Recognition: no theorem link
Dynamic Execution Commitment of Vision-Language-Action Models
Pith reviewed 2026-05-13 01:41 UTC · model grok-4.3
The pith
Vision-language-action models can adaptively commit to action sequences by verifying the longest consistent prefix through consensus sampling and invariance checks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that reframing execution commitment as self-speculative prefix verification allows A3 to select the longest verifiable prefix by using group sampling for a trajectory-wise consensus score and applying consensus-ordered conditional invariance along with prefix-closed sequential consistency, thereby satisfying both model logic and execution constraints without fixed horizons.
What carries the argument
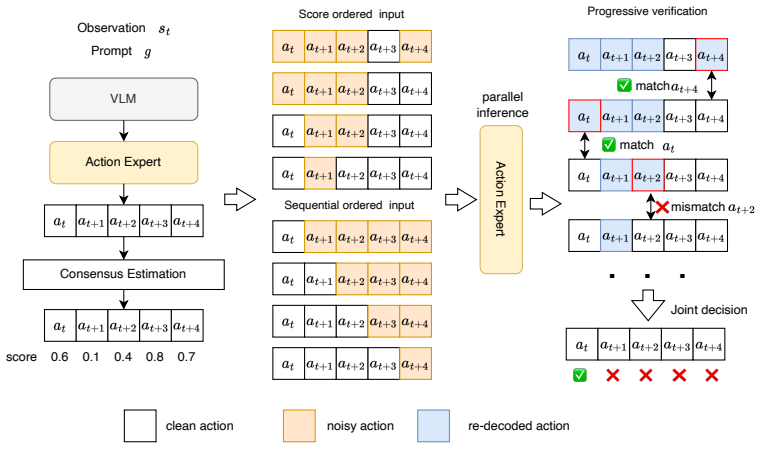
The Adaptive Action Acceptance (A3) mechanism, which uses group sampling to compute consensus scores and enforces two verification rules to determine the verifiable action prefix.
If this is right
- Eliminates manual tuning of execution horizons for different tasks.
- Provides a superior balance between success rate and inference speed across benchmarks.
- Enhances performance in dynamic and out-of-distribution environments.
- Applies to various existing VLA models without modification.
Where Pith is reading between the lines
- This verification strategy could be applied to other sequential prediction tasks like language modeling or video forecasting.
- It suggests that internal model uncertainty can be probed through self-consistency checks without external supervision.
- In practice, it might allow for more efficient resource use in robotic systems by avoiding unnecessary recomputation.
Load-bearing premise
A trajectory-wise consensus score from group sampling plus the two verification rules will accurately flag reliable prefixes even when the environment is dynamic or unfamiliar.
What would settle it
Running A3 on a VLA model in a simulated environment with unpredictable obstacles and measuring if the accepted horizons lead to fewer failures than fixed-horizon baselines while maintaining comparable average inference times.
Figures


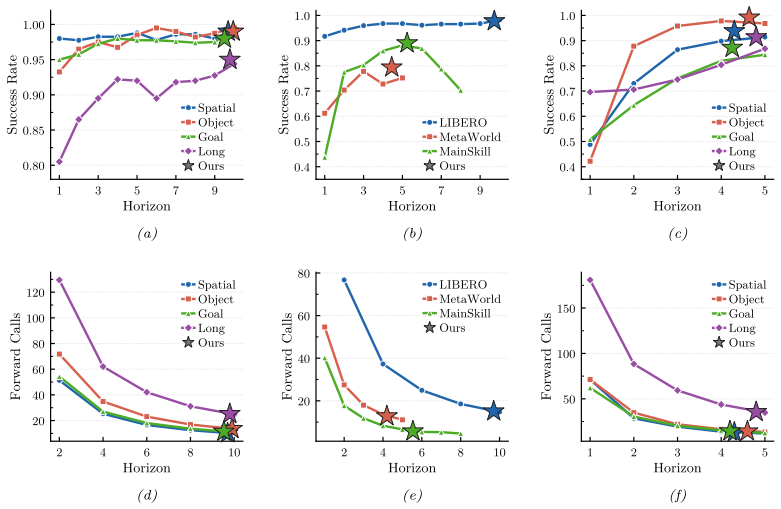


read the original abstract
Vision-Language-Action (VLA) models predominantly adopt action chunking, i.e., predicting and committing to a short horizon of consecutive low-level actions in a single forward pass, to amortize the inference cost of large-scale backbones and reduce per-step latency. However, committing these multi-step predictions to real-world execution requires balancing success rate against inference efficiency, a decision typically governed by fixed execution horizons tuned per task. Such heuristics ignore the state-dependent nature of predictive reliability, leading to brittle performance in dynamic or out-of-distribution settings. In this paper, we introduce A3, an Adaptive Action Acceptance mechanism that reframes dynamic execution commitment as a self-speculative prefix verification problem. A3 first computes a trajectory-wise consensus score of actions via group sampling, then selects a representative draft and prioritizes downstream verification. Specifically, it enforces: (1) consensus-ordered conditional invariance, which validates low-consensus actions by judging whether they remain consistent when re-decoded conditioned on high-consensus actions; and (2) prefix-closed sequential consistency, which guarantees physical rollout integrity by accepting only the longest continuous sequence of verified actions starting from the beginning. Consequently, the execution horizon emerges as the longest verifiable prefix satisfying both internal model logic and sequential execution constraints. Experiments across diverse VLA models and benchmarks demonstrate that A3 eliminates the need for manual horizon tuning while achieving a superior trade-off between execution robustness and inference throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces A3, an Adaptive Action Acceptance mechanism for Vision-Language-Action (VLA) models. It reframes dynamic execution commitment of action chunks as a self-speculative prefix verification problem: a trajectory-wise consensus score is computed via group sampling, a representative draft is selected, and two rules are enforced—(1) consensus-ordered conditional invariance (re-decoding low-consensus actions conditioned on high-consensus ones) and (2) prefix-closed sequential consistency (accepting only the longest continuous verified prefix). The execution horizon is defined as the longest prefix satisfying both rules, eliminating manual tuning while improving the robustness-throughput trade-off, as shown in experiments across VLA models and benchmarks.
