Recognition: 2 theorem links
· Lean TheoremCan LLM Agents Respond to Disasters? Benchmarking Heterogeneous Geospatial Reasoning in Emergency Operations
Pith reviewed 2026-05-13 01:20 UTC · model grok-4.3
The pith
LLM agents for disaster response are doubly limited by tool selection failures and rapid performance drops on longer compositional pipelines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
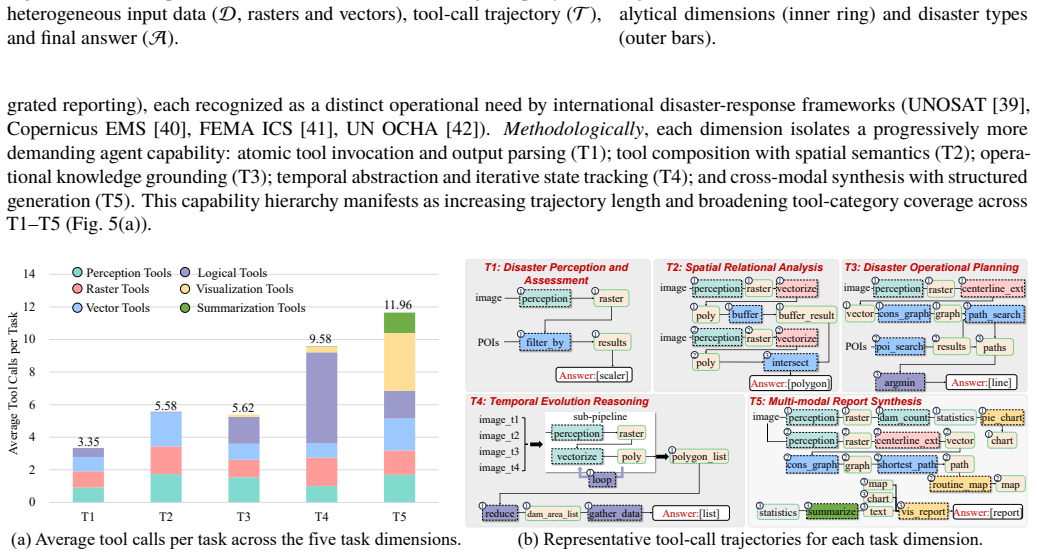
The DORA benchmark demonstrates that current LLM agents cannot reliably execute end-to-end disaster-response pipelines: they exhibit domain-specific grounding errors in damage semantics and sensor modalities, remain bottlenecked by both tool selection and argument generation even when given gold tool sequences, and suffer widening gaps relative to expert trajectories as pipeline length increases from short to long sequences.
What carries the argument
The DORA benchmark, a collection of 515 tasks and 3,500 expert-verified gold trajectories that require agents to compose calls from a heterogeneous 108-tool geospatial library spanning multi-temporal imagery and vector layers.
Load-bearing premise
That the 515 expert-authored tasks and 3,500 gold trajectories accurately capture the full operational disaster-response pipeline without selection bias or oversimplification of real-world constraints.
What would settle it
Running the same 13 models on a fresh collection of live disaster events using the identical 108-tool library and measuring whether the observed tool-selection and length-dependent gaps remain or shrink.
