Recognition: 2 theorem links
· Lean TheoremHindsight Hint Distillation: Scaffolded Reasoning for SWE Agents from CoT-free Answers
Pith reviewed 2026-05-13 01:50 UTC · model grok-4.3
The pith
Hindsight hints synthesized from an AI model's own failures can scaffold successful reasoning trajectories for software engineering tasks without needing chain-of-thought annotations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HHD synthesizes hindsight hints from the model's own failed self-rollouts and uses them to scaffold on-policy rollouts that successfully complete the tasks. The model then self-distills these scaffolded trajectories and generalizes to new problems without hint guidance, outperforming baselines substantially on SWE-bench tasks.
What carries the argument
Hindsight hints from failed self-rollouts used to scaffold successful on-policy trajectories for self-distillation.
If this is right
- Training data for agent reasoning can be generated without explicit step-by-step rationales.
- Substantial performance gains occur on software engineering benchmarks.
- Learned reasoning strategies transfer effectively to out-of-distribution problems like multilingual tasks.
- Self-distillation of guided trajectories improves generalization beyond the training distribution.
Where Pith is reading between the lines
- The approach may scale to other planning-heavy domains by using model self-correction to bootstrap better behavior.
- Future work could test if repeated cycles of hinting and distillation lead to compounding improvements without external data.
- Agents trained this way might require less human supervision for acquiring expert-like planning skills.
Load-bearing premise
Hints derived from the model's past failures provide sufficient and accurate guidance to enable successful task completions in new attempts.
What would settle it
Running HHD on SWE-bench tasks and observing no improvement over baselines or failure of the hints to increase rollout success rates would disprove the central claim.
Figures




read the original abstract
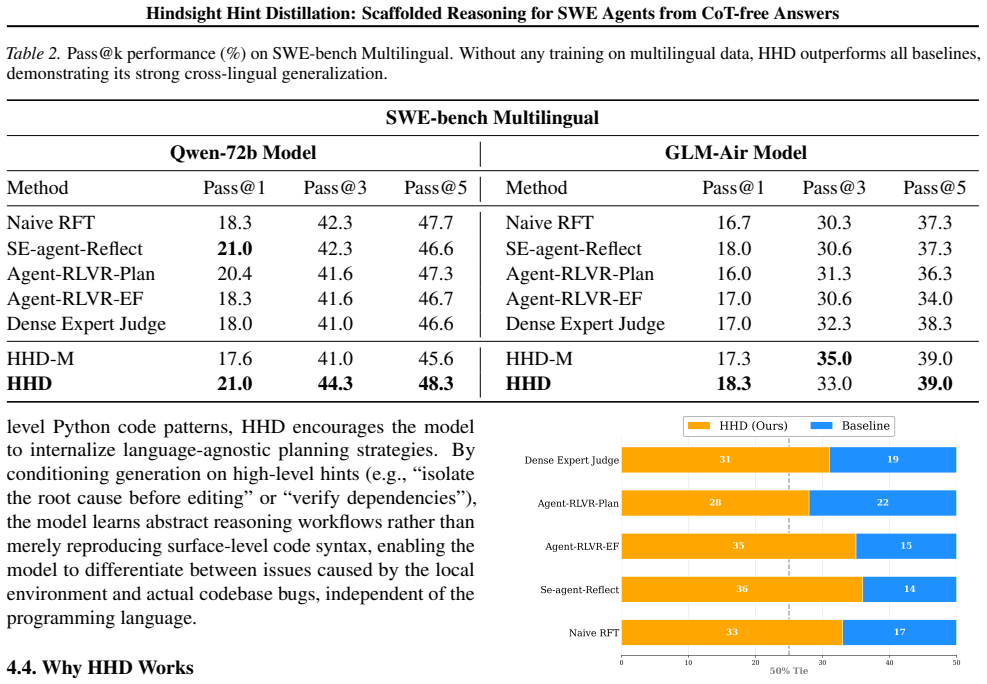
Solving complex long-horizon tasks requires strong planning and reasoning capabilities. Although datasets with explicit chain-of-thought (CoT) rationales can substantially benefit learning, they are costly to obtain. To address this challenge, we propose Hindsight Hint Distillation (HHD), which only requires easy-to-obtain question-answer pairs without CoT annotations. Inspired by how human teachers use student mistakes to provide targeted guidance, HHD synthesizes hindsight hints from the model's own failed self-rollouts and uses them to scaffold on-policy rollouts that successfully complete the tasks. The model then self-distills these scaffolded trajectories and generalizes to new problems without hint guidance. Experiments show that HHD significantly outperforms iterative RFT and trajectory-synthesis baselines, achieving an absolute improvement of 8\% on SWE-bench Verified, while all baselines improve by only around 2\%. Notably, the reasoning strategies induced by HHD generalize effectively to out-of-distribution tasks, yielding the largest gains on SWE-bench Multilingual despite no training on multilingual data. These results demonstrate that HHD can effectively synthesize expert-like reasoning from CoT-free data and substantially improve long-horizon performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Hindsight Hint Distillation (HHD), a self-improvement method for SWE agents that operates from CoT-free question-answer pairs. It generates hindsight hints from the model's failed self-rollouts, uses these hints to scaffold successful on-policy trajectories, self-distills the resulting trajectories into the model, and claims that the induced reasoning strategies transfer to new problems without further hints. Experiments report an 8% absolute gain on SWE-bench Verified (versus ~2% for iterative RFT and trajectory-synthesis baselines) and strong OOD generalization to SWE-bench Multilingual.
