Recognition: no theorem link
Beyond Prediction: Interval Neural Networks for Uncertainty-Aware System Identification
Pith reviewed 2026-05-13 02:09 UTC · model grok-4.3
The pith
Interval neural networks produce calibrated prediction intervals for dynamical systems by propagating uncertainty through interval arithmetic without probabilistic assumptions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
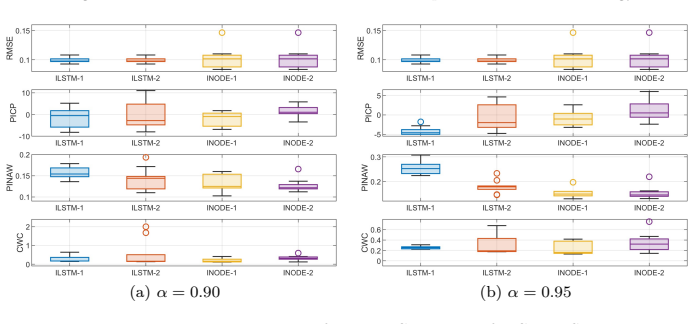
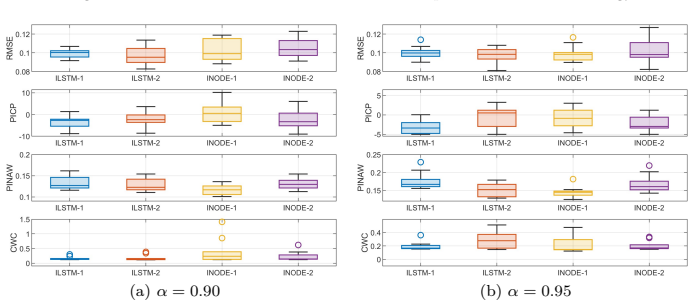
Extending crisp neural networks to interval counterparts via interval arithmetic in LSTM and NODE architectures, combined with uncertainty-aware loss functions and parameterization tricks, enables the models to output prediction intervals that represent model uncertainty for system identification tasks; the joint training strategy yields better-calibrated intervals while the cascade strategy preserves superior point predictions.
What carries the argument
Interval Neural Networks (INNs) that replace scalar operations with interval arithmetic in LSTM and NODE layers, trained via either Cascade INN (two-stage conversion from crisp NN) or Joint INN (one-stage joint optimization of accuracy and interval precision) using uncertainty-aware losses.
Load-bearing premise
That propagating uncertainty through interval arithmetic in these architectures, together with the proposed losses and tricks, will produce intervals that accurately reflect true model uncertainty rather than merely over- or under-bounding outputs.
What would settle it
On a standard SysID benchmark dataset, if the J-INN prediction intervals fail to cover the observed outputs at a rate matching the target coverage level or if C-INN point predictions do not exceed the accuracy of ordinary crisp networks, the central claims would be refuted.
Figures









read the original abstract
System identification (SysID) is critical for modeling dynamical systems from experimental data, yet traditional approaches often fail to capture nonlinear behaviors. While deep learning offers powerful tools for modeling such dynamics, incorporating uncertainty quantification is essential to ensure reliable predictions. This paper presents a systematic framework for constructing and training interval Neural Networks (INNs) for uncertainty-aware SysID. By extending crisp neural networks into interval counterparts, we develop Interval LSTM and NODE models that propagate uncertainty through interval arithmetic without probabilistic assumptions. This design allows them to represent uncertainty and produce prediction intervals. For training, we propose two strategies: Cascade INN (C-INN), a two-stage approach converting a trained crisp NN into an INN, and Joint INN (J-INN), a one-stage framework jointly optimizing prediction accuracy and interval precision. Both strategies employ uncertainty-aware loss functions and parameterization tricks to ensure reliable learning. Comprehensive experiments on multiple SysID datasets demonstrate the effectiveness of both approaches and benchmark their performance against well-established uncertainty-aware baselines: C-INN achieves superior point prediction accuracy, whereas J-INN yields more accurate and better-calibrated prediction intervals. Furthermore, to reveal how uncertainty is represented across model parameters, the concept of channel-wise elasticity is introduced, which is used to identify distinct patterns across the two training strategies. The results of this study demonstrate that the proposed framework effectively integrates deep learning with uncertainty-aware modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for Interval Neural Networks (INNs) for uncertainty-aware system identification, extending LSTM and Neural ODE architectures via interval arithmetic to generate prediction intervals without probabilistic assumptions. It introduces Cascade INN (C-INN), a two-stage method that first trains a crisp network then converts it, and Joint INN (J-INN), a one-stage joint optimization of accuracy and interval quality using uncertainty-aware losses and parameterization tricks. Experiments on multiple SysID datasets claim C-INN achieves superior point prediction accuracy while J-INN produces more accurate and better-calibrated intervals than baselines; a channel-wise elasticity metric is introduced to analyze uncertainty representation across parameters.
