Recognition: 2 theorem links
· Lean TheoremLiBrA-Net: Lie-Algebraic Bilateral Affine Fields for Real-Time 4K Video Dehazing
Pith reviewed 2026-05-13 02:25 UTC · model grok-4.3
The pith
Atmospheric dehazing of video reduces to applying per-pixel affine transforms whose parameters come from low-resolution bilateral grids fused in a Lie algebra.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LiBrA-Net factorizes the spatiotemporal affine field into a spatial-color and a temporal bilateral sub-grid predicted at a fixed low resolution, fuses their coefficients in the gl(3) Lie algebra under group-theoretic regularization, maps the result to invertible GL(3) transforms via a Cayley parameterization, and restores high-frequency detail through a lightweight input-guided branch, achieving state-of-the-art performance on video dehazing benchmarks while running native 4K at 25 FPS with 6.12 million parameters.
What carries the argument
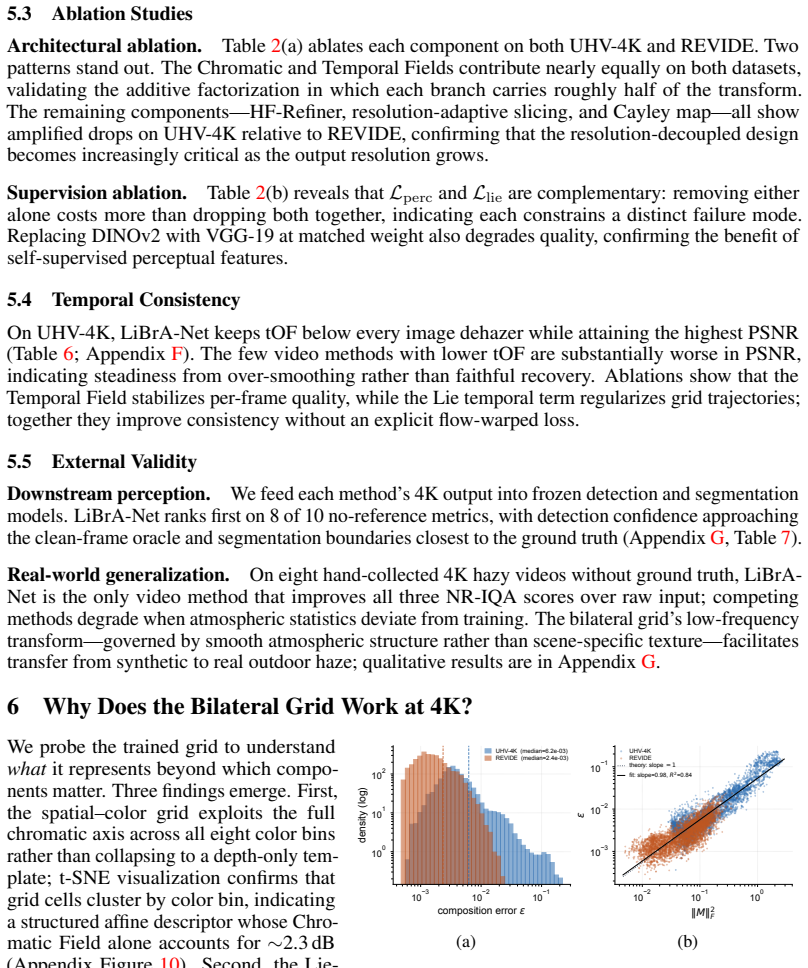
The Lie-algebraic bilateral affine field, which encodes the depth-governed per-pixel affine transform in low-resolution grids for efficient prediction decoupled from output resolution.
If this is right
- LiBrA-Net achieves a new state of the art on the UHV-4K, REVIDE, and HazeWorld video dehazing benchmarks.
- The method processes native 4K video at 25 frames per second on a single GPU using only 6.12 million parameters.