Figures







read the original abstract
Operational disaster response goes beyond damage assessment, requiring responders to integrate multi-sensor signals, reason over road networks, populations and key facilities, plan evacuations, and produce actionable reports. However, prior work largely isolates remote-sensing perception or evaluates generic tool use, leaving the end-to-end workflows of emergency operations underexplored. In this paper, we introduce Disaster Operational Response Agent benchmark (DORA), the first agentic benchmark for end-to-end disaster response: 515 expert-authored tasks across 45 real-world disaster events spanning 10 types, paired with expert-verified, replayable gold trajectories totaling 3,500 tool-call steps. Tasks span five dimensions that cover the operational disaster-response pipeline: disaster perception, spatial relational analysis, rescue and evacuation planning, temporal evolution reasoning, and multi-modal report synthesis. Agents compose calls from a 108-tool MCP library over heterogeneous geospatial data: optical, SAR, and multi-spectral imagery across single-, bi-, and multi-temporal sequences (0.015-10m GSD), complemented by elevation and social vector layers. We comprehensively evaluate 13 frontier LLMs on our benchmark, revealing three persistent challenges: 1) disaster-domain grounding exposes unique failure modes (damage-semantic grounding, sensor-modality mismatch, and disaster-pipeline composition); 2) agents are doubly bottlenecked by tool selection and argument grounding, where gold tool-order hints improve accuracy by only 1.08-4.40%, and alternative scaffolds yield at most a 3.24% gain; 3) compositional fragility scales with trajectory length, the agent-to-gold gap widening from 7% to 56% on long pipelines. DORA establishes a rigorous testbed for operationally reliable disaster-response agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DORA, the first agentic benchmark for end-to-end disaster response. It comprises 515 expert-authored tasks spanning 45 real-world events across 10 disaster types, paired with 3,500 expert-verified replayable gold trajectories that invoke a 108-tool library over heterogeneous geospatial data (optical/SAR/multi-spectral imagery, elevation, and social vectors). The work evaluates 13 frontier LLMs across five operational dimensions (perception, spatial analysis, rescue planning, temporal reasoning, report synthesis) and reports three challenges: domain-specific grounding failures, double bottlenecks in tool selection and argument grounding (with gold-order hints yielding only 1.08-4.40% gains and scaffolds at most 3.24%), and compositional fragility that widens the agent-to-gold gap from 7% to 56% on longer trajectories.
Significance. If the tasks and trajectories are representative, DORA provides a valuable, large-scale testbed that integrates multi-modal perception with planning and reporting in high-stakes scenarios, going beyond prior isolated remote-sensing or generic tool-use evaluations. The explicit provision of replayable gold trajectories, real disaster events, and dimensionally structured tasks is a strength that enables reproducible diagnosis of failure modes such as sensor-modality mismatch and length-dependent composition errors. These empirical patterns could usefully inform agent design for operational reliability.
major comments (2)
- [§4] §4 (Benchmark Construction): The claim that the 515 tasks and 3,500 trajectories 'faithfully sample the end-to-end disaster-response workflow' is load-bearing for all headline results on bottlenecks and fragility, yet the section supplies no inter-annotator agreement, coverage statistics across the 10 disaster types, or validation against after-action reports. Without these, it is impossible to assess selection bias toward well-structured, fully observable scenarios.
- [§5] §5 (Evaluation and Results): The reported tool-selection and argument-grounding bottlenecks rest on accuracy metrics whose exact definitions (e.g., partial credit for argument grounding, handling of multi-step trajectory replay) are not fully specified; this directly affects interpretation of the 1.08-4.40% hint gains and the 7%-to-56% gap widening.
minor comments (2)
- [Tables/Figures] Table 1 and Figure 2: axis labels and legend entries for the five task dimensions could be expanded with one-sentence operational definitions to improve readability for readers outside geospatial AI.
- [§2] §2 (Related Work): The comparison to prior benchmarks would benefit from a brief quantitative contrast (e.g., number of tools or trajectory length) rather than qualitative description alone.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive assessment of DORA's potential value as a testbed. We address each major comment below with point-by-point responses and have revised the manuscript where feasible to enhance transparency and rigor.
read point-by-point responses
-
Referee: [§4] §4 (Benchmark Construction): The claim that the 515 tasks and 3,500 trajectories 'faithfully sample the end-to-end disaster-response workflow' is load-bearing for all headline results on bottlenecks and fragility, yet the section supplies no inter-annotator agreement, coverage statistics across the 10 disaster types, or validation against after-action reports. Without these, it is impossible to assess selection bias toward well-structured, fully observable scenarios.
