Recognition: no theorem link
LDDR: Linear-DPP-Based Dynamic-Resolution Frame Sampling for Video MLLMs
Pith reviewed 2026-05-13 03:08 UTC · model grok-4.3
The pith
LDDR applies linear query-aware DPP selection and group importance to dynamically allocate resolution for better video frame sampling in MLLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
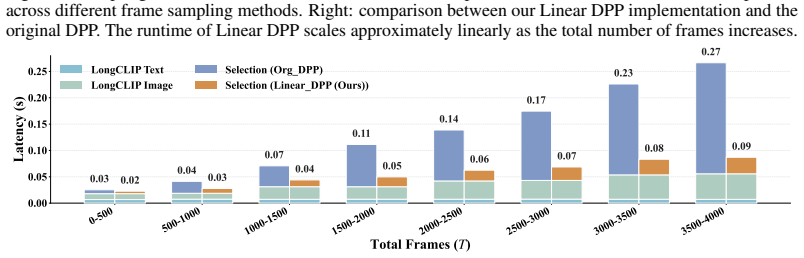
The paper claims that performing query-aware DPP frame selection in a task-conditioned feature space achieves a 3x runtime speedup over standard DPP baselines, while a Group DPP importance metric guides frame retention and dynamic resolution allocation by giving more tokens to informative non-redundant frames; across four benchmarks spanning short to long videos this yields 2.5-point gains under budget constraints and 1.6-point gains in high-budget settings, with consistent benefits across open- and closed-source MLLM backbones.
What carries the argument
Linear DPP-Based Dynamic-Resolution (LDDR) sampling, which linearizes query-aware DPP selection in task-conditioned space and applies a Group DPP importance metric to decide retention and token allocation per frame.
If this is right
- Outperforms next-best baselines by 2.5 points under budget-constrained settings on short-, medium-, and long-range video tasks.
- Delivers 1.6 point improvements in high-budget scenarios.
- Achieves 3x runtime speedup over standard DPP baselines.
- Produces consistent gains across multiple open- and closed-source MLLM backbones.
- Selects relevant frames and assigns them higher token budgets to support improved video understanding.
Where Pith is reading between the lines
- The training-free plug-and-play design could be inserted into existing MLLM inference pipelines with no retraining cost.
- Modeling global frame dependencies through DPP may reduce redundancy more effectively than independent or chunk-based scoring in other sequence-processing domains.
- Dynamic resolution allocation suggests a general strategy for trading off detail versus coverage whenever input length must be compressed under a fixed budget.
Load-bearing premise
That query-aware DPP selection performed in a task-conditioned feature space together with the Group DPP importance metric will reliably identify the most informative non-redundant frames such that dynamic resolution allocation improves downstream performance without discarding essential information.
What would settle it
On any of the four video benchmarks, if LDDR-selected frames with the proposed allocation produce lower task accuracy than uniform sampling when both methods use exactly the same total visual token budget, the claimed advantage would be disproven.
Figures



read the original abstract
Video understanding in multimodal large language models requires selecting informative frames from long, redundant videos under limited visual-token budgets. Existing methods often rely on uniform sampling, point-wise relevance scoring, chunk-wise selection, or agentic exploration, which either miss global dependencies or introduce substantial overhead. We propose LDDR (Linear DPP-Based Dynamic Resolution), a training-free, plug-and-play, and budget-aware video frame sampling framework. LDDR performs query-aware Determinantal Point Process (DPP) frame selection in a task-conditioned feature space, achieving a 3x runtime speedup over standard DPP baselines. It further introduces a Group DPP importance metric to guide frame retention and dynamic resolution allocation, assigning more tokens to informative, non-redundant frames while downscaling or pruning less useful ones. Across four video benchmarks spanning short-, medium-, and long-range videos, LDDR consistently outperforms the next-best baselines, achieving gains of 2.5 points under budget-constrained settings and 1.6 points in high-budget scenarios. These improvements are consistently observed across multiple MLLM backbones, including both open- and closed-source models. Qualitative analysis confirms that relevant frames are selected and allocated a higher budget, facilitating improved video understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LDDR, a training-free, plug-and-play, budget-aware framework for video frame sampling in multimodal large language models. It performs query-aware linear Determinantal Point Process (DPP) selection in a task-conditioned feature space for a claimed 3x runtime speedup over standard DPP, introduces a Group DPP importance metric to guide frame retention and dynamic resolution/token allocation to informative non-redundant frames, and reports consistent outperformance over baselines with gains of 2.5 points under budget-constrained settings and 1.6 points in high-budget scenarios across four video benchmarks (short-, medium-, and long-range) and multiple open- and closed-source MLLM backbones.