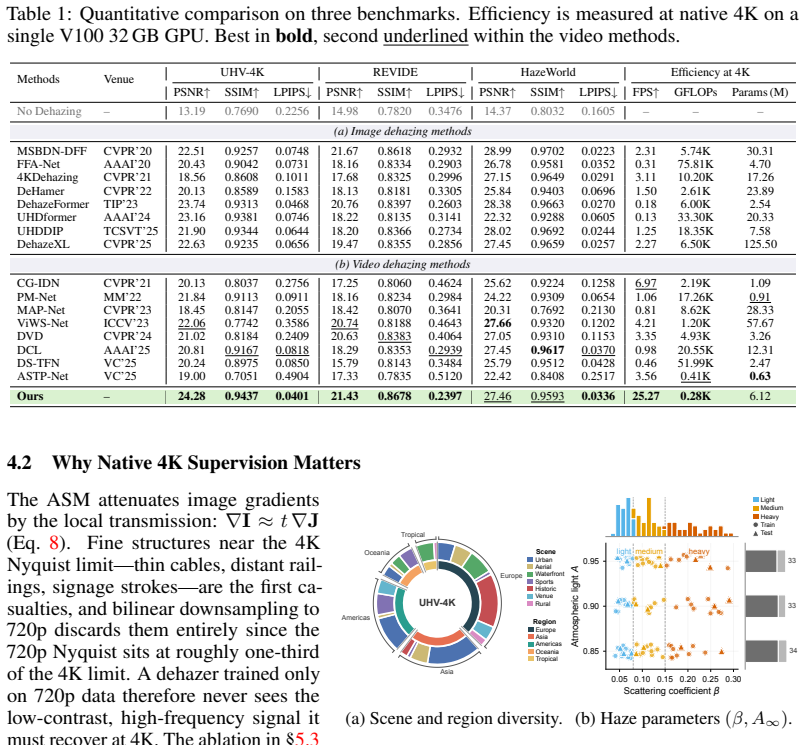
- A new benchmark dataset UHV-4K is released, providing paired hazy and clear 4K videos with depth, transmission, and optical flow annotations for every frame.
Where Pith is reading between the lines
- Similar bilateral grid encodings could be applied to other video restoration tasks where effects depend on low-frequency scene properties like depth or illumination.
- The use of Lie algebra fusion might provide a general way to regularize spatiotemporal consistency in learned video processing models.
- Testing the method on real-world captured hazy videos without synthetic pairing could reveal how well the affine model generalizes beyond the benchmark assumptions.
Load-bearing premise
Atmospheric dehazing reduces to a per-pixel affine transform governed by the low-frequency depth field, which can be compactly encoded in bilateral grids whose prediction cost is decoupled from the output resolution.
What would settle it
Running LiBrA-Net on a sequence of 4K frames where the haze formation deviates strongly from the depth-dependent affine model, such as in cases of non-uniform lighting or dense fog not following the atmospheric scattering equation, and observing if the output quality falls below prior methods or produces visible artifacts.
Figures




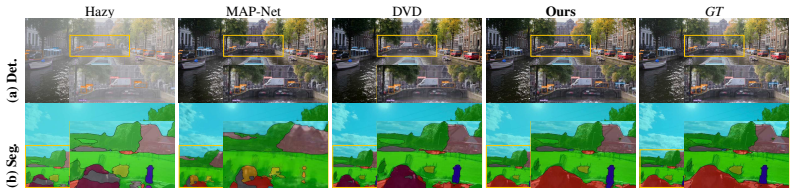



read the original abstract
Currently, there is a gap in the field of ultra-high-definition (UHD) video dehazing due to the lack of a benchmark for evaluation. Furthermore, existing video dehazing methods cannot run on consumer-grade GPUs when processing continuous UHD sequences of 3--5 frames at a time. In this paper, we address both issues with a new benchmark and an efficient method. Our key observation is that atmospheric dehazing reduces to a per-pixel affine transform governed by the low-frequency depth field, which can be compactly encoded in bilateral grids whose prediction cost is decoupled from the output resolution. Building on this, we propose LiBrA-Net, which factorizes the spatiotemporal affine field into a spatial--color and a temporal bilateral sub-grid predicted at a fixed low resolution, fuses their coefficients in the $\mathfrak{gl}(3)$ Lie algebra under group-theoretic regularization, maps the result to invertible GL(3) transforms via a Cayley parameterization, and restores high-frequency detail through a lightweight input-guided branch. We further release UHV-4K, the first paired 4K video dehazing benchmark with depth, transmission, and optical-flow annotations on every frame. Across UHV-4K, REVIDE, and HazeWorld, LiBrA-Net sets a new state of the art among compared video dehazing methods while running native 4K at 25 FPS on a single GPU with only 6.12 M parameters. Code and data are available at https://anonymous.4open.science/r/LiBrA-Net-42B8.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that atmospheric dehazing reduces to per-pixel affine transforms governed by a low-frequency depth field, which can be compactly encoded in bilateral grids whose prediction cost is decoupled from output resolution. It proposes LiBrA-Net, which factorizes the spatiotemporal affine field into spatial-color and temporal bilateral sub-grids predicted at fixed low resolution, fuses coefficients in the gl(3) Lie algebra under group-theoretic regularization, maps to invertible GL(3) transforms via Cayley parameterization, and restores high-frequency detail via a lightweight input-guided branch. The work also releases the UHV-4K benchmark (first paired 4K video dehazing dataset with depth, transmission, and optical-flow annotations per frame) and reports state-of-the-art results on UHV-4K, REVIDE, and HazeWorld while running native 4K at 25 FPS on a single GPU with 6.12 M parameters.
