Recognition: no theorem link
CAMPA: Efficient and Aligned Multimodal Graph Learning via Decoupled Propagation and Aggregation
Pith reviewed 2026-05-13 01:49 UTC · model grok-4.3
The pith
Decoupled multimodal graph networks gain accuracy by aligning cross-modal propagation and aggregation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAMPA resolves modal conflict in decoupled MGNN pipelines by introducing cross-modal aligned propagation, which injects cross-modal similarity priors into message passing to maintain semantic consistency, and trajectory aligned aggregation, which applies trajectory-level self-attention and cross-attention to capture and align long-range dependencies across modalities and hops; extensive experiments confirm this yields consistent outperformance over strong coupled and decoupled baselines while preserving the computational advantages of decoupling.
What carries the argument
Two-stage alignment mechanism of cross-modal aligned propagation (injecting similarity priors into message passing) and trajectory aligned aggregation (using self-attention and cross-attention on multi-hop trajectories).
Load-bearing premise
Modal conflict is the primary bottleneck in existing decoupled MGNNs and the proposed two-stage alignment resolves it without introducing new inconsistencies or overhead.
What would settle it
Running CAMPA on additional large-scale multimodal graph datasets and finding either no accuracy gains over strong decoupled baselines or a loss of efficiency advantages would falsify the central claim.
Figures
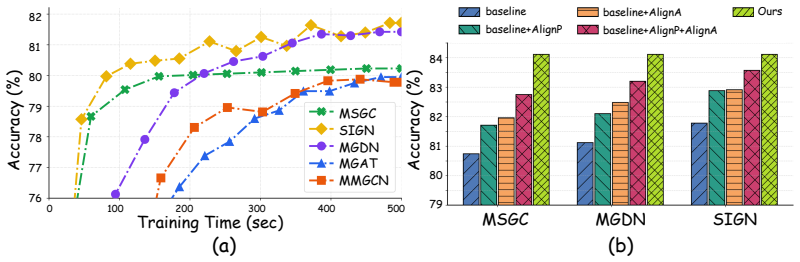





read the original abstract
Multimodal Graph Neural Networks (MGNNs) have shown strong potential for learning from multimodal attributed graphs, yet most existing approaches rely on tightly coupled architectures that suffer from prohibitive computational overhead. In this paper, we present a systematic empirical analysis showing that decoupled MGNNs are substantially more efficient and scalable for large-scale graph learning. However, we identify a critical bottleneck in existing decoupled pipelines, namely modal conflict, which arises in both the propagation and aggregation stages. Specifically, independent multi-hop diffusion causes cross-modal semantic divergence during propagation, while naive fusion fails to align multi-hop feature trajectories during aggregation, jointly limiting effective representation learning. To address this challenge, we propose CAMPA, a Cross-modal Aligned Multimodal Propagation & Aggregation framework for decoupled multimodal graph learning. Concretely, CAMPA introduces a two-stage alignment mechanism: (1) cross-modal aligned propagation, which injects cross-modal similarity priors into message passing to preserve semantic consistency without additional parameter overhead; (2) trajectory aligned aggregation, which leverages trajectory-level self-attention and cross-attention to capture and align long-range dependencies across modalities and hops. Extensive experiments on diverse benchmark datasets and tasks demonstrate that CAMPA consistently outperforms strong coupled and decoupled baselines while preserving the efficiency advantages of the decoupled paradigm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that decoupled MGNNs are substantially more efficient and scalable than coupled ones for large-scale multimodal graph learning, but suffer from a critical 'modal conflict' bottleneck: independent multi-hop diffusion causes cross-modal semantic divergence in propagation, while naive fusion fails to align multi-hop feature trajectories in aggregation. To resolve this, CAMPA introduces a two-stage alignment: (1) cross-modal aligned propagation that injects cross-modal similarity priors into message passing with no extra parameters, and (2) trajectory aligned aggregation that uses trajectory-level self-attention and cross-attention to capture long-range dependencies across modalities and hops. Extensive experiments are said to show consistent outperformance over strong coupled and decoupled baselines while preserving decoupled efficiency.
