Recognition: 2 theorem links
· Lean TheoremPhishSigma++: Malicious Email Detection with Typed Entity Relations
Pith reviewed 2026-05-13 01:19 UTC · model grok-4.3
The pith
Phishing detection can rely on stable relations among typed entities to resist text-based evasion attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
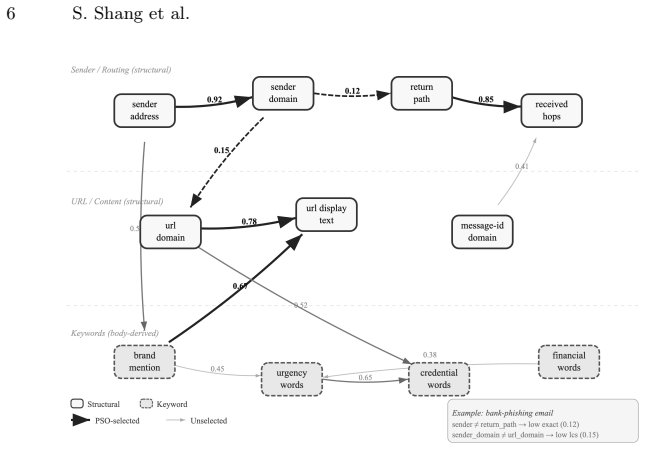
PhishSigma++ extracts forty typed entity classes from RFC822 messages, computes five cross-type relations to build a typed email graph, and uses particle swarm optimization to select a sparse discriminative mask for classification and type-level evidence. On 29,142 messages it reaches 0.9675 F1 on clean data and retains 0.9579 F1 under non-adaptive Good Word padding at rho equal to 0.8, while a token-based Bayesian filter falls to 0.0243 and a DistilBERT checkpoint falls to 0.7284. Thresholded relation scores also recover traditional rule-based field conditions, placing hand-crafted logic and learned masks inside one framework.
What carries the argument
A typed email graph built from forty entity classes and five cross-type relations, with a particle-swarm-optimized sparse mask that drives both classification and evidence.
If this is right
- Accuracy holds against non-adaptive text padding that defeats token-based and transformer models.
- Sparse relation masks supply interpretable type-level evidence for each detection decision.
- Relation thresholds directly recover traditional rule-based field conditions without separate rule sets.
- Data-driven selection of relations covers more invariants than manually written patterns alone.
Where Pith is reading between the lines
- Better entity extraction tools could raise overall accuracy without any change to the graph or mask logic.
- The same relation-invariance idea could be tested on other malicious content such as attachments or code.
- Adaptive attacks aimed at the relations themselves would be the direct next experiment for measuring limits.
- Structured evidence tied to specific entity types could be surfaced to analysts in operational tools.
Load-bearing premise
The forty entity classes and five relations stay stable and useful even after attackers alter visible text, and automated extraction from messages introduces no systematic bias.
What would settle it
Performance measured on a fresh collection of phishing messages where attackers are instructed to change the defined relations, for instance by re-associating links with different senders or attachments, while preserving overall malicious intent.
