Recognition: no theorem link
NAVIS: Concurrent Search and Update with Low Position-Seeking Overhead in On-SSD Graph-Based Vector Search
Pith reviewed 2026-05-13 01:42 UTC · model grok-4.3
The pith
NAVIS reduces position-seeking overhead in on-SSD graph-based vector search to improve concurrent throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We present NAVIS, an on-SSD GVS system that drives down position-seeking overhead through (i) a layout-supported selective vector read that breaks the packed-page coupling without losing its locality benefits, (ii) a dynamic lightweight entrance graph update mechanism that reuses traversal information already produced by concurrent updates, and (iii) an entrance graph-aware edgelist cache that concentrates capacity on high-reuse paths near refreshed entry points.
What carries the argument
Three mechanisms that lower position-seeking cost: layout-supported selective vector read, dynamic lightweight entrance graph update, and entrance graph-aware edgelist cache.
Load-bearing premise
That position seeking is the dominant bottleneck and that the three proposed mechanisms can be realized without introducing unmeasured overheads that would offset the gains in real deployments.
What would settle it
A direct measurement on the same benchmarks showing no reduction in position-seeking time during insertions, or no corresponding rise in overall insertion and search throughput, would falsify the claim.
Figures












read the original abstract
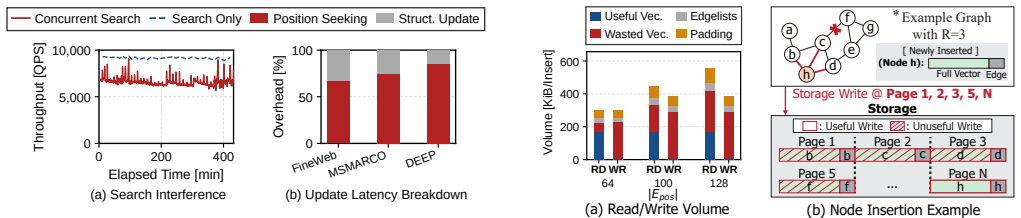
On-disk graph-based vector search (GVS) has become the dominant approach for serving large-scale vector databases at high recall, but prior systems struggle to sustain concurrent search and update throughput on high-dimensional workloads. We find the main cause of this in position seeking, a full graph traversal that every update performs to locate neighbors before linking the new vector into the graph. Position seeking is fundamentally heavier than a search query, and its cost is further amplified by two systemic limitations of current GVS systems, packed layouts that couple every edge fetch to a full vector load, and a static entrance graph whose entry points drift away from newly inserted regions as updates accumulate. We present NAVIS, an on-SSD GVS system that drives down position-seeking overhead through (i) a layout-supported selective vector read that breaks the packed-page coupling without losing its locality benefits, (ii) a dynamic lightweight entrance graph update mechanism that reuses traversal information already produced by concurrent updates, and (iii) an entrance graph-aware edgelist cache that concentrates capacity on high-reuse paths near refreshed entry points. Across multiple large-scale high-dimensional benchmarks, NAVIS enhances average insertion throughput by up to 2.74x and average concurrent search throughput by up to 1.37x while reducing average search latency by up to 25.26%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents NAVIS, an on-SSD graph-based vector search system that targets the position-seeking overhead incurred by every update when locating neighbors for insertion. It identifies two exacerbating factors in prior systems: packed page layouts that force full vector loads on every edge fetch, and static entrance graphs whose entry points become stale as updates accumulate. NAVIS introduces three mechanisms—layout-supported selective vector reads, dynamic lightweight entrance-graph reuse from concurrent updates, and entrance-aware edgelist caching—to reduce this overhead. The abstract reports that these changes yield up to 2.74× higher average insertion throughput, 1.37× higher average concurrent search throughput, and up to 25.26% lower average search latency across large-scale high-dimensional benchmarks.
Significance. If the performance numbers are supported by complete experimental methodology, ablations, and workload details, the work would be a useful empirical contribution to concurrent on-disk vector indexing. The explicit focus on position seeking as the dominant update cost and the three targeted mitigations provide concrete design insights for SSD-based graph indexes that must sustain mixed search/update workloads.
major comments (1)
- The central empirical claims rest on the unverified premise that the three mechanisms deliver net gains without measurable offsetting I/O, metadata, or synchronization costs. The abstract and typical systems-paper structure provide no indication of ablation studies or per-component breakdowns that would isolate each mechanism's contribution; without such evidence the causal attribution to the proposed fixes cannot be confirmed.
minor comments (1)
- The abstract supplies no experimental methodology, baselines, variance statistics, or workload details, which are required to assess the reported speedups.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for emphasizing the need for explicit empirical validation of our proposed mechanisms. We address the major comment below and will revise the manuscript to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: The central empirical claims rest on the unverified premise that the three mechanisms deliver net gains without measurable offsetting I/O, metadata, or synchronization costs. The abstract and typical systems-paper structure provide no indication of ablation studies or per-component breakdowns that would isolate each mechanism's contribution; without such evidence the causal attribution to the proposed fixes cannot be confirmed.