Significance. If the empirical claims hold with full verification, this would be a useful contribution to scalable multimodal graph learning by showing how to add alignment to the decoupled paradigm without sacrificing its asymptotic advantages. The identification of modal conflict as a joint propagation-aggregation issue provides a concrete diagnostic lens, and the parameter-free prior injection in propagation is a clean design choice that could influence future MGNN architectures.
major comments (2)
- [Method description of trajectory aligned aggregation] The central efficiency claim (preserving the decoupled paradigm's advantages) is load-bearing, yet the abstract and method description provide no analysis or bounds on the computational complexity of trajectory aligned aggregation. Attention over multi-hop trajectories across modalities is quadratic in the number of hops/modalities unless linearized, sparsified, or windowed; without explicit confirmation that the implementation avoids this cost on large graphs, the headline claim that efficiency is retained cannot be assessed.
- [Experimental results summary] The abstract asserts that CAMPA 'consistently outperforms strong coupled and decoupled baselines' on 'diverse benchmark datasets and tasks,' but supplies no information on the datasets used, exact baseline implementations, evaluation metrics, statistical tests, number of runs, or ablation studies isolating the two alignment stages. This absence prevents verification of the central empirical claim and the weakest assumption that the proposed alignment resolves modal conflict without introducing new inconsistencies.
minor comments (1)
- [Introduction] The term 'modal conflict' is introduced as a new bottleneck without a formal definition, mathematical characterization, or references to related concepts in multimodal or multi-view graph learning.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. We address each major comment in detail below, providing clarifications from the manuscript and committing to targeted revisions that strengthen the presentation of our efficiency claims and experimental details without altering the core contributions.
read point-by-point responses
-
Referee: [Method description of trajectory aligned aggregation] The central efficiency claim (preserving the decoupled paradigm's advantages) is load-bearing, yet the abstract and method description provide no analysis or bounds on the computational complexity of trajectory aligned aggregation. Attention over multi-hop trajectories across modalities is quadratic in the number of hops/modalities unless linearized, sparsified, or windowed; without explicit confirmation that the implementation avoids this cost on large graphs, the headline claim that efficiency is retained cannot be assessed.
Authors: We agree that an explicit complexity analysis is necessary to fully substantiate the efficiency claim. In the manuscript, trajectory aligned aggregation operates on fixed-length per-node trajectories (with small constants for hops H and modalities M, typically H=2-3 and M=2-3 in our experiments), using standard scaled dot-product attention followed by efficient linear projections. The per-node cost is O((H*M)^2 * d) where d is the feature dimension, which remains negligible relative to the linear propagation cost of the decoupled paradigm. We will add a dedicated subsection in the revised Methods (Section 3.3) providing both asymptotic bounds and empirical wall-clock runtime comparisons on the largest benchmark graphs to confirm that the overhead does not compromise the overall scalability advantage. revision: yes
-
Referee: [Experimental results summary] The abstract asserts that CAMPA 'consistently outperforms strong coupled and decoupled baselines' on 'diverse benchmark datasets and tasks,' but supplies no information on the datasets used, exact baseline implementations, evaluation metrics, statistical tests, number of runs, or ablation studies isolating the two alignment stages. This absence prevents verification of the central empirical claim and the weakest assumption that the proposed alignment resolves modal conflict without introducing new inconsistencies.
Authors: The full manuscript contains a comprehensive Experiments section (Section 4) that details the benchmark datasets, baseline implementations (with citations and hyperparameter settings), evaluation metrics, number of runs (5 random seeds with reported means and standard deviations), and ablation studies that isolate the contributions of cross-modal aligned propagation and trajectory aligned aggregation separately. We will revise the abstract to include a brief reference to these details and expand the ablation analysis in the revision to explicitly demonstrate that each alignment stage independently mitigates modal conflict without introducing inconsistencies, including additional statistical significance tests (paired t-tests) across all tasks. revision: partial