Significance. If validated, the work provides a practical non-probabilistic alternative for uncertainty quantification in deep dynamical models, useful for control and safety-critical applications where calibrated bounds matter. The distinction between C-INN and J-INN training strategies offers actionable guidance, and the elasticity metric adds interpretability value. Strengths include the use of interval arithmetic for direct propagation and benchmarking against established baselines, though empirical grounding is limited by missing protocol details.
major comments (3)
- [Methods (interval LSTM propagation) and Experiments (calibration results)] The claim that J-INN yields better-calibrated intervals (abstract and experimental results) rests on empirical coverage metrics, but the manuscript provides no analysis of the dependency problem in interval arithmetic when applied to recurrent LSTM structures; correlated hidden states are treated independently, which can cause exponential interval widening over sequence length and produce conservative rather than calibrated bounds. No formal bound or correction via the proposed losses or two-stage vs. one-stage training is shown.
- [Experiments section] Superiority claims for C-INN point accuracy and J-INN interval calibration lack error bars, full data splits, hyperparameter search details, and ablation on the uncertainty-aware losses/parameterization tricks. Without these, it is impossible to rule out post-hoc selection or overfitting to the specific SysID datasets, undermining the central benchmarking conclusions.
- [Section introducing channel-wise elasticity] The channel-wise elasticity metric is introduced to reveal uncertainty patterns, but its definition and computation are not shown to be independent of the interval widths produced by the arithmetic; if elasticity is derived directly from the same interval outputs, it risks being tautological rather than providing new insight into model uncertainty.
minor comments (2)
- Notation for interval bounds (e.g., lower/upper) should be standardized across equations and figures for clarity.
- [Experiments] The abstract mentions 'well-established uncertainty-aware baselines' but the manuscript should explicitly list them with citations in the experimental setup.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with honest clarifications and indicate where revisions will be made to improve the manuscript.
read point-by-point responses
-
Referee: [Methods (interval LSTM propagation) and Experiments (calibration results)] The claim that J-INN yields better-calibrated intervals (abstract and experimental results) rests on empirical coverage metrics, but the manuscript provides no analysis of the dependency problem in interval arithmetic when applied to recurrent LSTM structures; correlated hidden states are treated independently, which can cause exponential interval widening over sequence length and produce conservative rather than calibrated bounds. No formal bound or correction via the proposed losses or two-stage vs. one-stage training is shown.
Authors: We acknowledge the dependency problem in interval arithmetic for recurrent models as a known challenge, where independent treatment of correlated states can lead to interval overestimation. The J-INN joint optimization with uncertainty-aware losses is intended to produce tighter, better-calibrated intervals in practice, as shown by the empirical coverage results outperforming baselines. However, we do not provide a formal bound or theoretical correction for the widening effect. In revision we will add a limitations discussion section addressing this issue, describing how the training strategies empirically control widening on the evaluated datasets, and noting it as an open direction for future research. revision: partial
-
Referee: [Experiments section] Superiority claims for C-INN point accuracy and J-INN interval calibration lack error bars, full data splits, hyperparameter search details, and ablation on the uncertainty-aware losses/parameterization tricks. Without these, it is impossible to rule out post-hoc selection or overfitting to the specific SysID datasets, undermining the central benchmarking conclusions.
Authors: We agree these experimental details are required to substantiate the benchmarking claims and ensure reproducibility. In the revised manuscript we will add error bars computed over multiple independent runs, explicit descriptions of the train/validation/test splits for all datasets, the full hyperparameter search procedure and ranges explored, and ablation studies on the uncertainty-aware losses and parameterization tricks. These changes will directly address concerns about post-hoc selection or dataset-specific overfitting. revision: yes
-
Referee: [Section introducing channel-wise elasticity] The channel-wise elasticity metric is introduced to reveal uncertainty patterns, but its definition and computation are not shown to be independent of the interval widths produced by the arithmetic; if elasticity is derived directly from the same interval outputs, it risks being tautological rather than providing new insight into model uncertainty.
Authors: Channel-wise elasticity is defined as a normalized sensitivity measure: the relative change in interval width per channel under controlled input perturbations, allowing comparison of uncertainty distribution patterns between C-INN and J-INN. While computed from interval outputs, it yields comparative insights (e.g., concentrated vs. diffuse uncertainty across channels) not directly visible from raw widths or aggregate calibration metrics. We will revise the section to include the precise mathematical definition, computation procedure, and illustrative examples demonstrating its added interpretive value beyond tautology. revision: partial
- Formal theoretical bound or correction for the interval dependency problem in recurrent LSTM structures.
