Recognition: no theorem link
Hedwig: Dynamic Autonomy for Coding Agents Under Local Oversight
Pith reviewed 2026-05-13 01:39 UTC · model grok-4.3
The pith
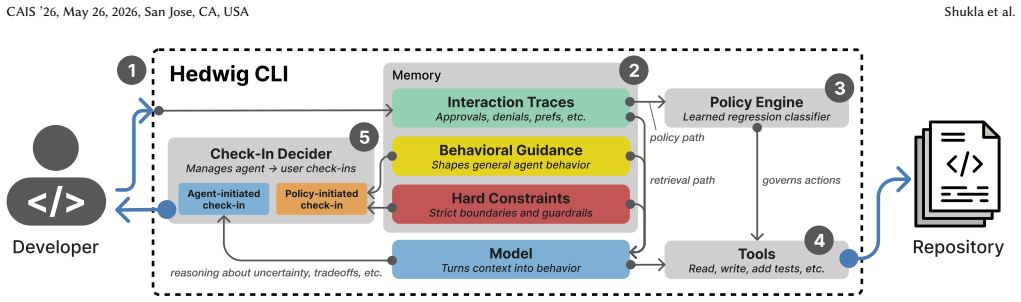
Hedwig is a coding agent that dynamically adjusts its autonomy by learning behavioral guidelines from developer decisions and feedback across sessions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Hedwig is a CLI coding agent that dynamically adjusts its autonomy level based on developer-agent interactions across sessions. Rather than operating on a global, fixed autonomy configuration, Hedwig learns an evolving set of behavioral guidelines from developer decisions and feedback, reducing friction on work for which the agent has earned trust, while tightening oversight when the agent operates outside familiar territory.
What carries the argument
The longitudinal learning of behavioral guidelines from developer decisions and feedback that directly controls when the agent acts independently or requests input.
Load-bearing premise
Developer decisions and feedback supply clear, consistent signals that can be turned into reliable guidelines for adjusting autonomy without adding new friction or mistakes.
What would settle it
A multi-session user study measuring whether Hedwig users produce fewer unintended edits, spend less time on oversight decisions, or report higher satisfaction than users of a static-permission coding agent; no measurable improvement would falsify the benefit of the dynamic approach.
Figures

read the original abstract
Despite coding agents' advances in handling increasingly complex tasks, their continued tendency to introduce unintended edits, subtle bugs, and scope drift that slip past code review means developers must still decide how much autonomy to grant them. However, existing approaches for setting an agent's level of autonomy, such as static permission settings or instruction files, cannot account for how developers' preferences for agent autonomy can shift across tasks and over time. We conducted a formative survey with 21 software engineers who use coding agents and found that they experience frustration with calibrating autonomy and have evolving preferences for level of oversight. Building on these insights, we present Hedwig, a CLI coding agent that dynamically adjusts its autonomy level based on developer-agent interactions across sessions. Rather than operating on a global, fixed autonomy configuration, Hedwig learns an evolving set of behavioral guidelines from developer decisions and feedback, reducing friction on work for which the agent has earned trust, while tightening oversight when the agent operates outside familiar territory. Hedwig demonstrates the potential of a new paradigm where agents intelligently adapt their level of autonomy based on user trust through active, longitudinal collaboration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that static autonomy settings for coding agents fail to accommodate developers' shifting preferences across tasks and time, as evidenced by a formative survey of 21 software engineers; it introduces Hedwig, a CLI coding agent that dynamically adjusts autonomy by learning an evolving set of behavioral guidelines from longitudinal developer decisions and feedback, thereby reducing friction in trusted areas while increasing oversight elsewhere.
Significance. If the described learning mechanism for autonomy calibration can be implemented and validated, the work could meaningfully advance HCI research on adaptive AI agents by establishing a longitudinal, interaction-driven alternative to fixed permission models. The survey provides initial qualitative grounding for user needs, and the conceptual design articulates a clear paradigm shift toward trust-based collaboration.
major comments (3)
- [Abstract / Hedwig system description] Abstract and Hedwig system description: The central claim that Hedwig 'learns an evolving set of behavioral guidelines from developer decisions and feedback' lacks any specification of the learning process, data structures for representing guidelines or trust, extraction algorithms, or update rules. This is load-bearing because the manuscript positions the learning mechanism as the key innovation enabling dynamic autonomy without new friction or errors, yet provides no basis for assessing feasibility or correctness.
- [Formative survey] Formative survey section: The survey (n=21) is invoked to establish that developers experience frustration with calibrating autonomy and hold evolving preferences, but no methodology details, question instruments, response distributions, or direct mapping from findings to specific behavioral guidelines are supplied. This undermines the motivation for the proposed design.
- [Evaluation / Results] Evaluation and results: No implementation, prototype metrics, user study, or longitudinal deployment data are reported to measure changes in oversight levels, error rates, task friction, or calibration accuracy across sessions. The abstract's assertion that Hedwig 'demonstrates the potential' of the paradigm therefore rests on an unevaluated concept rather than evidence.
minor comments (1)
- [Abstract] The abstract and introduction could explicitly note that the current contribution is a system concept and survey rather than a fully implemented and evaluated prototype, to set reader expectations.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which identifies key opportunities to improve the clarity, grounding, and scope of the manuscript. We address each major comment below, indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Hedwig system description] Abstract and Hedwig system description: The central claim that Hedwig 'learns an evolving set of behavioral guidelines from developer decisions and feedback' lacks any specification of the learning process, data structures for representing guidelines or trust, extraction algorithms, or update rules. This is load-bearing because the manuscript positions the learning mechanism as the key innovation enabling dynamic autonomy without new friction or errors, yet provides no basis for assessing feasibility or correctness.
