Recognition: 2 theorem links
· Lean TheoremPost-ADC Inference: Valid Inference After Active Data Collection
Pith reviewed 2026-05-13 01:45 UTC · model grok-4.3
The pith
Post-ADC inference corrects selection biases from both active data collection and data-driven targets to deliver valid p-values and confidence intervals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Post-ADC inference accounts for the biases arising from both the active data collection process and the subsequent data-driven target construction by building on selective inference, thereby providing valid p-values and confidence intervals that apply to a broad class of ADC processes under only assumptions on the observation noise.
What carries the argument
The post-ADC inference framework, an extension of selective inference that simultaneously corrects for adaptive sampling bias and data-dependent target selection.
If this is right
- Valid p-values and confidence intervals become available for data collected by GP-UCB and TPE.
- The same guarantees hold for any ADC process whose sampling depends only on past observations under the stated noise assumptions.
- No modeling assumptions are needed about the underlying black-box function or the surrogate used during collection.
- Both sources of bias, adaptive sampling and data-driven target construction, are corrected simultaneously.
Where Pith is reading between the lines
- The framework could support reliable post-hoc hypothesis tests on the outcomes of hyperparameter optimization or neural architecture search runs.
- Similar corrections might be developed for other adaptive collection settings such as sequential experimental design or online A/B testing.
- Future implementations could integrate the method directly into existing SMBO libraries to report inference results alongside optimization traces.
Load-bearing premise
The observation noise must obey conditions that let selective inference produce exact or asymptotic validity, without any requirements on the black-box function or the surrogate model.
What would settle it
A Monte Carlo experiment in which the p-values produced by post-ADC inference under the null hypothesis are not uniformly distributed between zero and one, or the associated confidence intervals fail to attain nominal coverage.
