Recognition: 1 theorem link
· Lean TheoremCTFusion: A CTF-based Benchmark for LLM Agent Evaluation
Pith reviewed 2026-05-13 01:33 UTC · model grok-4.3
The pith
Reused CTF challenges allow data contamination that inflates LLM agent scores, which CTFusion fixes by streaming evaluations from live events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CTFusion is a streaming evaluation framework built on live CTFs that preserves per-agent independence under a single team account and reduces competition impact by forwarding only the first correct flag per challenge, implemented as an MCP server on CTFd to support diverse events and agents.
What carries the argument
CTFusion streaming framework on CTFd, which enforces per-agent independence and first-flag-only forwarding to prevent contamination and competition effects during live evaluations.
Load-bearing premise
Live CTF events stay uncontaminated and the independence rule plus first-flag forwarding fully blocks data leakage and competition distortion.
What would settle it
An agent using web search succeeding on a CTFusion challenge whose live event had no prior public solutions or leaks.
Figures

















read the original abstract
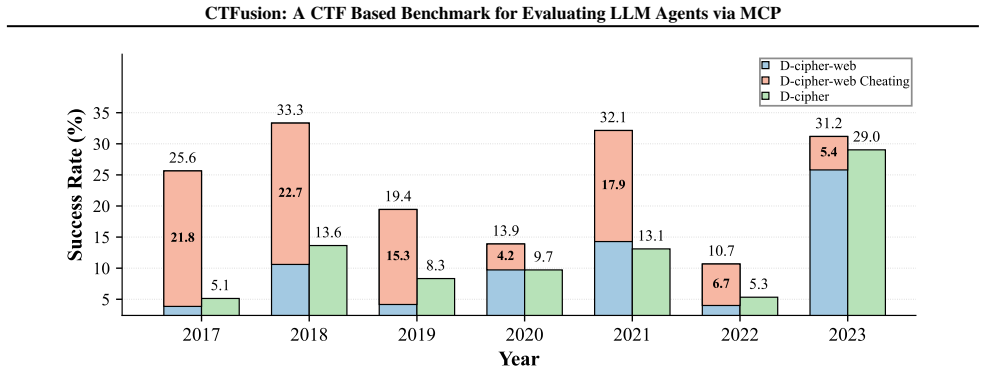
Recent advances in Large Language Models (LLMs) have enabled agentic systems for complex, multi-step tasks; cybersecurity is emerging as a prominent application. To evaluate such agents, researchers widely adopt Capture The Flag (CTF) benchmarks. However, current CTF benchmarks reuse existing challenges, which exposes them to data contamination and potential cheating. Notably, we confirmed these issues in practice by integrating web search tools into an existing agent. To address these limitations, we present CTFusion, a streaming evaluation framework built on Live CTFs. To achieve this, CTFusion preserves per-agent independence under a single team account and reduces competition impact by forwarding only the first correct flag per challenge. Moreover, we implement CTFusion as a Model Context Protocol (MCP) server on the widely used CTFd platform, which offers broad applicability to diverse CTF events and agent types. Through experiments with three LLMs, two agents, and five Live CTFs, we demonstrate that existing CTF benchmarks can be unreliable in assessing LLM-based agents, while CTFusion can serve as a robust solution for evaluating cybersecurity agents. We release CTFusion as open source to foster future research in this area.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing CTF benchmarks for LLM agents are unreliable due to data contamination and cheating (demonstrated via web-search tool integration experiments), and introduces CTFusion as a streaming framework for live CTFs. CTFusion achieves per-agent independence under a single team account and reduces competition impact by forwarding only the first correct flag per challenge; it is implemented as an MCP server on the CTFd platform. Experiments with three LLMs, two agents, and five live CTFs are used to support that CTFusion provides a robust alternative, with open-source release.
Significance. If the isolation and forwarding mitigations hold, this work addresses a critical and timely limitation in agent evaluation for cybersecurity, where reliable benchmarks are scarce. The open-source implementation on a widely used platform (CTFd) and the multi-LLM/multi-agent experimental setup are concrete strengths that could enable reproducible follow-up work and broader adoption in LLM agent research.
major comments (3)
- [CTFusion framework description (and abstract)] The central claim that CTFusion's two mitigations (per-agent independence under a shared team account + first-flag forwarding) fully neutralize both contamination and competition-impact problems requires stronger justification. The framework description does not specify how shared-account rate limits, platform logging, or sequential flag-submission order are prevented from creating observable differences between agents; without this, the 'robust solution' claim for live events rests on an untested isolation assumption.