Circularity Check
No significant circularity in the INN framework derivation
full rationale
The paper's core derivation extends crisp neural networks to interval counterparts via standard interval arithmetic applied to LSTM and NODE architectures, then defines two training procedures (C-INN as two-stage conversion and J-INN as joint optimization) along with uncertainty-aware losses and a channel-wise elasticity metric. None of these steps reduce by construction to fitted inputs or self-referential definitions; interval propagation follows established rules independent of the target prediction intervals, and the performance claims rest on external empirical benchmarks against uncertainty-aware baselines on SysID datasets. No load-bearing self-citations, imported uniqueness theorems, or smuggled ansatzes appear in the derivation chain. The framework is self-contained with independent experimental validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ljung, System Identification: Theory for the User, Prentice Hall PTR, 1999
L. Ljung, System Identification: Theory for the User, Prentice Hall PTR, 1999
work page 1999
-
[2]
A. Dankers, P. M. J. Van den Hof, X. Bombois, P. S. C. Heuberger, Identifi- cation of dynamic models in complex networks with prediction error meth- ods: Predictor input selection, IEEE Transactions on Automatic Control 61 (4) (2016) 937–952.doi:10.1109/TAC.2015.2450895
-
[3]
N. Zhou, J. Pierre, J. Hauer, Initial results in power system identification 33 from injected probing signals using a subspace method, IEEE Transactions on Power Systems 21 (3) (2006) 1296–1302.doi:10.1109/TPWRS.2006. 879292
-
[4]
G. Pillonetto, A. Aravkin, D. Gedon, L. Ljung, A. H. Ribeiro, T. B. Schön, Deep networks for system identification: A survey, Automatica 171 (2025) 111907
work page 2025
-
[5]
T. Dai, K. Aljanaideh, R. Chen, R. Singh, A. Stothert, L. Ljung, Deep learning of dynamic systems using system identification toolbox™, IFAC- PapersOnLine 58 (15) (2024) 580–585
work page 2024
-
[6]
M. F. Mansur, T. Kumbasar, Solis: Physics-informed learning of in- terpretable neural surrogates for nonlinear systems, arXiv preprint arXiv:2604.14879 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
R.-T. Wu, M. R. Jahanshahi, Deep convolutional neural network for struc- tural dynamic response estimation and system identification, Journal of Engineering Mechanics 145 (1) (2019) 04018125
work page 2019
-
[8]
M. Forgione, D. Piga, Continuous-time system identification with neural networks: Model structures and fitting criteria, European Journal of Con- trol 59 (2021) 69–81
work page 2021
-
[9]
T. A. Tutunji, Parametric system identification using neural networks, Ap- plied Soft Computing 47 (2016) 251–261
work page 2016
-
[10]
M. Forgione, A. Muni, D. Piga, M. Gallieri, On the adaptation of recurrent neural networks for system identification, Automatica 155 (2023) 111092
work page 2023
-
[11]
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Comput. 9 (8) (1997) 1735–1780
work page 1997
-
[12]
R. T. Chen, Y. Rubanova, J. Bettencourt, D. K. Duvenaud, Neural or- dinary differential equations, Advances in neural information processing systems 31 (2018)
work page 2018
-
[13]
T. Tuna, A. Beke, T. Kumbasar, Deep learning frameworks to learn pre- diction and simulation focused control system models, Applied Intelligence 52 (1) (2022) 662–679
work page 2022
-
[14]
Y. Wang, A new concept using lstm neural networks for dynamic system identification, in: 2017 American control conference (ACC), IEEE, 2017, pp. 5324–5329
work page 2017
- [15]
-
[16]
Y. Yang, H. Li, Neural ordinary differential equations for robust parameter estimation in dynamic systems with physical priors, Applied Soft Comput- ing 169 (2025) 112649
work page 2025
- [17]
- [18]
- [19]
-
[20]
H. D. Kabir, A. Khosravi, A. Kavousi-Fard, S. Nahavandi, D. Srinivasan, Optimal uncertainty-guided neural network training, Applied Soft Com- puting 99 (2021) 106878
work page 2021
-
[21]
J.Gawlikowski, C.R.N.Tassi, M.Ali, J.Lee, M.Humt, J.Feng, A.Kruspe, R. Triebel, P. Jung, R. Roscher, et al., A survey of uncertainty in deep neural networks, Artificial Intelligence Review 56 (Suppl 1) (2023) 1513– 1589
work page 2023
-
[22]