Figures
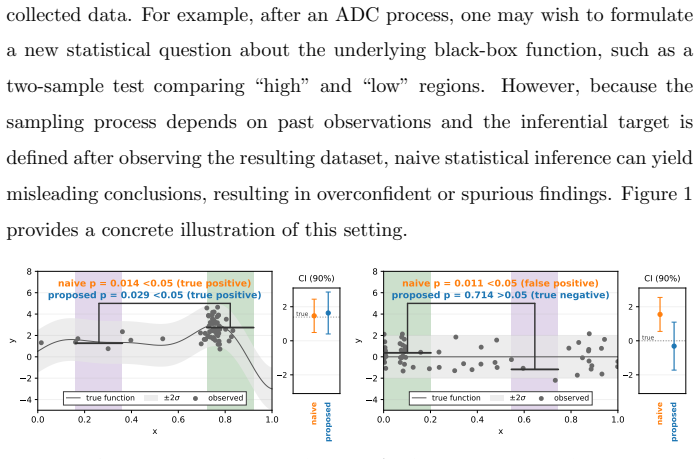
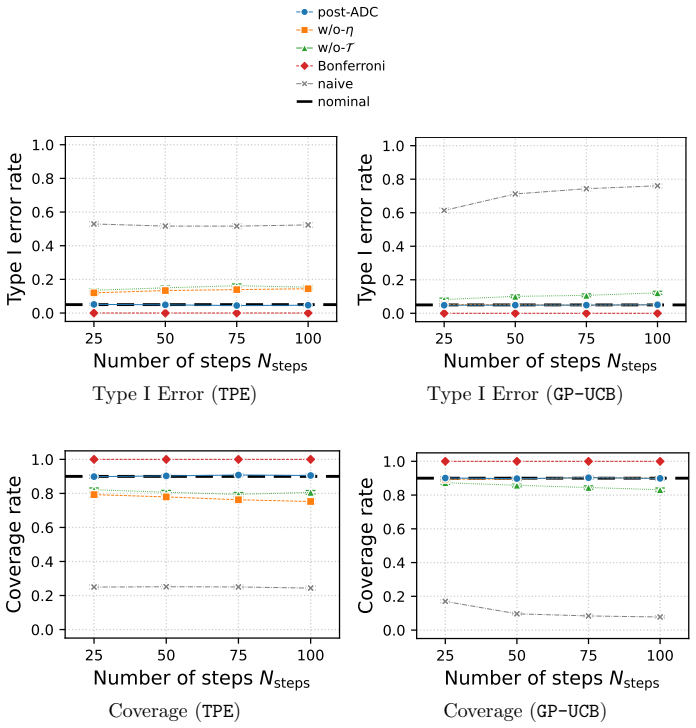
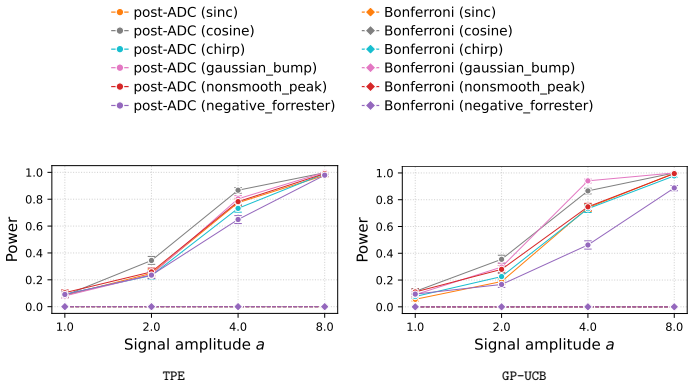



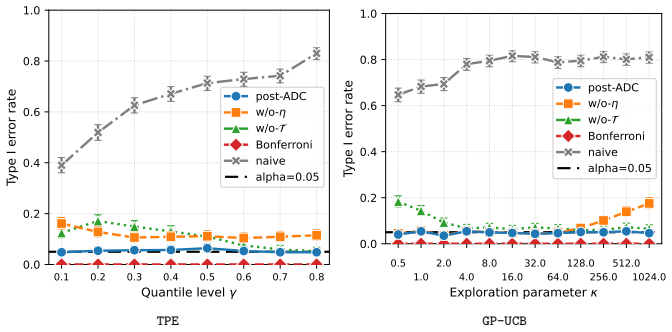
read the original abstract
The validity of statistical inference depends critically on how data are collected. When data gathered through active data collection (ADC) are reused for a post-hoc inferential task, conventional inference can fail because the sampling is adaptively biased toward regions favored by the collection strategy. This issue is especially pronounced in black-box optimization, where sequential model-based optimization (SMBO) methods such as the tree-structured Parzen estimator (TPE) and Gaussian process upper confidence bound (GP-UCB) preferentially concentrate evaluations in promising regions. We study statistical inference on actively collected data when the inferential target is constructed in a data-dependent manner after data collection. To enable valid inference in this setting, we propose post-ADC inference, a framework that accounts for the biases arising from both the active data collection process and the subsequent data-driven target construction. Our method builds on selective inference and provides valid $p$-values and confidence intervals that correct for both sources of bias. The framework applies to a broad class of ADC processes by imposing only assumptions on the observation noise, without requiring any assumptions on the underlying black-box function or the surrogate model used by the SMBO algorithm. Empirical results also show that post-ADC inference provides valid inference for data collected by GP-UCB and TPE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes post-ADC inference, a selective-inference framework for valid p-values and confidence intervals after active data collection (ADC) via SMBO algorithms such as GP-UCB and TPE. The inferential target may be constructed data-dependently after collection; the method corrects for selection bias from both the adaptive sampling path and the target construction. Validity is claimed to hold under noise-model assumptions alone, with no requirements on the black-box function or the surrogate model used by the ADC procedure. Empirical checks on GP-UCB and TPE data are reported to confirm validity.
