Recognition: 2 theorem links
· Lean TheoremLeveraging Multimodal Large Language Models for All-in-One Image Restoration via a Mixture of Frequency Experts
Pith reviewed 2026-05-14 21:20 UTC · model grok-4.3
The pith
Multimodal large language model embeddings guide a mixture of frequency experts to restore images from unknown mixed degradations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
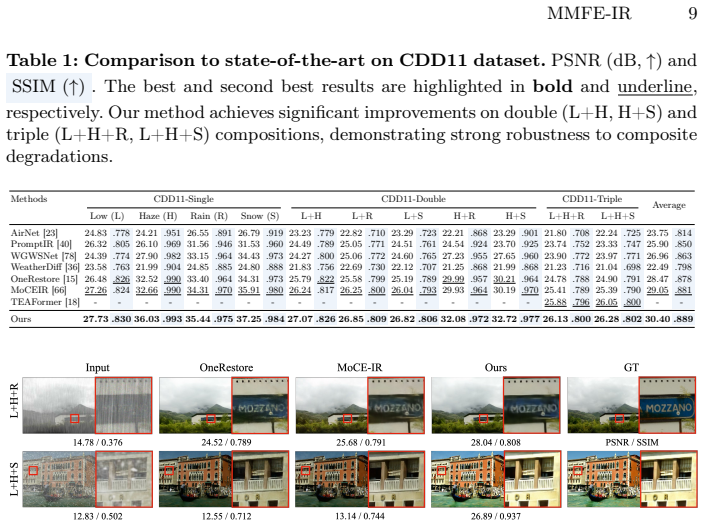
The central claim is that MLLM-derived multimodal embeddings, injected via an MLLM-guided fusion block and used to route a mixture-of-frequency-experts module through an MLLM-guided router with relational alignment loss, enable effective all-in-one restoration by capturing continuous relational structures among degradations, yielding strong performance on multiple benchmarks and a new state of the art on the CDD11 dataset with gains up to 1.35 dB.
What carries the argument
The mixture-of-frequency-experts (MoFE) module that adaptively combines frequency experts using MLLM-guided contextual cues together with a relational alignment loss.
If this is right
- The framework models continuous relational structures among degradations instead of treating them as discrete categories.
- MLLM features enhance degradation-aware representations inside the encoder-decoder via the fusion block.
- The relational alignment loss produces routing decisions consistent with embedding-space relationships of degraded inputs.
- The method reaches new state-of-the-art results on the CDD11 dataset, outperforming earlier techniques by as much as 1.35 dB.
- It delivers competitive results across multiple standard restoration benchmarks without task-specific retraining.
Where Pith is reading between the lines
- The same MLLM routing principle could be tested on video sequences where temporal consistency adds another continuous degradation dimension.
- If MLLM embeddings prove robust, similar multimodal guidance might simplify pipelines in related tasks such as blind denoising or low-light enhancement.
- Hybrid networks that combine the frequency experts with spatial attention layers could be explored to handle degradations that are only partially frequency-localized.
- Deployment on edge devices might benefit from distilling the MLLM router into a lighter model while retaining the performance gains on mixed degradations.
Load-bearing premise
That MLLM-derived embeddings supply reliable guidance for low-level restoration when fused and used for expert routing without introducing artifacts or overfitting to the language model's training distribution.
What would settle it
A test in which the MLLM embeddings are replaced by random vectors or non-semantic features and the method's performance on the CDD11 dataset falls below that of prior non-MLLM approaches.
