Recognition: 2 theorem links
· Lean TheoremEfficient LLM-based Advertising via Model Compression and Parallel Verification
Pith reviewed 2026-05-13 01:40 UTC · model grok-4.3
The pith
A framework using adaptive quantization, sparsification, and prefix-tree verification speeds up LLM inference for advertising while keeping quality acceptable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors introduce the Efficient Generative Targeting framework that integrates adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification. When applied to LLMs in ad creative generation and targeted advertising, the framework produces significant inference speedup while the resulting quality degradation stays within limits that remain usable for real deployments.
What carries the argument
The Efficient Generative Targeting framework, which combines adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification to reduce computation and latency in LLM inference.
If this is right
- LLM-based ad creative generation can run in real time inside production systems.
- Computational costs for deploying generative models in advertising drop substantially.
- Quality remains high enough to support operational advertising workflows.
- The same integrated approach works across both creative generation and targeting tasks.
Where Pith is reading between the lines
- The same three techniques might transfer to other real-time LLM tasks such as personalized recommendations or customer support.
- Further scaling the parallel verification could allow even larger base models to run under tight latency budgets.
- The interaction between quantization and sparsification may create additional efficiency gains that current experiments do not yet measure.
Load-bearing premise
The compression and verification steps preserve ad generation quality at a level that stays acceptable for real advertising use.
What would settle it
A side-by-side test on the two real-world advertising scenarios in which the framework's output produces measurably worse user engagement or conversion rates than the full-precision model.
Figures


read the original abstract
Large language models (LLMs) have shown remarkable potential in advertising scenarios such as ad creative generation and targeted advertising. However, deploying LLMs in real-time advertising systems poses significant challenges due to their high inference latency and computational cost. In this paper, we propose an Efficient Generative Targeting framework that integrates adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification to accelerate LLM inference while preserving generation quality. Extensive experiments on two real-world advertising scenarios demonstrate that our framework achieves significant speedup with acceptable quality degradation, making it operationally viable for practical deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an Efficient Generative Targeting framework for LLMs in advertising that integrates adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification to accelerate inference while preserving generation quality. It reports that experiments on two real-world advertising scenarios demonstrate significant speedup with acceptable quality degradation, rendering the approach operationally viable.
Significance. If the empirical claims are supported by rigorous, advertising-specific metrics and baselines, the work could have practical significance for real-time LLM deployment in advertising by reducing latency and cost through targeted compression and verification. The combination of techniques represents a pragmatic engineering synthesis, though its impact hinges on demonstrating that quality preservation translates to downstream advertising performance.
major comments (2)
- [Abstract] Abstract: The central claim that 'experiments on two real-world advertising scenarios demonstrate that our framework achieves significant speedup with acceptable quality degradation' supplies no quantitative results, baselines, error bars, or methodology. This is load-bearing because the abstract provides no data against which to evaluate either the speedup magnitude or whether the degradation remains acceptable for operational viability.
- [Experiments] Experiments section: No details are given on the evaluation metrics used, the exact nature of the two scenarios, or any ad-specific proxies (e.g., CTR lift, targeting relevance, or conversion impact). Without explicit degradation ceilings tied to advertising outcomes rather than generic NLP scores, the conclusion of operational viability does not follow from the reported evidence.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least one concrete quantitative highlight (e.g., latency reduction factor and quality metric delta) to allow readers to immediately gauge the result.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments point by point below and will make the necessary revisions to improve clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'experiments on two real-world advertising scenarios demonstrate that our framework achieves significant speedup with acceptable quality degradation' supplies no quantitative results, baselines, error bars, or methodology. This is load-bearing because the abstract provides no data against which to evaluate either the speedup magnitude or whether the degradation remains acceptable for operational viability.
Authors: We agree that the abstract would be strengthened by including quantitative support for the central claim. In the revised manuscript, we will update the abstract to report the key empirical results from our experiments, including the observed speedup factors, quality degradation levels with associated error bars, the baselines compared against, and a brief note on the evaluation methodology. This will enable readers to directly assess the magnitude of the improvements and the acceptability of any trade-offs. revision: yes
-
Referee: [Experiments] Experiments section: No details are given on the evaluation metrics used, the exact nature of the two scenarios, or any ad-specific proxies (e.g., CTR lift, targeting relevance, or conversion impact). Without explicit degradation ceilings tied to advertising outcomes rather than generic NLP scores, the conclusion of operational viability does not follow from the reported evidence.