Circularity Check
No circularity; empirical proposal with independent mechanisms
full rationale
The paper's core contribution is an empirical identification of modal conflict in decoupled MGNNs followed by a proposed two-stage alignment (cross-modal priors in propagation and trajectory attention in aggregation). No equations, derivations, or first-principles results are presented that reduce to fitted parameters, self-definitions, or self-citation chains. The efficiency and performance claims rest on benchmark experiments rather than any tautological reduction, satisfying the criteria for a self-contained non-circular analysis.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Independent multi-hop diffusion causes cross-modal semantic divergence during propagation
- domain assumption Naive fusion fails to align multi-hop feature trajectories during aggregation
invented entities (2)
-
cross-modal aligned propagation
no independent evidence
-
trajectory aligned aggregation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Rumor detection on social media with bi-directional graph convolutional networks
Tian Bian, Xi Xiao, Tingyang Xu, Peilin Zhao, Wenbing Huang, Yu Rong, and Junzhou Huang. Rumor detection on social media with bi-directional graph convolutional networks. In Proceedings of the Association for the Advancement of Artificial Intelligence, AAAI, 2020
work page 2020
-
[2]
Shaked Brody, Uri Alon, and Eran Yahav. How attentive are graph attention networks?Interna- tional Conference on Learning Representations, ICLR, 2022
work page 2022
-
[3]
Multimodal graph neural architecture search under distribution shifts
Jie Cai, Xin Wang, Haoyang Li, Ziwei Zhang, and Wenwu Zhu. Multimodal graph neural architecture search under distribution shifts. InProceedings of the AAAI Conference on Artificial Intelligence, AAAI, 2024
work page 2024
-
[4]
Nagphormer: A tokenized graph transformer for node classification in large graphs
Jinsong Chen, Kaiyuan Gao, Gaichao Li, and Kun He. Nagphormer: A tokenized graph transformer for node classification in large graphs. InInternational Conference on Learning Representations, ICLR, 2023
work page 2023
-
[5]
Simple and deep graph convolutional networks
Ming Chen, Zhewei Wei, Zengfeng Huang, Bolin Ding, and Yaliang Li. Simple and deep graph convolutional networks. InInternational Conference on Machine Learning, ICML, 2020
work page 2020
-
[6]
Redcaps: Web-curated image-text data created by the people, for the people
Karan Desai, Gaurav Kaul, Zubin Trivadi Aysola, and Justin Johnson. Redcaps: Web-curated image-text data created by the people, for the people. InAdvances in Neural Information Processing Systems, NeurIPS Datasets and Benchmarks Track, 2021
work page 2021
-
[7]
Mlaga: Multimodal large language and graph assistant.arXiv preprint arXiv:2506.02568, 2025
Dongzhe Fan, Yi Fang, Jiajin Liu, Djellel Difallah, and Qiaoyu Tan. Mlaga: Multimodal large language and graph assistant.arXiv preprint arXiv:2506.02568, 2025
-
[8]
Graphgpt- o: Synergistic multimodal comprehension and generation on graphs
Yi Fang, Bowen Jin, Jiacheng Shen, Sirui Ding, Qiaoyu Tan, and Jiawei Han. Graphgpt- o: Synergistic multimodal comprehension and generation on graphs. InProceedings of the Computer Vision and Pattern Recognition Conference, CVPR, pages 19467–19476, 2025
work page 2025
-
[9]
Sign: Scalable inception graph neural networks.arXiv preprint arXiv:2004.11198,
Fabrizio Frasca, Emanuele Rossi, Davide Eynard, Ben Chamberlain, Michael Bronstein, and Federico Monti. Sign: Scalable inception graph neural networks.arXiv preprint arXiv:2004.11198, 2020
-
[10]
How to read paintings: semantic art understanding with multi- modal retrieval
Noa Garcia and George V ogiatzis. How to read paintings: semantic art understanding with multi- modal retrieval. InProceedings of the European Conference on Computer Vision Workshops, ECCV, 2018
work page 2018
-
[11]
Disentangling homophily and heterophily in multimodal graph clustering.CoRR, abs/2507.15253, 2025
Zhaochen Guo, Zhixiang Shen, Xuanting Xie, Liangjian Wen, and Zhao Kang. Disentangling homophily and heterophily in multimodal graph clustering.CoRR, abs/2507.15253, 2025
-
[12]