Figures


read the original abstract
Here is a further shortened version (pure text, no extra formatting, academic style preserved, no content change): Abstract. With the rise of AI-generated content (AIGC), phishing actors now possess richer linguistic capabilities and evasion techniques. Most existing detectors over-rely on mutable textual features, achieving high accuracy on clean data but degrading severely under text-focused adversarial manipulation. This mirrors the lab-to-real performance gap. We investigate invariant signals in phishing emails: even when attackers modify surface text, functional intent constrains relations among typed entities. Threat-actor tradecraft is described via high-level TTPs, but rule-based systems like Sigma express invariants only through manually curated, field-specific patterns, limiting flexibility. We introduce PhishSigma++, an entity-relation-based malicious email detector for RFC822 messages that generalizes Sigma's design. It extracts 40 typed entity classes, computes 5 cross-type relations to build a typed email graph, and uses particle swarm optimization (PSO) to select a sparse discriminative mask, supporting classification and type-level evidence summary. On 29,142 messages, PhishSigma++ achieves 0.9675 F1 on clean data and outperforms text-centric baselines under non-adaptive Good Word padding at \r{ho}=0.8. It maintains 0.9579 F1, while a token-based Bayesian filter collapses to 0.0243 and a DistilBERT phishing checkpoint falls to 0.7284. Compared with traditional Sigma rules, PhishSigma++ offers higher detection, broader relational invariance coverage, and data-driven feature selection. We also show that thresholded typed relation scores encode a useful fragment of Sigma-style field conditions, unifying hand-crafted rule logic and learned relation masks in a single-email framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhishSigma++, an entity-relation detector for RFC822 phishing emails that extracts 40 typed entity classes and 5 cross-type relations to form a typed graph, applies PSO to select a sparse discriminative mask for classification and evidence generation, and claims to unify this with Sigma-style rules. On a 29,142-message dataset it reports 0.9675 F1 on clean data and 0.9579 F1 under non-adaptive Good Word padding at ρ=0.8, substantially outperforming a token-based Bayesian filter (0.0243 F1) and a DistilBERT checkpoint (0.7284 F1).
Significance. If the central performance and robustness claims hold after correcting the evaluation protocol, the work would be significant: it supplies a concrete, relational invariant that survives surface-text adversarial manipulation, offers a data-driven route to Sigma-like rules, and demonstrates a measurable gap between text-centric and structure-centric detectors under Good Word attacks.
major comments (3)
- [Experimental evaluation] Experimental evaluation (the protocol yielding the 0.9675 / 0.9579 F1 numbers): PSO mask selection is performed directly on the evaluation partition; the reported F1 therefore measures performance of a fitted feature set rather than a parameter-free predictor, undermining both the headline robustness result and the claim of unification with hand-crafted Sigma rules.
- [Method / Entity extraction] Entity extraction pipeline (the step that produces the 40 typed classes and 5 relations): no precision, recall, or confusion-matrix results are supplied for the automated extractor on either clean or Good-Word-padded messages. Because the headline invariance claim (0.9579 F1 at ρ=0.8) presupposes stable extraction under adversarial padding, the absence of this validation is load-bearing.
- [Dataset and experimental setup] Dataset description and split: the 29,142-message corpus is introduced without stating labeling procedure, train/test split ratios, or whether any hyper-parameter (including the PSO mask) was tuned on held-out data; these omissions prevent assessment of whether the reported gains are reproducible or merely artifacts of leakage.
minor comments (2)
- [PSO description] The abstract and results section should explicitly list the PSO swarm size, iteration count, and fitness function so that the mask-selection procedure can be reproduced.
- [Results tables/figures] Figure captions and table headers that present F1 scores under varying ρ should also report the corresponding precision and recall to allow readers to judge the operating point.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The three major comments identify genuine weaknesses in the current experimental protocol, validation of the extraction pipeline, and dataset documentation. We address each point below and will incorporate the necessary changes in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental evaluation] Experimental evaluation (the protocol yielding the 0.9675 / 0.9579 F1 numbers): PSO mask selection is performed directly on the evaluation partition; the reported F1 therefore measures performance of a fitted feature set rather than a parameter-free predictor, undermining both the headline robustness result and the claim of unification with hand-crafted Sigma rules.
Authors: We agree that performing PSO mask selection on the evaluation partition constitutes data leakage and prevents the results from representing a parameter-free predictor. This weakens both the robustness numbers and the unification claim with Sigma-style rules. In the revision we will re-run all experiments with PSO mask selection performed exclusively on the training partition using a proper train/validation/test split, report the new F1 scores on the held-out test set, and clarify that the learned mask is a data-driven generalization of Sigma rules rather than a direct hand-crafted equivalent. revision: yes
-
Referee: [Method / Entity extraction] Entity extraction pipeline (the step that produces the 40 typed classes and 5 relations): no precision, recall, or confusion-matrix results are supplied for the automated extractor on either clean or Good-Word-padded messages. Because the headline invariance claim (0.9579 F1 at ρ=0.8) presupposes stable extraction under adversarial padding, the absence of this validation is load-bearing.
