Recognition: 3 theorem links
· Lean TheoremFEFormer: Frequency-enhanced Vision Transformer for Generic Knowledge Extraction and Adaptive Feature Fusion in Volumetric Medical Image Segmentation
Pith reviewed 2026-05-13 00:45 UTC · model grok-4.3
The pith
FEFormer adds frequency modeling to Vision Transformers to capture fine local details and fuse features consistently for volumetric medical image segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
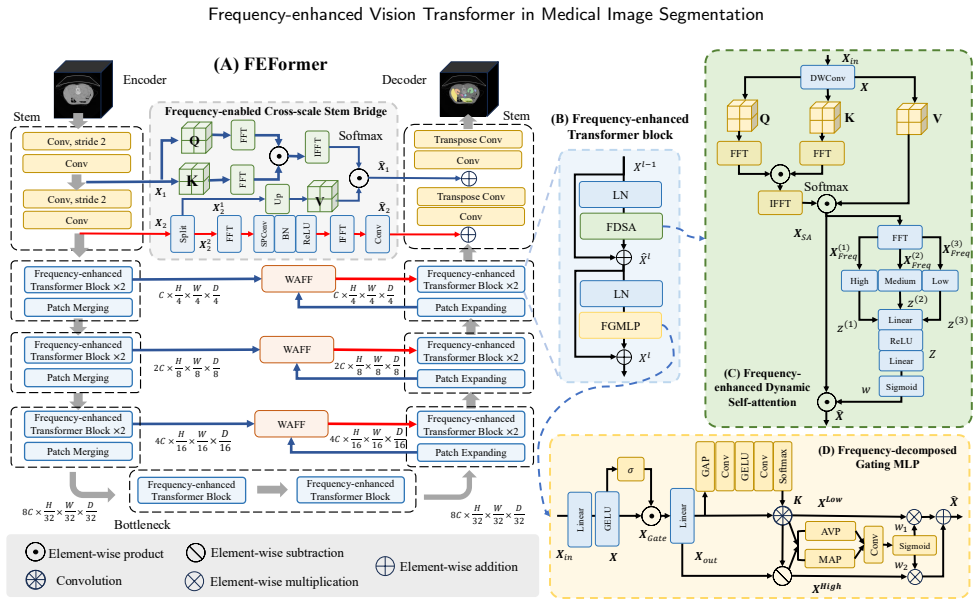
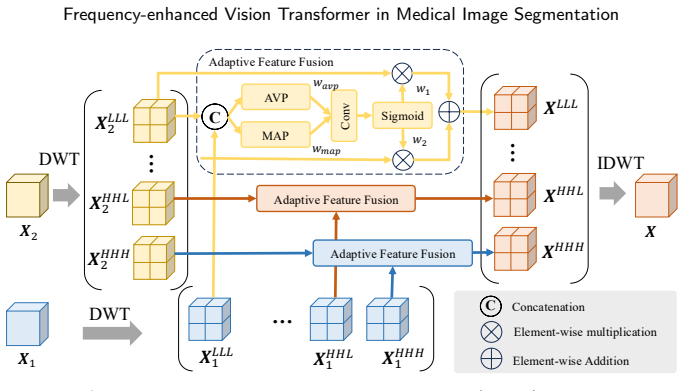
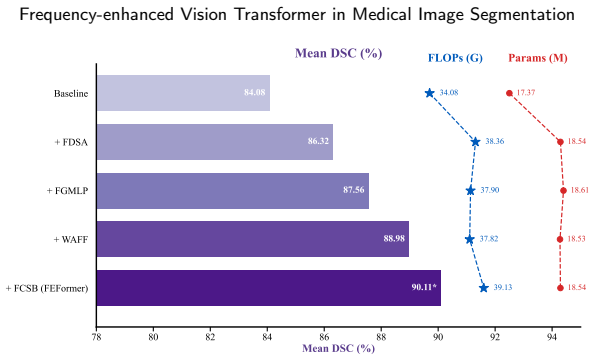
FEFormer jointly models global dependencies and fine-grained local features through frequency-enhanced components: FDSA uses locality-preserving convolution with frequency attention, FGMLP decomposes and gates low- and high-frequency signals, WAFF performs wavelet-guided adaptive fusion across encoder-decoder stages, and FCSB propagates low-level details via frequency-enabled cross-scale bridging. These mechanisms address the limitations of plain self-attention, spatial-agnostic MLPs, naive fusion, and missing low-level pathways, yielding improved segmentation accuracy and efficiency on volumetric data.