Significance. If the empirical claims hold with proper validation, the work would be a useful practical contribution to efficient video understanding in MLLMs. The training-free and plug-and-play design, combined with the use of DPP for diversity-aware selection and dynamic allocation under token budgets, addresses a relevant scalability issue for long videos. The reported consistency across backbones and video lengths, along with the speedup, would be strengths if substantiated.
major comments (1)
- Abstract: The abstract states specific performance gains (2.5 points budget-constrained, 1.6 points high-budget) and a 3x speedup but supplies no experimental protocol, baseline details, error bars, statistical tests, ablation results, or dataset statistics. This prevents verification of the central empirical claim that LDDR reliably outperforms baselines via query-aware DPP and Group DPP-guided allocation.
minor comments (2)
- Clarify the exact definition and computation of the 'Group DPP importance metric' and how it differs from standard DPP marginal gains, preferably with a short equation or pseudocode in the methods.
- The qualitative analysis is mentioned but not illustrated; consider adding a figure or table showing example frame selections and resolution allocations for a sample video-query pair.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment point-by-point below and clarify the experimental details provided in the full paper.
read point-by-point responses
-
Referee: Abstract: The abstract states specific performance gains (2.5 points budget-constrained, 1.6 points high-budget) and a 3x speedup but supplies no experimental protocol, baseline details, error bars, statistical tests, ablation results, or dataset statistics. This prevents verification of the central empirical claim that LDDR reliably outperforms baselines via query-aware DPP and Group DPP-guided allocation.
Authors: We acknowledge that the abstract is intentionally concise and omits detailed experimental protocols, error bars, statistical tests, and dataset statistics, which is standard to respect length constraints. The full manuscript provides these elements in Section 4 (Experiments), including: dataset statistics and video length distributions (Table 1 and Section 4.1), baseline descriptions and implementation details (Section 4.1), multiple MLLM backbones (open- and closed-source), ablation studies on DPP components and dynamic allocation (Section 4.3), and performance comparisons with the reported gains. Results are averaged over multiple runs where applicable. To improve immediate verifiability from the abstract, we will revise it to briefly reference the four benchmarks, video length ranges, and backbones evaluated. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents LDDR as a training-free algorithmic proposal that applies query-aware linear DPP selection in a task-conditioned feature space, introduces a Group DPP importance metric for frame retention and dynamic resolution, and reports empirical gains on benchmarks. No equations, derivations, or first-principles results are shown that reduce the claimed speedups or accuracy improvements to quantities fitted inside the paper or defined in terms of the outputs themselves. The method is described as plug-and-play and budget-aware without self-definitional loops, fitted-input predictions, or load-bearing self-citations that would force the results by construction. The central claims rest on the algorithmic design and external experimental validation rather than any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LLaVA-OneVision-1.5: Fully Open Framework for Democratized Multimodal Training
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Didi Zhu, et al. Llava-onevision-1.5: Fully open framework for democratized multimodal training.arXiv preprint arXiv:2509.23661, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[4]
URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Fair and diverse dpp-based data summarization
Elisa Celis, Vijay Keswani, Damian Straszak, Amit Deshpande, Tarun Kathuria, and Nisheeth Vishnoi. Fair and diverse dpp-based data summarization. InInternational conference on machine learning, pages 716–725. PMLR, 2018
work page 2018
-
[6]
Fast greedy map inference for determinantal point process to improve recommendation diversity
Laming Chen, Guoxin Zhang, and Hanning Zhou. Fast greedy map inference for determinantal point process to improve recommendation diversity. InProceedings of the 32nd International Conference on Neural Information Processing Systems, NIPS’18, page 5627–5638, Red Hook, NY , USA, 2018. Curran Associates Inc
work page 2018
-
[7]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[8]
Mike Gartrell, Ulrich Paquet, and Noam Koenigstein. Low-rank factorization of determinantal point processes.Proceedings of the AAAI Conference on Artificial Intelligence, 31(1), Feb
-
[9]
URL https://ojs.aaai.org/index.php/AAAI/ article/view/10869
doi: 10.1609/aaai.v31i1.10869. URL https://ojs.aaai.org/index.php/AAAI/ article/view/10869
-
[10]
Diverse sequential subset selection for supervised video summarization
Boqing Gong, Wei-Lun Chao, Kristen Grauman, and Fei Sha. Diverse sequential subset selection for supervised video summarization. InProceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2, NIPS’14, page 2069–2077, Cambridge, MA, USA, 2014. MIT Press
work page 2069
-
[11]
Shinichi Hemmi, Taihei Oki, Shinsaku Sakaue, Kaito Fujii, and Satoru Iwata. Lazy and fast greedy map inference for determinantal point process.Advances in Neural Information Processing Systems, 35:2776–2789, 2022
work page 2022
-
[12]
M-llm based video frame selection for efficient video understanding
Kai Hu, Feng Gao, Xiaohan Nie, Peng Zhou, Son Tran, Tal Neiman, Lingyun Wang, Mubarak Shah, Raffay Hamid, Bing Yin, et al. M-llm based video frame selection for efficient video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13702–13712, 2025
work page 2025
-
[13]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700–13710, 2024
work page 2024
-
[14]
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2-3):123–286, December 2012. ISSN 1935-8245. doi: 10.1561/2200000044. URLhttp://dx.doi.org/10.1561/2200000044
-
[15]
Llama-vid: An image is worth 2 tokens in large language models
Yanwei Li, Chengyao Wang, and Jiaya Jia. Llama-vid: An image is worth 2 tokens in large language models. InEuropean Conference on Computer Vision, pages 323–340. Springer, 2024
work page 2024
-
[16]
Less is more, but where? dynamic token compression via LLM-guided keyframe prior
Yulin Li, Haokun GUI, Ziyang Fan, Junjie Wang, Bin Kang, BIN CHEN, and Zhuotao Tian. Less is more, but where? dynamic token compression via LLM-guided keyframe prior. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id=uhFx1RGD1g. 10
work page 2026
-
[17]
Keyvideollm: Towards large-scale video keyframe selection.arXiv preprint arXiv:2407.03104, 2024
Hao Liang, Jiapeng Li, Tianyi Bai, Xijie Huang, Linzhuang Sun, Zhengren Wang, Conghui He, Bin Cui, Chong Chen, and Wentao Zhang. Keyvideollm: Towards large-scale video keyframe selection.arXiv preprint arXiv:2407.03104, 2024
-
[18]
Huanxuan Liao, Zhongtao Jiang, Yupu Hao, Yuqiao Tan, Shizhu He, Jun Zhao, Kun Xu, and Kang Liu. Resadapt: Adaptive resolution for efficient multimodal reasoning.arXiv preprint arXiv:2603.28610, 2026
-
[19]
Bingjun Luo, Tony Wang, Hanqi Chen, and Xinpeng Ding. Enhancing visual token rep- resentations for video large language models via training-free spatial-temporal pooling and gridding. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=MZi9SYPVz5
work page 2026
-
[20]
Yongdong Luo, Xiawu Zheng, Guilin Li, Shukang Yin, Haojia Lin, Chaoyou Fu, Jinfa Huang, Jiayi Ji, Fei Chao, Jiebo Luo, et al. Video-rag: Visually-aligned retrieval-augmented long video comprehension.arXiv preprint arXiv:2411.13093, 2024