Significance. If the reported gains and generalization hold under scrutiny, the work would be significant for agent self-improvement in long-horizon domains: it demonstrates a practical route to synthesizing higher-quality reasoning trajectories from cheap QA data alone, without requiring human CoT annotations or external verifiers beyond the task environment.
major comments (3)
- [§3] §3 (HHD Method): The central assumption that hindsight hints derived solely from failed self-rollouts and the CoT-free QA pair can reliably scaffold successful on-policy trajectories is load-bearing for the 8% gain claim, yet the section provides no quantitative breakdown of scaffolding success rates (e.g., fraction of failed rollouts that become successful after hint insertion) or failure-mode analysis for long-horizon SWE tasks.
- [§4.2] §4.2 (Experimental Setup) and Table 2: The 8% absolute improvement on SWE-bench Verified is presented without error bars, number of seeds, or statistical significance tests; given the high variance typical of agent rollouts on SWE-bench, it is unclear whether the difference from the ~2% baseline gains is robust or sensitive to rollout sampling choices and hint-synthesis prompts.
- [§4.3] §4.3 (OOD Generalization): The largest gains on SWE-bench Multilingual are attributed to induced reasoning strategies, but the paper does not report whether the distilled model still requires hints at test time or quantify how much of the OOD lift is explained by the self-distillation step versus other factors such as increased training data volume.
minor comments (3)
- [§1] The abstract and §1 use “self-distills these scaffolded trajectories” without clarifying whether distillation is performed via supervised fine-tuning, preference optimization, or another objective; a short equation or pseudocode would remove ambiguity.
- [Figure 2] Figure 2 (overview diagram) and the hint-generation prompt in the appendix should be cross-referenced more explicitly so readers can trace exactly which information from the failed rollout is fed into hint synthesis.
- [§4.1] The paper cites prior RFT and trajectory-synthesis baselines but does not include a direct comparison table entry for a simple “hint-augmented rollout without distillation” ablation; adding this would strengthen the attribution of gains to the full HHD pipeline.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive feedback and for recommending major revision. We address each of the major comments below and will incorporate the suggested improvements into the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (HHD Method): The central assumption that hindsight hints derived solely from failed self-rollouts and the CoT-free QA pair can reliably scaffold successful on-policy trajectories is load-bearing for the 8% gain claim, yet the section provides no quantitative breakdown of scaffolding success rates (e.g., fraction of failed rollouts that become successful after hint insertion) or failure-mode analysis for long-horizon SWE tasks.