Authors: We thank the referee for highlighting this important aspect of benchmark validity. The 515 tasks were authored iteratively by a team of domain experts with direct experience in emergency operations, drawing from the 45 real-world events, and each gold trajectory was verified for operational realism. In the revised manuscript, we have added explicit coverage statistics in §4 (new Table 2) detailing task and event distribution across all 10 disaster types, along with a description of the expert review process. We have also expanded the limitations discussion to address potential selection bias toward observable scenarios. However, because task development was collaborative and consensus-driven rather than independent parallel annotations, traditional inter-annotator agreement metrics were not collected; we have noted this methodological choice explicitly. Direct quantitative mapping to after-action reports was not performed due to variability in public report formats, but we have clarified how real-event grounding and replayable trajectories support workflow fidelity. These additions allow better assessment of representativeness while preserving the benchmark's contributions. revision: partial
-
Referee: [§5] §5 (Evaluation and Results): The reported tool-selection and argument-grounding bottlenecks rest on accuracy metrics whose exact definitions (e.g., partial credit for argument grounding, handling of multi-step trajectory replay) are not fully specified; this directly affects interpretation of the 1.08-4.40% hint gains and the 7%-to-56% gap widening.
Authors: We appreciate the referee's call for greater precision in metric definitions, which we agree is essential for interpreting the reported bottlenecks. In the revised §5, we have added a dedicated subsection with formal definitions: tool selection accuracy is the exact-match rate to the gold tool at each step; argument grounding uses per-argument partial credit (1.0 for exact match, 0.5 for correct type with value mismatch, 0 otherwise) averaged across arguments; multi-step trajectories are evaluated via sequential replay in the environment, requiring full sequence fidelity with only floating-point tolerance for geospatial parameters. These clarifications confirm that the small hint gains reflect fundamental selection and grounding difficulties rather than evaluation artifacts, and the length-dependent gap widening (7% to 56%) arises from compounding compositional errors. We have also added pseudocode and worked examples in a new appendix to ensure full reproducibility and transparent interpretation of all results. revision: yes
Circularity Check
No circularity: empirical benchmark construction and evaluation
full rationale
The paper constructs an empirical benchmark (DORA) consisting of 515 expert-authored tasks and 3,500 gold trajectories across five operational dimensions, then evaluates 13 LLMs on tool-use accuracy, compositional fragility, and scaffold sensitivity. No mathematical derivations, fitted parameters, or self-referential equations appear in the abstract or described methodology; results are direct measurements against the fixed gold trajectories rather than quantities defined by the paper's own outputs. Self-citations, if present, are not load-bearing for any central claim, and the work contains no uniqueness theorems, ansatzes, or renamings of known results that reduce to prior author work by construction. The evaluation pipeline is externally falsifiable via the released tasks and trajectories.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert-authored tasks and gold trajectories faithfully represent operational disaster response requirements
