Recognition: no theorem link
GriNNder: Breaking the Memory Capacity Wall in Full-Graph GNN Training with Storage Offloading
Pith reviewed 2026-05-13 01:52 UTC · model grok-4.3
The pith
GriNNder enables full-graph GNN training on a single GPU by offloading data to storage devices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
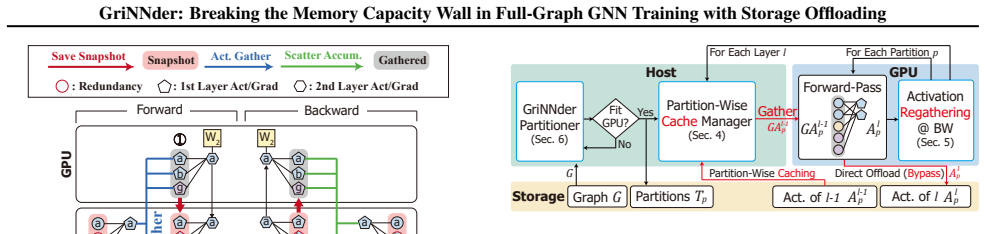
GriNNder is the first system to use storage offloading for full-graph GNN training under memory constraints by introducing structured storage offloading (SSO). SSO coordinates caching in host memory based on cross-partition dependencies, regathers data for gradient computation to eliminate redundant storage accesses, and applies lightweight partitioning to reduce memory needs.
What carries the argument
Structured storage offloading (SSO), which manages the GPU-host-storage hierarchy using coordinated cache, regather, and bypass mechanisms tailored to GNN access patterns.
If this is right
- Full-graph training becomes feasible for graphs that exceed available memory capacities.
- Training achieves speedups of up to 9.78 times compared to previous single-server approaches.
- Throughput reaches levels comparable to those of distributed multi-server systems.
- Large-scale GNN training no longer requires multiple GPUs or servers.
Where Pith is reading between the lines
- This method could be adapted for other machine learning workloads that involve large, irregularly accessed datasets.
- Adoption might significantly reduce the infrastructure costs for training large graph models in resource-limited settings.
- Testing on graphs with varying sparsity or different storage hardware would reveal the limits of the offloading benefits.
Load-bearing premise
The overhead of storage accesses stays low enough, thanks to GNN data patterns and modern SSD bandwidth, that the system outperforms methods limited by memory without excessive added latency.
What would settle it
A direct comparison of training time and accuracy on a large graph using GriNNder versus a memory-constrained baseline, checking if the storage-based method completes faster without accuracy loss.
Figures
















read the original abstract
Full-graph training of graph neural networks (GNNs) is widely used as it enables direct validation of algorithmic improvements by preserving complete neighborhood information. However, it typically requires multiple GPUs or servers, incurring substantial hardware and inter-device communication costs. While existing single-server methods reduce infrastructure requirements, they remain constrained by GPU and host memory capacity as graph sizes increase. To address this limitation, we introduce GriNNder, which is the first work to leverage storage devices to enable full-graph training even with limited memory. Because modern NVMe SSDs offer multi-terabyte capacities and bandwidths exceeding 10 GB/s, they provide an appealing option when memory resources are scarce. Yet, directly applying storage-based methods from other domains fails to address the unique access patterns and data dependencies in full-graph GNN training. GriNNder tackles these challenges by structured storage offloading (SSO), a framework that manages the GPU-host-storage hierarchy through coordinated cache, (re)gather, and bypass mechanisms. To realize the framework, we devise (i) a partition-wise caching strategy for host memory that exploits the observation on cross-partition dependencies, (ii) a regathering strategy for gradient computation that eliminates redundant storage operations, and (iii) a lightweight partitioning scheme that mitigates the memory requirements of existing graph partitioners. In experiments performed over various models and datasets, GriNNder achieves up to 9.78x speedup over state-of-the-art baselines and throughput comparable to distributed systems, enabling previously infeasible large-scale full-graph training even on a single GPU.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GriNNder, a system for full-graph GNN training on single-GPU hardware with limited memory by offloading to high-bandwidth NVMe SSD storage. It proposes a structured storage offloading (SSO) framework with three mechanisms: partition-wise host caching that exploits cross-partition dependencies, gradient regathering to avoid redundant storage reads during backpropagation, and a lightweight graph partitioning scheme to reduce memory overhead of existing partitioners. The authors claim that these techniques enable previously infeasible large-scale full-graph training, with experimental results showing up to 9.78x speedup over state-of-the-art single-server baselines and throughput comparable to distributed multi-GPU systems across various models and datasets.
