Recognition: no theorem link
Deep Minds and Shallow Probes
Pith reviewed 2026-05-13 02:15 UTC · model grok-4.3
The pith
Affine symmetries from equivalent realizations select a unique hierarchy of shallow probes, with linear probes as the base case.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Equivalent realizations induce affine changes of hidden coordinates. Requiring a probe family to be stable under this group action singles out a unique hierarchy of shallow coordinate-stable probes, with linear probes as its degree-1 member. A natural object for cross-model probe transfer is then the shared probe-visible quotient—the representation modulo directions invisible to the probe family—rather than the full hidden state.
What carries the argument
The group action of affine reparameterizations on hidden coordinates at the readout layer, which enforces coordinate-stability and selects the probe hierarchy.
If this is right
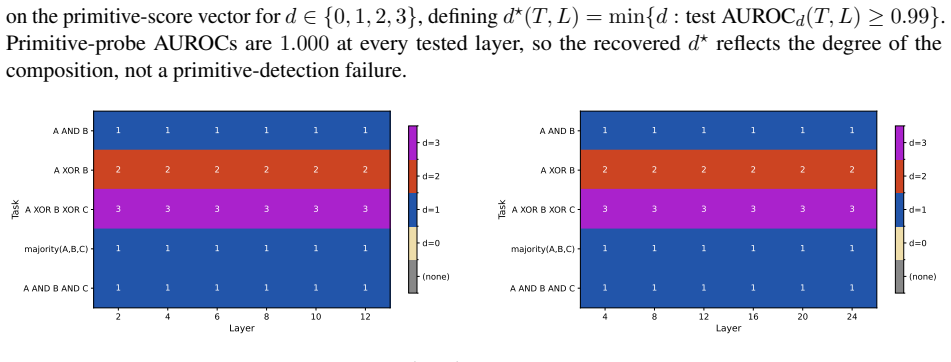
- Linear probes form the lowest level of a larger family of stable shallow probes.
- Degree-2 members of the hierarchy capture additional structure beyond what linear probes detect.
- Probe transfer should operate on the quotient modulo invisible directions to achieve coverage-aware portability.
- The same stability requirement yields monitors that transfer across different model families.
Where Pith is reading between the lines
- The symmetry analysis could be extended to intermediate layers if analogous group actions can be identified there.
- Quotient-based transfer may improve robustness when applying monitors trained on one architecture to another.
- The framework suggests that many existing probing techniques can be re-derived as special cases of symmetry-stable families.
Load-bearing premise
That affine coordinate changes from equivalent realizations are the only relevant symmetries and that probes intended to reveal existing structure must be invariant to them.
What would settle it
An experiment in which a probe family extracts reliable structure yet fails to be stable under affine reparameterizations, or in which full hidden-state transfer outperforms quotient-based transfer across models.
Figures

read the original abstract
Neural representations are not unique objects. Even when two systems realize the same downstream computation, their hidden coordinates may differ by reparameterization. A probe family intended to reveal structure already present in a representation should therefore be stable under the relevant representation symmetries rather than be tied to a particular basis. We study this group action in the tractable exact setting of the final readout layer, where equivalent realizations induce affine changes of hidden coordinates. The resulting symmetry principle singles out a unique hierarchy of shallow coordinate-stable probes, with linear probes as its degree-1 member. We also show that a natural object for cross-model probe transfer is a shared probe-visible quotient--the representation modulo directions invisible to the probe family--rather than the full hidden state. Experiments on synthetic and real-world tasks support both predictions, showing where degree-2 probes help beyond linear ones and how quotient-based transfer enables coverage-aware monitor portability across model families. These results point toward a broader geometric representation theory of neural probing, with coverage-aware monitor transfer as a concrete operational consequence.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that neural probes should be invariant under affine reparameterizations of hidden states that arise from equivalent realizations of the final readout layer. It claims this symmetry principle uniquely determines a hierarchy of shallow coordinate-stable probes (linear probes as the degree-1 member) and that a probe-visible quotient (representation modulo directions invisible to the probe family) is the appropriate object for cross-model probe transfer. Experiments on synthetic and real-world tasks are said to illustrate when degree-2 probes add value and how quotient-based transfer improves monitor portability.