Authors: We agree that the current manuscript describes the learning mechanism at a high conceptual level without specifying data structures, extraction methods, or update rules. This reflects the paper's focus on the HCI paradigm of longitudinal, trust-based autonomy adjustment rather than a systems implementation. In revision, we will expand the Hedwig system description to include proposed data structures (e.g., guideline representations as conditional rules paired with per-context trust scores), high-level extraction from interaction logs (e.g., identifying patterns in accepted edits or feedback), and update heuristics (e.g., threshold-based reinforcement or decay). These additions will provide a clearer feasibility basis while preserving the manuscript's emphasis on design principles over algorithmic detail; full pseudocode and implementation would be reserved for a follow-up systems paper. revision: partial
-
Referee: [Formative survey] Formative survey section: The survey (n=21) is invoked to establish that developers experience frustration with calibrating autonomy and hold evolving preferences, but no methodology details, question instruments, response distributions, or direct mapping from findings to specific behavioral guidelines are supplied. This undermines the motivation for the proposed design.
Authors: The referee is correct that the absence of survey methodology details weakens the grounding of the design motivation. We will add a new subsection to the formative survey section that reports recruitment approach, survey instrument (including sample questions on autonomy preferences and frustration points), participant demographics, and summarized response distributions. We will also explicitly map key findings (such as preferences for reduced oversight on familiar tasks) to specific elements of Hedwig's guideline-learning approach and autonomy calibration logic. revision: yes
-
Referee: [Evaluation / Results] Evaluation and results: No implementation, prototype metrics, user study, or longitudinal deployment data are reported to measure changes in oversight levels, error rates, task friction, or calibration accuracy across sessions. The abstract's assertion that Hedwig 'demonstrates the potential' of the paradigm therefore rests on an unevaluated concept rather than evidence.
Authors: We acknowledge that the manuscript contains no implementation, metrics, or user study data. Hedwig is presented as a conceptual design whose 'demonstration' consists of articulating how the paradigm would function in practice, informed by the formative survey. We will revise the abstract, introduction, and conclusion to explicitly frame the work as a design proposal and paradigm introduction, with the demonstration being illustrative rather than empirical. Evaluation via prototype and longitudinal studies is identified as future work. revision: yes
Circularity Check
No circularity: conceptual system proposal grounded in external survey data
full rationale
The manuscript contains no equations, derivations, fitted parameters, or predictive models. Its core contribution is a survey-informed system concept (Hedwig learns behavioral guidelines from interactions) rather than any computation that reduces to its own inputs by construction. The formative survey (n=21) supplies independent empirical motivation for the design choices, and no self-citation chains, uniqueness theorems, or ansatzes are invoked to justify load-bearing claims. This is a standard non-circular HCI/systems paper whose validity rests on future implementation and evaluation, not on internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Developers' preferences for agent autonomy evolve across tasks and sessions and can be inferred from their decisions and feedback.
invented entities (1)
-
Hedwig
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gagan Bansal, Besmira Nushi, Ece Kamar, Walter S. Lasecki, Daniel S. Weld, and Eric Horvitz. 2021. Does the Whole Exceed its Parts? The Effect of AI Explanations on Complementary Team Performance. InProceedings of the 2021 CHI Conference on Human Factors in Computing Systems
work page 2021
- [2]
-
[3]
KJ Kevin Feng, David W McDonald, and Amy X Zhang. 2025. Levels of Autonomy for AI Agents.Knight First Amendment Institute(2025). https://perma.cc/ETV7- M4Q9
work page 2025
- [4]
-
[5]
Ruanqianqian Huang, Avery Reyna, Sorin Lerner, Haijun Xia, and Brian Hempel
-
[6]
Professional Software Developers Don’t Vibe, They Control: AI Agent Use for Coding in 2025. arXiv:2512.14012
- [7]
-
[8]
Butler W. Lampson. 1971. Protection.Proceedings of the Fifth Princeton Symposium on Information Sciences and Systems(1971)
work page 1971
- [9]
-
[10]
Hussein Mozannar, Gagan Bansal, Cheng Tan, Adam Fourney, Victor Dibia, Jingya Chen, Jack Gerrits, Tyler Payne, Matheus Kunzler Maldaner, Madeleine Grunde-McLaughlin, Eric Zhu, Griffin Bassman, Jacob Alber, Peter Chang, Ricky Loynd, Friederike Niedtner, Ece Kamar, Maya Murad, Rafah Hosn, and Saleema Amershi. 2025. Magentic-UI: Towards Human-in-the-Loop Age...
-
[11]
Yi-Hao Peng, Dingzeyu Li, Jeffrey P. Bigham, and Amy Pavel. 2025. Morae: Proactively Pausing UI Agents for User Choices
work page 2025
-
[12]
Zora Zhiruo Wang, John Yang, Kilian Lieret, Alexa Tartaglini, Valerie Chen, Yux- iang Wei, Zijian Wang, Lingming Zhang, Karthik Narasimhan, Ludwig Schmidt, Graham Neubig, Daniel Fried, and Diyi Yang. 2025. Position: Humans are Miss- ing from AI Coding Agent Research. https://zorazrw.github.io/files/position- haicode.pdf
work page 2025
-
[13]
Jieyu Zhou, Aryan Roy, Sneh Gupta, Daniel Weitekamp, and Christopher J. MacLellan. 2026. When Should Users Check? Modeling Confirmation Frequency in Multi-Step Agentic AI Tasks. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. doi:10.1145/3772318.3790655 Appendix A Synthetic Trace Generation Each persona was defined as a pro...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.