Significance. If the results hold, the work is significant because it directly addresses the documented gap in UHD video dehazing benchmarks and real-time methods for consumer GPUs. The bilateral-grid factorization combined with Lie-algebraic fusion and Cayley parameterization provides a principled, resolution-independent efficiency mechanism that follows from the standard atmospheric scattering model. The public release of the UHV-4K benchmark together with code and data is a clear strength that supports reproducibility and future research.
minor comments (3)
- [Abstract] Abstract: the code and data link points to an anonymous repository; replace with a permanent, non-anonymous link in the camera-ready version.
- [Abstract] Abstract: the SOTA claim would be strengthened by including one or two concrete quantitative metrics (e.g., average PSNR or SSIM gains) rather than stating the claim only qualitatively.
- [Method] Notation: the transition from gl(3) fusion to GL(3) via Cayley parameterization is described at a high level; a short explicit statement of the mapping (e.g., the Cayley transform formula) in the main text would improve readability for readers unfamiliar with Lie-group methods.
Simulated Author's Rebuttal
We thank the referee for their positive summary of LiBrA-Net and the UHV-4K benchmark, as well as the recommendation for minor revision. We appreciate the recognition of the significance of the Lie-algebraic factorization for resolution-independent efficiency and the public release of the first paired 4K video dehazing dataset with per-frame annotations.
Circularity Check
No significant circularity identified
full rationale
The paper grounds its approach in the standard atmospheric scattering model I = J·t + A(1-t), which is independently known to be a per-pixel affine transform whose coefficients are governed by transmission t (hence depth). Bilateral grids are a pre-existing, resolution-decoupled technique for representing low-frequency fields; the spatial-color/temporal factorization, gl(3) fusion, Cayley parameterization to GL(3), and input-guided high-frequency branch are explicit design decisions that follow from this model without reducing any claimed prediction to a fitted input or self-referential definition. No load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation appear in the derivation chain. The efficiency and benchmark claims are independent of the modeling steps and rest on external evaluation.