Significance. If the central claim holds, the work would provide a practical tool for post-hoc inference on adaptively collected data in black-box optimization, extending selective-inference techniques to settings where both the sampling and the target are data-driven. The claimed generality (noise assumptions only) would be a strength relative to methods that require surrogate-specific derivations.
major comments (2)
- [Abstract] Abstract: the claim that the framework 'imposes only assumptions on the observation noise, without requiring any assumptions on ... the surrogate model' is load-bearing for the generality result, yet the selection event for TPE encodes the Parzen-estimator density ratios and sampling steps at each iteration. It is unclear how the conditional distribution of the data given the full adaptive path can be characterized (exactly or via Monte Carlo) without reference to the surrogate's update mechanics; a derivation or explicit algorithm showing surrogate-agnostic conditioning is needed.
- [Abstract] Abstract (and empirical section): the manuscript asserts that empirical checks on GP-UCB and TPE data succeed, but supplies neither a derivation/proof sketch for the conditional distribution nor a detailed protocol (number of Monte Carlo draws, exact conditioning event definition, coverage tables). Without these, the support for exact validity cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments on our manuscript. We address each major comment below, providing clarifications on the framework's generality and committing to additions that strengthen the presentation of the conditional distribution and empirical protocol.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the framework 'imposes only assumptions on the observation noise, without requiring any assumptions on ... the surrogate model' is load-bearing for the generality result, yet the selection event for TPE encodes the Parzen-estimator density ratios and sampling steps at each iteration. It is unclear how the conditional distribution of the data given the full adaptive path can be characterized (exactly or via Monte Carlo) without reference to the surrogate's update mechanics; a derivation or explicit algorithm showing surrogate-agnostic conditioning is needed.
Authors: The surrogate-agnostic claim means that the validity theorem depends only on the noise distribution and places no restrictions on the form of the surrogate or black-box function. To characterize the conditional distribution given the observed adaptive path, we use Monte Carlo sampling: draw fresh noise realizations from the assumed model, adjust the observed responses accordingly, and re-execute the identical ADC procedure (including all surrogate updates and sampling rules) that produced the original data. Because the practitioner knows and can re-run their chosen surrogate, this procedure requires no additional modeling assumptions. We will add an explicit algorithm box together with a short derivation sketch in the revised manuscript to detail the conditioning step. revision: yes
-
Referee: [Abstract] Abstract (and empirical section): the manuscript asserts that empirical checks on GP-UCB and TPE data succeed, but supplies neither a derivation/proof sketch for the conditional distribution nor a detailed protocol (number of Monte Carlo draws, exact conditioning event definition, coverage tables). Without these, the support for exact validity cannot be evaluated.
Authors: We agree that the current version lacks sufficient implementation detail. In the revision we will insert a proof sketch deriving the conditional distribution under the noise model, give the precise definition of the conditioning event (the full sequence of sampling decisions plus the data-dependent target construction), report the Monte Carlo protocol (10,000 draws in the reported experiments), and supply coverage tables for both GP-UCB and TPE to allow direct evaluation of the empirical results. revision: yes
Circularity Check
No significant circularity; derivation rests on external selective-inference conditioning
full rationale