Significance. If the performance claims hold under rigorous scrutiny, the work has substantial practical significance for the GNN community by lowering the hardware barrier for full-graph training, which preserves complete neighborhood information and enables direct validation of algorithmic improvements. By leveraging commodity storage rather than additional GPUs or servers, it addresses a real scalability bottleneck. The paper's strength lies in its system-level design tailored to GNN access patterns and the provision of concrete implementation details for the SSO components.
major comments (1)
- [Experiments (results and ablation sections)] The central claim that GriNNder outperforms memory-constrained baselines and matches distributed throughput rests on the quantitative demonstration that the SSO mechanisms (partition-wise caching, gradient regathering, and bypass) keep total storage I/O overhead low enough that execution time remains compute-dominated even when the graph exceeds host DRAM. The manuscript should provide explicit measurements—such as per-epoch I/O volume in GB, storage stall time as a fraction of total runtime, and latency-hiding effectiveness via overlap with computation—for the largest datasets in the experimental evaluation to verify that the >10 GB/s NVMe bandwidth is effectively utilized despite irregular multi-hop access patterns.
minor comments (2)
- [Abstract] The abstract states performance numbers without referencing specific dataset sizes, model architectures, or hardware configurations used in the experiments; these details should be summarized early in the introduction or experimental setup for immediate context.
- [System Design] Notation for the three SSO components (cache, regather, bypass) is introduced in the abstract but would benefit from a single consolidated diagram or table in the system overview section to clarify their interactions in the GPU-host-storage hierarchy.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's significance. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments (results and ablation sections)] The central claim that GriNNder outperforms memory-constrained baselines and matches distributed throughput rests on the quantitative demonstration that the SSO mechanisms (partition-wise caching, gradient regathering, and bypass) keep total storage I/O overhead low enough that execution time remains compute-dominated even when the graph exceeds host DRAM. The manuscript should provide explicit measurements—such as per-epoch I/O volume in GB, storage stall time as a fraction of total runtime, and latency-hiding effectiveness via overlap with computation—for the largest datasets in the experimental evaluation to verify that the >10 GB/s NVMe bandwidth is effectively utilized despite irregular multi-hop access patterns.
Authors: We agree that explicit quantification of I/O overhead is important to rigorously support the claim that execution remains compute-dominated. While the reported speedups (up to 9.78x) and throughput parity with distributed systems already indicate that storage latency is effectively hidden by our SSO mechanisms, we acknowledge the value of the requested breakdowns. In the revised manuscript we will add, for the largest datasets, (i) per-epoch I/O volumes in GB, (ii) storage stall time as a percentage of total runtime, and (iii) measurements of overlap effectiveness between I/O and computation. These additions will directly demonstrate utilization of the >10 GB/s NVMe bandwidth despite irregular multi-hop patterns and will be placed in both the main results and ablation sections. revision: yes
Circularity Check
No circularity: performance claims rest on empirical evaluation of implemented mechanisms, not self-referential derivations
full rationale
