Recognition: no theorem link
Optimal LTLf Synthesis
Pith reviewed 2026-05-13 01:55 UTC · model grok-4.3
The pith
Optimal LTLf synthesis computes strategies that realize the largest possible number of objectives from conflicting specifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
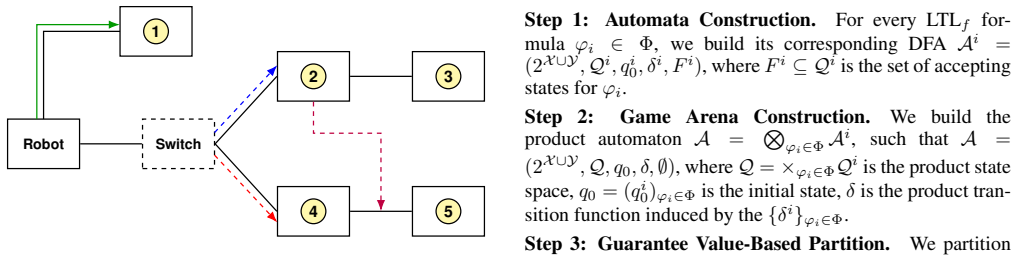
We introduce optimal LTLf synthesis for specifications consisting of multiple objectives that are not jointly realizable. Max-guarantee synthesis returns a maximal subset of objectives together with a strategy that is guaranteed to realize all of them. Max-observation synthesis returns a strategy that maximizes the number of realized objectives after the execution is observed. Incremental max-observation synthesis improves the strategy on the fly by exploiting opportunities for stronger guarantees that arise during execution.
What carries the argument
The reduction of optimal LTLf synthesis to the computation of maximal realizable objective subsets (for max-guarantee) and to the optimization of observed outcomes across executions (for max-observation).
If this is right
- A largest set of objectives can be selected and guaranteed before any execution begins.
- A single strategy can be returned that maximizes realized objectives once the actual run is observed.
- Strategies can be strengthened incrementally whenever the execution reveals new realizable objectives.
- The three variants scale comparably and solve most benchmark instances within the timeout.
- keywords
Where Pith is reading between the lines
- The same maximal-subset idea could be applied to other temporal logics or to quantitative synthesis problems where objectives carry different priorities.
- In deployed systems the approach would turn total failure into partial but usable success when goals conflict.
- It suggests a natural interface with runtime monitoring so that observed facts can be used to prune unrealizable objectives on the fly.
Load-bearing premise
That algorithms exist to compute maximal realizable objective subsets and to perform the a-posteriori maximization in finite time.
What would settle it
A concrete LTLf specification with conflicting objectives for which no algorithm in the paper can return a strategy realizing a maximal number of objectives, while a different strategy realizes strictly more.
Figures

read the original abstract
Strategy synthesis typically follows an all-or-nothing paradigm, returning unrealisable whenever a specification cannot be guaranteed in an uncertain environment. In this paper, we introduce optimal LTLf synthesis, where the goal is to realise as many objectives as possible from a given specification consisting of multiple objectives, especially for the case that they are not all jointly realisable. We first consider max-guarantee synthesis, which commits to a maximal set of objectives that we can a priori guarantee to realise. We then introduce max-observation synthesis, which maximises a posteriori realised objectives that may be incomparable on different executions. Finally, we present incremental max-observation synthesis, which further improves strategies by exploiting opportunities for stronger guarantees when they arise during an execution. Experimental results show that different variations of optimal synthesis scale broadly equally well, solving a large fraction of the benchmark instances within the given timeout, demonstrating the practical feasibility of the approach.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces optimal LTLf synthesis for multi-objective specifications consisting of LTLf formulas that may not be jointly realizable. It defines three concrete variants—max-guarantee synthesis (a priori maximal guaranteed set), max-observation synthesis (a posteriori maximization of realized objectives across executions), and incremental max-observation synthesis (dynamic strengthening of guarantees during execution)—and claims that algorithms exist to compute maximal realizable sets and perform the associated maximizations. Experimental results are reported showing that the variants scale comparably, solving a large fraction of benchmark instances within the timeout.