Figures








read the original abstract
All-in-one image restoration seeks to recover clean images from inputs affected by diverse and unknown degradations using a unified framework. Recent methods have shown strong performance by identifying degradation characteristics to guide the restoration process. However, many of them treat degradations as discrete categories, which limits their ability to model the continuous relational structure that arises in composite degradations. To address this issue, we propose a multimodal large language model (MLLM)-guided image restoration framework that exploits multimodal embeddings as guidance for low-level restoration. Specifically, MLLM-derived features are injected into an encoder-decoder architecture through an MLLM-guided fusion block (MGFB) to enhance degradation-aware representations. In addition, we incorporate a mixture-of-frequency-experts (MoFE) module that adaptively combines frequency experts using MLLM-guided contextual cues. To further improve expert routing, we design an MLLM-guided router with a relational alignment loss that encourages routing patterns consistent with the embedding-space relationships of degraded inputs. Extensive experiments on multiple benchmarks show that the proposed method achieves strong performance across diverse restoration settings and establishes a new state of the art on the challenging CDD11 dataset, outperforming previous methods by up to 1.35 dB.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an all-in-one image restoration framework that injects MLLM-derived embeddings into an encoder-decoder via an MLLM-guided fusion block (MGFB) and routes a mixture-of-frequency-experts (MoFE) module using an MLLM-guided router with a relational alignment loss. The central claim is that this architecture better models continuous relational structures among composite degradations than discrete-category methods, achieving strong results across benchmarks and new state-of-the-art performance on the CDD11 dataset with gains of up to 1.35 dB.
Significance. If the MLLM embeddings reliably supply degradation-specific rather than semantic cues to drive MoFE routing, the approach would offer a principled way to handle continuous degradation relations in a unified model, potentially improving robustness on real-world composite degradations beyond current frequency-decomposition baselines.
major comments (2)
- [Abstract and Experiments] The 1.35 dB SOTA claim on CDD11 (abstract) rests on the assumption that MLLM embeddings injected through MGFB and used by the relational-alignment router produce degradation-aware routing decisions. No analysis is provided showing that router selections correlate with measurable degradation parameters (noise variance, blur kernel size) rather than semantic content clusters; without this, the gains cannot be confidently attributed to the proposed MGFB/MoFE components.
- [Method (MoFE and router)] The relational alignment loss is described as enforcing consistency with embedding-space relationships, yet the manuscript supplies no ablation isolating its contribution to routing accuracy or any quantitative check that routing decisions align with degradation type rather than scene semantics.
minor comments (1)
- [Abstract] The abstract states 'extensive experiments' and 'strong performance' but omits any mention of specific baselines, error bars, or ablation studies supporting the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the need for stronger empirical validation of the degradation-aware behavior in our MLLM-guided framework. We address each major comment below and will revise the manuscript accordingly to include the requested analyses.
read point-by-point responses
-
Referee: [Abstract and Experiments] The 1.35 dB SOTA claim on CDD11 (abstract) rests on the assumption that MLLM embeddings injected through MGFB and used by the relational-alignment router produce degradation-aware routing decisions. No analysis is provided showing that router selections correlate with measurable degradation parameters (noise variance, blur kernel size) rather than semantic content clusters; without this, the gains cannot be confidently attributed to the proposed MGFB/MoFE components.
Authors: We agree that explicit validation is required to attribute the gains specifically to degradation-aware routing. In the revised manuscript, we will add a dedicated analysis subsection using controlled synthetic data where semantic content is held constant while varying degradation parameters (noise variance, blur kernel size). This will include plots of router selection probabilities versus these parameters, along with correlation coefficients, to demonstrate that routing decisions align with degradation characteristics rather than semantic clusters. These additions will directly support the 1.35 dB claim on CDD11. revision: yes
-
Referee: [Method (MoFE and router)] The relational alignment loss is described as enforcing consistency with embedding-space relationships, yet the manuscript supplies no ablation isolating its contribution to routing accuracy or any quantitative check that routing decisions align with degradation type rather than scene semantics.