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear515 expert-authored tasks... 108-tool MCP library... Tool-Any-Order, Tool-In-Order, Tool-Exact-Match, Parameter Accuracy... disaster-domain grounding exposes unique failure modes
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearcompositional fragility scales with trajectory length... agent-to-gold gap widening from 7% to 56%
Reference graph
Works this paper leans on
-
[1]
Implementing equitable wildfire response plans,
J. Xu, D. J. Nair, and S. T. Waller, “Implementing equitable wildfire response plans,”Science, vol. 388, no. 6743, pp. 158– 159, 2025
work page 2025
-
[2]
Effects of a natural disaster on mortality risks over the longer term,
E. Frankenberg, C. Sumantri, and D. Thomas, “Effects of a natural disaster on mortality risks over the longer term,”Nature sustainability, vol. 3, no. 8, pp. 614–619, 2020. 10
work page 2020
-
[3]
Executable code actions elicit better llm agents,
X. Wang, Y. Chen, L. Yuan, Y. Zhang, Y. Li, H. Peng, and H. Ji, “Executable code actions elicit better llm agents,” in Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[4]
Swe-agent: Agent-computer interfaces enable automated software engineering,
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering,”Advances in Neural Information Processing Systems, vol. 37, pp. 50528–50652, 2024
work page 2024
-
[5]
Agentbench: Evaluating LLMs as agents,
X. Liu, H. Yu, H. Zhang, Y. Xu, X. Lei, H. Lai, Y. Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y. Su, H. Sun, M. Huang, Y. Dong, and J. Tang, “Agentbench: Evaluating LLMs as agents,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[6]
Earth-agent: Unlocking the full landscape of earth observation with agents,
P. Feng, Z. Lv, J. Ye, X. Wang, X. Huo, J. Yu, W. Xu, W. Zhang, L. BAI, C. He, and W. Li, “Earth-agent: Unlocking the full landscape of earth observation with agents,” inThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[7]
Openearthagent: Aunifiedframeworkfortool-augmentedgeospatialagents,
A. Shabbir, M. U. Sheikh, M. A. Munir, H. Debary, M. Fiaz, M. Z. Zaheer, P. Fraccaro, F. S. Khan, M. H. Khan, X. X. Zhu,etal.,“Openearthagent: Aunifiedframeworkfortool-augmentedgeospatialagents,”arXivpreprintarXiv:2602.17665, 2026
-
[8]
Openearth-agent: From tool calling to tool creation for open-environment earth observation,
S. Zhao, F. Liu, X. Zhang, H. Chen, X. Gu, Z. Jiang, F. Ling, B. Fei, W. Zhang, J. Wang,et al., “Openearth-agent: From tool calling to tool creation for open-environment earth observation,”arXiv preprint arXiv:2603.22148, 2026
-
[9]
React: Synergizingreasoningandactinginlanguage models,
S.Yao,J.Zhao,D.Yu,N.Du,I.Shafran,K.Narasimhan,andY.Cao,“React: Synergizingreasoningandactinginlanguage models,” inInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[10]
Expel: Llm agents are experiential learners,
A. Zhao, D. Huang, Q. Xu, M. Lin, Y.-J. Liu, and G. Huang, “Expel: Llm agents are experiential learners,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 19632–19642, 2024
work page 2024
-
[11]
Y. Fu, D.-K. Kim, J. Kim, S. Sohn, L. Logeswaran, K. Bae, and H. Lee, “Autoguide: Automated generation and selection of context-aware guidelines for large language model agents,”Advances in Neural Information Processing Systems, vol. 37, pp. 119919–119948, 2024
work page 2024
-
[12]
S.Ouyang,J.Yan,I.Hsu,Y.Chen,K.Jiang,Z.Wang,R.Han,L.T.Le,S.Daruki,X.Tang,etal.,“Reasoningbank: Scaling agent self-evolving with reasoning memory,”arXiv preprint arXiv:2509.25140, 2025
-
[13]
Webarena: A realistic web environment for building autonomous agents,