Lgmrec: Local and global graph learning for multimodal recommendation
Zhiqiang Guo, Jianjun Li, Guohui Li, Chaoyang Wang, Si Shi, and Bin Ruan. Lgmrec: Local and global graph learning for multimodal recommendation. InAAAI, pages 8454–8462. AAAI Press, 2024
work page 2024
-
[13]
Yufei He, Yuan Sui, Xiaoxin He, Yue Liu, Yifei Sun, and Bryan Hooi. Unigraph2: Learning a unified embedding space to bind multimodal graphs.arXiv preprint arXiv:2502.00806, 2025
-
[14]
Bridging Language and Items for Retrieval and Recommendation: Benchmarking LLMs as Semantic Encoders
Yupeng Hou, Jiacheng Li, Zhankui He, An Yan, Xiusi Chen, and Julian McAuley. Bridging language and items for retrieval and recommendation.arXiv preprint arXiv:2403.03952, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Ntsformer: A self-teaching graph transformer for multimodal isolated cold-start node classification
Jun Hu, Yufei He, Yuan Li, Bryan Hooi, and Bingsheng He. Ntsformer: A self-teaching graph transformer for multimodal isolated cold-start node classification. InProceedings of the AAAI Conference on Artificial Intelligence, AAAI, 2025
work page 2025
-
[16]
Modality-independent graph neural networks with global transformers for multimodal recommendation
Jun Hu, Bryan Hooi, Bingsheng He, and Yinwei Wei. Modality-independent graph neural networks with global transformers for multimodal recommendation. InAAAI, pages 11790– 11798. AAAI Press, 2025
work page 2025
-
[17]
Jun Hu, Bryan Hooi, Shengsheng Qian, Quan Fang, and Changsheng Xu. Mgdcf: Distance learning via markov graph diffusion for neural collaborative filtering.IEEE Transactions on Knowledge and Data Engineering, 36(7):3281–3296, 2024. 10
work page 2024
-
[18]
Bowen Jin, Ziqi Pang, Bingjun Guo, Yu-Xiong Wang, Jiaxuan You, and Jiawei Han. Instructg2i: Synthesizing images from multimodal attributed graphs.Advances in Neural Information Processing Systems, 37:117614–117635, 2024
work page 2024
-
[19]
Semi-supervised classification with graph convolutional networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. InInternational Conference on Learning Representations, ICLR, 2017
work page 2017
-
[20]
C-mag: Cascade multimodal attributed graphs for supply chain link prediction
Yunqing Li, Zixiang Tang, Jiaying Zhuang, Zhenyu Yang, Farhad Ameri, and Jianbang Zhang. C-mag: Cascade multimodal attributed graphs for supply chain link prediction. InProceedings of the KDD Workshop on AI for Supply Chain, 2025
work page 2025
-
[21]
Jiajin Liu, Dongzhe Fan, Jiacheng Shen, Chuanhao Ji, Daochen Zha, and Qiaoyu Tan. Graph- mllm: Harnessing multimodal large language models for multimodal graph learning.arXiv preprint arXiv:2506.10282, 2025
-
[22]
Justifying recommendations using distantly- labeled reviews and fine-grained aspects
Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying recommendations using distantly- labeled reviews and fine-grained aspects. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natu- ral Language Processing (EMNLP-IJCNLP), pages 188–197. Association for Computational L...
work page 2019
-
[23]
Justifying recommendations using distantly- labeled reviews and fine-grained aspects
Jianmo Ni, Jiacheng Li, and Julian McAuley. Justifying recommendations using distantly- labeled reviews and fine-grained aspects. InProceedings of the Conference on Empirical Methods in Natural Language Processing and the International Joint Conference on Natural Language Processing, EMNLP-IJCNLP, 2019
work page 2019
-
[24]
Graph4mm: Weaving multimodal learning with structural information
Xuying Ning, Dongqi Fu, Tianxin Wei, Wujiang Xu, and Jingrui He. Graph4mm: Weaving multimodal learning with structural information. InProceedings of the International Conference on Machine Learning, ICML, 2025
work page 2025
-
[25]
Dinov2: Learning robust visual features without supervision
Maxime Oquab, Timothée Darcet, Theo Moutakanni, Huy V V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaa El-Nouby, et al. Dinov2: Learning robust visual features without supervision. InTransactions on Machine Learning Research, TMLR, 2024
work page 2024
-
[26]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational Conference on Machine Learning, ICML, 2021
work page 2021
-
[27]
MGAT: multimodal graph attention network for recommendation.Inf
Zhulin Tao, Yinwei Wei, Xiang Wang, Xiangnan He, Xianglin Huang, and Tat-Seng Chua. MGAT: multimodal graph attention network for recommendation.Inf. Process. Manag., 57(5):102277, 2020
work page 2020
-
[28]
Petar Veliˇckovi´c, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Lio, and Yoshua Bengio. Graph attention networks. InInternational Conference on Learning Representations, ICLR, 2018