Significance. If the algorithmic claims hold, the work provides a practical extension of standard LTLf synthesis (known to be decidable via automata) to the common case of conflicting objectives, moving beyond the all-or-nothing paradigm. The reported experimental scalability on benchmarks is a concrete strength that supports applicability; naming the specific benchmark suite, timeout, and any baseline comparisons would further increase the result's impact.
major comments (1)
- [Abstract and algorithmic sections] The abstract asserts that algorithms exist for computing maximal realizable sets and a-posteriori maximization while preserving decidability, yet no complexity bounds, automata-construction sketches, or reduction to standard LTLf synthesis appear in the provided description. This is load-bearing for the central claim that the optimal variants remain practically solvable.
minor comments (2)
- [Experimental results] The experimental claim that variants 'scale broadly equally well' would be strengthened by reporting the exact number of instances solved, timeout value, and any variance or per-variant breakdown.
- [Definition of max-observation synthesis] Clarify the precise semantics of 'incomparable on different executions' for max-observation synthesis, perhaps with a small illustrative example.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation of minor revision. We appreciate the positive assessment of the work's significance in extending LTLf synthesis to conflicting objectives and the recognition of the experimental scalability. We address the single major comment below and will incorporate clarifications into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and algorithmic sections] The abstract asserts that algorithms exist for computing maximal realizable sets and a-posteriori maximization while preserving decidability, yet no complexity bounds, automata-construction sketches, or reduction to standard LTLf synthesis appear in the provided description. This is load-bearing for the central claim that the optimal variants remain practically solvable.
Authors: We agree that the manuscript would benefit from explicit algorithmic details to support the central claims. The max-guarantee variant reduces to identifying a maximal subset S of objectives such that the conjunction of formulas in S is realizable; this is achieved by invoking the standard LTLf synthesis procedure (via DFA construction and game solving) on candidate subsets, which is feasible given the small number of objectives in typical specifications. The max-observation and incremental variants are solved by constructing the product automaton over the individual objective DFAs and solving a reachability game that maximizes the number of satisfied objectives along plays. Because each LTLf formula yields a DFA of size at most exponential in its length, and the number of objectives is treated as a fixed parameter, the overall procedure remains decidable and inherits the 2EXPTIME complexity of standard LTLf synthesis. We will add a dedicated algorithmic section with these reduction sketches, complexity remarks, and pseudocode to make the claims self-contained while preserving the experimental evidence of practical scalability. revision: yes
Circularity Check
No significant circularity; derivation is self-contained algorithmic extension
full rationale
The paper defines new problem variants (max-guarantee, max-observation, incremental max-observation synthesis) for LTLf with multiple objectives and claims decidability plus practical algorithms. These rest on standard automata constructions for LTLf synthesis, which are external and not reduced to the paper's own definitions or fitted values. No equations, parameter fits, predictions derived from inputs, or load-bearing self-citations appear in the provided text. The experimental scalability claims are presented as empirical validation rather than tautological outputs. The central claims therefore remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Planning under LTL environment specifications