The paper describes an engineering system (GriNNder) with three concrete mechanisms—partition-wise host caching, gradient regathering, and lightweight partitioning—under the SSO framework. These are presented as design choices to handle GNN access patterns on NVMe storage, followed by experimental measurements of speedup (up to 9.78x) against baselines. No equations, fitted parameters, or first-principles predictions appear in the provided text; the central claims are not derived mathematically but demonstrated via runtime comparisons on real graphs and models. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming of known results is used to justify the core result. The derivation chain is therefore self-contained as an implementation-plus-benchmark paper rather than a closed logical loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Modern NVMe SSDs offer multi-terabyte capacities and bandwidths exceeding 10 GB/s
- domain assumption Directly applying storage-based methods from other domains fails to address unique access patterns and data dependencies in full-graph GNN training
Reference graph
Works this paper leans on
-
[1]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , title =. 2023 , booktitle =
work page 2023
- [2]
-
[3]
Zirui Liu and Kaixiong Zhou and Fan Yang and Li Li and Rui Chen and Xia Hu , booktitle=
-
[4]
Zhihao Shi and Xize Liang and Jie Wang , booktitle=
-
[5]
International Conference on Learning Representations (ICLR) , year=
Graph Neural Networks Exponentially Lose Expressive Power for Node Classification , author=. International Conference on Learning Representations (ICLR) , year=
-
[6]
USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
John Thorpe and Yifan Qiao and Jonathan Eyolfson and Shen Teng and Guanzhou Hu and Zhihao Jia and Jinliang Wei and Keval Vora and Ravi Netravali and Miryung Kim and Guoqing Harry Xu , title =. USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
-
[7]
Demirci, Gunduz Vehbi and Haldar, Aparajita and Ferhatosmanoglu, Hakan , title =. 2022 , journal =
work page 2022
-
[8]
Saurabh Bajaj and Hojae Son and Juelin Liu and Hui Guan and Marco Serafini , title =. 2025 , journal =
work page 2025
- [9]
-
[10]
Peng, Jingshu and Chen, Zhao and Shao, Yingxia and Shen, Yanyan and Chen, Lei and Cao, Jiannong , title =. 2022 , journal =
work page 2022
-
[11]
International Conference on Management of Data (SIGMOD) , year =
Wang, Qiange and Zhang, Yanfeng and Wang, Hao and Chen, Chaoyi and Zhang, Xiaodong and Yu, Ge , title =. International Conference on Management of Data (SIGMOD) , year =
-
[12]
Conference on Machine Learning and Systems (MLSys) , year =
Jia, Zhihao and Lin, Sina and Gao, Mingyu and Zaharia, Matei and Aiken, Alex , title =. Conference on Machine Learning and Systems (MLSys) , year =
-
[13]
arXiv preprint arXiv:2010.05337 , year=
Da Zheng and Chao Ma and Minjie Wang and Jinjing Zhou and Qidong Su and Xiang Song and Quan Gan and Zheng Zhang and George Karypis , title=. arXiv preprint arXiv:2010.05337 , year=
-
[14]
Khatua, Arpandeep and Mailthody, Vikram Sharma and Taleka, Bhagyashree and Ma, Tengfei and Song, Xiang and Hwu, Wen-mei , title =. 2023 , booktitle =
work page 2023
-
[15]
ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
Zheng, Da and Song, Xiang and Yang, Chengru and LaSalle, Dominique and Karypis, George , title =. ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , year =
-
[16]
and Kyrillidis, Anastasios and Kim, Nam Sung and Lin, Yingyan , title =
Wan, Cheng and Li, Youjie and Wolfe, Cameron R. and Kyrillidis, Anastasios and Kim, Nam Sung and Lin, Yingyan , title =. International Conference on Learning Representations (ICLR) , year =
-
[17]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-supervised classification with graph convolutional networks , author=. arXiv preprint arXiv:1609.02907 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DeepRank-GNN: a graph neural network framework to learn patterns in protein--protein interfaces , author=. Bioinformatics , year=
-
[19]
A survey of graph neural networks for social recommender systems , author=. ACM Computing Surveys , year=
-
[20]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
A survey on graph neural networks and graph transformers in computer vision: A task-oriented perspective , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[21]
