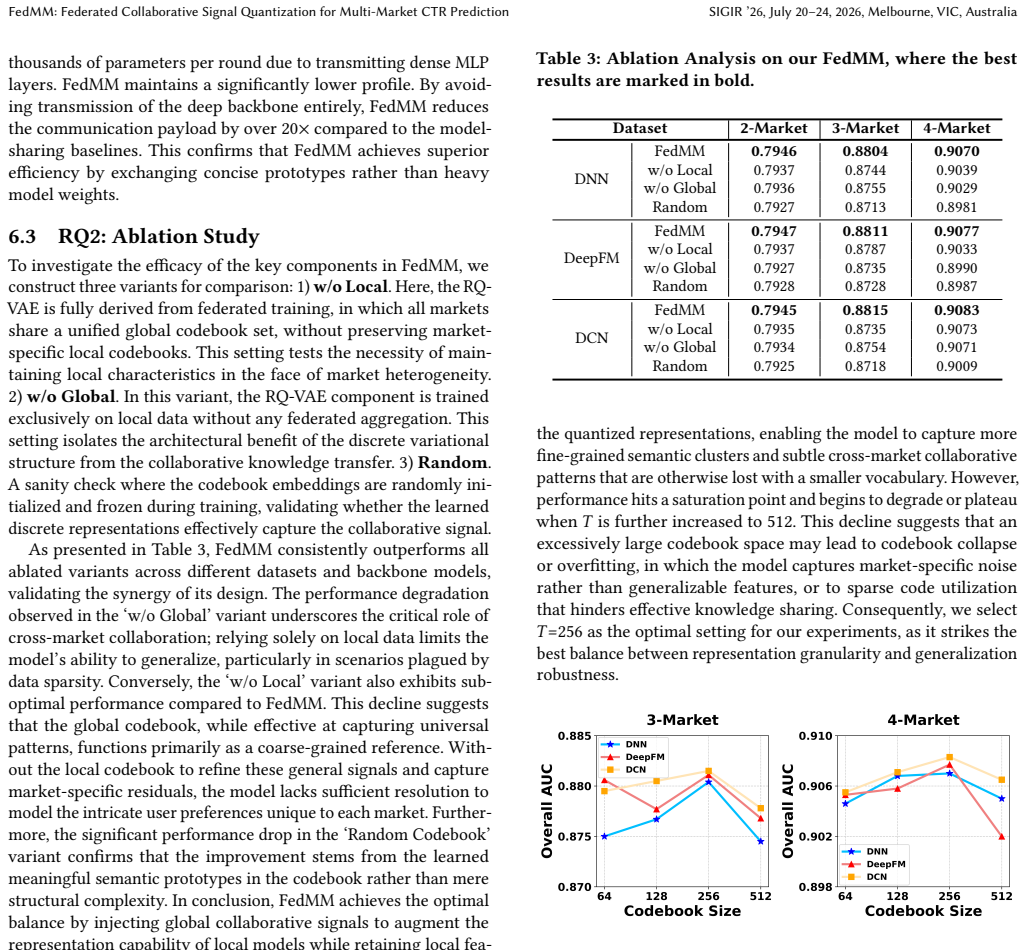
- [Abstract] Abstract: The central claim that 'Extensive experiments on benchmark datasets demonstrate that FedMM significantly improves recommendation performance' is asserted without any reported metrics (e.g., AUC, LogLoss), baselines (standard FedAvg, centralized pretrain-finetune, or other quantization methods), statistical tests, or ablation results. This is load-bearing for the paper's contribution, as the reader's weakest assumption (that dual-layer RQ-VAE codes retain usable collaborative signal across disjoint markets) cannot be evaluated from the given description.