Significance. If the internal verification rules correlate with actual execution reliability, A3 offers a practical advance for deploying VLA models in dynamic settings by adapting horizons without external feedback or per-task tuning. The self-contained nature (no simulator or ground-truth required) is a potential strength for real-world use, but only if the internal checks prove robust.
major comments (2)
- [Abstract and Method (verification rules)] Abstract and Method section on verification rules: both Rule (1) (consensus-ordered conditional invariance) and Rule (2) (prefix-closed sequential consistency) operate exclusively via internal group sampling and re-decoding within the model's generative distribution, with no external grounding (ground-truth actions, simulator rollouts, or state feedback). This makes the central claim that the selected prefix satisfies 'sequential execution constraints' and 'physical rollout integrity' vulnerable to internally consistent but factually incorrect sequences under distribution shift.
- [Experiments] Experiments section: the reported superior trade-off between execution robustness and inference throughput is not accompanied by ablations or controls demonstrating that the adaptive horizon outperforms fixed horizons specifically in OOD or dynamic regimes; without such evidence the claim that A3 'eliminates the need for manual horizon tuning' while improving performance rests on unverified correlation between internal consensus and actual reliability.
minor comments (2)
- [Abstract] Abstract: the acronym 'A3' is introduced without expansion on first use.
- [Method] Method: the process for selecting the 'representative draft' after computing the trajectory-wise consensus score is described only at high level; a pseudocode listing or diagram would clarify the pipeline.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments on our manuscript. We address each major comment below, providing clarifications and indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and Method (verification rules)] Abstract and Method section on verification rules: both Rule (1) (consensus-ordered conditional invariance) and Rule (2) (prefix-closed sequential consistency) operate exclusively via internal group sampling and re-decoding within the model's generative distribution, with no external grounding (ground-truth actions, simulator rollouts, or state feedback). This makes the central claim that the selected prefix satisfies 'sequential execution constraints' and 'physical rollout integrity' vulnerable to internally consistent but factually incorrect sequences under distribution shift.
Authors: We agree that A3's verification rules rely exclusively on internal group sampling and re-decoding without external grounding such as ground-truth actions or simulator feedback. This is an intentional design decision to support deployment in real-world settings where external signals may be unavailable or costly. The consensus score and conditional invariance checks are meant to identify prefixes where the model's own generative distribution exhibits high internal agreement and consistency, which our experiments indicate correlates with reliable execution. However, we recognize that under severe distribution shift, internally consistent sequences could still be factually incorrect. To address this concern directly, we will add a dedicated Limitations section in the revised manuscript that explicitly discusses the internal nature of the verification, its potential vulnerabilities, and avenues for future hybrid approaches that incorporate external feedback when available. revision: yes
-
Referee: [Experiments] Experiments section: the reported superior trade-off between execution robustness and inference throughput is not accompanied by ablations or controls demonstrating that the adaptive horizon outperforms fixed horizons specifically in OOD or dynamic regimes; without such evidence the claim that A3 'eliminates the need for manual horizon tuning' while improving performance rests on unverified correlation between internal consensus and actual reliability.