-
[21]
Odile Macchi. The coincidence approach to stochastic point processes.Advances in Applied Probability, 7(1):83–122, 1975. ISSN 00018678. URL http://www.jstor.org/stable/ 1425855
work page 1975
-
[22]
Zoomv: Temporal zoom-in for efficient long video understanding, 2026
Junwen Pan, Yuan Zhang, Rui Zhang, Xin Wan, Qizhe Zhang, Ming Lu, Shanghang Zhang, and Qi She. Zoomv: Temporal zoom-in for efficient long video understanding, 2026. URL https://openreview.net/forum?id=Spg6FCsmyc
work page 2026
-
[23]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[24]
Holitom: Holistic token merging for fast video large language models
Kele Shao, Keda TAO, Can Qin, Haoxuan You, Yang Sui, and Huan Wang. Holitom: Holistic token merging for fast video large language models. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/forum?id= 6hvaQTKkpF
work page 2026
-
[25]
Min Shi, Shihao Wang, Chieh-Yun Chen, Jitesh Jain, Kai Wang, Junjun Xiong, Guilin Liu, Zhiding Yu, and Humphrey Shi. Slow-fast architecture for video multi-modal large language models.arXiv preprint arXiv:2504.01328, 2025
-
[26]
Moviechat: From dense token to sparse memory for long video understanding
Enxin Song, Wenhao Chai, Guanhong Wang, Yucheng Zhang, Haoyang Zhou, Feiyang Wu, Haozhe Chi, Xun Guo, Tian Ye, Yanting Zhang, et al. Moviechat: From dense token to sparse memory for long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18221–18232, 2024
work page 2024
-
[27]
Guangyu Sun, Archit Singhal, Burak Uzkent, Mubarak Shah, Chen Chen, and Garin N. Kessler. From frames to clips: Efficient key clip selection for long-form video understanding, 2025. URLhttps://openreview.net/forum?id=BAdePgN4uR
work page 2025
-
[28]
Mdp3: A training-free approach for list-wise frame selection in video-llms
Hui Sun, Shiyin Lu, Huanyu Wang, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Ming Li. Mdp3: A training-free approach for list-wise frame selection in video-llms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 24090– 24101, 2025
work page 2025
-
[29]
Tspo: Temporal sampling policy optimization for long-form video language understanding
Canhui Tang, Zifan Han, Hongbo Sun, Sanping Zhou, Xuchong Zhang, Xin Wei, Ye Yuan, Huayu Zhang, Jinglin Xu, and Hao Sun. Tspo: Temporal sampling policy optimization for long-form video language understanding. InProceedings of the AAAI Conference on Artificial Intelligence, number 11, pages 9368–9376, 2026
work page 2026
-
[30]
Adaptive keyframe sampling for long video understanding
Xi Tang, Jihao Qiu, Lingxi Xie, Yunjie Tian, Jianbin Jiao, and Qixiang Ye. Adaptive keyframe sampling for long video understanding. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29118–29128, 2025. 11
work page 2025
-
[31]
Haibo Wang, Chenghang Lai, Yixuan Sun, and Weifeng Ge. Weakly supervised gaussian con- trastive grounding with large multimodal models for video question answering. InProceedings of the 32nd ACM International Conference on Multimedia, pages 5289–5298, 2024
work page 2024
-
[32]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958– 22967, 2025
work page 2025
-
[33]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Videoagent: Long-form video understanding with large language model as agent
Xiaohan Wang, Yuhui Zhang, Orr Zohar, and Serena Yeung-Levy. Videoagent: Long-form video understanding with large language model as agent. InEuropean Conference on Computer Vision, pages 58–76. Springer, 2024
work page 2024
-
[35]
Videotree: Adaptive tree-based video representation for llm reasoning on long videos
Ziyang Wang, Shoubin Yu, Elias Stengel-Eskin, Jaehong Yoon, Feng Cheng, Gedas Bertasius, and Mohit Bansal. Videotree: Adaptive tree-based video representation for llm reasoning on long videos. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3272–3283, 2025
work page 2025
-
[36]