- [Method] Method description (core architecture): No derivation, information-theoretic bound, or ablation is provided showing that the residual-quantized codes from the global + local codebooks preserve more collaborative signal than (a) local embeddings alone or (b) standard federated averaging of embeddings. Because ID spaces are disjoint, the claim that aggregated global code vectors align patterns across markets rests on an untested assumption about codebook capacity and embedding-space compatibility; this directly affects whether the downstream CTR improvement is attributable to the proposed mechanism.
minor comments (1)
- [Notation and figures] The notation for the dual-layer codebooks, residual quantization steps, and how discrete codes are injected into the CTR model could be clarified with a single summary table or diagram to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment below and describe the changes we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Extensive experiments on benchmark datasets demonstrate that FedMM significantly improves recommendation performance' is asserted without any reported metrics (e.g., AUC, LogLoss), baselines (standard FedAvg, centralized pretrain-finetune, or other quantization methods), statistical tests, or ablation results. This is load-bearing for the paper's contribution, as the reader's weakest assumption (that dual-layer RQ-VAE codes retain usable collaborative signal across disjoint markets) cannot be evaluated from the given description.
Authors: We agree that the abstract should be more self-contained and provide concrete quantitative support. In the revised manuscript we will expand the abstract to include specific AUC and LogLoss improvements, reference the main baselines (FedAvg, centralized pre-training/fine-tuning, and other quantization approaches), and note that improvements are statistically significant. The full experimental details, tables, and ablations already appear in Section 5; the revision will simply summarize the key results in the abstract so readers can immediately assess the empirical claim. revision: yes
-
Referee: [Method] Method description (core architecture): No derivation, information-theoretic bound, or ablation is provided showing that the residual-quantized codes from the global + local codebooks preserve more collaborative signal than (a) local embeddings alone or (b) standard federated averaging of embeddings. Because ID spaces are disjoint, the claim that aggregated global code vectors align patterns across markets rests on an untested assumption about codebook capacity and embedding-space compatibility; this directly affects whether the downstream CTR improvement is attributable to the proposed mechanism.
Authors: We acknowledge that the current method section emphasizes architectural description and motivation rather than a formal derivation or information-theoretic guarantee. The dual-codebook design is motivated by the practical constraint of disjoint ID spaces, which precludes direct embedding aggregation; the global codebook is updated via federated averaging of quantized indices, allowing shared collaborative patterns to emerge while the local codebook retains market-specific semantics. To strengthen the attribution of gains, we will add a dedicated ablation study (new subsection in Experiments) that compares (i) the full FedMM model, (ii) a local-codebook-only variant, and (iii) standard federated averaging of embeddings. We will also expand the discussion to articulate why residual quantization plus codebook aggregation empirically aligns signals across markets, supported by the existing cross-market transfer results. A strict information-theoretic bound is difficult to derive for this discrete, non-linear setting, but the added ablation and analysis will make the empirical grounding clearer. revision: partial
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper proposes FedMM as a new architecture: a residual quantized VAE with dual-layer codebooks (global federated codebook updated by aggregation for shared patterns, local codebook for market-specific semantics) to quantize embeddings, align disjoint ID spaces, and preserve privacy while feeding discrete codes into downstream CTR models. No equations, uniqueness theorems, or self-citations are invoked to derive the performance gain; the method is presented as an independent design choice whose value is assessed empirically on benchmarks. The core claim does not reduce to a fitted parameter renamed as a prediction, a self-referential definition, or a load-bearing citation chain. This is the normal case of a self-contained empirical proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary. 2019. Federated learning with personalization layers.arXiv preprint arXiv:1912.00818(2019)