Authors: Our current experiments evaluate A3 on multiple VLA models and benchmarks that include dynamic and challenging scenarios, demonstrating improved robustness-throughput trade-offs relative to fixed-horizon baselines. These results support the practical benefit of adaptive horizons. That said, we concur that more explicit ablations isolating performance in out-of-distribution (OOD) regimes would provide stronger evidence for the claim that A3 eliminates manual tuning while improving reliability. In the revised manuscript, we will incorporate additional ablation studies and controls that directly compare A3 against a range of fixed horizons under OOD and dynamic test conditions to better substantiate the correlation between internal consensus and execution reliability. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines A3 as a self-contained heuristic that computes a consensus score via internal group sampling and applies two new verification rules (consensus-ordered conditional invariance and prefix-closed sequential consistency) to select the longest prefix. The execution horizon is presented as the direct outcome of these rules by construction, with no equations, fitted parameters renamed as predictions, or load-bearing self-citations shown in the abstract or described method. The derivation does not reduce any claimed result to prior inputs; it introduces novel internal checks without external grounding or tautological loops.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Group sampling produces a trajectory-wise consensus score that reflects predictive reliability
- domain assumption Conditional invariance and prefix-closed consistency together guarantee safe execution commitment
invented entities (1)
-
A3 Adaptive Action Acceptance mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. pi-0.5: a vision- language-action model with open-world generalization.arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Gr-3 technical report.arXiv preprint arXiv:2507.15493,
Chilam Cheang, Sijin Chen, Zhongren Cui, Yingdong Hu, Liqun Huang, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Xiao Ma, et al. Gr-3 technical report.arXiv preprint arXiv:2507.15493, 2025
-
[4]
arXiv preprint arXiv:2510.24795 (2025)
Zhaoshu Yu, Bo Wang, Pengpeng Zeng, Haonan Zhang, Ji Zhang, Lianli Gao, Jingkuan Song, Nicu Sebe, and Heng Tao Shen. A survey on efficient vision-language-action models, 2025. arXiv preprint arXiv:2510.24795. 12
-
[5]
A Survey on Vision-Language-Action Models for Embodied AI
Yecheng Jason Ma, Zhen Song, Yu Zhuang, Jianye Hao, and Irwin King. A survey on vision- language-action models for embodied ai, 2024. arXiv preprint arXiv:2405.14093
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
arXiv preprint arXiv:2508.13073 (2025)
Runze Shao, Wenxuan Li, Lei Zhang, Rui Zhang, Zhicheng Liu, Ruocheng Chen, and Liqiang Nie. Large vlm-based vision-language-action models for robotic manipulation: A survey, 2025. arXiv preprint arXiv:2508.13073
-
[7]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
work page 2023
-
[9]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. pi-0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
Dong Jing, Gang Wang, Jiaqi Liu, Weiliang Tang, Zelong Sun, Yunchao Yao, Zhenyu Wei, Yunhui Liu, Zhiwu Lu, and Mingyu Ding. Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
-
[11]
Samarth Chopra, Alex McMoil, Ben Carnovale, Evan Sokolson, Rajkumar Kubendran, and Samuel Dickerson. Everydayvla: A vision-language-action model for affordable robotic manipulation.arXiv preprint arXiv:2511.05397, 2025
-
[12]
Vla knows its limits.arXiv preprint arXiv:2602.21445, 2026
Haoxuan Wang, Gengyu Zhang, Yan Yan, Ramana Rao Kompella, and Gaowen Liu. Vla knows its limits.arXiv preprint arXiv:2602.21445, 2026
-
[13]
When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781,
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view.arXiv preprint arXiv:2410.10781, 2024
-
[14]
See what you are told: Visual attention sink in large multimodal models
Seil Kang, Jinyeong Kim, Junhyeok Kim, and Seong Jae Hwang. See what you are told: Visual attention sink in large multimodal models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[15]
Self speculative decoding for diffusion large language models.arXiv preprint arXiv:2510.04147,
Yifeng Gao, Ziang Ji, Yuxuan Wang, Biqing Qi, Hanlin Xu, and Linfeng Zhang. Self speculative decoding for diffusion large language models.arXiv preprint arXiv:2510.04147, 2025
-
[16]
Fast inference from transformers via speculative decoding
Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR, 2023
work page 2023
-
[17]
Spatialvla: Exploring spatial representations for visual-language-action models
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Jiayuan Gu, Zhigang Wang, Yan Ding, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Exploring spatial representations for visual-language-action models. InProceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June 2025