Authors: We acknowledge the absence of these ablations in the current version. The revised manuscript will include an ablation study comparing the full model against a variant without the relational alignment loss, reporting impacts on both restoration metrics (PSNR/SSIM) and routing metrics (e.g., alignment accuracy with degradation labels). We will also add quantitative checks such as mutual information scores between routing decisions and degradation parameters versus semantic labels on benchmark data. This will isolate the loss's contribution and confirm degradation-type alignment. revision: yes
Circularity Check
No circularity: empirical architectural proposal with independent validation
full rationale
The paper introduces an MLLM-guided encoder-decoder with MGFB injection, MoFE routing, and a relational alignment loss as design choices. These components are motivated by the goal of handling continuous degradations and are evaluated directly on external benchmarks (including CDD11) via standard PSNR/SSIM metrics. No equations, losses, or routing mechanisms are defined in terms of the target performance quantities, nor do any predictions reduce to fitted inputs by construction. Self-citations, if present, are not load-bearing for the central claims, which rest on reproducible experimental comparisons rather than self-referential derivations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MLLM embeddings capture useful degradation characteristics for low-level restoration
invented entities (3)
-
MLLM-guided fusion block (MGFB)
no independent evidence
-
mixture-of-frequency-experts (MoFE)
no independent evidence
-
MLLM-guided router
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a mixture-of-frequency-experts (MoFE) module that adaptively combines frequency experts using MLLM-guided contextual cues... router... relational alignment loss LMGL = ||Sim(EAnswer) - Sim(S)||1
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MLLM-guided fusion block (MGFB) ... cross-attention ... EImage to encoder, EJoint to decoder
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ai, Y., Huang, H., Zhou, X., Wang, J., He, R.: Multimodal prompt perceiver: Empower adaptiveness generalizability and fidelity for all-in-one image restoration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 25432–25444 (2024)
work page 2024
-
[3]
Ad- vances in Neural Information Processing Systems37, 55443–55469 (2024)
Ai, Y., Zhou, X., Huang, H., Han, X., Chen, Z., You, Q., Yang, H.: Dreamclear: High-capacity real-world image restoration with privacy-safe dataset curation. Ad- vances in Neural Information Processing Systems37, 55443–55469 (2024)
work page 2024
-
[4]
Arbeláez, P., Maire, M., Fowlkes, C., Malik, J.: Contour detection and hierarchical image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelli- gence33(5), 898–916 (2011).https://doi.org/10.1109/TPAMI.2010.161
-
[5]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Bhagwatkar, R., Nayak, S., Bashivan, P., Rish, I.: Improving adversarial robustness in vision-language models with architecture and prompt design. In: Al-Onaizan, Y., Bansal, M., Chen, Y.N. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 17003–17020. Association for Computational Lin- guistics, Miami, Florida, USA (Nov 20...
-
[7]
Advances in Neural Information Processing Systems37, 110643– 110666 (2024)
Chen, H., Li, W., Gu, J., Ren, J., Chen, S., Ye, T., Pei, R., Zhou, K., Song, F., Zhu, L.: Restoreagent: Autonomous image restoration agent via multimodal large language models. Advances in Neural Information Processing Systems37, 110643– 110666 (2024)
work page 2024
-
[8]
In: European conference on computer vision
Chen, L., Chu, X., Zhang, X., Sun, J.: Simple baselines for image restoration. In: European conference on computer vision. pp. 17–33. Springer (2022)
work page 2022
-
[9]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., et al.: Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24185–24198 (2024) 16 Eunho Lee et al
work page 2024
-
[10]
In: European Conference on Computer Vision
Conde, M.V., Geigle, G., Timofte, R.: Instructir: High-quality image restoration following human instructions. In: European Conference on Computer Vision. pp. 1–21. Springer (2024)
work page 2024
-
[11]