Authors: We agree that ablation studies and per-component breakdowns are necessary to isolate the contributions of the three mechanisms and to quantify any offsetting costs. The current evaluation section reports end-to-end throughput and latency improvements, but does not include explicit ablations that separate the effects of layout-supported selective vector reads, dynamic lightweight entrance-graph reuse, and entrance-aware edgelist caching, nor direct measurements of added I/O, metadata, or synchronization overhead. In the revised manuscript we will add a dedicated ablation subsection that measures each mechanism individually and in combination, including breakdowns of I/O operations per update, metadata maintenance costs, and synchronization overhead under concurrent workloads. These additions will allow readers to verify that the reported net gains (up to 2.74× insertion throughput and 1.37× search throughput) are attributable to the proposed techniques without significant offsetting penalties. revision: yes
Circularity Check
No circularity: empirical systems paper with experimental validation only
full rationale
The paper is a systems contribution that identifies position-seeking as a bottleneck via observation, proposes three concrete mechanisms (selective vector reads, dynamic entrance-graph reuse, entrance-aware caching), and reports measured speedups on benchmarks. No equations, derivations, fitted parameters, or self-citation chains appear in the provided text; performance numbers are direct experimental outcomes rather than predictions that reduce to inputs by construction. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Position seeking is the primary performance limiter in concurrent on-SSD GVS workloads
Reference graph
Works this paper leans on
-
[1]
Jens Axboe. 2019. Efficient IO with io_uring. https://kernel.dk/io_uring.pdf
work page 2019
- [2]
-
[3]
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset.arXiv preprint arXiv:1611.09268(2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[4]
Dmitry Baranchuk, Artem Babenko, and Yury Malkov. 2018. Revisiting the Inverted Indices for Billion-Scale Approximate Nearest Neighbors. InProceedings of the 15th European Conference on Computer Vision (ECCV)
work page 2018
-
[5]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation. InFindings of the Association for Computational Linguistics: ACL 2024
work page 2024
-
[6]
Kangqi Chen, Rakesh Nadig, Manos Frouzakis, Nika Mansouri Ghiasi, Yu Liang, Haiyu Mao, Jisung Park, Mohammad Sadrosadati, and Onur Mutlu. 2025. REIS: A High-Performance and Energy-Efficient Retrieval System with In-Storage Processing. InProceedings of the 52nd International Symposium on Computer Architecture (ISCA)
work page 2025
-
[7]
Patrick Chen, Wei-Cheng Chang, Jyun-Yu Jiang, Hsiang-Fu Yu, Inderjit Dhillon, and Cho-Jui Hsieh. 2023. FINGER: Fast Inference for Graph-based Approxi- mate Nearest Neighbor Search. InProceedings of the ACM Web Conference 2023 (WWW)
work page 2023
-
[8]
Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. SPANN: Highly-Efficient Billion-Scale Approximate Nearest Neighbor Search. InProceedings of the Advances in Neural Information Processing Systems 34 (NeurIPS)
work page 2021
-
[9]
Benjamin Coleman, Santiago Segarra, Alex Smola, and Anshumali Shrivastava
-
[10]
InProceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS)
Graph Reordering for Cache-Efficient Near Neighbor Search. InProceedings of the Advances in Neural Information Processing Systems 35 (NeurIPS)
-
[11]
Paul Covington, Jay Adams, and Emre Sargin. 2016. Deep Neural Networks for YouTube Recommendations. InProceedings of the 10th ACM Conference on Recommender Systems (RecSys)
work page 2016
-
[12]
Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, and Hervé Jégou. 2025. The Faiss Library.IEEE Transactions on Big Data (BigData)(2025)
work page 2025
-
[13]
Gil Einziger, Roy Friedman, and Ben Manes. 2017. TinyLFU: A Highly Efficient Cache Admission Policy.ACM Transactions on Storage (TOS)13, 4 (2017)
work page 2017
-
[14]
Chantat Eksombatchai, Pranav Jindal, Jerry Zitao Liu, Yuchen Liu, Rahul Sharma, Charles Sugnet, Mark Ulrich, and Jure Leskovec. 2018. Pixie: A System for Rec- ommending 3+ Billion Items to 200+ Million Users in Real-Time. InProceedings of the 2018 World Wide Web Conference (WWW)