work page internal anchor Pith review arXiv 2019
-
[3]
Samarth Bhargav, Mohammad Aliannejadi, and Evangelos Kanoulas. 2023. Market-aware models for efficient cross-market recommendation. InProceedings of the 45th European Conference on Information Retrieval. Springer, 134–149
work page 2023
-
[4]
Hamed Bonab, Mohammad Aliannejadi, Ali Vardasbi, Evangelos Kanoulas, and James Allan. 2021. Cross-market product recommendation. InProceedings of the 30th ACM International Conference on Information and Knowledge Management. 110–119
work page 2021
-
[5]
Jiangxia Cao, Xin Cong, Tingwen Liu, and Bin Wang. 2022. Item similarity mining for multi-market recommendation. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2249–2254
work page 2022
-
[6]
Di Chai, Leye Wang, Kai Chen, and Qiang Yang. 2020. Secure federated matrix factorization.IEEE Intelligent Systems36, 5 (2020), 11–20
work page 2020
-
[7]
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al
-
[8]
InProceedings of the 1st Workshop on Deep Learning for Recommender Systems
Wide & deep learning for recommender systems. InProceedings of the 1st Workshop on Deep Learning for Recommender Systems. 7–10
-
[9]
Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta- learning for fast adaptation of deep networks. InProceedings of the 34th Interna- tional Conference on Machine Learning. 1126–1135
work page 2017
-
[10]
Carlos A Gomez-Uribe and Neil Hunt. 2015. The Netflix recommender system: Algorithms, business value, and innovation.ACM Transactions on Management Information Systems6, 4 (2015), 1–19. FedMM: Federated Collaborative Signal Quantization for Multi-Market CTR Prediction SIGIR ’26, July 20–24, 2026, Melbourne, VIC, Australia
work page 2015
-
[11]
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: A factorization-machine based neural network for CTR prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence. 1725–1731
work page 2017
-
[12]
Mingzhe Han, Dongsheng Li, Jiafeng Xia, Jiahao Liu, Hansu Gu, Peng Zhang, Ning Gu, and Tun Lu. 2025. FedCIA: Federated collaborative information aggregation for privacy-preserving recommendation. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1687–1696
work page 2025
-
[13]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. 639–648
work page 2020
- [14]
-
[15]
Yutao Huang, Lingyang Chu, Zirui Zhou, Lanjun Wang, Jiangchuan Liu, Jian Pei, and Yong Zhang. 2021. Personalized cross-silo federated learning on non-iid data. InProceedings of the 35th AAAI conference on artificial intelligence. 7865–7873
work page 2021
-
[16]
Nam Hyeon-Woo, Moon Ye-Bin, and Tae Hyun Oh. 2022. FedPara: Low-rank Hadamard product for communication-efficient federated learning. InProceedings of the 10th International Conference on Learning Representations
work page 2022
-
[17]
HyeoungGuk Kang, Donghoon Lee, and Hyunsouk Cho. 2023. Outlier-aware cross-market product recommendation. InProceedings of the 2023 IEEE Interna- tional Conference on Big Data and Smart Computing. IEEE, 120–123
work page 2023
-
[18]
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. 2020. Scaffold: Stochastic controlled averag- ing for federated learning. InProceedings of the 37th International Conference on Machine Learning. 5132–5143
work page 2020
-
[19]
Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization tech- niques for recommender systems.Computer42, 8 (2009), 30–37
work page 2009
-
[20]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. Autoregressive image generation using residual quantization. InProceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11523–11532
work page 2022
-
[21]
Shiwei Li, Yingyi Cheng, Haozhao Wang, Xing Tang, Shijie Xu, Weihong Luo, Yuhua Li, Dugang Liu, Xiuqiang He, and Ruixuan Li. 2024. Masked random noise for communication-efficient federated learning. InProceedings of the 32nd ACM International Conference on Multimedia. 3686–3694
work page 2024
-
[22]