C. J. Roy, W. L. Oberkampf, A comprehensive framework for verification, validation, and uncertainty quantification in scientific computing, Com- puter methods in applied mechanics and engineering 200 (25-28) (2011) 2131–2144
work page 2011
-
[23]
R. Ak, V. Vitelli, E. Zio, An interval-valued neural network approach for uncertaintyquantificationinshort-termwindspeedprediction, IEEEtrans- actions on neural networks and learning systems 26 (11) (2015) 2787–2800
work page 2015
- [24]
- [25]
-
[26]
A. Khosravi, S. Nahavandi, D. Creighton, A. F. Atiya, Comprehensive review of neural network-based prediction intervals and new advances, IEEE Transactions on Neural Networks 22 (9) (2011) 1341–1356.doi: 10.1109/TNN.2011.2162110. 35
- [27]
-
[28]
M. Morimoto, K. Fukami, R. Maulik, R. Vinuesa, K. Fukagata, Assess- ments of epistemic uncertainty using gaussian stochastic weight averag- ing for fluid-flow regression, Physica D: Nonlinear Phenomena 440 (2022) 133454
work page 2022
- [29]
-
[30]
M. R. Baker, R. B. Patil, Universal approximation theorem for interval neural networks, Reliable Computing 4 (1998) 235–239
work page 1998
- [31]
-
[32]
K. Tretiak, G. Schollmeyer, S. Ferson, Neural network model for imprecise regression with interval dependent variables, Neural Networks 161 (2023) 550–564
work page 2023
-
[33]
J. Sadeghi, M. de Angelis, E. Patelli, Efficient training of interval neural networks for imprecise training data, Neural Networks 118 (2019) 338–351
work page 2019
- [34]
-
[35]
A. Harapanahalli, S. Jafarpour, S. Coogan, A toolbox for fast interval arith- metic in numpy with an application to formal verification of neural network controlled systems, arXiv preprint arXiv:2306.15340 (2023)
-
[36]
M. A. Ferah, T. Kumbasar, Introducing interval neural networks for uncertainty-aware system identification, in: 2025 7th International Congress on Human-Computer Interaction, Optimization and Robotic Ap- plications (ICHORA), IEEE, 2025, pp. 1–7
work page 2025
-
[37]
A. Mahajan, S. Das, W. Su, V.-H. Bui, Bayesian-neural-network-based approach for probabilistic prediction of building-energy demands, Sustain- ability 16 (22) (2024) 9943
work page 2024
- [38]
-
[39]
Y. Gal, Z. Ghahramani, Dropout as a bayesian approximation: Represent- ing model uncertainty in deep learning, in: international conference on machine learning, PMLR, 2016, pp. 1050–1059
work page 2016
-
[40]
B. Lakshminarayanan, A. Pritzel, C. Blundell, Simple and scalable pre- dictive uncertainty estimation using deep ensembles, Advances in neural information processing systems 30 (2017)
work page 2017
- [41]
-
[42]
T.Zhang, Z.Yao, A.Gholami, J.E.Gonzalez, K.Keutzer, M.W.Mahoney, G. Biros, Anodev2: A coupled neural ode framework, Advances in Neural Information Processing Systems 32 (2019)
work page 2019
-
[43]
Z. Chen, V. Badrinarayanan, C.-Y. Lee, A. Rabinovich, Gradnorm: Gradi- ent normalization for adaptive loss balancing in deep multitask networks, in: International conference on machine learning, PMLR, 2018, pp. 794– 803
work page 2018
-
[44]
T. Pouplin, A. Jeffares, N. Seedat, M. van der Schaar, Relaxed quan- tile regression: Prediction intervals for asymmetric noise, arXiv preprint arXiv:2406.03258 (2024)
-
[45]
The MathWorks, Inc., Initialize Learnable Parameters for Custom Training Loop, accessed: 2025-07-02 (2024). URLhttps://www.mathworks.com/help/deeplearning/ug/ initialize-learnable-parameters-for-custom-training-loop.html
work page 2025
-
[46]
J. Wang, A. Sano, T. Chen, B. Huang, Identification of hammerstein sys- tems without explicit parameterisation of non-linearity, International Jour- nal of Control 82 (5) (2009) 937–952
work page 2009
-
[47]
B. De Moor, R. D. Bie, I. Lemahieu, J. Renders, Daisy: Database for the identification of systems, http://homes.esat.kuleuven.be/ smc/daisy/, accessed 13 Jan 2025 (1997)
work page 2025
-
[48]
H. Quan, D. Srinivasan, A. Khosravi, Short-term load and wind power forecasting using neural network-based prediction intervals, IEEE Trans- actions on Neural Networks and Learning Systems 25 (2) (2014) 303–315. doi:10.1109/TNNLS.2013.2276053
- [49]
-
[50]
C. Blundell, J. Cornebise, K. Kavukcuoglu, D. Wierstra, Weight uncer- tainty in neural network, in: International conference on machine learning, PMLR, 2015, pp. 1613–1622. 37
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.