- [Experiments (and abstract)] The experimental support for the unreliability of existing CTF benchmarks (via web-search integration) is only partially verifiable. The abstract and setup report results with three LLMs and two agents but omit full methods details, specific metrics, quantitative outcomes, or error analysis, weakening the load-bearing claim that current benchmarks are unreliable.
- [Live CTF setup and experiments] The assumption that live CTF events remain uncontaminated (and that the five selected events are representative) is not tested or discussed. Potential selection effects, prior exposure, or organizer-side leakage could still affect results, and no evidence is provided that the chosen live events avoid the contamination issues shown for static benchmarks.
minor comments (2)
- [Experiments] The abstract states experiments used 'five Live CTFs' but provides no list, table, or description of the specific events or challenges; adding this in the experimental section would improve reproducibility.
- [CTFusion implementation] Notation for agent independence and flag-forwarding logic could be clarified with a small diagram or pseudocode, as the current prose description leaves some implementation details ambiguous.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below, indicating where we agree revisions are needed to strengthen the presentation and justification.
read point-by-point responses
-
Referee: [CTFusion framework description (and abstract)] The central claim that CTFusion's two mitigations (per-agent independence under a shared team account + first-flag forwarding) fully neutralize both contamination and competition-impact problems requires stronger justification. The framework description does not specify how shared-account rate limits, platform logging, or sequential flag-submission order are prevented from creating observable differences between agents; without this, the 'robust solution' claim for live events rests on an untested isolation assumption.
Authors: We agree that the framework section would benefit from expanded technical details on the isolation mechanisms. In the revised manuscript we will elaborate on the MCP server implementation, specifying that submissions are queued server-side in a first-come-first-served manner without exposing order or timing to agents, that rate-limit handling occurs at the platform level to equalize impact across agents, and that logging strips any agent-identifying metadata. These design choices are already present in the released code; we will add explicit description and a short justification of why they prevent observable differences, thereby addressing the isolation assumption more directly. revision: yes
-
Referee: [Experiments (and abstract)] The experimental support for the unreliability of existing CTF benchmarks (via web-search integration) is only partially verifiable. The abstract and setup report results with three LLMs and two agents but omit full methods details, specific metrics, quantitative outcomes, or error analysis, weakening the load-bearing claim that current benchmarks are unreliable.
Authors: The full manuscript (Sections 3 and 4) already specifies the three LLMs, two agents, and the web-search integration experiment that demonstrates elevated success rates when external search is enabled. To improve verifiability we will expand the experiments section and add an appendix containing the complete method details (prompt templates, tool configurations), all quantitative success rates with and without search, and basic error analysis. The abstract will remain a high-level summary consistent with journal conventions. revision: partial
-
Referee: [Live CTF setup and experiments] The assumption that live CTF events remain uncontaminated (and that the five selected events are representative) is not tested or discussed. Potential selection effects, prior exposure, or organizer-side leakage could still affect results, and no evidence is provided that the chosen live events avoid the contamination issues shown for static benchmarks.
Authors: We will add a dedicated discussion subsection on the live-CTF experimental setup. It will describe the selection criteria for the five events (recency, diversity of challenge types, and public availability), explain why the live format inherently lowers the risk of pre-existing data contamination relative to static benchmarks, and acknowledge residual risks such as organizer-side leakage or selection effects. While exhaustive empirical verification of zero contamination is not feasible, the added discussion will make the assumptions and their limitations explicit. revision: yes
Circularity Check
No circularity in the engineering framework proposal
full rationale
The paper introduces CTFusion as an applied streaming evaluation framework on live CTFs, with per-agent independence and first-flag forwarding as design mitigations. No mathematical derivations, equations, fitted parameters, or self-citations appear in the provided text that reduce any central claim to its own inputs by construction. The confirmation of contamination issues is described as an empirical experiment with web-search tools, and the robustness claim rests on the stated engineering choices rather than any self-referential loop or renamed prior result. This is a self-contained applied contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM agents equipped with web search can solve or cheat on reused CTF challenges
- domain assumption Live CTF events supply challenges that have not been seen by the evaluated models
invented entities (1)
-
CTFusion streaming framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearCTFUSION preserves per-agent independence under a single team account and reduces competition impact by forwarding only the first correct flag per challenge.
