Recognition: 2 theorem links
· Lean TheoremA Composite Activation Function for Learning Stable Binary Representations
Pith reviewed 2026-05-13 01:59 UTC · model grok-4.3
The pith
HTAF, a sigmoid-tanh composite, lets networks with binary Heaviside activations train stably via standard gradient descent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
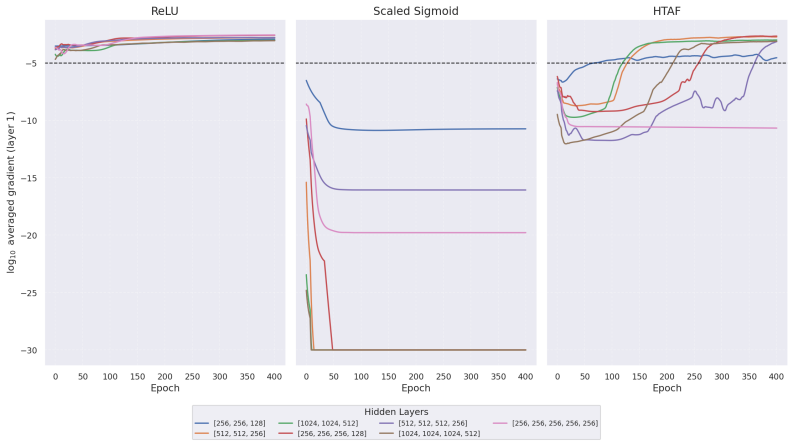
HTAF is constructed as a sigmoid hyperbolic tangent composite function and theoretically maintains a large gradient mass around zero inputs while exhibiting slower gradient decay in the tail regions. Spiking Neural Networks, Binary Neural Networks and Deep Heaviside neural Networks can therefore be trained stably using HTAF with gradient-based optimization. The function further induces discrete feature representations inside Implicit Concept Bottleneck Models, which achieve prediction performance comparable to or better than standard models on image datasets.
What carries the argument
Heavy Tailed Activation Function (HTAF), a smooth composite of sigmoid and hyperbolic tangent that approximates the Heaviside step while preserving strong gradients near the origin and slow tail decay.
If this is right
- Spiking neural networks become trainable by ordinary back-propagation without surrogate-gradient approximations.
- Binary neural networks reach stable solutions at full precision during training before any quantization step.
- Deep networks built entirely from Heaviside units can be optimized end-to-end with the same optimizer used for ReLU networks.
- Implicit Concept Bottleneck Models produce discrete, human-interpretable features directly from the activation while preserving task performance.
Where Pith is reading between the lines
- The same composite construction might be adapted to other non-differentiable threshold functions used in optimization or control.
- Because gradients remain usable far from zero, HTAF could reduce the need for gradient clipping or learning-rate schedules in binary architectures.
- Discrete internal states induced by HTAF may improve robustness to input perturbations that affect continuous activations.
Load-bearing premise
The favorable theoretical gradient profile of the composite function will actually produce stable convergence to useful binary representations during end-to-end gradient training without extra hyperparameter search or post-processing.
What would settle it
Train a binary neural network on a standard image benchmark using HTAF and measure whether the loss decreases steadily to a competitive accuracy level while the activations remain close to binary values; failure to converge or collapse to trivial solutions would falsify the claim.