What carries the argument
The FEFormer architecture, whose four frequency-based modules (FDSA for attention, FGMLP for gating, WAFF for fusion, FCSB for bridging) explicitly process frequency information to preserve both global context and local structural details during encoding and decoding.
If this is right
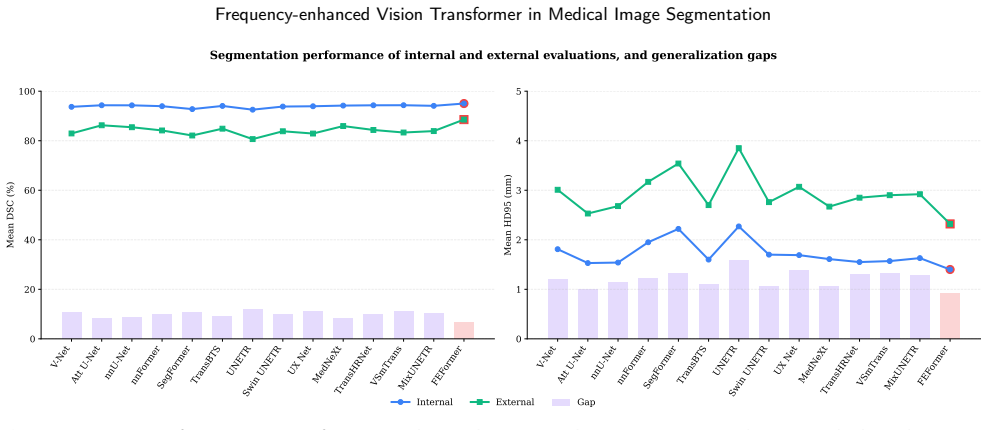
- Superior segmentation accuracy is obtained across four diverse volumetric medical tasks while maintaining lower computational cost than prior transformers.
- FDSA enables joint capture of fine local details and long-range dependencies inside the attention block.
- WAFF produces semantically consistent features when merging encoder and decoder representations.
- FGMLP and FCSB together improve representation of low- and high-frequency content and low-level information flow.
- The overall design supports generic knowledge extraction and adaptive fusion without task-specific redesign.
Where Pith is reading between the lines
- The frequency-centric design might transfer to other dense prediction tasks such as 3D object detection in medical volumes or non-medical volumetric data like seismic imaging.
- If the modules prove modular, they could be inserted into existing transformer backbones with minimal retraining to test gains on new datasets.
- Explicit frequency decomposition suggests possible extensions to multi-modal fusion where one modality supplies low-frequency priors.
- The efficiency claims imply the method could scale to higher-resolution scans or real-time clinical workflows once validated on larger cohorts.
Load-bearing premise
The four new modules actually overcome the stated shortcomings of ordinary Vision Transformers without needing extra derivations or detailed ablation evidence to confirm each one works as claimed.
What would settle it
If independent runs on the same four volumetric segmentation benchmarks show FEFormer matching or falling below current state-of-the-art accuracy or speed, or if ablating any single frequency module leaves performance unchanged, the central performance claim would not hold.