International Conference on Learning Representations (ICLR) , year=
Graph Attention Networks , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
International Conference on Learning Representations (ICLR) , year=
How Powerful are Graph Neural Networks? , author=. International Conference on Learning Representations (ICLR) , year=
-
[23]
Open Graph Benchmark: Datasets for Machine Learning on Graphs , year =
Hu, Weihua and Fey, Matthias and Zitnik, Marinka and Dong, Yuxiao and Ren, Hongyu and Liu, Bowen and Catasta, Michele and Leskovec, Jure , booktitle =. Open Graph Benchmark: Datasets for Machine Learning on Graphs , year =
-
[24]
Inductive Representation Learning on Large Graphs , year =
Hamilton, Will and Ying, Zhitao and Leskovec, Jure , booktitle =. Inductive Representation Learning on Large Graphs , year =
-
[25]
Hanqing Zeng and Hongkuan Zhou and Ajitesh Srivastava and Rajgopal Kannan and Viktor K. Prasanna , title =. International Conference on Learning Representations (ICLR) , year =
- [26]
-
[27]
USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
Mart. USENIX Symposium on Operating Systems Design and Implementation (OSDI) , year =
-
[28]
Paszke, Adam and Gross, Sam and Chintala, Soumith and Chanan, Gregory , journal=
-
[29]
SIAM Journal on scientific Computing , year=
A fast and high quality multilevel scheme for partitioning irregular graphs , author=. SIAM Journal on scientific Computing , year=
-
[30]
Conference on Machine Learning and Systems (MLSys) , year=
Accelerating training and inference of graph neural networks with fast sampling and pipelining , author=. Conference on Machine Learning and Systems (MLSys) , year=
-
[31]
arXiv preprint arXiv:2112.08541 , year=
BGL: GPU-Efficient GNN Training by Optimizing Graph Data I/O and Preprocessing , author=. arXiv preprint arXiv:2112.08541 , year=
-
[32]
Lin, Zhiqi and Li, Cheng and Miao, Youshan and Liu, Yunxin and Xu, Yinlong , title =. 2020 , booktitle =
work page 2020
- [33]
-
[34]
Zhu, Rong and Zhao, Kun and Yang, Hongxia and Lin, Wei and Zhou, Chang and Ai, Baole and Li, Yong and Zhou, Jingren , title =. 2019 , journal =
work page 2019
-
[35]
Zhang, Dalong and Huang, Xin and Liu, Ziqi and Zhou, Jun and Hu, Zhiyang and Song, Xianzheng and Ge, Zhibang and Wang, Lin and Zhang, Zhiqiang and Qi, Yuan , title =. 2020 , journal =
work page 2020
-
[36]
Yang, Jianbang and Tang, Dahai and Song, Xiaoniu and Wang, Lei and Yin, Qiang and Chen, Rong and Yu, Wenyuan and Zhou, Jingren , title =. 2022 , booktitle =
work page 2022
-
[37]
Dong, Jialin and Zheng, Da and Yang, Lin F. and Karypis, George , title =. 2021 , booktitle =
work page 2021
-
[38]
Wan, Cheng and Li, Youjie and Li, Ang and Kim, Nam Sung and Lin, Yingyan , booktitle =
-
[39]
ICLR Workshop on Representation Learning on Graphs and Manifolds (ICLRW) , year=
Fast graph representation learning with PyTorch Geometric , author=. ICLR Workshop on Representation Learning on Graphs and Manifolds (ICLRW) , year=
-
[40]
Leskovec, Jure and Kleinberg, Jon and Faloutsos, Christos , title =. 2005 , booktitle =
work page 2005
-
[41]
Song, Jaeyong and Jang, Hongsun and Lim, Hunseong and Jung, Jaewon and Kim, Youngsok and Lee, Jinho , title =. 2024 , booktitle =
work page 2024
- [42]
-
[43]
Yoo, Mingi and Song, Jaeyong and Lee, Jounghoo and Kim, Namhyung and Kim, Youngsok and Lee, Jinho , booktitle =
-
[44]
International Conference on Learning Representations (ICLR) , year=
DropEdge: Towards Deep Graph Convolutional Networks on Node Classification , author=. International Conference on Learning Representations (ICLR) , year=
-
[45]
International Conference on Parallel Architectures and Compilation Techniques (PACT) , year=
GNNear: Accelerating Full-Batch Training of Graph Neural Networks with Near-Memory Processing , author=. International Conference on Parallel Architectures and Compilation Techniques (PACT) , year=
-
[46]
Song, Jaeyong and Yim, Jinkyu and Jung, Jaewon and Jang, Hongsun and Kim, Hyung-Jin and Kim, Youngsok and Lee, Jinho , title =. 2023 , booktitle =