Figures







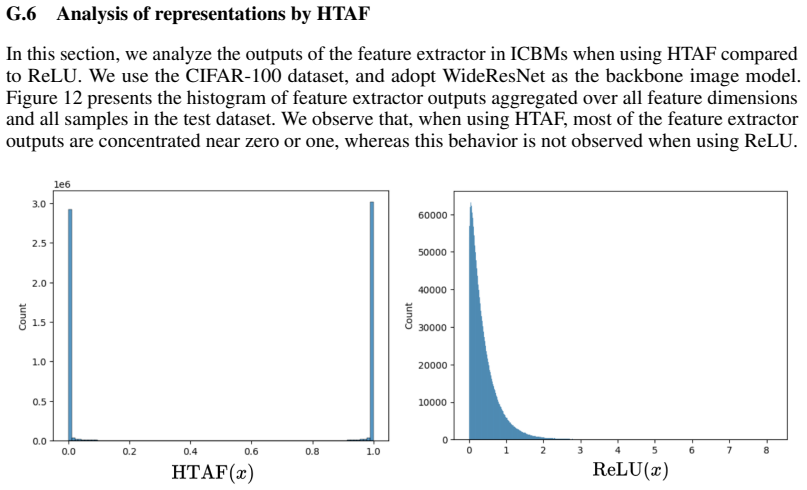
read the original abstract
Activation functions play a central role in neural networks by shaping internal representations. Recently, learning binary activation representations has attracted significant attention due to their advantages in computational and memory efficiency, as well as interpretability. However, training neural networks with Heaviside activations remains challenging, as their non-differentiability obstructs standard gradient-based optimization. In this paper, we propose Heavy Tailed Activation Function (HTAF), a smooth approximation to the Heaviside function that enables stable training with gradient-based optimization. We construct HTAF as a sigmoid hyperbolic tangent composite function and theoretically show that it maintains a large gradient mass around zero inputs while exhibiting slower gradient decay in the tail regions. We show that Spiking Neural Networks, Binary Neural Networks and Deep Heaviside neural Networks can be trained stably using HTAF with gradient-based optimization. Finally, we introduce Implicit Concept Bottleneck Models (ICBMs), an interpretable image model that leverages HTAF to induce discrete feature representations. Extensive experiments across various architectures and image datasets demonstrate that ICBM enables stable discretization while achieving prediction performance comparable to or better than standard models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Heavy Tailed Activation Function (HTAF), constructed as a composite of sigmoid and hyperbolic tangent functions to provide a smooth, differentiable approximation to the Heaviside step function. It derives that HTAF preserves substantial gradient mass near zero inputs with slower tail decay compared to standard activations, enabling stable gradient-based training of Spiking Neural Networks, Binary Neural Networks, and Deep Heaviside Neural Networks. The work further introduces Implicit Concept Bottleneck Models (ICBMs) that leverage HTAF for discrete feature representations and reports experiments on image classification tasks showing competitive performance with improved interpretability.
Significance. If the gradient properties survive multi-layer backpropagation and the experimental gains are causally attributable to HTAF rather than tuning, the method could offer a practical route to training binary-representation networks without specialized optimizers or straight-through estimators, with downstream benefits for memory-efficient and interpretable models such as ICBMs. The explicit construction from standard components and the focus on gradient mass/decay are positive features, but the absence of analytic multi-layer bounds and controlled ablations limits the assessed advance over existing smooth Heaviside approximations.
major comments (3)
- [theoretical analysis section] Theoretical analysis (gradient derivation): the per-neuron derivative is shown to maintain large mass near zero and slower tail decay, yet no analytic bound or perturbation argument is supplied demonstrating that these properties are preserved after multiplication by weight matrices and summation across layers under realistic weight distributions; this gap directly undermines the claim that isolated HTAF properties suffice for stable training of SNNs/BNNs/DHNNs.