In: 13th Inter- national Conference on Learning Representations, ICLR 2025
Cui, Y., Zamir, S.W., Khan, S., Knoll, A., Shah, M., Khan, F.S.: Adair: Adaptive all-in-one image restoration via frequency mining and modulation. In: 13th Inter- national Conference on Learning Representations, ICLR 2025. pp. 57335–57356. International Conference on Learning Representations, ICLR (2025)
work page 2025
-
[12]
In: European Conference on Computer Vision
Duan, H., Min, X., Wu, S., Shen, W., Zhai, G.: Uniprocessor: a text-induced unified low-level image processor. In: European Conference on Computer Vision. pp. 180–
-
[13]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gao, X., Qiu, T., Zhang, X., Bai, H., Liu, K., Huang, X., Wei, H., Zhang, G., Liu, H.: Efficient multi-scale network with learnable discrete wavelet transform for blind motion deblurring. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2733–2742 (2024)
work page 2024
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guo, S., Yan, Z., Zhang, K., Zuo, W., Zhang, L.: Toward convolutional blind denoising of real photographs. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1712–1722 (2019)
work page 2019
-
[16]
In: European conference on com- puter vision
Guo, Y., Gao, Y., Lu, Y., Zhu, H., Liu, R.W., He, S.: Onerestore: A universal restoration framework for composite degradation. In: European conference on com- puter vision. pp. 255–272. Springer (2024)
work page 2024
-
[17]
CoRRabs/2407.13181(2024),https://doi.org/10.48550/arXiv.2407.13181
He, X., Li, L., Wang, Y., Zheng, H., Cao, K., Yan, K., Li, R., Xie, C., Zhang, J., Zhou, M.: Training-free large model priors for multiple-in-one image restoration. CoRRabs/2407.13181(2024),https://doi.org/10.48550/arXiv.2407.13181
-
[18]
arXiv preprint arXiv:2506.18520 (2025)
Hu, J., Yao, Z., Jin, L., He, H., Lu, Y.: Enhancing image restoration transformer via adaptive translation equivariance. arXiv preprint arXiv:2506.18520 (2025)
-
[19]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Jiang, K., Wang, Z., Yi, P., Chen, C., Huang, B., Luo, Y., Ma, J., Jiang, J.: Multi- scale progressive fusion network for single image deraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8346–8355 (2020)
work page 2020
-
[20]
In: European Conference on Computer Vision
Jiang, Y., Zhang, Z., Xue, T., Gu, J.: Autodir: Automatic all-in-one image restora- tion with latent diffusion. In: European Conference on Computer Vision. pp. 340–
-
[21]
International Confer- ence on Learning Representations (2015)
Kingma, D.P.: Adam: A method for stochastic optimization. International Confer- ence on Learning Representations (2015)
work page 2015
-
[22]
IEEE transactions on image processing28(1), 492–505 (2018)
Li, B., Ren, W., Fu, D., Tao, D., Feng, D., Zeng, W., Wang, Z.: Benchmarking single-image dehazing and beyond. IEEE transactions on image processing28(1), 492–505 (2018)
work page 2018
-
[23]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, B., Liu, X., Hu, P., Wu, Z., Lv, J., Peng, X.: All-in-one image restoration for unknown corruption. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17452–17462 (2022)
work page 2022
-
[24]
In: International conference on machine learning
Li, J., Li, D., Savarese, S., Hoi, S.: Blip-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. In: International conference on machine learning. pp. 19730–19742. PMLR (2023)
work page 2023
-
[25]
In: International confer- ence on machine learning
Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International confer- ence on machine learning. pp. 12888–12900. PMLR (2022)
work page 2022
-
[26]
arXiv preprint arXiv:2312.05038 (2023) MMFE-IR 17
Li,Z.,Lei,Y.,Ma,C.,Zhang,J.,Shan,H.:Prompt-in-promptlearningforuniversal image restoration. arXiv preprint arXiv:2312.05038 (2023) MMFE-IR 17
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liang, J., Cao, J., Sun, G., Zhang, K., Van Gool, L., Timofte, R.: Swinir: Image restoration using swin transformer. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 1833–1844 (2021)
work page 2021
-
[28]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tun- ing. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 26296–26306 (2024)
work page 2024