Figures

read the original abstract
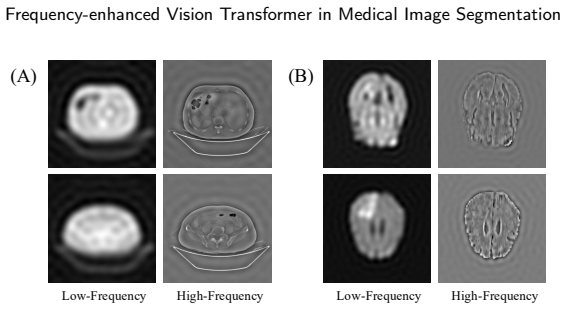
Accurate segmentation of organs and lesions in medical images is essential for clinical applications including diagnosis, prognosis, and treatment planning. While Vision Transformers (ViTs) have shown impressive segmentation performance, they face key challenges in module and architecture design. Specifically, self-attention struggles to capture fine-grained local features critical for understanding detailed anatomical structures, standard MLP modules lack explicit mechanisms to preserve spatial information, conventional encoder-decoder architectures rely on naive feature fusion strategies that cannot handle large semantic discrepancies, and existing designs lack explicit mechanisms to propagate low-level information from encoder to decoder. To address these limitations, we propose a Frequency-enhanced Vision Transformer (FEFormer) for robust and efficient volumetric medical image segmentation that explicitly models frequency information to jointly capture global context and fine structural details. FEFormer comprises four novel components: a Frequency-enhanced Dynamic Self-Attention (FDSA) module that jointly captures fine-grained local details and global long-range dependencies through locality-preserving convolution with frequency-domain attention; a Frequency-decomposed Gating MLP (FGMLP) that adaptively models low- and high-frequency components for enhanced semantic and structural representation; a Wavelet-guided Adaptive Feature Fusion (WAFF) module that enables semantically consistent encoder-decoder feature integration in the frequency domain; and a Frequency-enabled Cross-scale Stem Bridge (FCSB) that enhances low-level feature propagation across scales. Evaluated on four diverse volumetric medical image segmentation tasks, FEFormer achieved superior segmentation performance with high computational efficiency compared to state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FEFormer, a frequency-enhanced Vision Transformer for volumetric medical image segmentation. It introduces four modules—Frequency-enhanced Dynamic Self-Attention (FDSA) using locality-preserving convolution with frequency-domain attention, Frequency-decomposed Gating MLP (FGMLP) for adaptive low/high-frequency modeling, Wavelet-guided Adaptive Feature Fusion (WAFF) for semantically consistent encoder-decoder integration, and Frequency-enabled Cross-scale Stem Bridge (FCSB) for low-level feature propagation—to address limitations of standard ViTs in local feature capture and fusion. The work evaluates the model on four diverse volumetric segmentation tasks and claims superior performance alongside high computational efficiency versus state-of-the-art methods.
Significance. If the reported gains hold, the work offers a targeted advance in medical image segmentation by embedding explicit frequency-domain mechanisms into ViT designs, improving both fine-grained anatomical detail capture and encoder-decoder consistency while maintaining efficiency. Strengths include the concrete module definitions with frequency operations and the provision of quantitative efficiency metrics (FLOPs, parameters, inference time) alongside accuracy tables. This could inform subsequent architectures handling semantic gaps in volumetric tasks.
minor comments (4)
- §3.2 (FDSA module): the interaction between the convolution branch and frequency attention is described in text but would benefit from an explicit equation or pseudocode to clarify how locality is preserved while computing attention weights.
- Table 1 (main results): report standard deviations across runs or statistical significance tests for the Dice/HD95 improvements to strengthen the superiority claim over baselines.
- §4.3 (ablation study): the contribution of each module is shown via incremental addition, but the interaction effects between WAFF and FCSB are not isolated; a fuller factorial ablation would clarify independence.