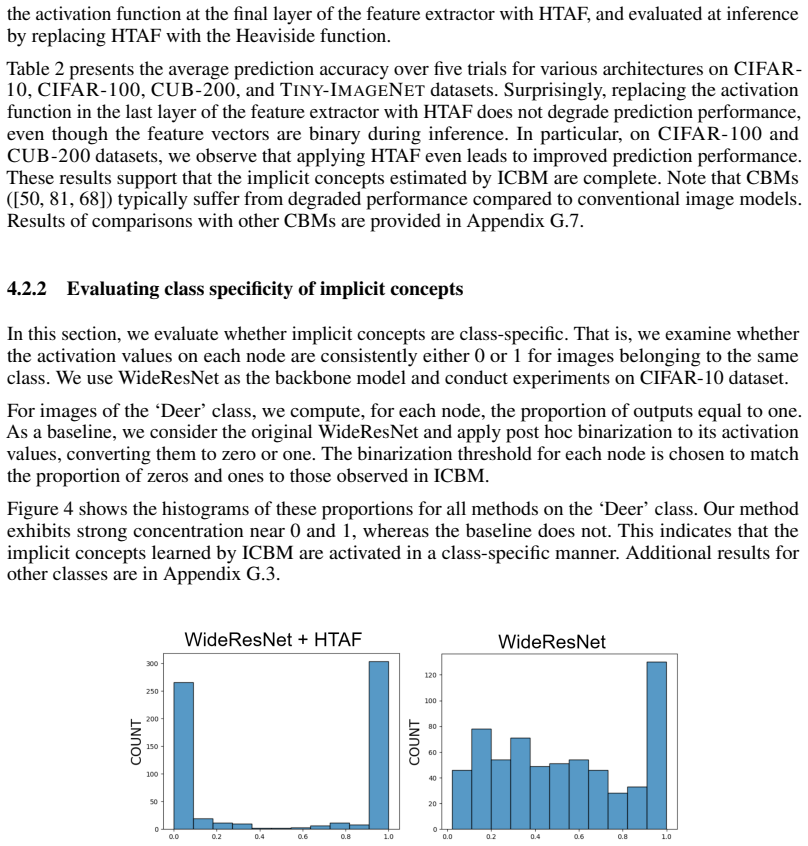
- [experiments section] Experiments section: reported stable convergence and performance on image datasets lack ablation controls that isolate HTAF from architecture-specific choices, learning-rate schedules, or other regularization; without such controls the causal link between the claimed gradient behavior and observed training stability cannot be verified.
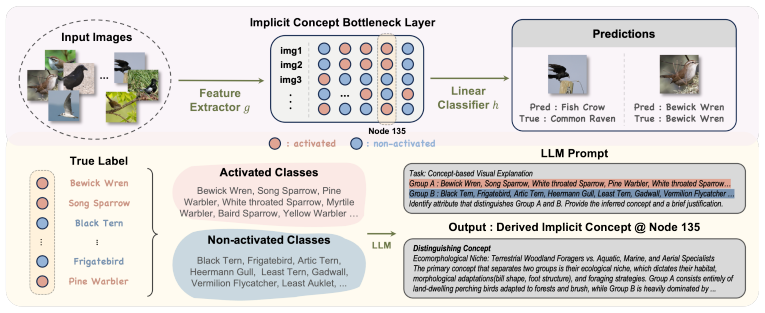
- [ICBM section] ICBM construction: while HTAF is used to induce discrete representations, the manuscript does not quantify the degree of binarization achieved (e.g., via entropy or fraction of near-binary activations) nor compare against standard concept-bottleneck baselines with post-hoc discretization, weakening the interpretability claim.
minor comments (2)
- [method section] Notation for the composite function (sigmoid-tanh product) should be defined explicitly with a single equation number rather than described in prose.
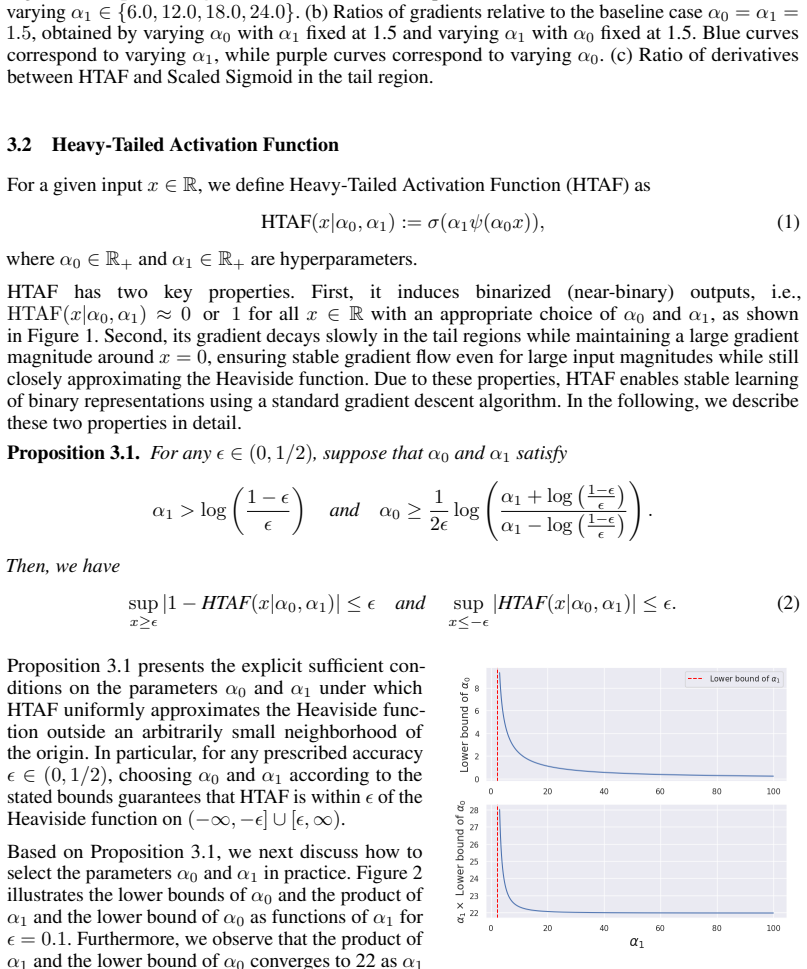
- [figures] Figure captions for gradient plots should include the exact parameter settings used to generate the curves and a direct overlay against ReLU and tanh for visual comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, outlining our planned revisions where appropriate while noting the limits of what can be addressed within the current scope.