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long- context interleaved video-language understanding.Advances in Neural Information Processing Systems, 37:28828–28857, 2024
work page 2024
-
[37]
Vca: Video curious agent for long video understanding
Zeyuan Yang, Delin Chen, Xueyang Yu, Maohao Shen, and Chuang Gan. Vca: Video curious agent for long video understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20168–20179, 2025
work page 2025
-
[38]
Shoubin Yu, Jaemin Cho, Prateek Yadav, and Mohit Bansal. Self-chained image-language model for video localization and question answering.Advances in Neural Information Processing Systems, 36:76749–76771, 2023
work page 2023
-
[39]
Frame-voyager: Learning to query frames for video large language models
Sicheng Yu, CHENGKAI JIN, Huanyu Wang, Zhenghao Chen, Sheng Jin, ZHONGRONG ZUO, XU XIAOLEI, Zhenbang Sun, Bingni Zhang, Jiawei Wu, Hao Zhang, and Qianru Sun. Frame-voyager: Learning to query frames for video large language models. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/forum?id=LNL7zKvm7e
work page 2025
-
[40]
Flexselect: Flexible token selection for efficient long video understanding
Yunzhuzhang, Yu Lu, Tianyi Wang, Fengyun Rao, Yi Yang, and Linchao Zhu. Flexselect: Flexible token selection for efficient long video understanding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview. net/forum?id=0D3ja9s17M
work page 2026
-
[41]
Sigmoid loss for language image pre-training
Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. InProceedings of the IEEE/CVF international conference on computer vision, pages 11975–11986, 2023
work page 2023
-
[42]
Long-clip: Unlocking the long-text capability of clip
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. Long-clip: Unlocking the long-text capability of clip. InEuropean conference on computer vision, pages 310–325. Springer, 2024
work page 2024
-
[43]
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al
Kaichen Zhang, Bo Li, Peiyuan Zhang, Fanyi Pu, Joshua Adrian Cahyono, Kairui Hu, Shuai Liu, Yuanhan Zhang, Jingkang Yang, Chunyuan Li, et al. Lmms-eval: Reality check on the evaluation of large multimodal models.URL https://arxiv. org/abs/2407.12772, 17, 2024
-
[44]
Beyond attention or similarity: Maximizing conditional diversity for token pruning in MLLMs
Qizhe Zhang, Mengzhen Liu, Lichen Li, Ming Lu, Yuan Zhang, Junwen Pan, Qi She, and Shanghang Zhang. Beyond attention or similarity: Maximizing conditional diversity for token pruning in MLLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=BLLixcuZgl. 12
work page 2026
-
[45]
Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms
Shaojie Zhang, Jiahui Yang, Jianqin Yin, Zhenbo Luo, and Jian Luan. Q-frame: Query-aware frame selection and multi-resolution adaptation for video-llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22056–22065, 2025
work page 2025
-
[46]
Mlvu: Benchmarking multi-task long video understanding
Junjie Zhou, Yan Shu, Bo Zhao, Boya Wu, Zhengyang Liang, Shitao Xiao, Minghao Qin, Xi Yang, Yongping Xiong, Bo Zhang, et al. Mlvu: Benchmarking multi-task long video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13691–13701, 2025
work page 2025
-
[47]
FOCUS: Efficient keyframe selection for long video understanding
Zirui Zhu, Hailun Xu, Yang Luo, Yong Liu, Kanchan Sarkar, Zhenheng Yang, and Yang You. FOCUS: Efficient keyframe selection for long video understanding. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=1OQKqLFcbB
work page 2026
-
[48]
Videolucy: Deep memory backtracking for long video understanding
Jialong Zuo, Yongtai Deng, Lingdong Kong, Jingkang Yang, Rui Jin, Yiwei Zhang, Nong Sang, Liang Pan, Ziwei Liu, and Changxin Gao. Videolucy: Deep memory backtracking for long video understanding. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URLhttps://openreview.net/forum?id=To7Rs2wsTd. 13 Table 5: Ablation study on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.