work page 2018
-
[15]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast Approximate Nearest Neighbor Search with the Navigating Spreading-Out Graph.Proceedings of the VLDB Endowment12, 5 (2019)
work page 2019
-
[16]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2014. Optimized Product Quantization.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)36, 4 (2014)
work page 2014
-
[17]
Siddharth Gollapudi, Neel Karia, Varun Sivashankar, Ravishankar Krishnaswamy, Nikit Begwani, Swapnil Raz, Yiyong Lin, Yin Zhang, Neelam Mahapatro, Premku- mar Srinivasan, Amit Singh, and Harsha Vardhan Simhadri. 2023. Filtered- DiskANN: Graph Algorithms for Approximate Nearest Neighbor Search with Filters. InProceedings of the ACM Web Conference 2023 (WWW)
work page 2023
-
[18]
Google. [n.d.]. YouTube. https://blog.youtube/press/
-
[19]
Fabian Groh, Lukas Ruppert, Patrick Wieschollek, and Hendrik P. A. Lensch
-
[20]
GGNN: Graph-Based GPU Nearest Neighbor Search.IEEE Transactions on Big Data (BigData)9, 1 (2023)
work page 2023
-
[21]
Hao Guo and Youyou Lu. 2025. Achieving Low-Latency Graph-Based Vector Search via Aligning Best-First Search Algorithm with SSD. InProceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
work page 2025
-
[22]
Hao Guo and Youyou Lu. 2026. OdinANN: Direct Insert for Consistently Stable Performance in Billion-Scale Graph-Based Vector Search. InProceedings of the 24th USENIX Conference on File and Storage Technologies (FAST)
work page 2026
-
[23]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. InProceedings of the 37th International Conference on Machine Learning (ICML)
work page 2020
- [24]
-
[25]
Han-Wen Hu, Wei-Chen Wang, Yuan-Hao Chang, Yung-Chun Lee, Bo-Rong Lin, Huai-Mu Wang, Yen-Po Lin, Yu-Ming Huang, Chong-Ying Lee, Tzu-Hsiang Su, Chih-Chang Hsieh, Chia-Ming Hu, Yi-Ting Lai, Chung-Kuang Chen, Han- Sung Chen, Hsiang-Pang Li, Tei-Wei Kuo, Meng-Fan Chang, Keh-Chung Wang, Chun-Hsiung Hung, and Chih-Yuan Lu. 2022. ICE: An Intelligent Cognition En...
work page 2022
-
[26]
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. Embedding- based Retrieval in Facebook Search. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD)
work page 2020
-
[27]
Zan Huang, Wingyan Chung, Thian-Huat Ong, and Hsinchun Chen. 2002. A Graph-based Recommender System for Digital Library. InProceedings of the 2nd ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL)
work page 2002
- [28]
-
[29]
Junhyeok Jang, Hanjin Choi, Hanyeoreum Bae, Seungjun Lee, Miryeong Kwon, and Myoungsoo Jung. 2023. CXL-ANNS: Software-Hardware Collaborative Memory Disaggregation and Computation for Billion-Scale Approximate Nearest Neighbor Search. InProceedings of the 2023 USENIX Annual Technical Conference (USENIX ATC)
work page 2023
-
[30]
Herve Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)33, 1 (2011)
work page 2011
-
[31]
Jinyoung Kim, Dayoon Ko, and Gunhee Kim. 2024. DynamicER: Resolving Emerging Mentions to Dynamic Entities for RAG. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP)
work page 2024
-
[32]
Ji-Hoon Kim, Yeo-Reum Park, Jaeyoung Do, Soo-Young Ji, and Joo-Young Kim
-
[33]
Accelerating Large-Scale Graph-Based Nearest Neighbor Search on a Computational Storage Platform.IEEE Transactions on Computers (TC)72, 1 (2023)
work page 2023
-
[34]
Sukjin Kim, Seongyeon Park, Si Ung Noh, Junguk Hong, Taehee Kwon, Hunseong Lim, and Jinho Lee. 2025. PathWeaver: A High-Throughput Multi-GPU System for Graph-Based Approximate Nearest Neighbor Search. InProceedings of the 2025 USENIX Annual Technical Conference (USENIX ATC)
work page 2025
-
[35]
Stanford Vision Lab. [n.d.]. ImageNet. https://www.image-net.org/index.php
-
[36]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InProceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS)
work page 2020
-
[37]
Jie Li, Haifeng Liu, Chuanghua Gui, Jianyu Chen, Zhenyuan Ni, Ning Wang, and Yuan Chen. 2018. The Design and Implementation of a Real Time Visual Search System on JD E-commerce Platform. InProceedings of the 19th International Middleware Conference Industry (Middleware)