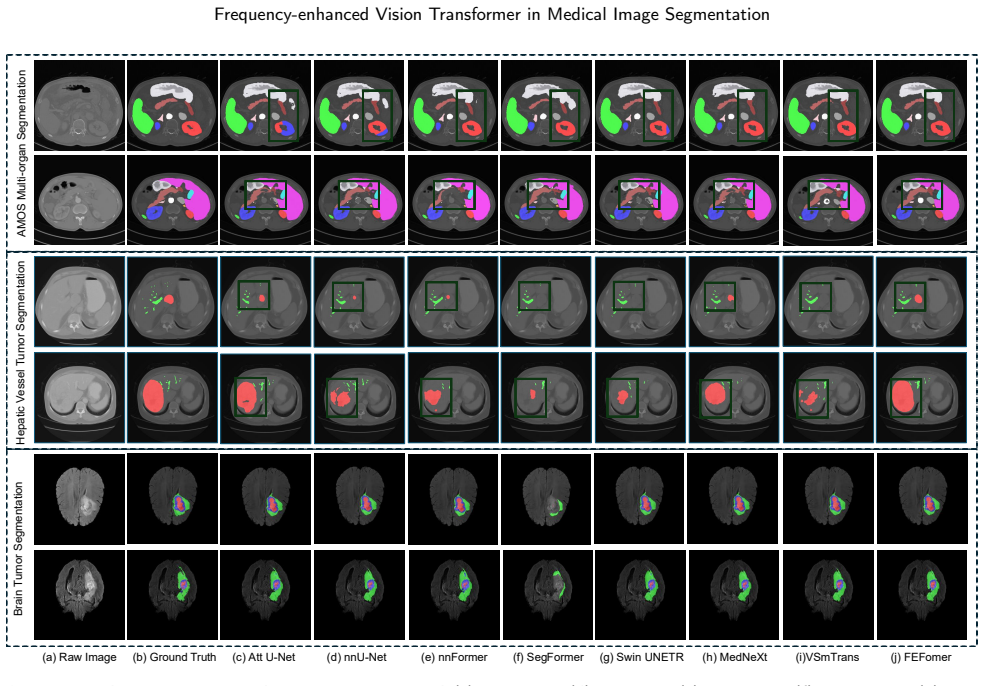
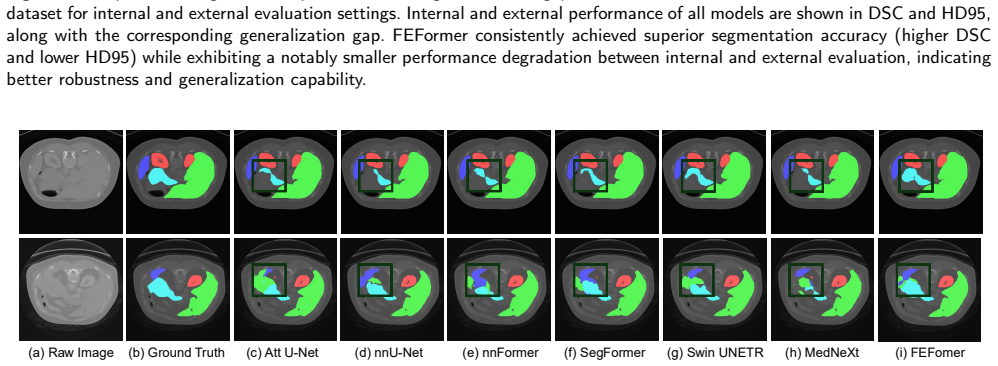
- Figure 3 (qualitative results): the caption and legend should explicitly state the color mapping for ground-truth versus prediction overlays to aid reader interpretation.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation for minor revision. The report accurately captures the core contributions of FEFormer, including the four frequency-aware modules and the evaluation across four volumetric tasks. No major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper describes an architectural proposal consisting of four frequency-enhanced modules (FDSA, FGMLP, WAFF, FCSB) to address stated limitations of standard ViTs. These modules are introduced via descriptive text in the abstract with no accompanying equations, derivations, or first-principles reductions. No predictions are claimed that reduce by construction to fitted inputs, no self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is presented as a derivation. The central claims rest on empirical segmentation performance across four tasks, which is independent of any internal definitional loop. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
invented entities (4)
-
Frequency-enhanced Dynamic Self-Attention (FDSA)
no independent evidence
-
Frequency-decomposed Gating MLP (FGMLP)
no independent evidence
-
Wavelet-guided Adaptive Feature Fusion (WAFF)
no independent evidence
-
Frequency-enabled Cross-scale Stem Bridge (FCSB)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearFDSA module that employs locality-preserving convolution with frequency-domain attention... frequency-domain self-attention mechanism... multi-frequency dynamic mechanism
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclearFGMLP... selective frequency decomposition mechanism... low-frequency and high-frequency components
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearWAFF... decomposes spatial features into multi-frequency components using the Discrete Wavelet Transform (DWT)
Reference graph
Works this paper leans on
-
[1]
Nature communications , volume=
Annotation-efficient deep learning for automatic medical image segmentation , author=. Nature communications , volume=. 2021 , publisher=
work page 2021
-
[2]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Medical image segmentation review: The success of u-net , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2024 , publisher=
work page 2024
-
[3]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
work page 2015
-
[4]
IEEE transactions on medical imaging , volume=
H-DenseUNet: hybrid densely connected UNet for liver and tumor segmentation from CT volumes , author=. IEEE transactions on medical imaging , volume=. 2018 , publisher=
work page 2018
-
[5]
Medical Imaging 2025: Computer-Aided Diagnosis , volume=
Dynamic U-Net: adaptively calibrate features for abdominal multiorgan segmentation , author=. Medical Imaging 2025: Computer-Aided Diagnosis , volume=. 2025 , organization=
work page 2025
-
[6]
D2-mlp: dynamic decomposed mlp mixer for medical image segmentation , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
work page 2025
-
[7]
Biomedical Signal Processing and Control , volume=
DMC-Net: Lightweight Dynamic Multi-scale and Multi-resolution convolution network for pancreas segmentation in CT images , author=. Biomedical Signal Processing and Control , volume=. 2025 , publisher=
work page 2025
-
[8]
arXiv preprint arXiv:2511.17873 , year=
TransLK-Net: Entangling Transformer and Large Kernel for Progressive and Collaborative Feature Encoding and Decoding in Medical Image Segmentation , author=. arXiv preprint arXiv:2511.17873 , year=
-
[9]
Biomedical Signal Processing and Control , volume=
D-net: Dynamic large kernel with dynamic feature fusion for volumetric medical image segmentation , author=. Biomedical Signal Processing and Control , volume=. 2026 , publisher=
work page 2026
-
[10]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[11]
Advances in Neural Information Processing Systems , volume=
Class-aware adversarial transformers for medical image segmentation , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
After-unet: Axial fusion transformer unet for medical image segmentation , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[13]