Authors: We acknowledge that the absence of quantitative validation for the entity and relation extractor is a significant omission, especially given the invariance claim under adversarial padding. The current manuscript provides no precision, recall, or confusion-matrix results. In the revised version we will add an evaluation section that reports these metrics for the extractor on both clean and Good-Word-padded messages, using a manually labeled subset where necessary to demonstrate stability of the typed graph construction. revision: yes
-
Referee: [Dataset and experimental setup] Dataset description and split: the 29,142-message corpus is introduced without stating labeling procedure, train/test split ratios, or whether any hyper-parameter (including the PSO mask) was tuned on held-out data; these omissions prevent assessment of whether the reported gains are reproducible or merely artifacts of leakage.
Authors: The referee is correct that the dataset section is incomplete. We will expand it to specify the labeling procedure (sources of phishing and benign messages and how ground-truth labels were obtained), the exact train/test split ratios used, and confirm that all hyper-parameter tuning, including PSO, will be performed only on training data. These additions will enable reproducibility assessment and remove the leakage concern. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical ML detector that extracts typed entities and relations from RFC822 messages, applies PSO to select a sparse mask, and measures classification performance on a fixed dataset of 29,142 messages under clean and Good-Word adversarial conditions. No step claims a first-principles derivation or prediction whose output is definitionally identical to its inputs; the F1 numbers are direct experimental measurements of the constructed system. PSO mask selection is an internal optimization step whose result is evaluated on the data, not a circular renaming of a fitted parameter as an independent prediction. The unification with Sigma rules is shown as a post-hoc interpretive observation on the learned masks rather than a load-bearing premise that reduces to self-citation or ansatz. The method is self-contained against external baselines and does not rely on any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
free parameters (1)
- PSO-selected mask
axioms (2)
- domain assumption Typed entity extraction from RFC822 messages is accurate enough that downstream relation scores reflect true functional intent rather than extraction noise.
- domain assumption The 29,142-message corpus is representative of both clean and adversarially manipulated phishing traffic.
invented entities (1)
-
Typed email graph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearextracts 40 typed entity classes, computes 5 cross-type relations... PSO to select a sparse discriminative mask
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearmaintains 0.9579 F1 under non-adaptive Good Word padding at ρ=0.8
Reference graph
Works this paper leans on
-
[1]
Good word attacks on statistical spam filters
Daniel Lowd and Christopher Meek. Good word attacks on statistical spam filters. InCEAS, volume 2005, 2005. 16 S. Shang et al
work page 2005
-
[2]
Sigma rules specification, version 2.1.0, 2025
Sigma HQ. Sigma rules specification, version 2.1.0, 2025. Released 2025-08- 02.https://sigmahq.io/sigma-specification/specification/sigma-rules- specification.html, accessed 2026-05-02
work page 2025
-
[3]
Enabling efficient cyber threat hunting with cyber threat intelligence
Peng Gao, Fei Shao, Xiaoyuan Liu, Xusheng Xiao, Zheng Qin, Fengyuan Xu, Pra- teek Mittal, Sanjeev R Kulkarni, and Dawn Song. Enabling efficient cyber threat hunting with cyber threat intelligence. In2021 IEEE 37th International Confer- ence on Data Engineering (ICDE), pages 193–204. IEEE, 2021
work page 2021
-
[4]