[Aminofet al., 2019 ] Benjamin Aminof, Giuseppe De Gia- como, Aniello Murano, and Sasha Rubin. Planning under LTL environment specifications. InICAPS, pages 31–39,
work page 2019
-
[2]
Best-Effort Synthesis: Doing your best is not harder than giving up
[Aminofet al., 2021 ] Benjamin Aminof, Giuseppe De Gia- como, and Sasha Rubin. Best-Effort Synthesis: Doing your best is not harder than giving up. InIJCAI, pages 1766–1772,
work page 2021
- [3]
- [4]
-
[5]
[Cimattiet al., 2003 ] Alessandro Cimatti, Marco Pistore, Marco Roveri, and Paolo Traverso. Weak, strong, and strong cyclic planning via symbolic model checking.Jour- nal of Artificial Intelligence, 1–2(147),
work page 2003
-
[6]
Automata-theoretic foundations of FOND planning for LTLf and LDLf goals
[De Giacomo and Rubin, 2018] Giuseppe De Giacomo and Sasha Rubin. Automata-theoretic foundations of FOND planning for LTLf and LDLf goals. InIJCAI, pages 4729– 4735,
work page 2018
-
[7]
[De Giacomo and Vardi, 2013] Giuseppe De Giacomo and Moshe Y . Vardi. Linear Temporal Logic and Linear Dy- namic Logic on Finite Traces. InIJCAI,
work page 2013
-
[8]
[De Giacomo and Vardi, 2015] Giuseppe De Giacomo and Moshe Y . Vardi. Synthesis for LTL and LDL on finite traces. InIJCAI,
work page 2015
-
[9]
LTLf adaptive synthesis for multi-tier goals in nondeterministic domains.ICAPS, pages 334–342,
[De Giacomoet al., 2025 ] Giuseppe De Giacomo, Gian- marco Parretti, and Shufang Zhu. LTLf adaptive synthesis for multi-tier goals in nondeterministic domains.ICAPS, pages 334–342,
work page 2025
-
[10]
[Dimitrovaet al., 2020 ] Rayna Dimitrova, Mahsa Ghasemi, and Ufuk Topcu. Reactive synthesis with maximum real- izability of linear temporal logic specifications.Acta In- formatica, 57(1–2):107–135,
work page 2020
-
[11]
[Duret-Lutzet al., 2025 ] Alexandre Duret-Lutz, Shufang Zhu, Nir Piterman, Giuseppe De Giacomo, and Moshe Y . Vardi. Engineering an LTLf synthesis tool. InCIAA, pages 129–147,
work page 2025
-
[12]
[Friedet al., 2016 ] Dror Fried, Lucas M. Tabajara, and Moshe Y . Vardi. BDD-Based boolean functional synthesis. InCAV, pages 402–421,
work page 2016
-
[13]
[Geffner and Bonet, 2013] Hector Geffner and Blai Bonet.A Concise Introduction to Models and Methods for Auto- mated Planning. Morgan & Claypool Publishers,
work page 2013
-
[14]
Nau, and Paolo Traverso.Automated planning and acting
[Ghallabet al., 2016 ] Malik Ghallab, Dana S. Nau, and Paolo Traverso.Automated planning and acting. Cam- bridge,
work page 2016
-
[15]
[Jorge and McIlraith, 2008] A. Jorge and Sheila A. McIl- raith. Planning with preferences.AI Magazine, 29(4):25,
work page 2008
-
[16]
Soft goals can be compiled away.Journal of Artificial Intelligence Research, 36:547–556,
[Keyder and Geffner, 2009] Emil Keyder and Hector Geffner. Soft goals can be compiled away.Journal of Artificial Intelligence Research, 36:547–556,
work page 2009
-
[17]
On the synthesis of a reactive module
[Pnueli and Rosner, 1989] Amir Pnueli and Roni Rosner. On the synthesis of a reactive module. InPOPL,
work page 1989
-
[18]
The temporal logic of programs
[Pnueli, 1977] Amir Pnueli. The temporal logic of programs. InFOCS, pages 46–57,
work page 1977
-
[19]
[Reiter, 2001] Raymond Reiter.Knowledge in Action: Logi- cal Foundations for Specifying and Implementing Dynam- ical Systems. MIT,
work page 2001
-
[20]
CUDD: CU decision di- agram package 3.0.0
[Somenzi, 2016] Fabio Somenzi. CUDD: CU decision di- agram package 3.0.0. University of Colorado at Boulder
work page 2016
-
[21]
[Son and Pontelli, 2006] Tran Cao Son and Enrico Pontelli. Planning with preferences using logic programming.The- ory and Practice of Logic Programming, 6(5):559–607,
work page 2006
-
[22]
Tabajara, Jianwen Li, Geguang Pu, and Moshe Y
[Zhuet al., 2017 ] Shufang Zhu, Lucas M. Tabajara, Jianwen Li, Geguang Pu, and Moshe Y . Vardi. Symbolic LTL f synthesis. InIJCAI, pages 1362–1369, 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.