Recognition: no theorem link
Read, Grep, and Synthesize: Diagnosing Cross-Domain Seed Exposure for LLM Research Ideation
Pith reviewed 2026-05-13 01:02 UTC · model grok-4.3
The pith
Cross-domain retrieval boosts LLM research idea novelty over baselines but matches random diverse seeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the synthesis stage, cross-domain retrieval via paraphrased seeds across seven ML domains receives more pairwise novelty wins than no-retrieval and same-domain baselines, but shows no significant difference from a random diverse-seed control. These findings indicate that LLM ideation systems benefit from diverse seed exposure but do not yet reliably exploit the semantic reason particular seeds were retrieved.
What carries the argument
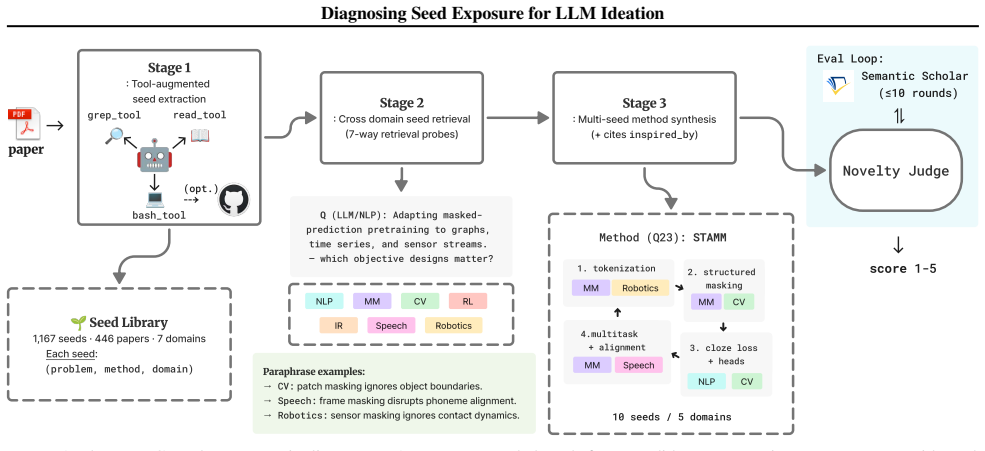
PaperGym, the three-stage pipeline of tool-augmented seed extraction, paraphrase-based cross-domain retrieval, and rubric-based LLM judging of synthesized methods.
Load-bearing premise
Rubric-based LLM judges provide a reliable, unbiased measure of novelty and the seven ML domains plus paraphrase retrieval adequately represent meaningful cross-domain exposure without introducing artifacts.
What would settle it
A follow-up experiment in which human ML researchers independently rate the novelty of the same set of synthesized ideas, revealing whether the LLM judge rankings between cross-domain retrieval and the random diverse control hold or reverse.
Figures

read the original abstract
The discovery of novel methodologies for emerging problems is a continuing cycle in ML, often driven by the migration of techniques across domains. Building on this observation, we ask whether current LLM ideation systems benefit from targeted cross-domain retrieval or simply from exposure to diverse mechanisms. We study this question through PaperGym, a three-stage pipeline: (1) tool-augmented seed extraction via read, grep, and bash over an isolated paper environment, (2) cross-domain seed retrieval via paraphrasing across seven ML domains, and (3) method synthesis from retrieved seeds, each scored by rubric-based judges. Tool-augmented extraction improves specificity, and paraphrase-based retrieval broadens domain coverage. In synthesis, cross-domain retrieval receives more pairwise novelty wins than no-retrieval and same-domain baselines, but shows no significant difference from a random diverse-seed control. These findings suggest LLM ideation systems benefit from diverse seed exposure, but do not yet reliably exploit the semantic reason particular seeds were retrieved. We release the seed library, rubric prompts, and run scripts at https://github.com/yunjoochoi/PaperGym
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes PaperGym, a pipeline consisting of tool-augmented seed extraction from isolated paper environments using read, grep, and bash commands, paraphrase-based cross-domain retrieval across seven ML domains, and LLM-driven method synthesis. Through experiments with rubric-based LLM judges, it claims that cross-domain retrieval achieves more pairwise novelty wins than no-retrieval and same-domain baselines but exhibits no significant difference from a random diverse-seed control. This leads to the conclusion that LLM ideation systems benefit from diverse seed exposure rather than the specific semantic reasons for cross-domain retrieval. The seed library, rubric prompts, and run scripts are released publicly.