Significance. If the uniqueness derivation holds without hidden restrictions on probe functional form, the work supplies a geometric rationale for the prevalence of linear probes and a concrete mechanism for coverage-aware transfer across model families. This could shift probing from empirical heuristics toward symmetry-based design, with the quotient construction offering a practical advance for interpretability and monitoring. The experiments provide initial support for both the hierarchy and the transfer claim.
major comments (2)
- [Abstract / §3 (Symmetry Principle)] Abstract and theoretical core: the claim that the symmetry principle 'singles out a unique hierarchy' requires an explicit statement of the probe function class (e.g., polynomials of bounded degree). Without a proof that no other families (non-polynomial or unbounded) satisfy the stability condition under the affine group action, uniqueness does not follow from the group action alone; the skeptic concern on functional-form restriction is load-bearing for the central claim.
- [§4 (Quotient and Transfer)] Probe-visible quotient construction: because the quotient is defined relative to the chosen probe family, the transfer claim inherits the same dependence on the hierarchy derivation. If the hierarchy is not uniquely fixed by symmetry, the quotient is likewise not canonical; this affects the cross-model portability result.
minor comments (2)
- [§3] Notation for the group action and stability condition should be introduced with a single running example (e.g., a two-layer readout) before the general case to improve readability.
- [§5] Experimental section should report the precise synthetic data-generating process and any controls for probe capacity or regularization that could confound the degree-1 vs. degree-2 comparison.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The comments highlight an important point about the scope of the uniqueness claim, which we address by clarifying the probe function class in the revision. We respond point by point below.
read point-by-point responses
-
Referee: [Abstract / §3 (Symmetry Principle)] Abstract and theoretical core: the claim that the symmetry principle 'singles out a unique hierarchy' requires an explicit statement of the probe function class (e.g., polynomials of bounded degree). Without a proof that no other families (non-polynomial or unbounded) satisfy the stability condition under the affine group action, uniqueness does not follow from the group action alone; the skeptic concern on functional-form restriction is load-bearing for the central claim.
Authors: We agree that an explicit statement of the function class is needed for the uniqueness claim to be precise. In the manuscript, shallow probes are implicitly the polynomial functions of bounded degree, as this is the natural class closed under affine reparameterizations that admits a grading by total degree (with linear probes as the degree-1 member). We will revise the abstract and §3 to state explicitly that the symmetry principle is applied to the vector space of polynomial probes of degree at most d, and briefly justify why this class is appropriate: affine transformations preserve polynomial degree, yielding a finite-dimensional representation in which the hierarchy of invariant subspaces is uniquely determined by representation theory of the affine group. Within this class the hierarchy is canonical; we do not claim uniqueness over all possible function families, as non-polynomial probes fall outside the shallow-probe setting studied here. revision: yes
-
Referee: [§4 (Quotient and Transfer)] Probe-visible quotient construction: because the quotient is defined relative to the chosen probe family, the transfer claim inherits the same dependence on the hierarchy derivation. If the hierarchy is not uniquely fixed by symmetry, the quotient is likewise not canonical; this affects the cross-model portability result.
Authors: We concur that the quotient construction is relative to the probe family. With the clarification in §3 that the family is the symmetry-selected hierarchy of polynomial probes of bounded degree, the quotient becomes the canonical object for that family. We will revise §4 to make this dependence explicit, stating that cross-model transfer is performed with respect to the same polynomial probe class on both models, and that the resulting quotient captures precisely the directions visible to the chosen probes. The experimental results on synthetic and real-world portability continue to demonstrate the practical benefit of this coverage-aware transfer within the stated class. revision: yes
Circularity Check
Symmetry principle derivation is self-contained without reduction to inputs by construction
full rationale
The paper starts from the group action of affine reparameterizations induced by equivalent readout realizations and derives a stability condition for probe families. This is used to identify a hierarchy whose degree-1 case is the linear probe and to motivate the probe-visible quotient. No equation or claim in the abstract or described chain defines the hierarchy in terms of itself, renames a fitted quantity as a prediction, or relies on a self-citation whose content is unverified. The uniqueness statement is presented as following from the symmetry principle applied to shallow probes; experiments are described as supporting rather than constituting the derivation. The central claims therefore remain independent of the paper's own fitted values or prior self-references.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Neural representations are not unique objects; equivalent downstream computations may differ by reparameterization of hidden coordinates.
