Recognition: 1 theorem link
· Lean TheoremLearning U-Statistics with Active Inference
Pith reviewed 2026-05-13 01:12 UTC · model grok-4.3
The pith
Active sampling guided by machine learning predictions reduces variance in U-statistic estimates while preserving valid inference under a fixed label budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We develop an active inference framework for U-statistics that selectively queries informative labels to improve estimation efficiency under a fixed labeling budget, while preserving valid statistical inference. Our approach is built on the augmented inverse probability weighting U-statistic, which is designed to incorporate the sampling rule and machine learning predictions. We characterize the optimal sampling rule that minimizes its variance and design practical sampling strategies. We further extend the framework to U-statistic-based empirical risk minimization.
What carries the argument
The augmented inverse probability weighting U-statistic, which reweights the standard U-statistic by the inverse probability of selection and adds a correction term based on machine learning predictions to account for active sampling.
If this is right
- U-statistic estimators achieve strictly lower asymptotic variance than passive uniform sampling for any fixed labeling budget when the optimal rule is used.
- The estimator remains asymptotically normal, so standard confidence intervals and tests stay valid.
- The same active framework applies directly to U-statistic empirical risk minimization, improving model training efficiency under label constraints.
- Practical sampling strategies derived from the optimal rule deliver measurable efficiency gains on real data while maintaining coverage.
Where Pith is reading between the lines
- If machine learning predictors continue to improve, the efficiency advantage of this active framework would grow without changing the core procedure.
- The same weighting idea could be adapted to other semiparametric estimators that depend on pairwise or higher-order kernels.
- Sequential or online versions of the sampling rule might further reduce the total labels needed in streaming settings.
Load-bearing premise
The machine learning predictions used to guide sampling are accurate enough not to introduce bias, and the augmented IPW U-statistic correctly incorporates the active sampling rule without invalidating the inference properties.
What would settle it
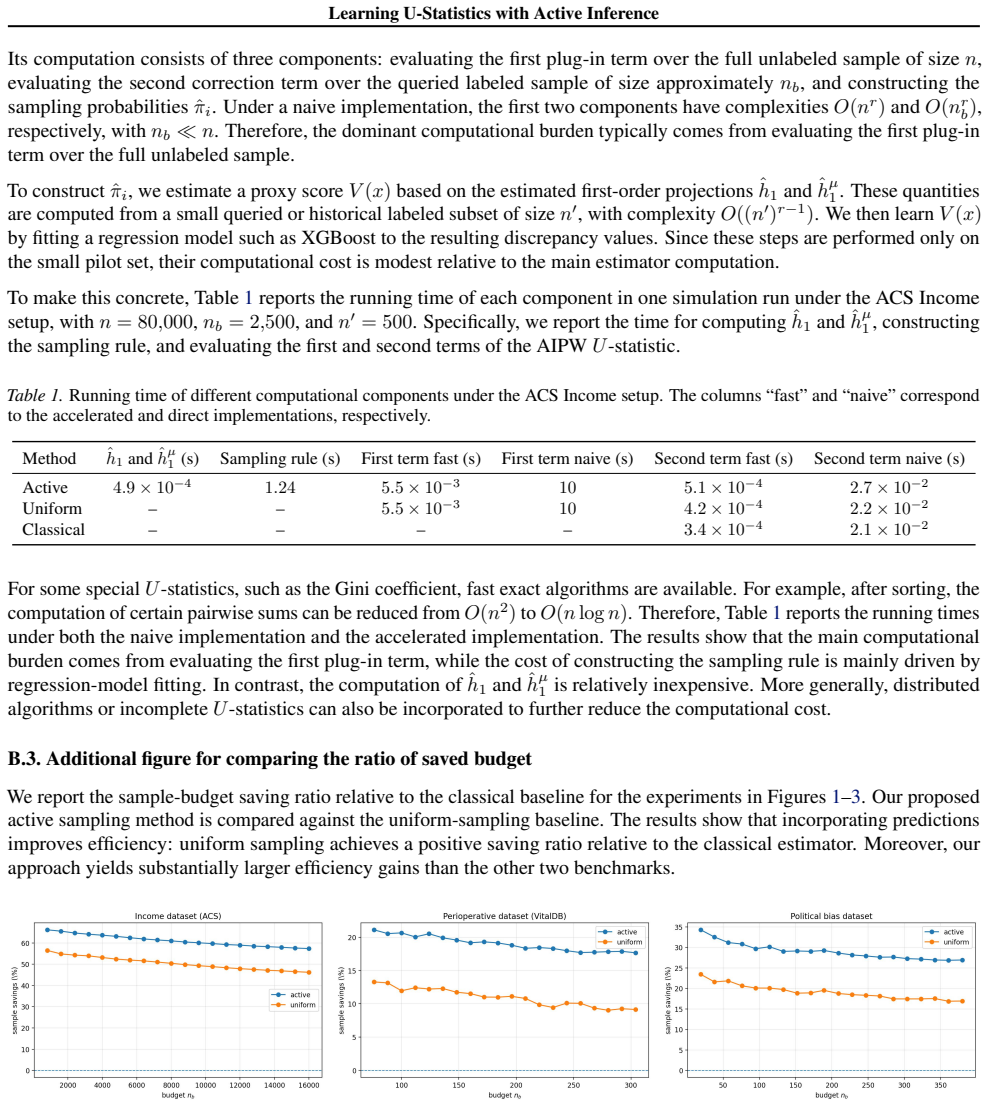
If experiments using deliberately inaccurate machine learning predictions show that variance reduction disappears or confidence-interval coverage falls below the nominal level, the practical value of the framework would be refuted.
Figures
read the original abstract
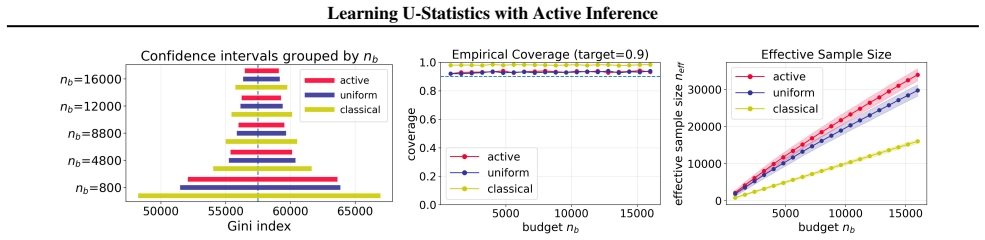
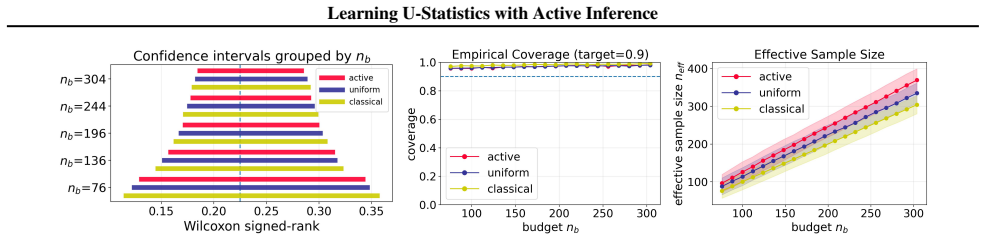
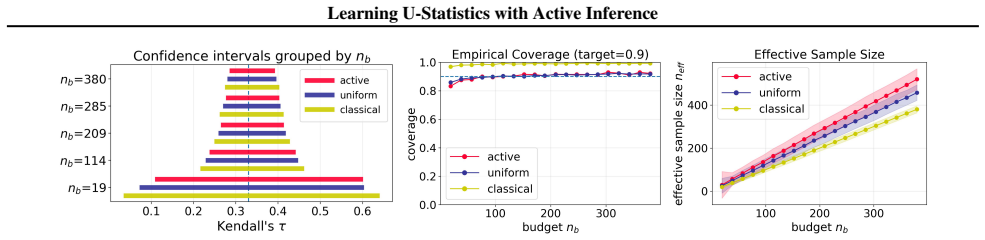
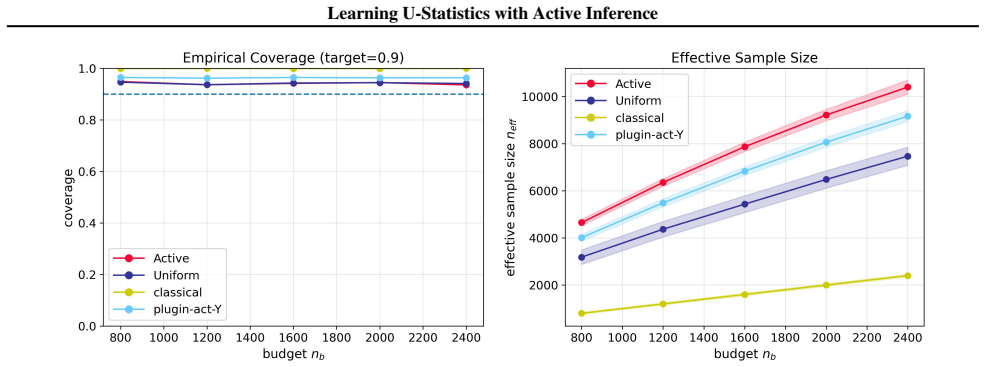
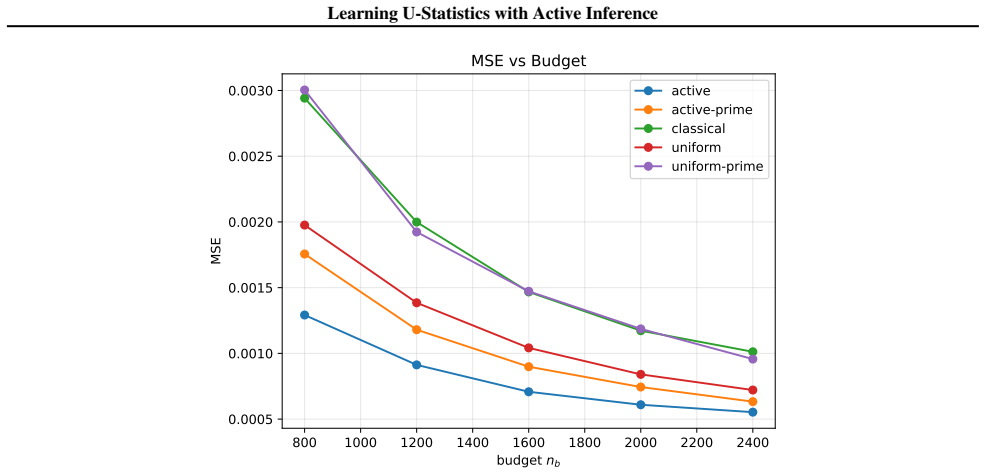
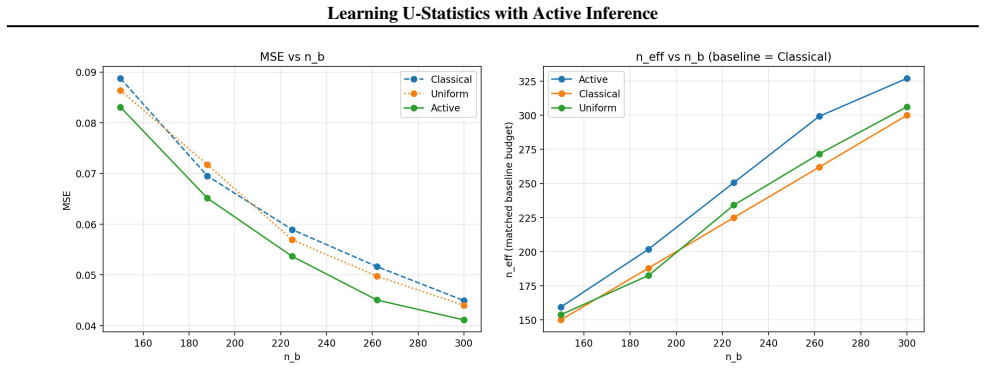
$U$-statistics play a central role in statistical inference. In many modern applications, however, acquiring the labels required for $U$-statistics is costly. Motivated by recent advances in active inference, we develop an active inference framework for $U$-statistics that selectively queries informative labels to improve estimation efficiency under a fixed labeling budget, while preserving valid statistical inference. Our approach is built on the augmented inverse probability weighting $U$-statistic, which is designed to incorporate the sampling rule and machine learning predictions. We characterize the optimal sampling rule that minimizes its variance and design practical sampling strategies. We further extend the framework to $U$-statistic-based empirical risk minimization. Experiments on real datasets demonstrate substantial gains in estimation efficiency over baseline methods, while maintaining target coverage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops an active inference framework for U-statistics that selectively queries labels using machine learning predictions to improve estimation efficiency under a fixed labeling budget. It is built on an augmented inverse probability weighting U-statistic designed to incorporate the sampling rule and predictions while preserving valid statistical inference, characterizes the optimal sampling rule that minimizes variance, extends the approach to U-statistic-based empirical risk minimization, and reports experimental gains in efficiency with maintained coverage on real datasets.