Significance. Should the results prove robust, this paper offers valuable diagnostics for LLM research ideation systems, distinguishing the effects of diversity from targeted cross-domain transfer. The open release of code and artifacts is a notable strength, facilitating reproducibility and extension by the community. It contributes to the growing literature on retrieval-augmented generation for creative tasks in AI by providing empirical evidence that may guide future system designs toward prioritizing seed diversity.
major comments (3)
- [§4.2 (Synthesis Evaluation)] The central comparisons of novelty rely exclusively on pairwise win rates from rubric-based LLM judges. No inter-annotator agreement metrics, human-expert correlation studies, or audits for biases (such as the judge LLM preferring syntheses generated in a similar style) are reported. This undermines confidence in the no-significant-difference finding versus the random control, as any systematic judge preference would confound the diversity vs. cross-domain distinction.
- [§3.2 (Domain and Retrieval Setup)] The selection of seven ML sub-domains and the use of paraphrase retrieval for cross-domain exposure may not provide adequate separation from the random diverse-seed baseline. Details on paper selection criteria, exclusion rules, and quantitative measures of domain distance are insufficient to evaluate whether the setup truly tests cross-domain effects or inadvertently creates similar distributions.
- [§4.1 (Experimental Controls)] While baselines including random diverse control are mentioned, the manuscript lacks full details on data exclusion, judge calibration procedures, and statistical tests used for 'no significant difference,' making it difficult to assess if post-hoc choices influenced the key result.
minor comments (2)
- [Abstract] The abstract states the main finding but could benefit from including specific win rate percentages or p-values for the comparisons to give readers a quick sense of effect sizes.
- [§5 (Discussion)] The discussion on implications for LLM ideation could be expanded with concrete suggestions for how to better exploit cross-domain semantics in future systems.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which highlights important areas for strengthening the robustness and transparency of our claims. We agree that additional validations, documentation, and statistical details are warranted to better support the distinction between diversity and targeted cross-domain effects. We will revise the manuscript accordingly, as detailed in the point-by-point responses below.
read point-by-point responses
-
Referee: [§4.2 (Synthesis Evaluation)] The central comparisons of novelty rely exclusively on pairwise win rates from rubric-based LLM judges. No inter-annotator agreement metrics, human-expert correlation studies, or audits for biases (such as the judge LLM preferring syntheses generated in a similar style) are reported. This undermines confidence in the no-significant-difference finding versus the random control, as any systematic judge preference would confound the diversity vs. cross-domain distinction.
Authors: We agree that reliance on LLM judges without validation metrics introduces potential confounds and weakens confidence in the no-significant-difference result. In the revised manuscript, we will add to §4.2: (1) inter-annotator agreement using two distinct judge models (GPT-4o and Claude-3.5) on 100 randomly sampled synthesis pairs, reporting percentage agreement and Cohen's kappa; (2) a human correlation study with two independent ML experts scoring novelty on 50 syntheses (using the same rubric), computing Spearman rank correlation with LLM judgments; and (3) bias audits analyzing win rates by synthesis length, lexical overlap with seeds, and stylistic markers (e.g., via n-gram analysis). Full details and results will appear in the main text and appendix. These additions directly address the concern without altering the core experimental design. revision: yes
-
Referee: [§3.2 (Domain and Retrieval Setup)] The selection of seven ML sub-domains and the use of paraphrase retrieval for cross-domain exposure may not provide adequate separation from the random diverse-seed baseline. Details on paper selection criteria, exclusion rules, and quantitative measures of domain distance are insufficient to evaluate whether the setup truly tests cross-domain effects or inadvertently creates similar distributions.
Authors: We concur that insufficient details on domain construction limit evaluation of whether the setup isolates cross-domain semantics from general diversity. The revised §3.2 will include: (1) explicit paper selection criteria (top 50 papers per domain from arXiv categories cs.LG, cs.CL, cs.CV, cs.IR, cs.AI, cs.RO, cs.NE, 2018–2023, filtered by keyword relevance in titles/abstracts); (2) exclusion rules (no papers with authors spanning multiple domains or containing explicit cross-domain citations in the introduction); and (3) quantitative domain distance (average cosine similarity of domain-level TF-IDF vectors and Sentence-BERT embeddings, demonstrating lower inter-domain than intra-domain similarity). These additions will show that paraphrase retrieval targets semantically related yet distributionally distant seeds, providing clearer separation from the random diverse baseline. revision: yes
-
Referee: [§4.1 (Experimental Controls)] While baselines including random diverse control are mentioned, the manuscript lacks full details on data exclusion, judge calibration procedures, and statistical tests used for 'no significant difference,' making it difficult to assess if post-hoc choices influenced the key result.