- domain assumption A probe family intended to reveal structure already present should be stable under the relevant representation symmetries.
Reference graph
Works this paper leans on
-
[1]
Computational Linguistics , year =
Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances.Computational Linguis- tics, 48(1):207–219, March 2022. doi: 10.1162/coli_a_00422. URL https://aclanthology. org/2022.cl-1.7/
work page internal anchor Pith review doi:10.1162/coli_a_00422 2022
-
[2]
What you can cram into a single \ &!\#* vector:
Alexis Conneau, German Kruszewski, Guillaume Lample, Loïc Barrault, and Marco Baroni. What you can cram into a single $&!#* vector: Probing sentence embeddings for linguistic properties. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2126–2136, Melbourne, Australia, July 2018. Asso...
-
[3]
Designing and Interpreting Probes with Control Tasks
John Hewitt and Percy Liang. Designing and interpreting probes with control tasks. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors,Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2733–2743, Hong Kong, Chi...
-
[4]
Pareto probing: Trading off accuracy for complexity
Tiago Pimentel, Naomi Saphra, Adina Williams, and Ryan Cotterell. Pareto probing: Trading off accuracy for complexity. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 3138–3153, 2020
work page 2020
-
[5]
Information-Theoretic Probing for Linguistic Structure
Tiago Pimentel, Josef Valvoda, Rowan Hall Maudslay, Ran Zmigrod, Adina Williams, and Ryan Cotterell. Information-theoretic probing for linguistic structure. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4609–4622, Online, July 2020. ...
-
[6]
White, Tiago Pimentel, Naomi Saphra, and Ryan Cotterell
Jennifer C. White, Tiago Pimentel, Naomi Saphra, and Ryan Cotterell. A non-linear structural probe. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tur, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors,Proceedings of the 2021 Conference of the North American Chapter of the Association for Comp...
-
[7]
Tamara G. Kolda and Brett W. Bader. Tensor decompositions and applications.SIAM Review, 51(3): 455–500, 2009. doi: 10.1137/07070111X. URLhttps://doi.org/10.1137/07070111X
-
[8]
Scalable interpretability via polynomials
Abhimanyu Dubey, Filip Radenovic, and Dhruv Mahajan. Scalable interpretability via polynomials. InAdvances in Neural Information Processing Systems, volume 35, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ ee81a23d6b83ac15fbeb5b7a30934e0b-Abstract-Conference.html
work page 2022
-
[9]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024. URLhttps://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b.arXiv preprint arXiv:23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Characterization of polynomials by their invariance properties
José María Almira and Ya-Qing Hu. Characterization of polynomials by their invariance properties. Aequationes Mathematicae, 99:2725–2744, 2025. doi: 10.1007/s00010-025-01190-5. URL https: //doi.org/10.1007/s00010-025-01190-5
-
[12]
Understanding intermediate layers using linear classifier probes
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[13]
Liu, Matt Gardner, Yonatan Belinkov, Matthew E
Nelson F. Liu, Matt Gardner, Yonatan Belinkov, Matthew E. Peters, and Noah A. Smith. Linguistic knowledge and transferability of contextual representations. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 1073–1094, Min...