Avisha Das, Shahryar Baki, Ayman El Aassal, Rakesh Verma, and Arthur Dun- bar. Sok: a comprehensive reexamination of phishing research from the security perspective.IEEE Communications Surveys & Tutorials, 22(1):671–708, 2019
work page 2019
-
[5]
High precision detection of business email compromise
Asaf Cidon, Lior Gavish, Itay Bleier, Nadia Korshun, Marco Schweighauser, and Alexey Tsitkin. High precision detection of business email compromise. In28th USENIX Security Symposium (USENIX Security 19), pages 1291–1307, 2019
work page 2019
-
[6]
2023 data breach investigations report
Verizon Business. 2023 data breach investigations report. Technical report, Verizon Business, 2023.https://www.verizon.com/business/resources/reports/2023- data-breach-investigations-report-dbir.pdf, accessed 2026-05-02
work page 2023
-
[7]
Detecting and characterizing lateral phishing at scale
Grant Ho, Asaf Cidon, Lior Gavish, Marco Schweighauser, Vern Paxson, Stefan Savage, Geoffrey M Voelker, and David Wagner. Detecting and characterizing lateral phishing at scale. In28th USENIX security symposium (USENIX security 19), pages 1273–1290, 2019
work page 2019
-
[8]
Reading be- tween the lines: content-agnostic detection of spear-phishing emails
Hugo Gascon, Steffen Ullrich, Benjamin Stritter, and Konrad Rieck. Reading be- tween the lines: content-agnostic detection of spear-phishing emails. InInterna- tional Symposium on Research in Attacks, Intrusions, and Defenses, pages 69–91. Springer, 2018
work page 2018
-
[9]
SpamBayes Project. Spambayes: Bayesian anti-spam classifier, 2011.https:// spambayes.sourceforge.io/, accessed 2026-05-02
work page 2011
-
[10]
Apache spamassassin, 2025.https : / / spamassassin.apache.org/, accessed 2026-05-02
Apache Software Foundation. Apache spamassassin, 2025.https : / / spamassassin.apache.org/, accessed 2026-05-02
work page 2025
-
[11]
Bing Xue, Mengjie Zhang, Will N Browne, and Xin Yao. A survey on evolutionary computation approaches to feature selection.IEEE Transactions on evolutionary computation, 20(4):606–626, 2015
work page 2015
-
[12]
The enron corpus: A new dataset for email clas- sification research
Bryan Klimt and Yiming Yang. The enron corpus: A new dataset for email clas- sification research. InEuropean conference on machine learning, pages 217–226. Springer, 2004
work page 2004
-
[13]
Phishing pot (public phishing .eml repository snapshot), 2024
rf-peixoto. Phishing pot (public phishing .eml repository snapshot), 2024. GitHub repository snapshot; no formal release or tag published.https://github.com/rf- peixoto/phishing_pot. Accessed 2025-01-15
work page 2024
-
[14]
J. Nazario. Phishing corpus, 2006.https://monkey.org/~jose/phishing/. Ac- cessed 2025-01-15
work page 2006
-
[15]
Dos and don’ts of machine learning in computer security
Daniel Arp, Erwin Quiring, Feargus Pendlebury, Alexander Warnecke, Fabio Pier- azzi, Christian Wressnegger, Lorenzo Cavallaro, and Konrad Rieck. Dos and don’ts of machine learning in computer security. In31st USENIX Security Symposium (USENIX Security 22), pages 3971–3988, 2022
work page 2022
- [16]
-
[17]
E-phishgen: Unlocking novel research in phishing email de- tection
Luca Pajola, Eugenio Caripoti, Stefan Banzer, Simeone Pizzi, Mauro Conti, and Giovanni Apruzzese. E-phishgen: Unlocking novel research in phishing email de- tection. InProceedings of the 18th ACM Workshop on Artificial Intelligence and Security, pages 64–76, 2025
work page 2025
-
[18]
MITRE ATT&CK framework, v14, 2023.https://attack
MITRE Corporation. MITRE ATT&CK framework, v14, 2023.https://attack. mitre.org/versions/v14/, accessed 2026-05-02. PhishSigma++: Malicious Email Detection 17
work page 2023
-
[19]
In28th USENIX security symposium (USENIX Security 19), pages 729–746, 2019
Feargus Pendlebury, Fabio Pierazzi, Roberto Jordaney, Johannes Kinder, and Lorenzo Cavallaro.{TESSERACT}: Eliminating experimental bias in malware classificationacrossspaceandtime. In28th USENIX security symposium (USENIX Security 19), pages 729–746, 2019