Axiom & Free-Parameter Ledger
free parameters (1)
- fixed low resolution of bilateral grids
axioms (1)
- domain assumption Atmospheric dehazing reduces to a per-pixel affine transform governed by the low-frequency depth field
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearatmospheric dehazing reduces to a per-pixel affine transform governed by the low-frequency depth field, which can be compactly encoded in bilateral grids
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearfuses their coefficients in the gl(3) Lie algebra under group-theoretic regularization, maps the result to invertible GL(3) transforms via a Cayley parameterization
Reference graph
Works this paper leans on
-
[1]
O-haze: a dehazing benchmark with real hazy and haze-free outdoor images
Codruta O Ancuti, Cosmin Ancuti, Radu Timofte, and Christophe De Vleeschouwer. O-haze: a dehazing benchmark with real hazy and haze-free outdoor images. InProceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 754–762, 2018
work page 2018
-
[2]
I-haze: A dehazing benchmark with real hazy and haze-free indoor images
Cosmin Ancuti, Codruta O Ancuti, Radu Timofte, and Christophe De Vleeschouwer. I-haze: A dehazing benchmark with real hazy and haze-free indoor images. InInternational conference on advanced concepts for intelligent vision systems, pages 620–631. Springer, 2018
work page 2018
-
[3]
Dana Berman, Tali treibitz, and Shai Avidan. Non-local image dehazing. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016
work page 2016
-
[4]
Jiawen Chen, Sylvain Paris, and Frédo Durand. Real-time edge-aware image processing with the bilateral grid.ACM Transactions on Graphics (TOG), 26(3):103–es, 2007
work page 2007
- [5]
-
[6]
Tokenize image patches: Global context fusion for effective haze removal in large images
Jiuchen Chen, Xinyu Yan, Qizhi Xu, and Kaiqi Li. Tokenize image patches: Global context fusion for effective haze removal in large images. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 2258–2268, June 2025
work page 2025
-
[7]
Multi-scale boosted dehazing network with dense feature fusion
Hang Dong, Jinshan Pan, Lei Xiang, Zhe Hu, Xinyi Zhang, Fei Wang, and Ming-Hsuan Yang. Multi-scale boosted dehazing network with dense feature fusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2157–2167, 2020
work page 2020
-
[8]
A.M. Eskicioglu and P.S. Fisher. Image quality measures and their performance.IEEE Transactions on Communications, 43(12):2959–2965, 1995. doi: 10.1109/26.477498
-
[9]
Depth-centric dehazing and depth-estimation from real-world hazy driving video, 2024
Junkai Fan, Kun Wang, Zhiqiang Yan, Xiang Chen, Shangbing Gao, Jun Li, and Jian Yang. Depth-centric dehazing and depth-estimation from real-world hazy driving video, 2024. URL https://arxiv.org/abs/2412.11395
-
[10]
Driving-video dehazing with non-aligned regularization for safety assistance
Junkai Fan, Jiangwei Weng, Kun Wang, Yijun Yang, Jianjun Qian, Jun Li, and Jian Yang. Driving-video dehazing with non-aligned regularization for safety assistance. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26109–26119, 2024
work page 2024
-
[11]
Michaël Gharbi, Jiawen Chen, Jonathan T Barron, Samuel W Hasinoff, and Frédo Durand. Deep bilateral learning for real-time image enhancement.ACM Transactions on Graphics (TOG), 36(4):1–12, 2017
work page 2017
-
[12]
3d packing for self-supervised monocular depth estimation
Vitor Guizilini, Rares Ambrus, Sudeep Pillai, Allan Raventos, and Adrien Gaidon. 3d packing for self-supervised monocular depth estimation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2485–2494, 2020
work page 2020
-
[13]
Image dehazing transformer with transmission-aware 3d position embedding
Chun-Le Guo, Qixin Yan, Saeed Anwar, Runmin Cong, Wenqi Ren, and Chongyi Li. Image dehazing transformer with transmission-aware 3d position embedding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5812–5820, 2022
work page 2022
-
[14]
Single image haze removal using dark channel prior
Kaiming He, Jian Sun, and Xiaoou Tang. Single image haze removal using dark channel prior. IEEE transactions on pattern analysis and machine intelligence, 33(12):2341–2353, 2010
work page 2010
-
[15]
Kaiming He, Jian Sun, and Xiaoou Tang. Guided image filtering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(6):1397–1409, 2013. doi: 10.1109/TPAMI.2012.213. 10
-
[16]
Orthogonal recurrent neural networks with scaled cayley transform
Kyle Helfrich, Devin Willmott, and Qiang Ye. Orthogonal recurrent neural networks with scaled cayley transform. InInternational Conference on Machine Learning, pages 1969–1978. PMLR, 2018
work page 1969
-
[17]
Learning blind video temporal consistency
Wei-Sheng Lai, Jia-Bin Huang, Oliver Wang, Eli Shechtman, Ersin Yumer, and Ming-Hsuan Yang. Learning blind video temporal consistency. InProceedings of the European conference on computer vision (ECCV), pages 170–185, 2018
work page 2018
-
[18]
Chenyang Lei, Yazhou Xing, and Qifeng Chen. Blind video temporal consistency via deep video prior.Advances in neural information processing systems, 33:1083–1093, 2020
work page 2020
-
[19]
Mario Lezcano-Casado and David Martínez-Rubio. Cheap orthogonal constraints in neu- ral networks: A simple parametrization of the orthogonal and unitary group. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Con- ference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 3794–3803...