work page 2019
-
[14]
and Gardner, Matt and Belinkov, Yonatan and Peters, Matthew E
Association for Computational Linguistics. doi: 10.18653/v1/N19-1112. URL https:// aclanthology.org/N19-1112/. 12
-
[15]
BERT Rediscovers the Classical NLP Pipeline
Ian Tenney, Dipanjan Das, and Ellie Pavlick. BERT rediscovers the classical NLP pipeline. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4593– 4601, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1452. URLhttps://aclanthology.org/P19-1452/
-
[16]
InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Elena V oita and Ivan Titov. Information-theoretic probing with minimum description length. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 183–196, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/ 2020.emnlp-main.14. URLhttps://aclanthology.org/2020.emnlp-main.14/
-
[17]
John Hewitt and Christopher D. Manning. A structural probe for finding syntax in word representa- tions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, pages 4129–4138, 2019
work page 2019
-
[18]
Understanding image representations by measuring their equivariance and equivalence
Karel Lenc and Andrea Vedaldi. Understanding image representations by measuring their equivariance and equivalence. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 991–999, 2015
work page 2015
-
[19]
Revisiting model stitching to compare neural representations
Yamini Bansal, Preetum Nakkiran, and Boaz Barak. Revisiting model stitching to compare neural representations. InAdvances in Neural Information Processing Systems, volume 34, pages 225–236, 2021. URL https://proceedings.neurips.cc/paper/2021/hash/ 01ded4259d101feb739b06c399e9cd9c-Abstract.html
work page 2021
-
[20]
On the functional similarity of robust and non-robust neural representations
András Balogh and Márk Jelasity. On the functional similarity of robust and non-robust neural representations. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 1614–1635. PMLR, 2023. URL https: //proceedings.mlr.press/v202/balogh23a.html
work page 2023
-
[21]
Transferring linear features across language models with model stitching
Alan Chen, Jack Merullo, Alessandro Stolfo, and Ellie Pavlick. Transferring linear features across language models with model stitching. InAdvances in Neural Information Processing Systems 38 (NeurIPS 2025), 2025. URL https://openreview.net/forum?id=Qvvy0X63Fv. Spotlight; arXiv:2506.06609
-
[22]
How not to stitch representations to measure similarity: Task loss matching versus direct matching
Andras Balogh and Mark Jelasity. How not to stitch representations to measure similarity: Task loss matching versus direct matching. InProceedings of the AAAI Conference on Artificial Intelligence,
-
[23]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. Svcca: Sin- gular vector canonical correlation analysis for deep learning dynamics and interpretability. InAdvances in Neural Information Processing Systems 30, pages 6076–6085. Curran As- sociates, Inc., 2017. URL https://proceedings.neurips.cc/paper/2017/hash/ dc6a7e655d7e5840e6673...
work page 2017
-
[24]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3519–3529. PMLR, 2019. URL https://proceedings.mlr.press/v97/kornblith19a.html
work page 2019
-
[25]
Discovering latent knowledge in language models without supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. InThe Eleventh International Conference on Learning Representations,
-
[26]
URLhttps://openreview.net/forum?id=ETKGuby0hcs. 13
-
[27]
The internal state of an LLM knows when it ' s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.68. URL https: //aclanthology.org/2023.findings-emnlp.68/
-
[28]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InConference on Language Modeling (COLM), 2024. URLhttps://arxiv.org/abs/2310.06824
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Eliciting latent knowledge from quirky language models
Alex Mallen, Madeline Brumley, Julia Kharchenko, and Nora Belrose. Eliciting latent knowledge from quirky language models. InConference on Language Modeling (COLM), 2024. URL https: //arxiv.org/abs/2312.01037
-
[30]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023. URLhttps://arxiv.org/abs/2303.08112
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Juyeon Heo, Christina Heinze-Deml, Oussama Elachqar, Kwan Ho Ryan Chan, Shirley You Ren, Andrew Miller, Udhyakumar Nallasamy, and Jaya Narain. Do LLMs “know” internally when they follow instructions? InThe Thirteenth International Conference on Learning Representations, 2025. URLhttps://openreview.net/forum?id=qIN5VDdEOr
work page 2025
-
[32]
Beyond linear probes: Dynamic safety monitoring for language models
James Oldfield, Philip Torr, Ioannis Patras, Adel Bibi, and Fazl Barez. Beyond linear probes: Dynamic safety monitoring for language models. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=AGWa8whf92. Published as a conference paper at ICLR 2026
work page 2026
-
[33]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405, 2023. URL https://arxiv.org/ abs/2310.01405
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , shorttitle =
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems, volume 36, 2023. URLhttps://arxiv.org/abs/2306.03341
-
[35]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248, 2023. URLhttps://arxiv.org/abs/2308.10248
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Steering Llama 2 via Contrastive Activation Addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors, Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15504–15522, Bangkok, Thailand, Aug...