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y. Bisk, D. Fried, U. Alon, and G. Neubig, “Webarena: A realistic web environment for building autonomous agents,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[14]
Osworld: Benchmarkingmul- timodal agents for open-ended tasks in real computer environments,
T.Xie,D.Zhang,J.Chen,X.Li,S.Zhao,R.Cao,T.J.Hua,Z.Cheng,D.Shin,F.Lei,etal.,“Osworld: Benchmarkingmul- timodal agents for open-ended tasks in real computer environments,”Advances in Neural Information Processing Systems, vol. 37, pp. 52040–52094, 2024
work page 2024
-
[15]
SWE-bench multimodal: Do AI systems generalize to visual software domains?,
J. Yang, C. E. Jimenez, A. L. Zhang, K. Lieret, J. Yang, X. Wu, O. Press, N. Muennighoff, G. Synnaeve, K. R. Narasimhan, D. Yang, S. Wang, and O. Press, “SWE-bench multimodal: Do AI systems generalize to visual software domains?,” inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[16]
Octobench: Benchmarking scaffold-aware instruction following in repository-grounded agentic coding,
D. Ding, S. Liu, E. Yang, J. Lin, Z. Chen, S. Dou, H. Guo, W. Cheng, P. Zhao, C. Xiao,et al., “Octobench: Benchmarking scaffold-aware instruction following in repository-grounded agentic coding,”arXiv preprint arXiv:2601.10343, 2026
-
[17]
Featurebench: Benchmarking agentic coding for complex feature development,
Q.Zhou,J.Zhang,H.Wang,R.Hao,J.Wang,M.Han,Y.Yang,S.Wu,F.Pan,L.Fan,D.Tu,andZ.Zhang,“Featurebench: Benchmarking agentic coding for complex feature development,” inThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[18]
GAIA: a benchmark for general AI assistants,
G. Mialon, C. Fourrier, T. Wolf, Y. LeCun, and T. Scialom, “GAIA: a benchmark for general AI assistants,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[19]
Gta: a benchmark for general tool agents,
J. Wang, Z. Ma, Y. Li, S. Zhang, C. Chen, K. Chen, and X. Le, “Gta: a benchmark for general tool agents,”Advances in Neural Information Processing Systems, vol. 37, pp. 75749–75790, 2024. 11
work page 2024
-
[20]
m & m’s: A benchmark to evaluate tool-use for m ulti-step m ulti-modal tasks,
Z. Ma, W. Huang, J. Zhang, T. Gupta, and R. Krishna, “m & m’s: A benchmark to evaluate tool-use for m ulti-step m ulti-modal tasks,” inEuropean Conference on Computer Vision, pp. 18–34, Springer, 2024
work page 2024
-
[21]
Geollm-engine: Arealisticenvironmentforbuildinggeospatialcopilots,
S.Singh,M.Fore,andD.Stamoulis,“Geollm-engine: Arealisticenvironmentforbuildinggeospatialcopilots,”inProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 585–594, 2024
work page 2024
-
[22]
ThinkGeo: Evaluating tool-augmented agents for remote sensing tasks,
A. Shabbir, M. A. Munir, A. Dudhane, M. U. Sheikh, M. H. Khan, P. Fraccaro, J. B. Moreno, F. S. Khan, and S. Khan, “Thinkgeo: Evaluating tool-augmented agents for remote sensing tasks,”arXiv preprint arXiv:2505.23752, 2025
-
[23]
Towards llm agents for earth observation,
C. H. Kao, W. Zhao, S. Revankar, S. Speas, S. Bhagat, R. Datta, C. P. Phoo, U. Mall, C. Vondrick, K. Bala,et al., “Towards llm agents for earth observation,”arXiv preprint arXiv:2504.12110, 2025
-
[24]
RS-Agent: Automating remote sensing tasks through intelligent agent,
W.Xu, Z.Yu, B.Mu, Z.Wei, Y.Zhang, G.Li, J.Wang, andM.Peng, “Rs-agent: Automatingremotesensingtasksthrough intelligent agent,”arXiv preprint arXiv:2406.07089, 2024
-
[25]
Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,
C. Liu, K. Chen, H. Zhang, Z. Qi, Z. Zou, and Z. Shi, “Change-agent: Toward interactive comprehensive remote sensing change interpretation and analysis,”IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024
work page 2024
-
[26]