work page 2019
-
[20]
End-to-end united video dehazing and detection
Boyi Li, Xiulian Peng, Zhangyang Wang, Jizheng Xu, and Dan Feng. End-to-end united video dehazing and detection. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
work page 2018
-
[21]
Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. Benchmarking single-image dehazing and beyond.IEEE transactions on image processing, 28 (1):492–505, 2018
work page 2018
-
[22]
Embedding fourier for ultra-high-definition low-light image enhancement
Chongyi Li, Chunle Guo, Man Zhou, Zhexin Liang, Shangchen Zhou, Ruicheng Feng, and Chen Change Loy. Embedding fourier for ultra-high-definition low-light image enhancement. ArXiv, abs/2302.11831, 2023
-
[23]
Phase-based memory network for video dehazing
Ye Liu, Liang Wan, Huazhu Fu, Jing Qin, and Lei Zhu. Phase-based memory network for video dehazing. InProceedings of the 30th ACM international conference on multimedia, pages 5427–5435, 2022
work page 2022
-
[24]
Yidi Liu, Dong Li, Xueyang Fu, Xin Lu, Jie Huang, and Zheng-Jun Zha. Uhd-processer: Unified uhd image restoration with progressive frequency learning and degradation-aware prompts. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 23121–23130, 2025
work page 2025
-
[25]
Uvg dataset: 50/120fps 4k sequences for video codec analysis and development
Alexandre Mercat, Marko Viitanen, and Jarno Vanne. Uvg dataset: 50/120fps 4k sequences for video codec analysis and development. InProceedings of the 11th ACM multimedia systems conference, pages 297–302, 2020
work page 2020
-
[26]
Vision and the atmosphere.International journal of computer vision, 48(3):233–254, 2002
Srinivasa G Narasimhan and Shree K Nayar. Vision and the atmosphere.International journal of computer vision, 48(3):233–254, 2002
work page 2002
-
[27]
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick L...
work page 2024
-
[28]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Arbeláez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017
work page internal anchor Pith review arXiv 2017
-
[29]
Ffa-net: Feature fusion attention network for single image dehazing
Xu Qin, Zhilin Wang, Yuanchao Bai, Xiaodong Xie, and Huizhu Jia. Ffa-net: Feature fusion attention network for single image dehazing. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 11908–11915, 2020. 11
work page 2020
-
[30]
Wenqi Ren, Jingang Zhang, Xiangyu Xu, Lin Ma, Xiaochun Cao, Gaofeng Meng, and Wei Liu. Deep video dehazing with semantic segmentation.IEEE Transactions on Image Processing, 28 (4):1895–1908, 2019. doi: 10.1109/TIP.2018.2876178
-
[31]
Vision transformers for single image dehazing
Yuda Song, Zhuqing He, Hui Qian, and Xin Du. Vision transformers for single image dehazing. IEEE Transactions on Image Processing, 32:1927–1941, 2023. doi: 10.1109/TIP.2023.3256763
-
[32]
Alexandros Stergiou and Ronald Poppe. Adapool: Exponential adaptive pooling for information- retaining downsampling.IEEE Transactions on Image Processing, 32:251–266, 2022
work page 2022
-
[33]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402–419. Springer, 2020
work page 2020
-
[34]
Selvaraju, Michael Cogswell, Ab- hishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra
C. Tomasi and R. Manduchi. Bilateral filtering for gray and color images. InSixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), pages 839–846, 1998. doi: 10.1109/ICCV .1998.710815
-
[35]
Ultralytics. Yolov8, 2023. URLhttps://github.com/ultralytics/ultralytics
work page 2023
-
[36]
Correlation matching transformation transformers for uhd image restoration, 2024
Cong Wang, Jinshan Pan, Wei Wang, Gang Fu, Siyuan Liang, Mengzhu Wang, Xiao-Ming Wu, and Jun Liu. Correlation matching transformation transformers for uhd image restoration, 2024. URLhttps://arxiv.org/abs/2406.00629
-
[37]