Authors: We concur that a quantitative breakdown of the scaffolding process is important to substantiate the method's effectiveness. We will revise §3 to include success rates for hint scaffolding (i.e., the proportion of failed rollouts that yield successful trajectories post-hint) and a failure-mode analysis specific to long-horizon SWE tasks. This will be supported by additional figures or tables. revision: yes
-
Referee: [§4.2] §4.2 (Experimental Setup) and Table 2: The 8% absolute improvement on SWE-bench Verified is presented without error bars, number of seeds, or statistical significance tests; given the high variance typical of agent rollouts on SWE-bench, it is unclear whether the difference from the ~2% baseline gains is robust or sensitive to rollout sampling choices and hint-synthesis prompts.
Authors: We agree that the lack of error bars and statistical analysis limits the interpretability of the results given the known variance in SWE-bench evaluations. We will update the experimental setup in §4.2 and Table 2 to report results over multiple seeds with error bars and include statistical significance testing to confirm that the observed gains are robust. revision: yes
-
Referee: [§4.3] §4.3 (OOD Generalization): The largest gains on SWE-bench Multilingual are attributed to induced reasoning strategies, but the paper does not report whether the distilled model still requires hints at test time or quantify how much of the OOD lift is explained by the self-distillation step versus other factors such as increased training data volume.
Authors: To clarify, the self-distilled model does not use hints at inference time, as the training process internalizes the reasoning strategies for generalization. We will revise §4.3 to explicitly state this and add an ablation study that isolates the contribution of the self-distillation step from other factors like training data volume, thereby quantifying its role in the OOD gains on SWE-bench Multilingual. revision: yes
Circularity Check
No circularity: empirical self-improvement procedure
full rationale
The paper presents HHD as a procedural algorithm that generates hindsight hints from the model's failed self-rollouts, uses them to scaffold on-policy trajectories, and then self-distills the resulting data for generalization. No equations, formal derivations, or parameter-fitting steps are described that would reduce the reported benchmark gains (e.g., 8% on SWE-bench Verified) to quantities defined by construction from the inputs or from self-referential definitions. The method relies on standard RL and distillation techniques applied to CoT-free QA pairs, with results validated externally on held-out benchmarks including OOD multilingual tasks. Any self-citations, if present, are not load-bearing for the core empirical claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Hindsight hints synthesized from failed self-rollouts can scaffold successful task completions.
- domain assumption Self-distillation of the resulting scaffolded trajectories produces generalization without hints.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieving an absolute improvement of 8% on SWE-bench Verified... generalization to SWE-bench Multilingual
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The problem is about partial object instantiation in Hydra
-
[2]
Currently, if a config group has a missing value, partial instantiation fails with an exception
-
[3]
The request is to instead return a partial object where missing values become required arguments of the partial object
-
[4]
This is for use in hyperparameter search systems where parameters are proposed later Key technical details: - The code uses ‘@dataclass‘ with ‘MISSING‘ from ‘omegaconf‘ - The config has ‘_target_‘ and ‘_partial_‘ fields - The goal is to allow ‘hydra.utils.instantiate(cfg)‘ to work even with missing values The example shows: - A PartialFoo class with ‘foo:...
-
[5]
Understand the current behavior
-
[6]
Find where partial instantiation is handled
-
[7]
Modify the logic to handle missing values gracefully
-
[8]
Ensure the partial object can be completed later with the missing values)" "observation":"EXECUTION RESULT of [think]: Your thought has been logged." ...... Step 9 "step":9 "action":"str_replace_editor(command=view, path=/testbed/hydra/_internal/instantiate/ _instantiate2.py, view_range=[270, 361])" "observation":"EXECUTION RESULT of [str_replace_editor]:...
-
[9]
Compare the original problem statement with the ground truth patch
-
[10]
Use the trajectory to identify where the original statement might have been unclear or misleading
-
[11]
Generate a **concise hint ** that strengthens or clarifies the original problem statement. Requirements: - The hint must NOT explicitly mention the trajectory, ground truth patch, or agent actions. - The hint should be very short (2-3 sentences). - Output must be JSON with a single key: ‘hint‘. --- ## Output Example ‘‘‘json { "hint": "Make sure the fix is...