read point-by-point responses
-
Referee: Theoretical analysis (gradient derivation): the per-neuron derivative is shown to maintain large mass near zero and slower tail decay, yet no analytic bound or perturbation argument is supplied demonstrating that these properties are preserved after multiplication by weight matrices and summation across layers under realistic weight distributions; this gap directly undermines the claim that isolated HTAF properties suffice for stable training of SNNs/BNNs/DHNNs.
Authors: We appreciate the referee's point on the theoretical gap. The manuscript derives the per-neuron gradient properties of HTAF as the core mechanism for maintaining gradient mass near zero with slower tail decay. While these properties are shown to enable stable multi-layer training in practice for SNNs, BNNs, and DHNNs, we acknowledge that a rigorous analytic bound or perturbation argument for arbitrary weight distributions is not provided. Deriving such bounds is non-trivial and would require substantial additional analysis beyond the paper's focus. In revision we will add a first-order perturbation argument for small weight perturbations around typical initializations, together with empirical measurements of gradient flow across layers, to better support the practical claims. revision: partial
-
Referee: Experiments section: reported stable convergence and performance on image datasets lack ablation controls that isolate HTAF from architecture-specific choices, learning-rate schedules, or other regularization; without such controls the causal link between the claimed gradient behavior and observed training stability cannot be verified.
Authors: We agree that the experiments would be strengthened by explicit ablations. The current results demonstrate stable convergence and competitive performance, but do not fully isolate HTAF. In the revised manuscript we will add controlled ablation studies that fix architecture, optimizer, learning-rate schedule, and regularization, comparing HTAF only against ReLU, sigmoid, tanh, and other smooth Heaviside approximations. These will directly test whether the observed stability and performance gains are attributable to HTAF's gradient properties. revision: yes
-
Referee: ICBM construction: while HTAF is used to induce discrete representations, the manuscript does not quantify the degree of binarization achieved (e.g., via entropy or fraction of near-binary activations) nor compare against standard concept-bottleneck baselines with post-hoc discretization, weakening the interpretability claim.
Authors: We thank the referee for this suggestion. To strengthen the interpretability claims for ICBMs, the revision will include quantitative measures of binarization: specifically, the entropy of the activation distributions and the fraction of activations lying within 0.05 of 0 or 1. We will also add direct comparisons against standard Concept Bottleneck Models that apply post-hoc discretization, reporting both predictive accuracy and the fidelity of the resulting discrete concepts. revision: yes
- Full analytic bounds demonstrating preservation of HTAF gradient properties after multiplication by weight matrices and summation across layers under realistic weight distributions
Circularity Check
No circularity: HTAF constructed explicitly and properties derived from definition before any training claims
full rationale
The paper defines HTAF directly as a sigmoid-tanh composite, then derives its gradient mass and tail decay analytically from that closed-form expression. No step renames a fitted parameter as a prediction, imports uniqueness via self-citation, or reduces the stability claim to the construction itself. Experiments on SNNs/BNNs/DHNNs and ICBMs are presented as downstream validation rather than the source of the gradient properties. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Sigmoid and hyperbolic tangent functions are continuously differentiable everywhere
invented entities (1)
-
HTAF
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe construct HTAF as a sigmoid hyperbolic tangent composite function and theoretically show that it maintains a large gradient mass around zero inputs while exhibiting slower gradient decay in the tail regions (Theorem 3.2, Proposition 3.1).