Liyan Wang, Cong Wang, Jinshan Pan, Xiaofeng Liu, Weixiang Zhou, Xiaoran Sun, Wei Wang, and Zhixun Su. Ultra-high-definition image restoration: New benchmarks and a dual interaction prior-driven solution.IEEE Transactions on Circuits and Systems for Video Technology, 2025
work page 2025
-
[38]
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612,
-
[39]
doi: 10.1109/TIP.2003.819861
-
[40]
Longyin Wen, Dawei Du, Zhaowei Cai, Zhen Lei, Ming-Ching Chang, Honggang Qi, Jongwoo Lim, Ming-Hsuan Yang, and Siwei Lyu. Ua-detrac: A new benchmark and protocol for multi-object detection and tracking.Computer Vision and Image Understanding, 193:102907, 2020
work page 2020
-
[41]
Video dehazing via a dual-stage temporal fusion net: J
Junwei Xi, Zhihua Chen, Lei Dai, and Lei Liang. Video dehazing via a dual-stage temporal fusion net: J. xi et al.The Visual Computer, 41(11):8569–8578, 2025
work page 2025
-
[42]
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers.Advances in neural information processing systems, 34:12077–12090, 2021
work page 2021
-
[43]
Yiming Xie, Henglu Wei, Zhenyi Liu, Xiaoyu Wang, and Xiangyang Ji. Synfog: A photo- realistic synthetic fog dataset based on end-to-end imaging simulation for advancing real-world defogging in autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21763–21772, 2024
work page 2024
-
[44]
Video dehazing via a multi-range temporal alignment network with physical prior, 2023
Jiaqi Xu, Xiaowei Hu, Lei Zhu, Qi Dou, Jifeng Dai, Yu Qiao, and Pheng-Ann Heng. Video dehazing via a multi-range temporal alignment network with physical prior, 2023. URL https://arxiv.org/abs/2303.09757
-
[45]
Canqian Yang, Meiguang Jin, Xu Jia, Yi Xu, and Ying Chen. Adaint: Learning adaptive intervals for 3d lookup tables on real-time image enhancement.2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17501–17510, 2022
work page 2022
-
[46]
Seplut: Separable image-adaptive lookup tables for real-time image enhancement
Canqian Yang, Meiguang Jin, Yi Xu, Rui Zhang, Ying Chen, and Huaida Liu. Seplut: Separable image-adaptive lookup tables for real-time image enhancement. InEuropean Conference on Computer Vision, pages 201–217. Springer, 2022
work page 2022
-
[47]
Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything v2.Advances in Neural Information Processing Systems, 37:21875– 21911, 2024. 12
work page 2024
-
[48]
Yijun Yang, Angelica I Aviles-Rivero, Huazhu Fu, Ye Liu, Weiming Wang, and Lei Zhu. Video adverse-weather-component suppression network via weather messenger and adversarial backpropagation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13200–13210, 2023
work page 2023
-
[49]
Huiyu Zeng, Jianrui Cai, Lida Li, Zisheng Cao, and Lei Zhang. Learning image-adaptive 3d lookup tables for high performance photo enhancement in real-time.IEEE Transactions on Pattern Analysis and Machine Intelligence, 44:2058–2073, 2020
work page 2058
-
[50]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018. doi: 10.1109/CVPR.2018.00068
-
[51]
Xinyi Zhang, Hang Dong, Jinshan Pan, Chao Zhu, Ying Tai, Chengjie Wang, Jilin Li, Feiyue Huang, and Fei Wang. Learning to restore hazy video: A new real-world dataset and a new method. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9235–9244, 2021. doi: 10.1109/CVPR46437.2021.00912
-
[52]
Wang Zhen, Liu Yanli, Xing Guanyu, and Wei Housheng. Adaptive spatiotemporal par- titioning for efficient video dehazing: Adaptive spatiotemporal partitioning for efficient video dehazing.Vis. Comput., 41(14):12055–12070, August 2025. ISSN 0178-2789. doi: 10.1007/s00371-025-04144-9. URLhttps://doi.org/10.1007/s00371-025-04144-9
-
[53]
Zhuoran Zheng, Wenqi Ren, Xiaochun Cao, Xiaobin Hu, Tao Wang, Fenglong Song, and Xiuyi Jia. Ultra-high-definition image dehazing via multi-guided bilateral learning. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16180–16189, 2021. doi: 10.1109/CVPR46437.2021.01592. A Proof of Proposition 1 We restate the result for co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.