Authors: We acknowledge that the absence of these procedural details hinders assessment of the statistical validity of the no-significant-difference finding. In the revised §4.1 and experimental setup, we will specify: (1) data exclusion criteria (syntheses discarded for invalid JSON output, excessive length >512 tokens, or failure to produce a coherent method description, affecting <4% of generations); (2) judge calibration (exact few-shot examples in the rubric prompt, temperature fixed at 0.7, and system prompt emphasizing rubric adherence); and (3) statistical tests (two-tailed paired t-tests on win rates with 1,000 bootstrap resamples, p-values adjusted via Holm-Bonferroni correction for the three pairwise comparisons, confirming p>0.05 between cross-domain and random conditions). The released code repository already contains the scripts implementing these procedures. revision: yes
Circularity Check
No circularity in empirical pipeline evaluation
full rationale
This paper presents an empirical three-stage pipeline (tool-augmented extraction, paraphrase-based cross-domain retrieval across seven ML domains, and LLM-synthesized method generation) whose central claims rest on direct experimental comparisons of novelty win rates against explicit baselines (no-retrieval, same-domain, and random diverse-seed controls). No mathematical derivations, equations, fitted parameters renamed as predictions, or self-referential definitions appear in the described methodology. Results are obtained from independent runs with released artifacts, rubric prompts, and scripts, rendering the evaluation chain self-contained and externally verifiable rather than circular by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Rubric-based LLM judges provide consistent and valid novelty scores
- domain assumption Paraphrase-based retrieval across seven ML domains captures meaningful cross-domain semantic exposure
invented entities (1)
-
PaperGym pipeline
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. 2023 , eprint =
work page 2023
-
[2]
International Conference on Learning Representations (ICLR) , year =
Explaining and Harnessing Adversarial Examples , author =. International Conference on Learning Representations (ICLR) , year =
-
[3]
Xiaogeng Liu and Nan Xu and Muhao Chen and Chaowei Xiao , booktitle =
-
[4]
Chen Xiong and Pin-Yu Chen and Tsung-Yi Ho , booktitle =
-
[5]
Chris Lu and Cong Lu and Robert Tjarko Lange and Jakob Foerster and Jeff Clune and David Ha , year =. The. 2408.06292 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Jiabin Tang and Lianghao Xia and Zhonghang Li and Chao Huang , booktitle =
-
[7]
Samuel Schmidgall and Yusheng Su and Ze Wang and Ximeng Sun and Jialian Wu and Xiaodong Yu and Jiang Liu and Michael Moor and Zicheng Liu and Emad Barsoum , booktitle =. Agent Laboratory: Using
- [8]
-
[9]
arXiv preprint arXiv:2404.07738
Jinheon Baek and Sujay Kumar Jauhar and Silviu Cucerzan and Sung Ju Hwang , year =. 2404.07738 , archivePrefix =
-
[10]
Joel Chan and Joseph Chee Chang and Tom Hope and Dafna Shahaf and Aniket Kittur , journal =. 2018 , doi =
work page 2018
-
[11]
Mlagentbench: Evaluating language agents on machine learning experimentation, 2024
Qian Huang and Jian Vora and Percy Liang and Jure Leskovec , year =. 2310.03302 , archivePrefix =
-
[12]
Xing and Hao Zhang and Joseph E
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and Eric P. Xing and Hao Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle =. Judging
-
[13]
Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Large Language Models are not Fair Evaluators , author =. Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[14]
Yang Liu and Dan Iter and Yichong Xu and Shuohang Wang and Ruochen Xu and Chenguang Zhu , booktitle =. 2023 , doi =
work page 2023
-
[15]
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik Narasimhan and Yuan Cao , booktitle =
- [16]
-
[17]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[19]
Qingyun Wang and Doug Downey and Heng Ji and Tom Hope , booktitle =
-
[20]
Conference on Creativity and Cognition (C&C) , year =
Fluid Transformers and Creative Analogies: Exploring Large Language Models' Capacity for Augmenting Cross-Domain Analogical Creativity , author =. Conference on Creativity and Cognition (C&C) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.