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, X., Suganuma, M., Sun, Z., Okatani, T.: Dual residual networks leveraging the potential of paired operations for image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7007–7016 (2019)
work page 2019
-
[30]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Y., Lu, Y., Liu, H., An, Y., Xu, Z., Yao, Z., Zhang, B., Xiong, Z., Gui, C.: Hierarchical prompt learning for multi-task learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10888– 10898 (2023)
work page 2023
-
[31]
In: International Conference on Learning Representations (2024)
Luo, Z., Gustafsson, F.K., Zhao, Z., Sjölund, J., Schön, T.B.: Controlling vision- language models for multi-task image restoration. In: International Conference on Learning Representations (2024)
work page 2024
-
[32]
IEEE Transactions on Image Processing26(2), 1004–1016 (2017).https://doi.org/10
Ma, K., Duanmu, Z., Wu, Q., Wang, Z., Yong, H., Li, H., Zhang, L.: Waterloo exploration database: New challenges for image quality assessment models. IEEE Transactions on Image Processing26(2), 1004–1016 (2017).https://doi.org/10. 1109/TIP.2016.2631888
-
[33]
In: Proceedings Eighth IEEE International Confer- ence on Computer Vision
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natu- ral images and its application to evaluating segmentation algorithms and mea- suring ecological statistics. In: Proceedings Eighth IEEE International Confer- ence on Computer Vision. ICCV 2001. vol. 2, pp. 416–423 vol.2 (2001).https: //doi.org/10.1109/ICCV.2001.937655
-
[34]
In: Proceedings of the AAAI conference on artificial intelligence
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 4296–4304 (2024)
work page 2024
-
[35]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Nah, S., Hyun Kim, T., Mu Lee, K.: Deep multi-scale convolutional neural network for dynamic scene deblurring. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3883–3891 (2017)
work page 2017
-
[36]
IEEE transactions on pattern analysis and machine intelligence45(8), 10346–10357 (2023)
Özdenizci, O., Legenstein, R.: Restoring vision in adverse weather conditions with patch-based denoising diffusion models. IEEE transactions on pattern analysis and machine intelligence45(8), 10346–10357 (2023)
work page 2023
-
[37]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Park, D., Lee, B.H., Chun, S.Y.: All-in-one image restoration for unknown degra- dations using adaptive discriminative filters for specific degradations. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 5815–5824. IEEE (2023)
work page 2023
-
[38]
Park, N., Kim, S.: How do vision transformers work? In: International Confer- ence on Learning Representations (2022),https://openreview.net/forum?id= D78Go4hVcxO
work page 2022
-
[39]
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=FjNys5c7VyY
work page 2023
-
[40]
Advances in Neural Information Processing Systems36, 71275–71293 (2023) 18 Eunho Lee et al
Potlapalli, V., Zamir, S.W., Khan, S.H., Shahbaz Khan, F.: Promptir: Prompt- ing for all-in-one image restoration. Advances in Neural Information Processing Systems36, 71275–71293 (2023) 18 Eunho Lee et al
work page 2023
-
[41]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
work page 2021
-
[42]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Rao, Y., Zhao, W., Chen, G., Tang, Y., Zhu, Z., Huang, G., Zhou, J., Lu, J.: Denseclip: Language-guided dense prediction with context-aware prompting. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 18082–18091 (2022)
work page 2022
-
[43]
Reimers, N., Gurevych, I.: Sentence-bert: Sentence embeddings using siamese bert- networks. In: Proceedings of the 2019 Conference on Empirical Methods in Nat- ural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). p. 3982. Association for Computational Linguistics (2019)
work page 2019
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ren, D., Zuo, W., Hu, Q., Zhu, P., Meng, D.: Progressive image deraining networks: A better and simpler baseline. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3937–3946 (2019)
work page 2019
-
[45]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Ren, W., Ma, L., Zhang, J., Pan, J., Cao, X., Liu, W., Yang, M.H.: Gated fusion network for single image dehazing. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3253–3261 (2018)
work page 2018
-
[46]
International Journal of Computer Vision128(1), 240–259 (2020)