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearHTAF(x|α₀,α₁) := σ(α₁ ψ(α₀ x))
Reference graph
Works this paper leans on
-
[1]
Telco customer churn. kaggle, 2017. https://www.kaggle.com/datasets/blastchar/telco-customer- churn/data
work page 2017
-
[2]
FICO Explainable Learning Challenge, 2018
Fico heloc. FICO Explainable Learning Challenge, 2018. https://community.fico.com/s/ explainable-machine-learning-challenge
work page 2018
-
[3]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Yoshua Bengio, Nicholas Léonard, and Aaron Courville. Estimating or propagating gradients through stochastic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Garrett Bingham and Risto Miikkulainen. Efficient activation function optimization through surrogate modeling.Advances in Neural Information Processing Systems, 36:6634–6661, 2023
work page 2023
-
[5]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
work page 1901
-
[6]
Yongqiang Cao, Yang Chen, and Deepak Khosla. Spiking deep convolutional neural networks for energy-efficient object recognition.International Journal of Computer Vision, 113(1):54–66, 2015
work page 2015
-
[7]
Hashnet: Deep learning to hash by continuation
Zhangjie Cao, Mingsheng Long, Jianmin Wang, and Philip S Yu. Hashnet: Deep learning to hash by continuation. InProceedings of the IEEE international conference on computer vision, pages 5608–5617, 2017
work page 2017
-
[8]
Chao Chen, Chenghua Guo, Rufeng Chen, Guixiang Ma, Ming Zeng, Xiangwen Liao, Xi Zhang, and Sihong Xie. Training for stable explanation for free.Advances in Neural Information Processing Systems, 37:3421–3457, 2024
work page 2024
-
[9]
Wenlin Chen and Hong Ge. Neural characteristic activation analysis and geometric parameteri- zation for relu networks.Advances in Neural Information Processing Systems, 37:97562–97586, 2024
work page 2024
-
[10]
Paulo Cortez, A. Cerdeira, F. Almeida, T. Matos, and J. Reis. Wine Quality. 2009. DOI: https://doi.org/10.24432/C56S3T
-
[11]
Matthieu Courbariaux, Itay Hubara, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or-1.arXiv preprint arXiv:1602.02830, 2016
-
[12]
Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing
Peter U Diehl, Daniel Neil, Jonathan Binas, Matthew Cook, Shih-Chii Liu, and Michael Pfeiffer. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In2015 International joint conference on neural networks (IJCNN), pages 1–8. ieee, 2015
work page 2015
-
[13]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[14]
Tolga Ergen, Halil Ibrahim Gulluk, Jonathan Lacotte, and Mert Pilanci. Globally optimal training of neural networks with threshold activation functions.arXiv preprint arXiv:2303.03382, 2023
-
[15]
Wei Fang, Yanqi Chen, Jianhao Ding, Zhaofei Yu, Timothée Masquelier, Ding Chen, Liwei Huang, Huihui Zhou, Guoqi Li, and Yonghong Tian. Spikingjelly: An open-source machine learning infrastructure platform for spike-based intelligence.Science Advances, 9(40):eadi1480, 2023. 10
work page 2023
-
[16]
Wei Fang, Zhaofei Yu, Yanqi Chen, Tiejun Huang, Timothée Masquelier, and Yonghong Tian. Deep residual learning in spiking neural networks.Advances in neural information processing systems, 34:21056–21069, 2021
work page 2021
-
[17]
Craft: Concept recursive activation factorization for ex- plainability
Thomas Fel, Agustin Picard, Louis Bethune, Thibaut Boissin, David Vigouroux, Julien Colin, Rémi Cadène, and Thomas Serre. Craft: Concept recursive activation factorization for ex- plainability. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2711–2721, 2023
work page 2023
-
[18]
Amirata Ghorbani, James Wexler, James Y Zou, and Been Kim. Towards automatic concept- based explanations.Advances in neural information processing systems, 32, 2019
work page 2019
-
[19]
Understanding the difficulty of training deep feedfor- ward neural networks
Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedfor- ward neural networks. InProceedings of the thirteenth international conference on artificial intelligence and statistics, pages 249–256. JMLR Workshop and Conference Proceedings, 2010