Authors: The referee correctly identifies that the experiments section requires additional detail to substantiate the claim of operational viability. We will expand this section to describe the two real-world advertising scenarios in full, specify all evaluation metrics (including both standard NLP metrics and advertising-specific proxies such as CTR lift, targeting relevance, and conversion impact), and explicitly define degradation thresholds linked to downstream business outcomes. We will also clarify how the observed results support practical deployment in advertising systems. revision: yes
Circularity Check
No circularity: empirical engineering integration with no derivation chain or fitted predictions
full rationale
The paper presents an engineering framework combining adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification for LLM inference acceleration in advertising. It reports experimental results on real-world scenarios showing speedup with acceptable quality degradation. No mathematical derivations, equations, parameter fitting to subsets followed by 'predictions,' self-citations as load-bearing uniqueness theorems, or ansatzes smuggled via prior work are described. The central claim rests on empirical measurements rather than any self-referential reduction of outputs to inputs by construction. This is a standard non-circular empirical study.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
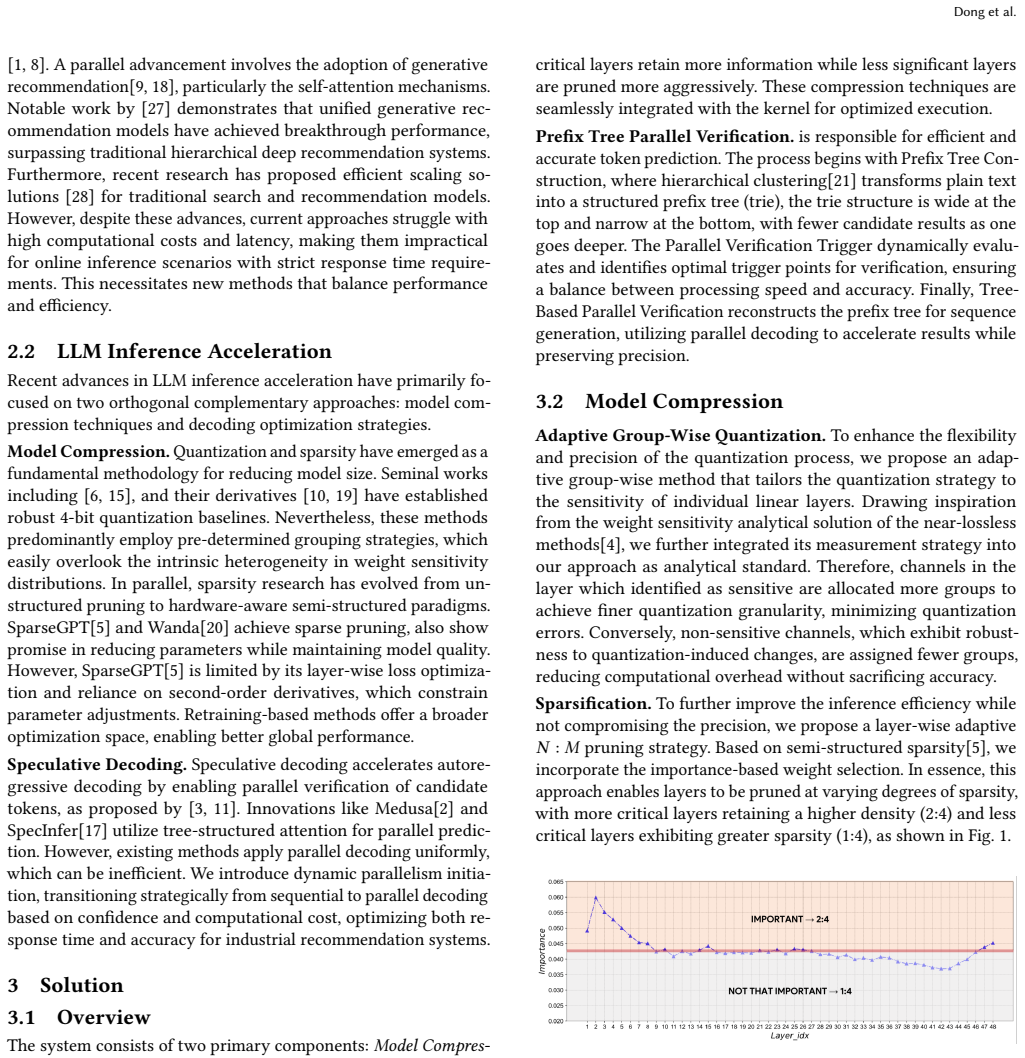
adaptive group-wise quantization... layer-wise semi-structured sparsity... prefix tree-based parallel verification... SparseGemv acceleration kernel
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
hierarchical clustering... prefix tree... beam search
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He
- [2]
-
[3]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. 2024. Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads. InICML
work page 2024
-
[4]
Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Lau- rent Sifre, and John Jumper. 2023. Accelerating Large Language Model Decoding with Speculative Sampling.CoRRabs/2302.01318 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Tim Dettmers, Ruslan Svirschevski, Vage Egiazarian, Denis Kuznedelev, Elias Frantar, Saleh Ashkboos, Alexander Borzunov, Torsten Hoefler, and Dan Alistarh
-
[6]
SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression. InICLR
-
[7]
Elias Frantar and Dan Alistarh. 2023. SparseGPT: Massive Language Models Can be Accurately Pruned in One-Shot. InICML, Vol. 202. PMLR, 10323–10337
work page 2023
-
[8]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2023. GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. InICLR
work page 2023
-
[9]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5). InRecSys. ACM, 299–315
work page 2022
-
[10]
Yeongseo Jung, Eunseo Jung, and Lei Chen. 2023. Towards a Unified Con- versational Recommendation System: Multi-task Learning via Contextualized Knowledge Distillation. InEMNLP. 13625–13637
work page 2023
-
[11]
Wang-Cheng Kang and Julian J. McAuley. 2018. Self-Attentive Sequential Rec- ommendation. InICDM. IEEE, 197–206