Physics in Medicine & Biology , volume=
CTA-UNet: CNN-transformer architecture UNet for dental CBCT images segmentation , author=. Physics in Medicine & Biology , volume=. 2023 , publisher=
work page 2023
-
[14]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
iSegFormer: interactive segmentation via transformers with application to 3D knee MR images , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2022 , organization=
work page 2022
-
[15]
Radiology: Artificial Intelligence , volume=
Optimizing performance of transformer-based models for fetal brain MR image segmentation , author=. Radiology: Artificial Intelligence , volume=. 2024 , publisher=
work page 2024
-
[16]
SwinCross: Cross-modal Swin transformer for head-and-neck tumor segmentation in PET/CT images , author=. Medical physics , volume=. 2024 , publisher=
work page 2024
-
[17]
Medical image analysis , volume=
FAT-Net: Feature adaptive transformers for automated skin lesion segmentation , author=. Medical image analysis , volume=. 2022 , publisher=
work page 2022
-
[18]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Adaptive template transformer for mitochondria segmentation in electron microscopy images , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[19]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Shunted self-attention via multi-scale token aggregation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[20]
IEEE Transactions on Image Processing , volume=
S2AFormer: Strip Self-Attention for Efficient Vision Transformer , author=. IEEE Transactions on Image Processing , volume=. 2025 , publisher=
work page 2025
-
[21]
Multi-scale convolutional attention frequency-enhanced transformer network for medical image segmentation , author=. Information Fusion , volume=. 2025 , publisher=
work page 2025
-
[22]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
PHA: Patch-wise high-frequency augmentation for transformer-based person re-identification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[23]
International conference on machine learning , pages=
Global context vision transformers , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[24]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Lightweight vision transformer with spatial and channel enhanced self-attention , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[25]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[26]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Low-resolution self-attention for semantic segmentation , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[27]
SU-RMT: Toward Bridging Semantic Representation and Structural Detail Modeling for Medical Image Segmentation , author=. Information Fusion , pages=. 2026 , publisher=
work page 2026
-
[28]
European conference on computer vision , pages=
Improving vision transformers by revisiting high-frequency components , author=. European conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[29]
The Fourteenth International Conference on Learning Representations , year=
GmNet: Revisiting Gating Mechanisms From A Frequency View , author=. The Fourteenth International Conference on Learning Representations , year=
-
[30]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Squeeze-and-excitation networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
ECA-Net: Efficient channel attention for deep convolutional neural networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[32]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Squeeze-and-attention networks for semantic segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[33]
International conference on medical image computing and computer-assisted intervention , pages=
3D U-Net: learning dense volumetric segmentation from sparse annotation , author=. International conference on medical image computing and computer-assisted intervention , pages=. 2016 , organization=
work page 2016
-
[34]
Expert Systems with Applications , volume=
MSM-UNet: a medical image segmentation method based on wavelet transform and multi-scale Mamba-UNet , author=. Expert Systems with Applications , volume=. 2025 , publisher=
work page 2025
-
[35]