-
[37]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024), 2024. URLhttps://arxiv.org/abs/2406.11717
work page internal anchor Pith review arXiv 2024
-
[38]
Linear probe penalties reduce LLM sycophancy
Henry Papadatos and Rachel Freedman. Linear probe penalties reduce LLM sycophancy. InNeurIPS 2024 Workshop on Socially Responsible Language Modelling Research (SoLaR), 2024. URLhttps: //openreview.net/forum?id=6N2yES22rG. 14
work page 2024
-
[39]
Jérémy Scheurer, Mikita Balesni, and Marius Hobbhahn. Large language models can strategically deceive their users when put under pressure.arXiv preprint arXiv:2311.07590, 2023. URL https: //arxiv.org/abs/2311.07590
-
[40]
arXiv preprint arXiv:2503.10965 , year =
Samuel Marks, Johannes Treutlein, Trenton Bricken, Jack Lindsey, et al. Auditing language models for hidden objectives.arXiv preprint arXiv:2503.10965, 2025. URL https://arxiv.org/abs/ 2503.10965
-
[41]
Xianxuan Long, Yao Fu, Runchao Li, Mu Sheng, Haotian Yu, Xiaotian Han, and Pan Li. When truthful representations flip under deceptive instructions?arXiv preprint arXiv:2507.22149, 2025. URL https://arxiv.org/abs/2507.22149
-
[42]
Todor Markov, Chong Zhang, Sandhini Agarwal, Florentine Eloundou Nekoul, Theodore Lee, Steven Adler, Angela Jiang, and Lilian Weng. A holistic approach to undesired content detection in the real world.Proceedings of the AAAI Conference on Artificial Intelligence, 37(12):15009–15018, 2023. doi: 10.1609/aaai.v37i12.26752. URL https://ojs.aaai.org/index.php/...
-
[43]
OpenAI. GPT-4 system card, 2023. URL https://cdn.openai.com/papers/ gpt-4-system-card.pdf. OpenAI system card
work page 2023
-
[44]
OpenAI. GPT-4o system card, 2024. URL https://cdn.openai.com/ gpt-4o-system-card.pdf. OpenAI system card
work page 2024
-
[45]
Openai o3 and o4-mini system card, 2025
OpenAI. Openai o3 and o4-mini system card, 2025. URL https://cdn.openai.com/pdf/ 2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf . OpenAI system card
work page 2025
-
[46]
Mrinank Sharma, Meg Tong, Jesse Mu, Jerry Wei, et al. Constitutional classifiers: Defending against universal jailbreaks across thousands of hours of red teaming.arXiv preprint arXiv:2501.18837, 2025. URLhttps://arxiv.org/abs/2501.18837
-
[47]
Hoagy Cunningham, Jerry Wei, Zihan Wang, Andrew Persic, et al. Constitutional classifiers++: Efficient production-grade defenses against universal jailbreaks.arXiv preprint arXiv:2601.04603, 2026. URL https://arxiv.org/abs/2601.04603
-
[48]
Pythia: A suite for analyzing large language models across training and scaling
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar van der Wal. Pythia: A suite for analyzing large language models across training and scaling. InInternational Conference on Machine Le...
work page 2023
-
[49]
ToxicChat: Unveiling hidden challenges of toxicity detection in real-world user-AI conversation
Zi Lin, Zihan Wang, Yongqi Tong, Yangkun Wang, Yuxin Guo, Yujia Wang, and Jingbo Shang. ToxicChat: Unveiling hidden challenges of toxicity detection in real-world user-AI conversation. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Com- putational Linguistics: EMNLP 2023, pages 4694–4702, Singapore, December 2023. As...