work page 2010
-
[20]
Deep sparse rectifier neural networks
Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pages 315–323. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[21]
On the impact of the activation function on deep neural networks training
Soufiane Hayou, Arnaud Doucet, and Judith Rousseau. On the impact of the activation function on deep neural networks training. InInternational conference on machine learning, pages 2672–2680. PMLR, 2019
work page 2019
-
[22]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[23]
Augmix: A simple data processing method to improve robustness and uncertainty
Dan Hendrycks, Norman Mu, Ekin D Cubuk, Barret Zoph, Justin Gilmer, and Balaji Lakshmi- narayanan. Augmix: A simple data processing method to improve robustness and uncertainty. arXiv preprint arXiv:1912.02781, 2019
-
[24]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[25]
Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xiaojuan Qi. Billm: Pushing the limit of post-training quantization for llms.arXiv preprint arXiv:2402.04291, 2024
-
[26]
Quan- tized neural networks: Training neural networks with low precision weights and activations
Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Quan- tized neural networks: Training neural networks with low precision weights and activations. journal of machine learning research, 18(187):1–30, 2018
work page 2018
-
[27]
Shayan Hundrieser, Philipp Tuchel, Insung Kong, and Johannes Schmidt-Hieber. On the universal representation property of spiking neural networks.arXiv preprint arXiv:2512.16872, 2025
-
[28]
A Iliev, Nikolay Kyurkchiev, and Svetoslav Markov. On the approximation of the step function by some sigmoid functions.Mathematics and Computers in Simulation, 133:223–234, 2017
work page 2017
-
[29]
Yuling Jiao, Guohao Shen, Yuanyuan Lin, and Jian Huang. Deep nonparametric regression on approximate manifolds: Nonasymptotic error bounds with polynomial prefactors.The Annals of Statistics, 51(2):691–716, 2023
work page 2023
-
[30]
Rémi Kazmierczak, Steve Azzolin, Eloïse Berthier, Goran Frehse, and Gianni Franchi. Enhancing concept localization in clip-based concept bottleneck models.arXiv preprint arXiv:2510.07115, 2025
-
[31]
Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). InInternational conference on machine learning, pages 2668–2677. PMLR, 2018. 11
work page 2018
-
[32]
Pang Wei Koh, Thao Nguyen, Yew Siang Tang, Stephen Mussmann, Emma Pierson, Been Kim, and Percy Liang. Concept bottleneck models. InInternational conference on machine learning, pages 5338–5348. PMLR, 2020
work page 2020
-
[33]
Michael Kohler and Sophie Langer. On the rate of convergence of fully connected deep neural network regression estimates.The Annals of Statistics, 49(4):2231 – 2249, 2021
work page 2021
-
[34]
On the expressivity of deep heaviside networks.arXiv preprint arXiv:2505.00110, 2025
Insung Kong, Juntong Chen, Sophie Langer, and Johannes Schmidt-Hieber. On the expressivity of deep heaviside networks.arXiv preprint arXiv:2505.00110, 2025
-
[35]
Insung Kong and Yongdai Kim. Posterior concentrations of fully-connected bayesian neural networks with general priors on the weights.Journal of Machine Learning Research, 26(94):1– 60, 2025
work page 2025
-
[36]
Learning multiple layers of features from tiny images
Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009
work page 2009
-
[37]
Interpretable generative models through post-hoc concept bottlenecks
Akshay Kulkarni, Ge Yan, Chung-En Sun, Tuomas Oikarinen, and Tsui-Wei Weng. Interpretable generative models through post-hoc concept bottlenecks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8162–8171, 2025
work page 2025
-
[38]
Self- binarizing networks.arXiv preprint arXiv:1902.00730, 2019
Fayez Lahoud, Radhakrishna Achanta, Pablo Márquez-Neila, and Sabine Süsstrunk. Self- binarizing networks.arXiv preprint arXiv:1902.00730, 2019
-
[39]
Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
Yann Le and Xuan Yang. Tiny imagenet visual recognition challenge.CS 231N, 7(7):3, 2015
work page 2015
-
[40]
Seeking interpretability and explainability in binary activated neural networks
Benjamin Leblanc and Pascal Germain. Seeking interpretability and explainability in binary activated neural networks. InWorld Conference on Explainable Artificial Intelligence, pages 3–20. Springer, 2024
work page 2024
-
[41]
Yuhang Li, Yufei Guo, Shanghang Zhang, Shikuang Deng, Yongqing Hai, and Shi Gu. Differ- entiable spike: Rethinking gradient-descent for training spiking neural networks.Advances in neural information processing systems, 34:23426–23439, 2021
work page 2021
-
[42]
Zechun Liu, Baoyuan Wu, Wenhan Luo, Xin Yang, Wei Liu, and Kwang-Ting Cheng. Bi-real net: Enhancing the performance of 1-bit cnns with improved representational capability and advanced training algorithm. InProceedings of the European conference on computer vision (ECCV), pages 722–737, 2018
work page 2018
-
[43]
Jianfeng Lu, Zuowei Shen, Haizhao Yang, and Shijun Zhang. Deep network approximation for smooth functions.SIAM Journal on Mathematical Analysis, 53(5):5465–5506, 2021
work page 2021
-
[44]
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Lifeng Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits.arXiv preprint arXiv:2402.17764, 1(4), 2024
-
[45]
Networks of spiking neurons: the third generation of neural network models
Wolfgang Maass. Networks of spiking neurons: the third generation of neural network models. Neural networks, 10(9):1659–1671, 1997
work page 1997
-
[46]
Torchvision: Pytorch’s computer vision library
TorchVision maintainers and contributors. Torchvision: Pytorch’s computer vision library. https://github.com/pytorch/vision, 2016
work page 2016
-
[47]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391, 2018
work page 2018
-
[48]
Emre O Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks.IEEE Signal Processing Magazine, 36(6):51–63, 2019
work page 2019
-
[49]
Ilsang Ohn and Yongdai Kim. Smooth function approximation by deep neural networks with general activation functions.Entropy, 21(7):627, 2019
work page 2019
-
[50]
Label-free concept bottleneck models.arXiv preprint arXiv:2304.06129, 2023
Tuomas Oikarinen, Subhro Das, Lam M Nguyen, and Tsui-Wei Weng. Label-free concept bottleneck models.arXiv preprint arXiv:2304.06129, 2023. 12
-
[51]
Philipp Petersen and Felix V oigtlaender. Optimal approximation of piecewise smooth functions using deep ReLU neural networks.Neural Networks, 108:296–330, 2018
work page 2018
-
[52]
Binary neural networks: A survey.Pattern Recognition, 105:107281, 2020
Haotong Qin, Ruihao Gong, Xianglong Liu, Xiao Bai, Jingkuan Song, and Nicu Sebe. Binary neural networks: A survey.Pattern Recognition, 105:107281, 2020
work page 2020
-
[53]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026
work page 2026
-
[54]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[55]
Xnor-net: Imagenet classification using binary convolutional neural networks
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary convolutional neural networks. InEuropean conference on computer vision, pages 525–542. Springer, 2016
work page 2016
-
[56]
Frank Rosenblatt. The perceptron: a probabilistic model for information storage and organization in the brain.Psychological review, 65(6):386, 1958
work page 1958
-
[57]
Bodo Rueckauer, Iulia-Alexandra Lungu, Yuhuang Hu, Michael Pfeiffer, and Shih-Chii Liu. Conversion of continuous-valued deep networks to efficient event-driven networks for image classification.Frontiers in neuroscience, 11:682, 2017
work page 2017
-
[58]
Learning representations by back-propagating errors.nature, 323(6088):533–536, 1986
David E Rumelhart, Geoffrey E Hinton, and Ronald J Williams. Learning representations by back-propagating errors.nature, 323(6088):533–536, 1986
work page 1986
-
[59]
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
work page 2021
-
[60]