X-UNet: A novel global context-aware collaborative fusion U-shaped network with progressive feature fusion of codec for medical image segmentation , author=. Neural Networks , pages=. 2025 , publisher=
work page 2025
-
[36]
Advances in neural information processing systems , volume=
Early convolutions help transformers see better , author=. Advances in neural information processing systems , volume=
-
[37]
Advances in Neural Information Processing Systems , volume=
Fast fourier convolution , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
Mixed transformer u-net for medical image segmentation , author=. ICASSP 2022-2022 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2022 , organization=
work page 2022
-
[39]
A lightweight convolution and vision transformer integrated model with multi-scale self-attention mechanism , author=. Neurocomputing , pages=. 2025 , publisher=
work page 2025
-
[40]
Biomedical Signal Processing and Control , volume=
Transformers in medical image segmentation: A review , author=. Biomedical Signal Processing and Control , volume=. 2023 , publisher=
work page 2023
-
[41]
European conference on computer vision , pages=
Swin-unet: Unet-like pure transformer for medical image segmentation , author=. European conference on computer vision , pages=. 2022 , organization=
work page 2022
-
[42]
IEEE Transactions on Medical Imaging , volume=
Missformer: An effective transformer for 2d medical image segmentation , author=. IEEE Transactions on Medical Imaging , volume=. 2022 , publisher=
work page 2022
-
[43]
IEEE Transactions on Instrumentation and Measurement , volume=
Ds-transunet: Dual swin transformer u-net for medical image segmentation , author=. IEEE Transactions on Instrumentation and Measurement , volume=. 2022 , publisher=
work page 2022
-
[44]
Medical transformer: Gated axial-attention for medical image segmentation , author=. Medical image computing and computer assisted intervention--MICCAI 2021: 24th international conference, Strasbourg, France, September 27--October 1, 2021, proceedings, part I 24 , pages=. 2021 , organization=
work page 2021
-
[45]
Ct-net: Asymmetric compound branch transformer for medical image segmentation , author=. Neural Networks , volume=. 2024 , publisher=
work page 2024
-
[46]
Biomedical Signal Processing and Control , volume=
SEAformer: Selective Edge Aggregation transformer for 2D medical image segmentation , author=. Biomedical Signal Processing and Control , volume=. 2025 , publisher=
work page 2025
-
[47]
Biomedical Signal Processing and Control , volume=
AgileFormer: Spatially agile and scalable transformer for medical image segmentation , author=. Biomedical Signal Processing and Control , volume=. 2026 , publisher=
work page 2026
-
[48]
2025 IEEE/CVF winter conference on applications of computer vision (WACV) , pages=
Spectformer: Frequency and attention is what you need in a vision transformer , author=. 2025 IEEE/CVF winter conference on applications of computer vision (WACV) , pages=. 2025 , organization=
work page 2025
- [49]
-
[50]
Efficient frequency feature aggregation transformer for image super-resolution , author=. Pattern Recognition , volume=. 2025 , publisher=
work page 2025
-
[51]
Holistic dynamic frequency transformer for image fusion and exposure correction , author=. Information Fusion , volume=. 2024 , publisher=
work page 2024
-
[52]
Proceedings of the 32nd ACM International Conference on Multimedia , pages=
Loformer: Local frequency transformer for image deblurring , author=. Proceedings of the 32nd ACM International Conference on Multimedia , pages=
-
[53]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Efficient frequency domain-based transformers for high-quality image deblurring , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[54]
DBFFT: Adversarial-robust dual-branch frequency domain feature fusion in vision transformers , author=. Information Fusion , volume=. 2024 , publisher=
work page 2024
-
[55]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Wnet: Audio-guided video object segmentation via wavelet-based cross-modal denoising networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[56]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Xnet: Wavelet-based low and high frequency fusion networks for fully-and semi-supervised semantic segmentation of biomedical images , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[57]