xbd: A dataset for assessing building damage from satellite imagery,
R. Gupta, R. Hosfelt, S. Sajeev, N. Patel, B. Goodman, J. Doshi, E. Heim, H. Choset, and M. Gaston, “xbd: A dataset for assessing building damage from satellite imagery,”arXiv preprint arXiv:1911.09296, 2019
-
[27]
Disasterm3: Aremote sensing vision-language dataset for disaster damage assessment and response,
J.Wang,W.Xuan,H.Qi,Z.Liu,K.Liu,Y.Wu,H.Chen,J.Song,J.Xia,Z.Zheng,andN.Yokoya,“Disasterm3: Aremote sensing vision-language dataset for disaster damage assessment and response,” inProceedings of the Neural Information Processing Systems, 2025
work page 2025
-
[28]
H. Chen, J. Song, O. Dietrich, C. Broni-Bediako, W. Xuan, J. Wang, X. Shao, Y. Wei, J. Xia, C. Lan,et al., “Bright: A globally distributed multimodal building damage assessment dataset with very-high-resolution for all-weather disaster response,”Earth System Science Data, vol. 17, no. 11, pp. 6217–6253, 2025
work page 2025
-
[29]
National agriculture imagery program (NAIP)
USDA Farm Service Agency, “National agriculture imagery program (NAIP).”https://naip-usdaonline.hub. arcgis.com/, 2022. Accessed: 2025
work page 2022
-
[30]
Maxar Technologies, “Maxar open data program.”https://www.maxar.com/open-data, 2024. Accessed: 2025
work page 2024
-
[31]
O. Ghorbanzadeh, Y. Xu, H. Zhao, J. Wang, Y. Zhong, D. Zhao, Q. Zang, S. Wang, F. Zhang, Y. Shi,et al., “The outcome of the 2022 landslide4sense competition: Advanced landslide detection from multisource satellite imagery,”IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 15, pp. 9927–9942, 2022
work page 2022
-
[32]
X. Zhang, W. Yu, M.-O. Pun, and W. Shi, “Cross-domain landslide mapping from large-scale remote sensing images us- ing prototype-guided domain-aware progressive representation learning,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 197, pp. 1–17, 2023
work page 2023
-
[33]
M. Rahnemoonfar, T. Chowdhury, and R. Murphy, “Rescuenet: A high resolution uav semantic segmentation dataset for natural disaster damage assessment,”Scientific data, vol. 10, no. 1, p. 913, 2023
work page 2023
-
[34]
T. Manzini, P. Perali, R. Karnik, and R. Murphy, “Crasar-u-droids: A large scale benchmark dataset for building alignment and damage assessment in georectified suas imagery,”arXiv preprint arXiv:2407.17673, 2024
-
[35]
Openearthmap: Abenchmarkdatasetforglobalhigh-resolutionland cover mapping,
J.Xia,N.Yokoya,B.Adriano,andC.Broni-Bediako,“Openearthmap: Abenchmarkdatasetforglobalhigh-resolutionland cover mapping,” inProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 6254–6264, 2023
work page 2023
-
[36]
Land surface temperature and climate data
Japan Meteorological Agency, “Land surface temperature and climate data.”https://www.jma.go.jp/jma/ indexe.html, 2025. Accessed: 2025
work page 2025
-
[37]
Planet dump retrieved from https://planet.osm.org
OpenStreetMap contributors, “Planet dump retrieved from https://planet.osm.org.”https://www.openstreetmap. org, 2025. Data licensed under ODbL
work page 2025
-
[38]
M.Roser,H.Ritchie,E.Ortiz-Ospina,L.Rodés-Guirao,J.Hasell,B.Macdonald,D.Beltekian,E.Mathieu,andC.Giattino, “Our world in data.”https://ourworldindata.org, 2025. Licensed under CC BY. Accessed: 2025. 12
work page 2025
-
[39]
UNOSAT – United Nations Satellite Centre emergency mapping service
United Nations Institute for Training and Research (UNITAR), “UNOSAT – United Nations Satellite Centre emergency mapping service.”https://unosat.org/services/, 2024. Accessed: 2026-04-06
work page 2024
-
[40]
Manual for CEMS-rapid mapping products,
I. Joubert-Boitat, A. Wania, and S. Dalmasso, “Manual for CEMS-rapid mapping products,” Tech. Rep. JRC121741, Euro- pean Commission, Joint Research Centre (JRC), 2020