work page 2023
-
[47]
Vogels, Thijs and Karimireddy, Sai Praneeth and Jaggi, Martin , title =. 2019 , booktitle =
work page 2019
-
[48]
Tim Kaler and Alexandros-Stavros Iliopoulos and Philip Murzynowski and Tao B. Schardl and Charles E. Leiserson and Jie Chen , title =. Conference on Machine Learning and Systems (MLSys) , year =
-
[49]
Yang, Shuangyan and Zhang, Minjia and Dong, Wenqian and Li, Dong , title =. 2023 , booktitle =
work page 2023
-
[50]
A Cost-Effective Near-Storage Processing Solution for Offline Inference of Long-Context LLMs , author=. 2026 , booktitle =
work page 2026
-
[51]
Waleffe, Roger and Mohoney, Jason and Rekatsinas, Theodoros and Venkataraman, Shivaram , title =. 2023 , booktitle =
work page 2023
-
[52]
Jiang, Qisheng and Jia, Lei and Wang, Chundong , title =. 2024 , booktitle =
work page 2024
-
[53]
Liu, Renjie and Wang, Yichuan and Yan, Xiao and Jiang, Haitian and Cai, Zhenkun and Wang, Minjie and Tang, Bo and Li, Jinyang , title =. 2025 , booktitle =
work page 2025
-
[54]
Out-of-Core Edge Partitioning at Linear Run-Time , year=
Mayer, Ruben and Orujzade, Kamil and Jacobsen, Hans-Arno , booktitle=. Out-of-Core Edge Partitioning at Linear Run-Time , year=
-
[55]
Wan, Xinchen and Xu, Kaiqiang and Liao, Xudong and Jin, Yilun and Chen, Kai and Jin, Xin , title =. 2023 , booktitle=
work page 2023
- [56]
-
[57]
Rajbhandari, Samyam and Ruwase, Olatunji and Rasley, Jeff and Smith, Shaden and He, Yuxiong , booktitle=
-
[58]
Sun, Jie and Sun, Mo and Zhang, Zheng and Xie, Jun and Shi, Zuocheng and Yang, Zihan and Zhang, Jie and Wu, Fei and Wang, Zeke , journal=
- [59]
-
[60]
Wang, Qiange and Chen, Yao and Wong, Weng-Fai and He, Bingsheng , title =. 2023 , journal =
work page 2023
-
[61]
LaSalle, Dominique and Karypis, George , booktitle=
-
[62]
Martella, Claudio and Logothetis, Dionysios and Loukas, Andreas and Siganos, Georgos , booktitle=
-
[63]
and Bik, Aart J.C and Dehnert, James C
Malewicz, Grzegorz and Austern, Matthew H. and Bik, Aart J.C and Dehnert, James C. and Horn, Ilan and Leiser, Naty and Czajkowski, Grzegorz , year =
-
[64]
Karypis, George and Schloegel, Kirk and Kumar, Vipin , institution=
-
[65]
Zhang, Ruisi and Javaheripi, Mojan and Ghodsi, Zahra and Bleiweiss, Amit and Koushanfar, Farinaz , booktitle=
-
[66]
Tsourakakis, Charalampos and Gkantsidis, Christos and Radunovic, Bozidar and Vojnovic, Milan , booktitle =
-
[67]
Echbarthi, Ghizlane and Kheddouci, Hamamache , booktitle=
-
[68]
Kaur, Gurneet and Gupta, Rajiv , booktitle=
-
[69]
Jia, Zhihao and Kwon, Yongkee and Shipman, Galen and McCormick, Pat and Erez, Mattan and Aiken, Alex , title =. 2017 , journal =
work page 2017
-
[70]
Huang, Wenbing and Zhang, Tong and Rong, Yu and Huang, Junzhou , journal=
-
[71]
Chen, Hongzhi and Liu, Miao and Zhao, Yunjian and Yan, Xiao and Yan, Da and Cheng, James , title =. 2018 , booktitle =
work page 2018
-
[72]
Ying, Rex and He, Ruining and Chen, Kaifeng and Eksombatchai, Pong and Hamilton, William L. and Leskovec, Jure , title =. ACM SIGKDD International Conference on Knowledge Discovery Data Mining (KDD) , year =
-
[73]
International Conference on Machine Learning (ICML) , year=
Sheng, Ying and Zheng, Lianmin and Yuan, Binhang and Li, Zhuohan and Ryabinin, Max and Chen, Beidi and Liang, Percy and R. International Conference on Machine Learning (ICML) , year=
-
[74]
Sun, Jie and Su, Li and Shi, Zuocheng and Shen, Wenting and Wang, Zeke and Wang, Lei and Zhang, Jie and Li, Yong and Yu, Wenyuan and Zhou, Jingren and others , booktitle=
-
[75]
Karypis, George and Kumar, Vipin , booktitle=
- [76]
-
[77]
Davis, Timothy A. and Hager, William W. and Kolodziej, Scott P. and Yeralan, S. Nuri , title =. 2020 , journal =
work page 2020
-
[78]
Heuer, Tobias and Schlag, Sebastian , booktitle=
-
[79]
Shaydulin, Ruslan and Safro, Ilya , journal=
-
[80]
Akhremtsev, Yaroslav and Heuer, Tobias and Sanders, Peter and Schlag, Sebastian , booktitle=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.