work page 2018
-
[38]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2020. Approximate Nearest Neighbor Search on High Dimensional Data — Experiments, Analyses, and Improvement.IEEE Transactions on Knowl- edge and Data Engineering (TKDE)32, 8 (2020)
work page 2020
-
[39]
Jiahao Lou, Quan Yu, Shufeng Gong, Song Yu, Yanfeng Zhang, and Ge Yu. 2025. DGAI: Decoupled On-Disk Graph-Based ANN Index for Efficient Updates and Queries.arXiv preprint arXiv:2510.25401(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Anton Lozhkov, Loubna Ben Allal, Leandro von Werra, and Thomas Wolf. 2024. FineWeb-Edu: the Finest Collection of Educational Content. https://huggingface. co/datasets/HuggingFaceFW/fineweb-edu
work page 2024
-
[41]
Yu A. Malkov and D. A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)42, 4 (2020)
work page 2020
-
[42]
Incremental ivf index maintenance for streaming vector search,
Jason Mohoney, Anil Pacaci, Shihabur Rahman Chowdhury, Umar Farooq Minhas, Jeffery Pound, Cedric Renggli, Nima Reyhani, Ihab F. Ilyas, Theodoros Rekatsinas, and Shivaram Venkataraman. 2024. Incremental IVF Index Maintenance for Streaming Vector Search.arXiv preprint arXiv:2411.00970(2024)
-
[43]
Ilyas, Theodoros Rekatsinas, and Shivaram Venkataraman
Jason Mohoney, Devesh Sarda, Mengze Tang, Shihabur Rahman Chowdhury, Anil Pacaci, Ihab F. Ilyas, Theodoros Rekatsinas, and Shivaram Venkataraman
-
[44]
InProceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
Quake: Adaptive Indexing for Vector Search. InProceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
-
[45]
Hiroyuki Ootomo, Akira Naruse, Corey Nolet, Ray Wang, Tamas Feher, and Yong Wang. 2024. CAGRA: Highly Parallel Graph Construction and Approxi- mate Nearest Neighbor Search for GPUs. InProceedings of the 2024 IEEE 40th International Conference on Data Engineering (ICDE)
work page 2024
-
[46]
OpenAI. 2024. Embeddings – OpenAI API. https://developers.openai.com/api/ docs/guides/embeddings
work page 2024
-
[47]
OpenAI. 2024. New embedding models and API updates. https://openai.com/ index/new-embedding-models-and-api-updates/
work page 2024
-
[48]
Yu Pan, Jianxin Sun, and Hongfeng Yu. 2023. LM-DiskANN: Low Memory Footprint in Disk-Native Dynamic Graph-Based ANN Indexing. InProceedings 13 of the 2023 IEEE International Conference on Big Data (BigData)
work page 2023
-
[49]
Qdrant. 2025. Qdrant: High-Performance Vector Search at Scale. https://qdrant. tech/
work page 2025
-
[50]
Ziyue Qiu, Juncheng Yang, Juncheng Zhang, Cheng Li, Xiaosong Ma, Qi Chen, Mao Yang, and Yinlong Xu. 2023. FrozenHot Cache: Rethinking Cache Manage- ment for Modern Hardware. InProceedings of the 18th European Conference on Computer Systems (EuroSys)
work page 2023
-
[51]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InProceedings of the 38th International Conference on Machine Learning (ICML)
work page 2021
-
[52]
Jie Ren, Minjia Zhang, and Dong Li. 2020. HM-ANN: Efficient Billion-Point Near- est Neighbor Search on Heterogeneous Memory. InProceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS)
work page 2020
- [53]
-
[54]
Suhas Jayaram Subramanya, Devvrit, Rohan Kadekodi, Ravishankar Kr- ishaswamy, and Harsha Vardhan Simhadri. 2019. DiskANN: Fast Accurate Billion-Point Nearest Neighbor Search on a Single Node. InProceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS)
work page 2019
-
[55]
Philip Sun, David Simcha, Dave Dopson, Ruiqi Guo, and Sanjiv Kumar. 2023. SOAR: Improved Indexing for Approximate Nearest Neighbor Search. InPro- ceedings of the Advances in Neural Information Processing Systems 36 (NeurIPS)
work page 2023
-
[56]
Bing Tian, Haikun Liu, Zhuohui Duan, Xiaofei Liao, Hai Jin, and Yu Zhang. 2024. Scalable Billion-point Approximate Nearest Neighbor Search Using SmartSSDs. InProceedings of the 2024 USENIX Annual Technical Conference (USENIX ATC)
work page 2024
-
[57]
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, Sindhu Raghuram Panyam, Sara Smoot, Iftekhar Naim, Joe Zou, Feiyang Chen, Daniel Cer, Alice Lisak, Min Choi, Lucas Gonzalez, Omar Sanseviero, Glenn Cameron, Ian Ballantyne, Kat Black, Kaifeng Chen, Weiyi Wang, Zhe Li, Gus Martins, Jinhyuk Lee, Mark Sherwood, Juyeong Ji, Renjie Wu, ...