Ren, W., Pan, J., Zhang, H., Cao, X., Yang, M.H.: Single image dehazing via multi- scale convolutional neural networks with holistic edges. International Journal of Computer Vision128(1), 240–259 (2020)
work page 2020
-
[47]
In: European Conference on Computer Vision
Ren, Y., Li, Y., Kong, A.W.K.: Adaptive multi-task learning for few-shot object detection. In: European Conference on Computer Vision. pp. 297–314. Springer (2024)
work page 2024
-
[48]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
work page 2022
-
[49]
Advances in neural information processing systems35, 25278–25294 (2022)
Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al.: Laion-5b: An open large- scale dataset for training next generation image-text models. Advances in neural information processing systems35, 25278–25294 (2022)
work page 2022
-
[50]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Tian, X., Liao, X., Liu, X., Li, M., Ren, C.: Degradation-aware feature perturba- tion for all-in-one image restoration. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 28165–28175 (2025)
work page 2025
-
[51]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Valanarasu, J.M.J., Yasarla, R., Patel, V.M.: Transweather: Transformer-based restoration of images degraded by adverse weather conditions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2353– 2363 (2022)
work page 2022
-
[52]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Vasu, P.K.A., Faghri, F., Li, C.L., Koc, C., True, N., Antony, A., Santhanam, G., Gabriel, J., Grasch, P., Tuzel, O., et al.: Fastvlm: Efficient vision encoding for vision language models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 19769–19780 (2025)
work page 2025
-
[53]
Ad- vances in Neural Information Processing Systems36, 8898–8912 (2023)
Wang, C., Pan, J., Wang, W., Dong, J., Wang, M., Ju, Y., Chen, J.: Promptre- storer: A prompting image restoration method with degradation perception. Ad- vances in Neural Information Processing Systems36, 8898–8912 (2023)
work page 2023
-
[54]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, M., Xing, J., Jiang, B., Chen, J., Mei, J., Zuo, X., Dai, G., Wang, J., Liu, Y.: A multimodal, multi-task adapting framework for video action recognition. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 5517– 5525 (2024) MMFE-IR 19
work page 2024
-
[55]
In: International Conference on Learning Representations (2022)
Wang, P., Zheng, W., Chen, T., Wang, Z.: Anti-oversmoothing in deep vision trans- formers via the fourier domain analysis: From theory to practice. In: International Conference on Learning Representations (2022)
work page 2022
-
[56]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., Fan, Y., Dang, K., Du, M., Ren, X., Men, R., Liu, D., Zhou, C., Zhou, J., Lin, J.: Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution. CoRRabs/2409.12191(2024),https://doi.org/10.48550/ arXiv.2409.12191
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
International journal of computer vision 132(10), 4541–4563 (2024)
Wang, T., Zhang, K., Shao, Z., Luo, W., Stenger, B., Lu, T., Kim, T.K., Liu, W., Li, H.: Gridformer: Residual dense transformer with grid structure for image restoration in adverse weather conditions. International journal of computer vision 132(10), 4541–4563 (2024)
work page 2024
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Lu, Y., Li, Q., Tao, X., Guo, Y., Gong, M., Liu, T.: Cris: Clip-driven referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11686–11695 (2022)
work page 2022
-
[59]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Cun, X., Bao, J., Zhou, W., Liu, J., Li, H.: Uformer: A general u-shaped transformer for image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17683–17693 (2022)
work page 2022
-
[60]
Deep Retinex Decomposition for Low-Light Enhancement
Wei, C., Wang, W., Yang, W., Liu, J.: Deep retinex decomposition for low-light enhancement. arXiv preprint arXiv:1808.04560 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[61]
Xiao, J., Fu, X., Liu, A., Wu, F., Zha, Z.J.: Image de-raining transformer. IEEE Transactions on Pattern Analysis and Machine Intelligence45(11), 12978–12995 (2023).https://doi.org/10.1109/TPAMI.2022.3183612
-