The paper's central construction conditions the target statistic on the observed ADC selection path under a noise model only. This conditioning step is defined independently of the final inferential target and does not reduce any reported p-value or CI to a fitted parameter or self-referential quantity by construction. The framework explicitly invokes the established selective-inference machinery for the selection event; no load-bearing premise collapses to a self-citation, an ansatz smuggled via prior work, or a renaming of an empirical pattern. The generality claim (no assumptions on f or surrogate) is a correctness question rather than a definitional loop, and the derivation chain remains non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Observation noise satisfies standard conditions (e.g., independence, known distribution family) sufficient for the selective-inference correction to remain valid.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearThe framework applies to a broad class of ADC processes by imposing only assumptions on the observation noise, without requiring any assumptions on the underlying black-box function or the surrogate model... conditional distribution of the test statistic admits a closed-form expression... truncated normal distribution TN(Δ_sel, v_η, Z)
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_injective unclearconditioning on the selection event E_Y=(T_Y, η_Y)... T(Y)|{E_Y=E_y, Q_Y=Q_y} ∼ TN(Δ_sel, v_η, Z)
Reference graph
Works this paper leans on
-
[1]
Donald R Jones, Matthias Schonlau, and William J Welch. Efficient global optimization of expensive black-box functions.Journal of Global optimiza- tion, 13(4):455–492, 1998
work page 1998
-
[2]
Gaussian process optimization in the bandit setting: no regret and exper- imental design
Niranjan Srinivas, Andreas Krause, Sham Kakade, and Matthias Seeger. Gaussian process optimization in the bandit setting: no regret and exper- imental design. InProceedings of the 27th International Conference on International Conference on Machine Learning, ICML’10, page 1015–1022, Madison, WI, USA, 2010. Omnipress
work page 2010
-
[3]
Algo- rithms for hyper-parameter optimization
James Bergstra, R´ emi Bardenet, Yoshua Bengio, and Bal´ azs K´ egl. Algo- rithms for hyper-parameter optimization. InAdvances in Neural Informa- tion Processing Systems 24, pages 2546–2554, 2011
work page 2011
-
[4]
Frank Hutter, Holger H. Hoos, and Kevin Leyton-Brown. Sequential model- based optimization for general algorithm configuration. In Carlos A. Coello Coello, editor,Learning and Intelligent Optimization, volume 6683 ofLec- ture Notes in Computer Science, pages 507–523. Springer, 2011
work page 2011
-
[5]
Peter I. Frazier. Bayesian optimization. InINFORMS TutORials in Oper- ations Research: Recent Advances in Optimization and Modeling of Con- temporary Problems, pages 255–278. INFORMS, 2018
work page 2018
-
[6]
Yoav Benjamini, Ruth Heller, and Daniel Yekutieli. Selective inference in complex research.Philosophical Transactions of the Royal Society A: Math- ematical, Physical and Engineering Sciences, 367(1906):4255–4271, 2009
work page 1906
-
[7]
Optimal inference after model selection.arXiv preprint arXiv:1410.2597, 2014
William Fithian, Dennis Sun, and Jonathan Taylor. Optimal inference after model selection.arXiv preprint arXiv:1410.2597, 2014
-
[8]
Jason D Lee, Dennis L Sun, Yuekai Sun, and Jonathan E Taylor. Ex- act post-selection inference, with application to the lasso.The Annals of Statistics, 44(3):907–927, 2016. 54
work page 2016
-
[9]
Exact post-selection inference for sequential regression procedures
Ryan J Tibshirani, Jonathan Taylor, Richard Lockhart, and Robert Tib- shirani. Exact post-selection inference for sequential regression procedures. Journal of the American Statistical Association, 111(514):600–620, 2016
work page 2016
-
[10]
Jonathan Taylor and Robert Tibshirani. Post-selection inference for- penalized likelihood models.Canadian Journal of Statistics, 46(1):41–61, 2018
work page 2018
-
[11]
Selective inference with a randomized response.The Annals of Statistics, 46(2):679–710, 2018
Xiaoying Tian and Jonathan Taylor. Selective inference with a randomized response.The Annals of Statistics, 46(2):679–710, 2018
work page 2018
-