-
[12]
Suboptimal Reasoning: Reinventing the Wheel The agent failed to grasp the high-level intent. It attempted to reinvent the wheelby manually calculating indices and slicing the object list, ignoring the existingpage()method
-
[13]
It formulated a plan to simply iterate over self.page range and yieldself.page(num)
Optimal Reasoning: Leveraging Abstractions The agent correctly identified that iter is just a wrapper. It formulated a plan to simply iterate over self.page range and yieldself.page(num)
-
[14]
Process Trap: Inefficient Debugging Loop The agent got locked into a“Local Optima” loop. It spent nu- merous steps debugging low-level off-by-one errors and edge cases (e.g., empty lists) unrelated to the task, unable to break free and reassess the global context
-
[15]
Process Pivot: Isolated Verification When faced with environment errors unrelated to the task, the agent distinguished noise from the core issue. It adhered to the high- level plan by constructing a targeted script, allowing it to focus exclusively on the relevant bug without getting trapped in unrelated system failures
-
[16]
The final code was bloated, fragile, and failed to handleboundary conditions, leading to regressions
Outcome: Incorrect and Bloated Code The trajectory was filled with inefficient exploration. The final code was bloated, fragile, and failed to handleboundary conditions, leading to regressions
-
[17]
Outcome: Correct and Concise Solution The model solved the task with a concise4-line fix. It successfully internalized the strategy of “reusing abstractions” rather than mem- orizing a specific answer. B.1. Baseline Failed Trajectory We here provide the detailed trajectory for the failure case study referenced in Table 3. 14 Hindsight Hint Distillation: S...
work page 2025
-
[18]
EXPLORATION: Thoroughly explore relevant files and understand the context before proposing solutions
-
[19]
ANALYSIS: Consider multiple approaches and select the most promising one
-
[20]
TESTING: * For bug fixes: Create tests to verify issues before implementing fixes * For new features: Consider test-driven development when appropriate * If the repository lacks testing infrastructure and implementing tests would require extensive setup, consult with the user before investing time in building testing infrastructure * If the environment is...
-
[21]
IMPLEMENTATION: Make focused, minimal changes to address the problem
-
[22]
VERIFICATION: If the environment is set up to run tests, test your implementation thoroughly, including edge cases. If the environment is not set up to run tests, consult with the user first before investing time to run tests. </PROBLEM_SOLVING_WORKFLOW> <SECURITY> * Only use GITHUB_TOKEN and other credentials in ways the user has explicitly requested and...
-
[23]
txt, pyproject.toml, package.json, Gemfile, etc.)
First, look around in the repository for existing dependency files (requirements. txt, pyproject.toml, package.json, Gemfile, etc.)
-
[24]
If dependency files exist, use them to install all dependencies at once (e.g., ‘pip install -r requirements.txt‘, ‘npm install‘, etc.)
-
[25]
Only install individual packages directly if no dependency files are found or if only specific packages are needed * Similarly, if you encounter missing dependencies for essential tools requested by the user, install them when possible. </ENVIRONMENT_SETUP> <TROUBLESHOOTING> * If you’ve made repeated attempts to solve a problem but tests still fail or the...
-
[26]
Step back and reflect on 5-7 different possible sources of the problem
-
[27]
Assess the likelihood of each possible cause
-
[28]
Methodically address the most likely causes, starting with the highest probability
-
[29]
Document your reasoning process * When you run into any major issue while executing a plan from the user, please don’t try to directly work around it. Instead, propose a new plan and confirm with the user before proceeding. </TROUBLESHOOTING> You have access to the following functions: ---- BEGIN FUNCTION #1: execute_bash ---- Description: Execute a bash ...