work page 2025
-
[18]
Learning to act anywhere with task-centric latent actions
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Learning to act anywhere with task-centric latent actions. InProceedings of Robotics: Science and Systems, Los Angeles, CA, USA, June 2025
work page 2025
-
[19]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, Abby O’Neill, et al. Open x-embodiment: Robotic learning datasets and rt-x models, 2023. arXiv preprint arXiv:2310.08864. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
PaliGemma: A versatile 3B VLM for transfer
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, et al. Paligemma: A versatile 3b vlm for transfer.arXiv preprint arXiv:2407.07726, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023. arXiv preprint arXiv:2303.04137
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Wei Song, Jie Chen, Peng Ding, Hao Zhao, Wei Zhao, Zhi Zhong, Zhen Ge, Jun Ma, and Hong Li. PD-VLA: Accelerating vision-language-action model integrated with action chunking via parallel decoding, 2025. arXiv preprint arXiv:2503.02310
-
[25]
Freqpolicy: Efficient flow-based visuomotor policy via frequency consistency, 2025
Yu Su, Ning Liu, Dong Chen, Zhen Zhao, Kun Wu, Meng Li, Zhi Xu, Zhe Che, and Jie Tang. Freqpolicy: Efficient flow-based visuomotor policy via frequency consistency, 2025. arXiv preprint arXiv:2506.08822
-
[26]
Tony Z. Zhao et al. Learning fine-grained bimanual manipulation with low-cost hardware. In Robotics: Science and Systems (RSS), 2023
work page 2023
-
[27]
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
work page 2022
-
[28]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. RLBench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
work page 2020
-
[29]
DROID: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, et al. DROID: A large-scale in-the-wild robot manipulation dataset. InProceedings of Robotics: Science and Systems, Delft, Netherlands, July 2024
work page 2024
-
[30]
Yefei He, Feng Chen, Yuanyu He, Shaoxuan He, Hong Zhou, Kaipeng Zhang, and Bohan Zhuang. Zipar: Accelerating autoregressive image generation through spatial locality.arXiv preprint arXiv:2412.04062, 2(3):4, 2024
-
[31]
Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, and Wenjie Li. Swift: On-the-fly self- speculative decoding for llm inference acceleration.arXiv preprint arXiv:2410.06916, 2024
-
[32]
Large Language Diffusion Models
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. Large language diffusion models.arXiv preprint arXiv:2502.09992, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Fucai Ke, Joy Hsu, Zhixi Cai, Zixian Ma, Xin Zheng, Xindi Wu, Sukai Huang, Weiqing Wang, Pari Delir Haghighi, Gholamreza Haffari, et al. Explain before you answer: A survey on compositional visual reasoning.arXiv preprint arXiv:2508.17298, 2025
-
[34]
Shuo Wang, Ruize Yu, Zhiyuan Yuan, Chao Yu, Feng Gao, Yilin Wang, and Derek F. Wong. Spec-vla: Speculative decoding for vision-language-action models with relaxed acceptance,
- [35]
-
[36]
Kailas S Holkar and Laxman M Waghmare. An overview of model predictive control.Interna- tional Journal of control and automation, 3(4):47–63, 2010
work page 2010
-
[37]
Model predictive control.Switzerland: Springer International Publishing, 38(13-56):7, 2016
Basil Kouvaritakis and Mark Cannon. Model predictive control.Switzerland: Springer International Publishing, 38(13-56):7, 2016
work page 2016
-
[38]
arXiv preprint arXiv:2510.25122 (2025)
Jiahong Chen, Jing Wang, Long Chen, Chuwei Cai, and Jinghui Lu. Nanovla: Routing decoupled vision-language understanding for nano-sized generalist robotic policies.arXiv preprint arXiv:2510.25122, 2025
-
[39]
The kinematics of contact and grasp.The International Journal of Robotics Research, 7(3):17–32, 1988
David J Montana. The kinematics of contact and grasp.The International Journal of Robotics Research, 7(3):17–32, 1988. 14 VLM Observation Prompt Action Expert Consensus Estimation 0.8 0.70.6 0.40.1 Score ordered input Sequential ordered input Action Expert Progressive verification match✅ match✅ mismatch❌ . . . ✅ ❌ ❌ ❌ ❌ parallel inference Joint decision sc...
work page 1988
-
[40]
Hongzhi Zang, Shu’ang Yu, Hao Lin, Tianxing Zhou, Zefang Huang, Zhen Guo, Xin Xu, Jiakai Zhou, Yuze Sheng, Shizhe Zhang, Feng Gao, Wenhao Tang, Yufeng Yue, Quanlu Zhang, Xinlei Chen, Chao Yu, and Yu Wang. Rlinf-user: A unified and extensible system for real-world online policy learning in embodied ai.arXiv preprint arXiv:2602.07837, 2026
-
[41]
Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Yang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations.arXiv preprint arXiv:2107.14483, 2021
-
[42]
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning
Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. InConference on robot learning, pages 1094–1100. PMLR, 2020. A Implementation Details Implementation of the verification tree.As shown in Figure 6, following the self-s...
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.