[62]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, F., Yang, H., Fu, J., Lu, H., Guo, B.: Learning texture transformer net- work for image super-resolution. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5791–5800 (2020)
work page 2020
-
[63]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, H., Pan, L., Yang, Y., Liang, W.: Language-driven all-in-one adverse weather removal. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24902–24912 (2024)
work page 2024
-
[64]
IEEE transactions on image processing (2024)
Yao, M., Xu, R., Guan, Y., Huang, J., Xiong, Z.: Neural degradation representation learning for all-in-one image restoration. IEEE transactions on image processing (2024)
work page 2024
-
[65]
arXiv preprint arXiv:2405.15475 (2024)
Zamfir, E., Wu, Z., Mehta, N., Paudel, D.P., Zhang, Y., Timofte, R.: Efficient degradation-aware any image restoration. arXiv preprint arXiv:2405.15475 (2024)
-
[66]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Zamfir, E., Wu, Z., Mehta, N., Tan, Y., Paudel, D.P., Zhang, Y., Timofte, R.: Com- plexity experts are task-discriminative learners for any image restoration. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 12753– 12763 (2025)
work page 2025
-
[67]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H.: Restormer: Efficient transformer for high-resolution image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5728–5739 (2022)
work page 2022
-
[68]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Cycleisp: Real image restoration via improved data synthesis. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2696– 2705 (2020)
work page 2020
-
[69]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Zamir, S.W., Arora, A., Khan, S., Hayat, M., Khan, F.S., Yang, M.H., Shao, L.: Multi-stage progressive image restoration. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 14821–14831 (2021) 20 Eunho Lee et al
work page 2021
-
[70]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zeng, H., Wang, X., Chen, Y., Su, J., Liu, J.: Vision-language gradient descent- driven all-in-one deep unfolding networks. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 7524–7533 (2025)
work page 2025
-
[71]
In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition
Zhang, H., Patel, V.M.: Densely connected pyramid dehazing network. In: Pro- ceedings of the IEEE conference on computer vision and pattern recognition. pp. 3194–3203 (2018)
work page 2018
-
[72]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, J., Huang, J., Yao, M., Yang, Z., Yu, H., Zhou, M., Zhao, F.: Ingredient- oriented multi-degradation learning for image restoration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5825–5835 (2023)
work page 2023
-
[73]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, K., Zuo, W., Gu, S., Zhang, L.: Learning deep cnn denoiser prior for image restoration. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3929–3938 (2017)
work page 2017
-
[74]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, K., Luo, W., Zhong, Y., Ma, L., Stenger, B., Liu, W., Li, H.: Deblurring by realistic blurring. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2737–2746 (2020)
work page 2020
-
[75]
Zhang, Y., Li, K., Li, K., Zhong, B., Fu, Y.: Residual non-local attention networks for image restoration. In: International Conference on Learning Representations (2019),https://openreview.net/forum?id=HkeGhoA5FX
work page 2019
-
[76]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition
Zhong, Y., Yang, J., Zhang, P., Li, C., Codella, N., Li, L.H., Zhou, L., Dai, X., Yuan, L., Li, Y., et al.: Regionclip: Region-based language-image pretraining. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 16793–16803 (2022)
work page 2022
-
[77]
Zhu, K., Gu, J., You, Z., Qiao, Y., Dong, C.: An intelligent agentic system for complex image restoration problems. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= 3RLxccFPHz
work page 2025
-
[78]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhu, Y., Wang, T., Fu, X., Yang, X., Guo, X., Dai, J., Qiao, Y., Hu, X.: Learning weather-general and weather-specific features for image restoration under multi- ple adverse weather conditions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21747–21758 (2023) MMFE-IR 21 Supplemental Material A Detailed Experime...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.