-
[30]
When exploring a repository and discovering the source of a bug, call this tool to brainstorm several unique ways of fixing the bug, and assess which change(s) are likely to be simplest and most effective
-
[31]
After receiving test results, use this tool to brainstorm ways to fix failing tests
-
[32]
When planning a complex refactoring, use this tool to outline different approaches and their tradeoffs
-
[33]
When designing a new feature, use this tool to think through architecture decisions and implementation details
-
[34]
When debugging a complex issue, use this tool to organize your thoughts and hypotheses. The tool simply logs your thought process for better transparency and does not execute any code or make changes. Parameters: (1) thought (string, required): The thought to log. ---- END FUNCTION #2 ---- ---- BEGIN FUNCTION #3: finish ---- Description: Signals the compl...
-
[35]
Use the view tool to understand the file’s contents and context
-
[36]
Verify the directory path is correct (only applicable when creating new files): - Use the view tool to verify the parent directory exists and is the correct location When making edits: - Ensure the edit results in idiomatic, correct code - Do not leave the code in a broken state - Always use absolute file paths (starting with /) CRITICAL REQUIREMENTS FOR ...
-
[37]
EXACT MATCHING: The ‘old_str‘ parameter must match EXACTLY one or more consecutive lines from the file, including all whitespace and indentation. The tool will fail if ‘old_str‘ matches multiple locations or doesn’t match exactly with the file content
-
[38]
UNIQUENESS: The ‘old_str‘ must uniquely identify a single instance in the file: - Include sufficient context before and after the change point (3-5 lines recommended ) - If not unique, the replacement will not be performed
-
[39]
Both strings must be different
REPLACEMENT: The ‘new_str‘ parameter should contain the edited lines that replace the ‘old_str‘. Both strings must be different. Remember: when making multiple file edits in a row to the same file, you should prefer to send all edits in a single message with multiple calls to this tool, rather than multiple messages with a single call each. Parameters: (1...
-
[40]
121 [1]+ Exit 1 python3 app.py > server.log 2>&1 ASSISTANT: Looks like the server was running with PID 121 then crashed. Let me check the server log : <function=execute_bash> <parameter=command> cat server.log </parameter> </function> USER: EXECUTION RESULT of [execute_bash]: Traceback (most recent call last): File "/workspace/app.py", line 2, in <module>...
-
[41]
Do not use it in a production deployment
124 ASSISTANT: Let me check the server log again: <function=execute_bash> <parameter=command> 24 Hindsight Hint Distillation: Scaffolded Reasoning for SWE Agents from CoT-free Answers cat server.log </parameter> </function> USER: EXECUTION RESULT of [execute_bash]: * Serving Flask app ’app’ * Debug mode: off WARNING: This is a development server. Do not u...
-
[42]
You can access the list of numbers in a table format by visiting http://127.0.0.1:5000
126 25 Hindsight Hint Distillation: Scaffolded Reasoning for SWE Agents from CoT-free Answers ASSISTANT: The server is running on port 5000 with PID 126. You can access the list of numbers in a table format by visiting http://127.0.0.1:5000. ASSISTANT: The server is running on port 5000 with PID 126. You can access the list of numbers in a table format by...
-
[43]
8.1 Ensure you’ve fully addressed all requirements
FINAL REVIEW: Carefully re-read the problem description and compare your changes with the base commit. 8.1 Ensure you’ve fully addressed all requirements. 8.2 Run any tests in the repository related to: 8.2.1 The issue you are fixing 8.2.2 The files you modified 8.2.3 The functions you changed 8.3 If any tests fail, revise your implementation until all te...
-
[44]
**Efficiency**: Fewer wasted steps, less unrelated context reading
-
[45]
**Logic**: Clearer reasoning
-
[46]
**Precision**: No hallucinations, no syntax errors in commands, no reverting edits
-
[47]
**Safety**: Did not delete unrelated files or ruin the environment. ### Problem Statement {problem} --- ### Trajectory A 27 Hindsight Hint Distillation: Scaffolded Reasoning for SWE Agents from CoT-free Answers {traj_a} --- ### Trajectory B {traj_b} --- ### Decision Compare the two objectively. Return a JSON object with the following structure (Put ’winne...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.