work page 2018
-
[12]
Changhun Lee, Jungyu Jin, Taesu Kim, Hyungjun Kim, and Eunhyeok Park
-
[13]
OWQ: Outlier-Aware Weight Quantization for Efficient Fine-Tuning and Inference of Large Language Models. InAAAI. 13355–13364
-
[14]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. InICML, Vol. 202. PMLR, 19274–19286
work page 2023
-
[15]
Yudong Li, Yuqing Zhang, Zhe Zhao, Linlin Shen, Weijie Liu, Weiquan Mao, and Hui Zhang. 2022. CSL: A Large-scale Chinese Scientific Literature Dataset. In ICCL. 3917–3923
work page 2022
-
[16]
Jiayi Liao, Sihang Li, Zhengyi Yang, Jiancan Wu, Yancheng Yuan, Xiang Wang, and Xiangnan He. 2024. LLaRA: Large Language-Recommendation Assistant. In SIGIR. ACM, 1785–1795
work page 2024
-
[17]
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, and Weinan Zhang. 2024. ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation. InWWW. ACM, 3497–3508
work page 2024
-
[18]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration. InMLSys
work page 2024
- [19]
-
[20]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. 2024. SpecInfer: Accelerating Large Language Model Serving with Tree- based Speculative Inference and Verification. InProceedings of the 29t...
work page 2024
-
[21]
Aleksandr V. Petrov and Craig Macdonald. 2023. Generative Sequential Recom- mendation with GPTRec.CoRRabs/2306.11114 (2023)
-
[22]
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. 2024. OmniQuant: Omni- directionally Calibrated Quantization for Large Language Models. InICLR
work page 2024
-
[23]
Mingjie Sun, Zhuang Liu, Anna Bair, and J. Zico Kolter. 2024. A Simple and Effective Pruning Approach for Large Language Models. InICLR
work page 2024
-
[24]
Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Prakash Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. 2022. Transformer Memory as a Differentiable Search Index. In Neural Information Processing Systems
work page 2022
- [25]
- [26]
-
[27]
Wei Wei, Xubin Ren, Jiabin Tang, Qinyong Wang, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, and Chao Huang. 2024. LLMRec: Large Language Models with Graph Augmentation for Recommendation. InWSDM. ACM, 806–815
work page 2024
-
[28]
Sam Wiseman and Alexander M. Rush. 2016. Sequence-to-Sequence Learning as Beam-Search Optimization. InEMNLP. 1296–1306
work page 2016
- [29]
-
[30]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Jiayuan He, Yinghai Lu, and Yu Shi. 2024. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Gener- ative Recommendations. InICML
work page 2024
-
[31]
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Shen Li, Yanli Zhao, Yuchen Hao, Yantao Yao, Ellie Dingqiao Wen, Jongsoo Park, Maxim Naumov, and Wenlin Chen. 2024. Wukong: Towards a Scaling Law for Large-Scale Rec- ommendation. InICML
work page 2024
-
[32]
Chao Zhang, Shiwei Wu, Haoxin Zhang, Tong Xu, Yan Gao, Yao Hu, and En- hong Chen. 2024. NoteLLM: A Retrievable Large Language Model for Note Recommendation. InWWW. ACM, 170–179
work page 2024
-
[33]
Zizhuo Zhang and Bang Wang. 2023. Prompt Learning for News Recommenda- tion. InSIGIR. ACM, 227–237
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.