-
[50]
BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset
Jiaming Ji, Mickel Liu, Juntao Dai, Xuehai Pan, Chi Zhang, Ce Bian, Boyuan Chen, Ruiyang Sun, Yizhou Wang, and Yaodong Yang. BeaverTails: Towards improved safety alignment of LLM via a human-preference dataset. InAdvances in Neural Information Processing Systems 36 (NeurIPS 2023) Datasets and Benchmarks Track, volume 36, 2023. 15
work page 2023
-
[51]
Manning, Andrew Ng, and Christopher Potts
Richard Socher, Alex Perelygin, Jean Wu, Jason Chuang, Christopher D. Manning, Andrew Ng, and Christopher Potts. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1631–1642, 2013
work page 2013
-
[52]
Bowman, Miriam Connor, John Bauer, and Christopher D
Natalia Silveira, Timothy Dozat, Marie-Catherine de Marneffe, Samuel R. Bowman, Miriam Connor, John Bauer, and Christopher D. Manning. A gold standard dependency corpus for English. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), pages 2897–2904. European Language Resources Association (ELRA), 2014. URL...
work page 2014
-
[53]
For each i∈ {1,2} , there exists a unique linear map Qi :H i → C ∗ satisfying Qi(v)(Ei(ℓ)) = ℓ(v)for allv∈H i and allℓ∈V i.In particular,Q i(hi(x)) = evx for allx∈X. 42
-
[54]
The kernel ofQ i is exactly the probe-invisible subspaceK(V i)
-
[55]
The induced map Qi :Z(V i) =H i/K(Vi)→ C ∗ is a linear isomorphism. Consequently the probe-visible quotients of the two models are canonically isomorphic to the same abstract space C∗. In particular, H1/K(V1) ∼= C∗ ∼= H2/K(V2). Because C is finite-dimensional, the canonical bidual identification also givesC ∼= (C∗)∗. Proof.Fixi∈ {1,2}. Because the concept...
-
[56]
4.Linear on raw concat:logistic regression on concatenated hidden states[h subj;h verb](2dfeatures)
Quadratic on scores:logistic regression on [ssubj ⊙s verb;s subj;s verb] where s are the 3 morphological- number probe scores (9 features). 4.Linear on raw concat:logistic regression on concatenated hidden states[h subj;h verb](2dfeatures). 5.Bilinear on raw:logistic regression on[h subj ⊙h verb;h subj;h verb](3dfeatures)
-
[57]
Quotient-level quadratic:project each hidden state through the quotient, then fit a quadratic on quotient coordinates. Table 18 shows that the quadratic head on probe scores (bacc = 0.863±0.007 ) outperforms the bilinear probe on raw hidden states, though these operate on different feature representations (5 pre-trained probe scores vs 3d raw dimensions) ...
-
[58]
Table 27: Effect of alignment-text domain on Qwen-7B → Qwen-3B zero-label transfer (AUROC)
Alignment text must cover the concept space.We tested whether domain-independent text suffices for alignment by using only SST-2 movie reviews (5K samples) instead of safety-relevant text. Table 27: Effect of alignment-text domain on Qwen-7B → Qwen-3B zero-label transfer (AUROC). SST-2 alignment transfers sentiment but fails on safety; safety-domain text ...
-
[59]
Alignment budget scaling.How many paired samples are needed for reliable alignment? We sweep alignment budget n from 100 to 76,000 for Qwen-7B →Qwen-3B transfer (mean AUROC over 5 concepts, 10 repeats per budget): Table 28: Alignment-budget scaling for Qwen-7B → Qwen-3B zero-label transfer. Cells are mean AUROC across five safety concepts (toxicity, jailb...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.