-
[58]
Mengzhao Wang, Weizhi Xu, Xiaomeng Yi, Songlin Wu, Zhangyang Peng, Xi- angyu Ke, Yunjun Gao, Xiaoliang Xu, Rentong Guo, and Charles Xie. 2024. Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High- Dimensional Vector Similarity Search on Data Segment.Proceedings of the ACM on Management of Data (PACMMOD)2, 1 (2024)
work page 2024
-
[59]
Bernstein, Badrish Chan- dramouli, Richard Wen, and Harsha Vardhan Simhadri
Haike Xu, Magdalen Dobson Manohar, Philip A. Bernstein, Badrish Chan- dramouli, Richard Wen, and Harsha Vardhan Simhadri. 2025. In-Place Updates of a Graph Index for Streaming Approximate Nearest Neighbor Search.arXiv preprint arXiv:2502.13826(2025)
-
[60]
Yuming Xu, Hengyu Liang, Jin Li, Shuotao Xu, Qi Chen, Qianxi Zhang, Cheng Li, Ziyue Yang, Fan Yang, Yuqing Yang, Peng Cheng, and Mao Yang. 2023. SPFresh: Incremental In-Place Update for Billion-Scale Vector Search. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP)
work page 2023
-
[61]
Song Yu, Shengyuan Lin, Shufeng Gong, Yongqing Xie, Ruicheng Liu, Yijie Zhou, Ji Sun, Yanfeng Zhang, Guoliang Li, and Ge Yu. 2025. A Topology-Aware Localized Update Strategy for Graph-Based ANN Index.Proceedings of the VLDB Endowment19, 3 (2025)
work page 2025
-
[62]
Yuanhang Yu, Dong Wen, Ying Zhang, Lu Qin, Wenjie Zhang, and Xuemin Lin
-
[63]
InProceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE)
GPU-accelerated Proximity Graph Approximate Nearest Neighbor Search and Construction. InProceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE)
work page 2022
-
[64]
Shulin Zeng, Zhenhua Zhu, Jun Liu, Haoyu Zhang, Guohao Dai, Zixuan Zhou, Shuangchen Li, Xuefei Ning, Yuan Xie, Huazhong Yang, and Yu Wang. 2023. DF-GAS: a Distributed FPGA-as-a-Service Architecture towards Billion-Scale Graph-based Approximate Nearest Neighbor Search. InProceedings of the 56th IEEE/ACM International Symposium on Microarchitecture (MICRO)
work page 2023
-
[65]
Minjia Zhang, Wenhan Wang, and Yuxiong He. 2022. GraSP: Optimizing Graph- based Nearest Neighbor Search with Subgraph Sampling and Pruning. InPro- ceedings of the 15th ACM International Conference on Web Search and Data Mining (WSDM)
work page 2022
- [66]
-
[67]
Weijie Zhao, Shulong Tan, and Ping Li. 2020. SONG: Approximate Nearest Neighbor Search on GPU. InProceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE)
work page 2020
-
[68]
Lei Zhu, Chaoqun Zheng, Weili Guan, Jingjing Li, Yang Yang, and Heng Tao Shen. 2024. Multi-Modal Hashing for Efficient Multimedia Retrieval: A Survey. IEEE Transactions on Knowledge and Data Engineering (TKDE)36, 1 (2024)
work page 2024
-
[69]
Zhenhua Zhu, Jun Liu, Guohao Dai, Shulin Zeng, Bing Li, Huazhong Yang, and Yu Wang. 2023. Processing-In-Hierarchical-Memory Architecture for Billion- Scale Approximate Nearest Neighbor Search. InProceedings of the 60th ACM/IEEE Design Automation Conference (DAC). 14
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.