Reference graph
Works this paper leans on
-
[1]
Minghao Shao and Sofija Jancheska and Meet Udeshi and Brendan Dolan-Gavitt and Haoran Xi and Kimberly Milner and Boyuan Chen and Max Yin and Siddharth Garg and Prashanth Krishnamurthy and Farshad Khorrami and Ramesh Karri and Muhammad Shafique , booktitle=. 2024 , url=
work page 2024
-
[2]
Benchmark Data Contamination of Large Language Models: A Survey , author=. 2024 , eprint=
work page 2024
-
[3]
Measuring and Augmenting Large Language Models for Solving Capture-the-Flag Challenges , author=. 2025 , eprint=
work page 2025
-
[4]
Don't Make Your LLM an Evaluation Benchmark Cheater , author=. 2023 , eprint=
work page 2023
-
[5]
Forty-second International Conference on Machine Learning , year=
DyCodeEval: Dynamic Benchmarking of Reasoning Capabilities in Code Large Language Models Under Data Contamination , author=. Forty-second International Conference on Machine Learning , year=
-
[6]
LastingBench: Defend Benchmarks Against Knowledge Leakage , author=. 2025 , eprint=
work page 2025
-
[7]
LiveBench: A Challenging, Contamination-Free
Colin White and Samuel Dooley and Manley Roberts and Arka Pal and Benjamin Feuer and Siddhartha Jain and Ravid Shwartz-Ziv and Neel Jain and Khalid Saifullah and Sreemanti Dey and Shubh-Agrawal and Sandeep Singh Sandha and Siddartha Venkat Naidu and Chinmay Hegde and Yann LeCun and Tom Goldstein and Willie Neiswanger and Micah Goldblum , booktitle=. LiveB...
-
[8]
Towards Effective Offensive Security LLM Agents: Hyperparameter Tuning, LLM as a Judge, and a Lightweight CTF Benchmark , author=. 2025 , eprint=
work page 2025
-
[9]
The Thirteenth International Conference on Learning Representations , year=
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[10]
Large Language Models for Cyber Security: A Systematic Literature Review , author=. 2025 , eprint=
work page 2025
-
[11]
Talor Abramovich and Meet Udeshi and Minghao Shao and Kilian Lieret and Haoran Xi and Kimberly Milner and Sofija Jancheska and John Yang and Carlos E Jimenez and Farshad Khorrami and Prashanth Krishnamurthy and Brendan Dolan-Gavitt and Muhammad Shafique and Karthik R Narasimhan and Ramesh Karri and Ofir Press , booktitle=. En. 2025 , url=
work page 2025
-
[12]
Network and Distributed System Security (NDSS) Symposium , year=
YURASCANNER: Leveraging LLMs for Task-driven Web App Scanning , author=. Network and Distributed System Security (NDSS) Symposium , year=
-
[13]
D-CIPHER: Dynamic Collaborative Intelligent Multi-Agent System with Planner and Heterogeneous Executors for Offensive Security , author=. 2025 , eprint=
work page 2025
- [14]
- [15]
- [16]
- [17]
- [18]
-
[19]
2017 USENIX Workshop on Advances in Security Education (ASE 17) , year =
Kevin Chung , title =. 2017 USENIX Workshop on Advances in Security Education (ASE 17) , year =
work page 2017
- [20]
-
[21]
The Vulnerability of Language Model Benchmarks: Do They Accurately Reflect True LLM Performance? , author=. 2024 , eprint=
work page 2024
-
[22]
arXiv preprint arXiv:2505.17107 , url=
CRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution , author=. arXiv preprint arXiv:2505.17107 , url=
-
[23]
Waisman, Nico , title =
- [24]
- [25]
- [26]
- [27]
- [28]
-
[29]
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
work page 2021
- [30]
-
[31]
Introducing GPT-4.1 in the API , year =
-
[32]
Gemini 2.5 Flash , year =
- [33]
-
[34]
DuckDuckGo, Inc. DuckDuckGo---Protection. Privacy. Peace of Mind. 2025
work page 2025
-
[35]
CTFd API , author =. 2025
work page 2025
-
[36]
An Empirical Evaluation of LLMs for Solving Offensive Security Challenges , author=. 2024 , eprint=
work page 2024
- [37]
-
[38]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[39]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[40]
M. J. Kearns , title =
-
[41]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[42]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[43]
Suppressed for Anonymity , author=
-
[44]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[45]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[46]
12th # EURODW, booktitle =
- [47]
- [48]
-
[49]
SIGOPS Oper. Syst. Rev. , year = 2016, month = mar, volume =
work page 2016
-
[50]
ACM Transactions on Information and System Security (TISSEC) , year = 2012, month = mar, volume =
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.