Deep relu network approximation of functions on a manifold.arXiv preprint arXiv:1908.00695, 2019
Johannes Schmidt-Hieber. Deep relu network approximation of functions on a manifold.arXiv preprint arXiv:1908.00695, 2019
-
[61]
Johannes Schmidt-Hieber. Nonparametric regression using deep neural networks with ReLU activation function.The Annals of Statistics, 48(4):1875 – 1897, 2020
work page 2020
-
[62]
Abhronil Sengupta, Yuting Ye, Robert Wang, Chiao Liu, and Kaushik Roy. Going deeper in spiking neural networks: Vgg and residual architectures.Frontiers in neuroscience, 13:95, 2019
work page 2019
-
[63]
GLU Variants Improve Transformer
Noam Shazeer. Glu variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[64]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
Low curvature activations reduce overfitting in adversarial training
Vasu Singla, Sahil Singla, Soheil Feizi, and David Jacobs. Low curvature activations reduce overfitting in adversarial training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16423–16433, 2021
work page 2021
-
[66]
Deep learning in spiking neural networks.Neural networks, 111:47–63, 2019
Amirhossein Tavanaei, Masoud Ghodrati, Saeed Reza Kheradpisheh, Timothée Masquelier, and Anthony Maida. Deep learning in spiking neural networks.Neural networks, 111:47–63, 2019
work page 2019
-
[67]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[68]
Moritz Vandenhirtz, Sonia Laguna, Riˇcards Marcinkeviˇcs, and Julia V ogt. Stochastic concept bottleneck models.Advances in Neural Information Processing Systems, 37:51787–51810, 2024
work page 2024
-
[69]
C. Wah, S. Branson, P. Welinder, P. Perona, and S. Belongie. The caltech-ucsd birds-200-2011 dataset. Technical Report CNS-TR-2011-001, California Institute of Technology, 2011. 13
work page 2011
-
[70]
Bitnet: Scaling 1-bit transformers for large language models,
Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao Ma, Fan Yang, Ruiping Wang, Yi Wu, and Furu Wei. Bitnet: Scaling 1-bit transformers for large language models.arXiv preprint arXiv:2310.11453, 2023
-
[71]
Qingcan Wang et al. Exponential convergence of the deep neural network approximation for analytic functions.arXiv preprint arXiv:1807.00297, 2018
-
[72]
Nash Warwick, Sellers Tracy, Talbot Simon, Cawthorn Andrew, and Ford Wes. Abalone. UCI Machine Learning Repository, 1995. DOI: https://doi.org/10.24432/C55C7W
-
[73]
Zhirong Wu, Dahua Lin, and Xiaoou Tang. Adjustable bounded rectifiers: Towards deep binary representations.arXiv preprint arXiv:1511.06201, 2015
-
[74]
Smooth adversarial training.arXiv preprint arXiv:2006.14536, 2020
Cihang Xie, Mingxing Tan, Boqing Gong, Alan Yuille, and Quoc V Le. Smooth adversarial training.arXiv preprint arXiv:2006.14536, 2020
-
[75]
Yunfei Yang and Ding-Xuan Zhou. Optimal rates of approximation by shallow ReLUk neural networks and applications to nonparametric regression.Constructive Approximation, pages 1–32, 2024
work page 2024
-
[76]
Error bounds for approximations with deep ReLU networks.Neural Networks, 94:103–114, 2017
Dmitry Yarotsky. Error bounds for approximations with deep ReLU networks.Neural Networks, 94:103–114, 2017
work page 2017
-
[77]
Penghang Yin, Jiancheng Lyu, Shuai Zhang, Stanley Osher, Yingyong Qi, and Jack Xin. Under- standing straight-through estimator in training activation quantized neural nets.arXiv preprint arXiv:1903.05662, 2019
-
[78]
Ansheng You, Xiangtai Li, Zhen Zhu, and Yunhai Tong. Torchcv: A pytorch-based framework for deep learning in computer vision.https://github.com/donnyyou/torchcv, 2019
work page 2019
-
[79]
Chang Yue and Niraj K Jha. Learning interpretable differentiable logic networks.IEEE Transactions on Circuits and Systems for Artificial Intelligence, 2024
work page 2024
-
[80]
Mert Yuksekgonul, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. When and why vision-language models behave like bags-of-words, and what to do about it?arXiv preprint arXiv:2210.01936, 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.