work page 2020
-
[41]
National urban search and rescue (US&R) response system: Rescue field operations guide,
Federal Emergency Management Agency (FEMA), “National urban search and rescue (US&R) response system: Rescue field operations guide,” Tech. Rep. US&R-23-FG, U.S. Department of Homeland Security, 2008
work page 2008
-
[42]
UnitedNationsOfficefortheCoordinationofHumanitarianAffairs(OCHA),“ThisisOCHA.”https://www.unocha. org/ocha, 2024. Established by UN General Assembly Resolution 46/182 (1991)
work page 2024
-
[43]
Hazusinventorytechnicalmanual,
FederalEmergencyManagementAgency,“Hazusinventorytechnicalmanual,”Tech.Rep.Hazus6.1,DepartmentofHome- land Security, FEMA, Washington, D.C., 2024
work page 2024
-
[44]
The Multi-Temporal Urban Development SpaceNet Dataset,
A. Van Etten, D. Hogan, J. M. Manso, J. Shermeyer, N. Weir, and R. Lewis, “The Multi-Temporal Urban Development SpaceNet Dataset,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6398–6407, 2021
work page 2021
-
[45]
Toolllm: Facilitatinglargelanguage models to master 16000+ real-world apis,
Y.Qin,S.Liang,Y.Ye,K.Zhu,L.Yan,Y.Lu,Y.Lin,X.Cong,X.Tang,B.Qian,etal.,“Toolllm: Facilitatinglargelanguage models to master 16000+ real-world apis,” inThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[46]
OpenAI, “GPT-5.4 thinking system card,” tech. rep., OpenAI, March 2026
work page 2026
-
[47]
Claude sonnet 4.6 system card,
Anthropic, “Claude sonnet 4.6 system card,” tech. rep., Anthropic, February 2026
work page 2026
-
[48]
Introducing Gemini 3 flash: Benchmarks, global availability
Google DeepMind, “Introducing Gemini 3 flash: Benchmarks, global availability.”https://blog.google/ products/gemini/gemini-3-flash/, 2026
work page 2026
- [49]
-
[50]
Qwen3.5: Towards native multimodal agents
Qwen Team, “Qwen3.5: Towards native multimodal agents.”https://qwen.ai/blog?id=qwen3.5, 2026
work page 2026
-
[51]
LLM-Core, Xiaomi, “MiMo-V2-Pro.”https://mimo.xiaomi.com/mimo-v2-pro, 2026. API model card, re- leased March 18, 2026
work page 2026
-
[52]
Step 3.5 Flash: Fast enough to think, reliable enough to act
StepFun, “Step 3.5 Flash: Fast enough to think, reliable enough to act.”https://static.stepfun.com/blog/ step-3.5-flash/, 2025. Technical blog and model card
work page 2025
-
[53]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI, “DeepSeek-V3.2: Pushing the frontier of open large language models,”arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Gemma 4: Byte for byte, the most capable open models,
Gemma Team and Google DeepMind, “Gemma 4: Byte for byte, the most capable open models,” tech. rep., Google Deep- Mind, April 2026
work page 2026
-
[55]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI, “gpt-oss-120b & gpt-oss-20b model card,”arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
MiniMax-M2.7: A self-evolving agent model,
MiniMax AI, “MiniMax-M2.7: A self-evolving agent model,” tech. rep., MiniMax AI, March 2026
work page 2026
- [57]
-
[58]
G. He, G. Demartini, and U. Gadiraju, “Plan-then-execute: An empirical study of user trust and team performance when usingllmagentsasadailyassistant,”inProceedingsofthe2025CHIConferenceonHumanFactorsinComputingSystems, pp. 1–22, 2025
work page 2025
-
[59]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,”Advances in neural information processing systems, vol. 36, pp. 8634–8652, 2023
work page 2023
-
[60]
B. Xu, Z. Peng, B. Lei, S. Mukherjee, Y. Liu, and D. Xu, “Rewoo: Decoupling reasoning from observations for efficient augmented language models,”arXiv preprint arXiv:2305.18323, 2023. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.