Knowledge-Based Systems , volume=
WCMamba: Enhancing high-resolution remote sensing image semantic segmentation with pyramid wavelet convolution and SS2D , author=. Knowledge-Based Systems , volume=. 2025 , publisher=
work page 2025
-
[58]
IEEE Transactions on Industrial Informatics , year=
WTCLIP: A Wavelet-Aware CLIP Framework for Boundary-Refined Weakly Supervised Semantic Segmentation , author=. IEEE Transactions on Industrial Informatics , year=
-
[59]
Frequency Domain-Enhanced Spectral-Spatial Fusion Transformer for Semantic Segmentation of Remote Sensing Images , author=. Information Fusion , pages=. 2026 , publisher=
work page 2026
-
[60]
Advances in neural information processing systems , volume=
Amos: A large-scale abdominal multi-organ benchmark for versatile medical image segmentation , author=. Advances in neural information processing systems , volume=
-
[61]
Nature communications , volume=
The medical segmentation decathlon , author=. Nature communications , volume=. 2022 , publisher=
work page 2022
-
[62]
Medical Image Analysis , volume=
Fast and low-GPU-memory abdomen CT organ segmentation: the flare challenge , author=. Medical Image Analysis , volume=. 2022 , publisher=
work page 2022
-
[63]
and Farag, Ayman and Turkbey, Evrim B
Roth, Holger R. and Farag, Ayman and Turkbey, Evrim B. and Lu, Le and Liu, Jiamin and Summers, Ronald M. , title =. 2016 , publisher =. doi:10.7937/K9/TCIA.2016.tNB1kqBU , url =
-
[64]
2016 fourth international conference on 3D vision (3DV) , pages=
V-net: Fully convolutional neural networks for volumetric medical image segmentation , author=. 2016 fourth international conference on 3D vision (3DV) , pages=. 2016 , organization=
work page 2016
-
[65]
nnU-Net: a self-configuring method for deep learning-based biomedical image segmentation , author=. Nature methods , volume=. 2021 , publisher=
work page 2021
-
[66]
Attention U-Net: Learning Where to Look for the Pancreas
Attention u-net: Learning where to look for the pancreas , author=. arXiv preprint arXiv:1804.03999 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Transbts: Multimodal brain tumor segmentation using transformer , author=. Medical Image Computing and Computer Assisted Intervention--MICCAI 2021: 24th International Conference, Strasbourg, France, September 27--October 1, 2021, Proceedings, Part I 24 , pages=. 2021 , organization=
work page 2021
-
[68]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Unetr: Transformers for 3d medical image segmentation , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[69]
International MICCAI Brainlesion Workshop , pages=
Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images , author=. International MICCAI Brainlesion Workshop , pages=. 2021 , organization=
work page 2021
-
[70]
arXiv preprint arXiv:2209.15076 , year=
3d ux-net: A large kernel volumetric convnet modernizing hierarchical transformer for medical image segmentation , author=. arXiv preprint arXiv:2209.15076 , year=
-
[71]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Mednext: transformer-driven scaling of convnets for medical image segmentation , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2023 , organization=
work page 2023
-
[72]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[73]
IEEE Transactions on Image Processing , year=
nnformer: Volumetric medical image segmentation via a 3d transformer , author=. IEEE Transactions on Image Processing , year=
-
[74]
Medical Image Analysis , pages=
VSmTrans: A Hybrid Paradigm Integrating Self-attention and Convolution for 3D Medical Image Segmentation , author=. Medical Image Analysis , pages=. 2024 , publisher=
work page 2024
-
[75]
MixUNETR: A U-shaped network based on W-MSA and depth-wise convolution with channel and spatial interactions for zonal prostate segmentation in MRI , author=. Neural Networks , volume=. 2025 , publisher=
work page 2025
-
[76]
3D medical image segmentation using parallel transformers , author=. Pattern Recognition , volume=. 2023 , publisher=
work page 2023
-
[77]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Attentional feature fusion , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.