work page 2018
-
[29]
arXiv preprint arXiv:2602.05576 , year =
Chenxi Wan, Xunkai Li, Yilong Zuo, Haokun Deng, Sihan Li, Bowen Fan, Hongchao Qin, Ronghua Li, and Guoren Wang. Openmag: A comprehensive benchmark for multimodal- attributed graph.arXiv preprint arXiv:2602.05576, 2026
-
[30]
Item recommendation on monotonic behavior chains
Mengting Wan and Julian McAuley. Item recommendation on monotonic behavior chains. In Proceedings of the ACM Conference on Recommender Systems, RecSys, 2018
work page 2018
-
[31]
Fine-grained spoiler detection from large-scale review corpora
Mengting Wan, Rishabh Misra, Ndapandula Nakashole, and Julian McAuley. Fine-grained spoiler detection from large-scale review corpora. InProceedings of the Annual Meeting of the Association for Computational Linguistics, ACL, 2019
work page 2019
-
[32]
Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Mengfei Du, Xuancheng Ren, Rui Men, Dayiheng Liu, Chang Zhou, Jingren Zhou, and Junyang Lin. Qwen2-vl: Enhancing vision- language model’s perception of the world at any resolution, 2024. 11
work page 2024
-
[33]
Towards multi-modal graph large language model.arXiv preprint arXiv:2506.09738, 2025
Xin Wang, Zeyang Zhang, Linxin Xiao, Haibo Chen, Chendi Ge, and Wenwu Zhu. Towards multi-modal graph large language model.arXiv preprint arXiv:2506.09738, 2025
-
[34]
MMGCN: multi-modal graph convolution network for personalized recommendation of micro- video
Yinwei Wei, Xiang Wang, Liqiang Nie, Xiangnan He, Richang Hong, and Tat-Seng Chua. MMGCN: multi-modal graph convolution network for personalized recommendation of micro- video. InACM Multimedia, pages 1437–1445. ACM, 2019
work page 2019
-
[35]
Simplifying graph convolutional networks
Felix Wu, Amauri Souza, Tianyi Zhang, Christopher Fifty, Tao Yu, and Kilian Weinberger. Simplifying graph convolutional networks. InInternational Conference on Machine Learning, ICML, 2019
work page 2019
-
[36]
Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and S Yu Philip. A comprehensive survey on graph neural networks.IEEE Transactions on Neural Networks and Learning Systems, 32(1):4–24, 2020
work page 2020
-
[37]
When graph meets multimodal: benchmarking and meditating on multimodal attributed graph learning
Hao Yan, Chaozhuo Li, Jun Yin, Zhigang Yu, Weihao Han, Mingzheng Li, Zhengxin Zeng, Hao Sun, and Senzhang Wang. When graph meets multimodal: benchmarking and meditating on multimodal attributed graph learning. InProceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD, 2025
work page 2025
-
[38]
Multimodal graph learning for generative tasks.arXiv preprint arXiv:2310.07478, 2023
Minji Yoon, Jing Yu Koh, Bryan Hooi, and Ruslan Salakhutdinov. Multimodal graph learning for generative tasks.arXiv preprint arXiv:2310.07478, 2023
-
[39]
Wentao Zhang, Mingyu Yang, Zeang Sheng, Yang Li, Wen Ouyang, Yangyu Tao, Zhi Yang, and Bin Cui. Node dependent local smoothing for scalable graph learning.Advances in Neural Information Processing Systems, NeurIPS, 2021
work page 2021
-
[40]
Wentao Zhang, Ziqi Yin, Zeang Sheng, Yang Li, Wen Ouyang, Xiaosen Li, Yangyu Tao, Zhi Yang, and Bin Cui. Graph attention multi-layer perceptron.Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD, 2022
work page 2022
-
[41]
Cross-contrastive clustering for multimodal attributed graphs with dual graph filtering, 2025
Haoran Zheng, Renchi Yang, Hongtao Wang, and Jianliang Xu. Cross-contrastive clustering for multimodal attributed graphs with dual graph filtering, 2025
work page 2025
-
[42]
Yu Zhou, Haixia Zheng, Xin Huang, Shufeng Hao, Dengao Li, and Jumin Zhao. Graph neural networks: Taxonomy, advances, and trends.ACM Transactions on Intelligent Systems and TechnoLoGy, 13(1):1–54, 2022
work page 2022
-
[43]
Jing Zhu, Yuhang Zhou, Shengyi Qian, Zhongmou He, Tong Zhao, Neil Shah, and Danai Koutra. Mosaic of modalities: A comprehensive benchmark for multimodal graph learning. In Proceedings of the Computer Vision and Pattern Recognition Conference, CVPR, 2025. 12 A Supplementary Empirical Analysis This appendix supplements the empirical studies in Sec. 1 and pr...
work page 2025
-
[44]
For Modality Retrieval, Modality Matching, and Modality Alignment, we adopt task-specific downstream contrastive models and objectives with a temperature scaling factorτ= 0.1 . The models are trained for up to 500 epochs with a learning rate of 1×10 −3, batch size of 256, and early-stop patience of 50. For the G2Image [18] task, we adopt Stable Diffusion ...
-
[45]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.