Shiwei Li, Xiandi Luo, Haozhao Wang, Xing Tang, Shijie Xu, Yuhua Li, Ruix- uan Li, et al . 2025. The Panaceas for improving low-rank decomposition in communication-efficient federated learning. InProceedings of the 42nd Interna- tional Conference on Machine Learning. 35536–35561
work page 2025
-
[23]
Shiwei Li, Wenchao Xu, Haozhao Wang, Xing Tang, Yining Qi, Shijie Xu, Weihong Luo, Yuhua Li, Xiuqiang He, and Ruixuan Li. 2024. FedBAT: Communication- efficient federated learning via learnable binarization. InProceedings of the 41st International Conference on Machine Learning. 29074–29095
work page 2024
-
[24]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. 2020. Federated optimization in heterogeneous networks. In Proceedings of the 3rd Conference on Machine Learning and System. 429–450
work page 2020
-
[25]
Dugang Liu, Chaohua Yang, Yuwen Fu, Xing Tang, Gongfu Li, Fuyuan Lyu, Xiuqiang He, and Zhong Ming. 2025. Scenario shared instance modeling for click-through rate prediction. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2436–2447
work page 2025
-
[26]
Dugang Liu, Chaohua Yang, Xing Tang, Yejing Wang, Fuyuan Lyu, Weihong Luo, Xiuqiang He, Zhong Ming, and Xiangyu Zhao. 2024. MultiFS: Automated multi-scenario feature selection in deep recommender systems. InProceedings of the 17th ACM International Conference on Web Search and Data Mining. 434–442
work page 2024
-
[27]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. 2017. Communication-efficient learning of deep net- works from decentralized data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics. 1273–1282
work page 2017
-
[28]
Vasileios Perifanis and Pavlos S Efraimidis. 2022. Federated neural collaborative filtering.Knowledge-Based Systems242 (2022), 108441
work page 2022
-
[29]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al
-
[30]
InProceedings of the 37th International Conference on Neural Information Processing Systems
Recommender systems with generative retrieval. InProceedings of the 37th International Conference on Neural Information Processing Systems. 10299–10315
-
[31]
Brent Smith and Greg Linden. 2017. Two decades of recommender systems at Amazon. com.IEEE Internet Computing21, 3 (2017), 12–18
work page 2017
-
[32]
Zehua Sun, Yonghui Xu, Yong Liu, Wei He, Lanju Kong, Fangzhao Wu, Yali Jiang, and Lizhen Cui. 2024. A survey on federated recommendation systems.IEEE Transactions on Neural Networks and Learning Systems36, 1 (2024), 6–20
work page 2024
-
[33]
Ben Tan, Bo Liu, Vincent Zheng, and Qiang Yang. 2020. A federated recom- mender system for online services. InProceedings of the 14th ACM Conference on Recommender Systems. 579–581
work page 2020
-
[34]
Xing Tang, Chaohua Yang, Yuwen Fu, Dongyang Ao, Shiwei Li, Fuyuan Lyu, Dugang Liu, and Xiuqiang He. 2025. Retrieval augmented cross-domain lifeLong behavior modeling for enhancing click-through rate prediction. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4891–4900
work page 2025
-
[35]
Chen Wang, Ziwei Fan, Liangwei Yang, Mingdai Yang, Xiaolong Liu, Zhiwei Liu, and Philip Yu. 2024. Pre-Training with transferable attention for addressing market shifts in cross-market sequential recommendation. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 2970– 2979
work page 2024
-
[36]
Jianyu Wang, Qinghua Liu, Hao Liang, Gauri Joshi, and H Vincent Poor. 2020. Tackling the objective inconsistency problem in heterogeneous federated opti- mization. InProceedings of the 34th International Conference on Neural Information Processing System. 7611–7623
work page 2020
-
[37]
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. 2017. Deep & cross network for ad click predictions. InProceedings of the ADKDD 2017. 1–7
work page 2017
-
[38]
Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019. Neural graph collaborative filtering. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval. 165–174
work page 2019
-
[39]
Chaohua Yang, Dugang Liu, Xing Tang, Yuwen Fu, Xiuqiang He, Xiangyu Zhao, and Zhong Ming. 2025. Multi-scenario instance embedding learning for deep rec- ommender systems. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2132–2141
work page 2025
-
[40]
Liu Yang, Ben Tan, Vincent W Zheng, Kai Chen, and Qiang Yang. 2020. Federated recommendation systems. InFederated Learning: Privacy and Incentive. Springer, 225–239
work page 2020
- [41]
- [42]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.