[12]
Asymptotics of selective inference
Xiaoying Tian and Jonathan Taylor. Asymptotics of selective inference. Scandinavian Journal of Statistics, 44(2):480–499, 2017
work page 2017
-
[13]
Selective inference for group-sparse linear models
Fan Yang, Rina Foygel Barber, Prateek Jain, and John Lafferty. Selective inference for group-sparse linear models. InAdvances in Neural Information Processing Systems, pages 2469–2477, 2016
work page 2016
-
[14]
Keli Liu, Jelena Markovic, and Robert Tibshirani. More powerful post-selection inference, with application to the lasso.arXiv preprint arXiv:1801.09037, 2018
-
[15]
Sangwon Hyun, Max G’sell, and Ryan J Tibshirani. Exact post-selection inference for the generalized lasso path.Electronic Journal of Statistics, 12(1):1053–1097, 2018
work page 2018
-
[16]
Selective inference: The silent killer of replicability
Yoav Benjamini. Selective inference: The silent killer of replicability. 2020
work page 2020
-
[17]
Jonathan Taylor, Richard Lockhart, Ryan J Tibshirani, and Robert Tib- shirani. Post-selection adaptive inference for least angle regression and the lasso.arXiv preprint arXiv:1401.3889, 354, 2014
-
[18]
Selective sequential model selection.arXiv preprint arXiv:1512.02565, 2015
William Fithian, Jonathan Taylor, Robert Tibshirani, and Ryan Tibshi- rani. Selective sequential model selection.arXiv preprint arXiv:1512.02565, 2015. 55
-
[19]
Lucy L Gao, Jacob Bien, and Daniela Witten. Selective inference for hier- archical clustering.Journal of the American Statistical Association, pages 1–11, 2022
work page 2022
-
[20]
Vo Nguyen Le Duy, Shogo Iwazaki, and Ichiro Takeuchi. Quantifying statis- tical significance of neural network-based image segmentation by selective inference.Advances in Neural Information Processing Systems, 35:31627– 31639, 2022
work page 2022
-
[21]
Valid p-value for deep learning-driven salient region
Daiki Miwa, Duy Vo Nguyen Le, and Ichiro Takeuchi. Valid p-value for deep learning-driven salient region. InProceedings of the 11th International Conference on Learning Representation, 2023
work page 2023
-
[22]
Statistical test for feature selection pipelines by selective in- ference
Tomohiro Shiraishi, Tatsuya Matsukawa, Shuichi Nishino, and Ichiro Takeuchi. Statistical test for feature selection pipelines by selective in- ference. InForty-second International Conference on Machine Learning, 2025
work page 2025
-
[23]
Statistical test for auto feature engineering by selective inference
Tatsuya Matsukawa, Tomohiro Shiraishi, Shuichi Nishino, Teruyuki Kat- suoka, and Ichiro Takeuchi. Statistical test for auto feature engineering by selective inference. InThe 28th International Conference on Artificial Intelligence and Statistics, 2025
work page 2025
-
[24]
Jelena Markovic, Lucy Xia, and Jonathan Taylor. Unifying approach to selective inference with applications to cross-validation.arXiv preprint arXiv:1703.06559, 2017
-
[25]
Why adap- tively collected data have negative bias and how to correct for it
Xinkun Nie, Xiaoying Tian, Jonathan Taylor, and James Zou. Why adap- tively collected data have negative bias and how to correct for it. InProceed- ings of the Twenty-First International Conference on Artificial Intelligence and Statistics, volume 84 ofProceedings of Machine Learning Research, pages 1261–1269. PMLR, 2018
work page 2018
-
[26]
Selective randomization inference for adaptive experiments.arXiv preprint arXiv:2405.07026, 2024
Tobias Freidling, Qingyuan Zhao, and Zijun Gao. Selective randomization inference for adaptive experiments.arXiv preprint arXiv:2405.07026, 2024. 56
-
[27]
Optimal conditional inference in adap- tive experiments.arXiv preprint arXiv:2309.12162, 2023
Jiafeng Chen and Isaiah Andrews. Optimal conditional inference in adap- tive experiments.arXiv preprint arXiv:2309.12162, 2023
-
[28]
Danijel Kivaranovic and Hannes Leeb. A (tight) upper bound for the length of confidence intervals with conditional coverage.Electronic Journal of Statistics, 18(1):1677–1701, 2024
work page 2024
-
[29]
Erich Leo Lehmann, Joseph P Romano, et al.Testing statistical hypotheses, volume 3. Springer, 1986. 57
work page 1986
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.