work page 2019
-
[20]
Ozgur Koray Sahingoz, Ebubekir Buber, Onder Demir, and Banu Diri. Machine learning based phishing detection from urls.Expert Systems with Applications, 117:345–357, 2019
work page 2019
-
[21]
Panagiotis Bountakas and Christos Xenakis. Helphed: Hybrid ensemble learn- ing phishing email detection.Journal of network and computer applications, 210:103545, 2023
work page 2023
-
[22]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[23]
Doubly dangerous: Evad- ing phishing reporting systems by leveraging email tracking techniques
Anish Chand, Nick Nikiforakis, and Phani Vadrevu. Doubly dangerous: Evad- ing phishing reporting systems by leveraging email tracking techniques. In34th USENIX Security Symposium (USENIX Security 25), pages 3181–3200, 2025
work page 2025
-
[24]
In 34th USENIX Security Symposium (USENIX Security 25), pages 1435–1454, 2025
Daniele Lain, Yoshimichi Nakatsuka, Kari Kostiainen, Gene Tsudik, and Srdjan Capkun.{URL}inspection tasks: Helping users detect phishing links in emails. In 34th USENIX Security Symposium (USENIX Security 25), pages 1435–1454, 2025
work page 2025
-
[25]
Hades attack: Under- standing and evaluating manipulation risks of email blocklists
Ruixuan Li, Chaoyi Lu, Baojun Liu, Yunyi Zhang, Geng Hong, Haixin Duan, Yanzhong Lin, Qingfeng Pan, Min Yang, and Jun Shao. Hades attack: Under- standing and evaluating manipulation risks of email blocklists. InNDSS, 2025
work page 2025
-
[26]
Nilesh Dalvi, Pedro Domingos, Mausam, Sumit Sanghai, and Deepak Verma. Ad- versarial classification. InProceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining, pages 99–108, 2004
work page 2004
-
[27]
TextBugger: Generating Adversarial Text Against Real-world Applications
Jinfeng Li, Shouling Ji, Tianyu Du, Bo Li, and Ting Wang. Textbugger: Generating adversarial text against real-world applications.arXiv preprint arXiv:1812.05271, 2018
work page Pith review arXiv 2018
-
[28]
Evasionattacksagainstmachinelearning at test time
Battista Biggio, Igino Corona, Davide Maiorca, Blaine Nelson, Nedim Šrndić, Pavel Laskov,GiorgioGiacinto,andFabioRoli. Evasionattacksagainstmachinelearning at test time. InJoint European conference on machine learning and knowledge discovery in databases, pages 387–402. Springer, 2013
work page 2013
-
[29]
A different cup of{TI}? the added value of commercial threat intelligence
Xander Bouwman, Harm Griffioen, Jelle Egbers, Christian Doerr, Bram Klievink, and Michel Van Eeten. A different cup of{TI}? the added value of commercial threat intelligence. In29th USENIX security symposium (USENIX security 20), pages 433–450, 2020
work page 2020
-
[30]
Unicorn: Runtime provenance-based detector for advanced persistent threats
Xueyuan Han, Thomas Pasquier, Adam Bates, James Mickens, and Margo Seltzer. Unicorn: Runtime provenance-based detector for advanced persistent threats. arXiv preprint arXiv:2001.01525, 2020
-
[31]
Holmes: real-time apt detection through correlation of sus- picious information flows
Sadegh M Milajerdi, Rigel Gjomemo, Birhanu Eshete, Ramachandran Sekar, and VN Venkatakrishnan. Holmes: real-time apt detection through correlation of sus- picious information flows. In2019 IEEE symposium on security and privacy (SP), pages 1137–1152. IEEE, 2019
work page 2019
-
[32]
Nodoze: Combatting threat alert fatigue with auto- mated provenance triage
Wajih Ul Hassan, Shengjian Guo, Ding Li, Zhengzhang Chen, Kangkook Jee, Zhichun Li, and Adam Bates. Nodoze: Combatting threat alert fatigue with auto- mated provenance triage. Innetwork and distributed systems security symposium, 2019. 18 S. Shang et al. A Supplementary Tables Table A1: Entity extractor groups. Extractor Group Entity Types Count Sender id...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.