Significance. If the unbiasedness and variance characterization hold under active sampling, the framework could meaningfully advance efficient nonparametric inference in label-scarce regimes by bridging active learning with U-statistic theory. The explicit characterization of the optimal sampling rule and the extension to empirical risk minimization would be notable contributions if rigorously established.
major comments (1)
- The central claim that the augmented IPW U-statistic preserves unbiasedness and valid inference under the active per-instance sampling rule (guided by ML predictions) is load-bearing for the entire contribution. Because U-statistics are defined over pairs, the pair inclusion probability is the product of individual probabilities only under independent sampling; any dependence induced by the global active rule or by correlation between the predictor and labels could invalidate the simple per-instance augmentation. The manuscript should provide an explicit derivation (in the section introducing the augmented IPW U-statistic) showing that the augmentation term cancels the bias for all pairwise terms and that the variance formula remains correct under the stated sampling probabilities.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for highlighting the importance of rigorously establishing the unbiasedness properties of the augmented IPW U-statistic. We address the major comment in detail below and will incorporate the requested clarification into the revised version.
read point-by-point responses
-
Referee: The central claim that the augmented IPW U-statistic preserves unbiasedness and valid inference under the active per-instance sampling rule (guided by ML predictions) is load-bearing for the entire contribution. Because U-statistics are defined over pairs, the pair inclusion probability is the product of individual probabilities only under independent sampling; any dependence induced by the global active rule or by correlation between the predictor and labels could invalidate the simple per-instance augmentation. The manuscript should provide an explicit derivation (in the section introducing the augmented IPW U-statistic) showing that the augmentation term cancels the bias for all pairwise terms and that the variance formula remains correct under the stated sampling probabilities.
Authors: We agree that an explicit derivation is essential for establishing the validity of the framework. In the revised manuscript we will insert a dedicated subsection immediately following the definition of the augmented IPW U-statistic. The derivation proceeds as follows: the active sampling rule is implemented via independent Bernoulli draws with success probabilities π_i that depend only on the (fixed) machine-learning predictions for each instance; this is realized through a Poisson sampling scheme that respects the overall labeling budget in expectation while preserving independence of the inclusion indicators I_i. Consequently, P(I_i = 1, I_j = 1) = π_i π_j exactly. For any pair term, the estimator contribution is I_i I_j h(Y_i, Y_j) / (π_i π_j) augmented by correction terms that replace missing observations with the known predictions (scaled by the appropriate inclusion probabilities). Taking the conditional expectation given the predictions shows that each augmentation term exactly cancels the bias introduced by the missing indicators, yielding E[augmented pair term | predictions] = E[h(Y_i, Y_j) | predictions]. Unconditioning then recovers the unconditional expectation. The same conditioning argument shows that the variance formula, which already accounts for the second-moment structure of the indicators, remains valid; the correlation between the predictor and the labels is absorbed into the conditional expectations and does not affect the unbiasedness. We will also add a short remark clarifying that the Poisson approximation introduces only a negligible dependence that vanishes asymptotically under standard budget scaling. revision: yes
Circularity Check
No circularity: framework derives optimal rule from variance expression without self-definition or fitted-input renaming
full rationale
The abstract and skeptic summary describe a standard construction: an augmented IPW U-statistic is defined to incorporate a given sampling rule and ML predictions, after which the optimal rule is characterized by minimizing the resulting variance expression. This is a conventional optimization step (minimize Var(estimator) w.r.t. sampling probabilities) rather than a reduction by construction. No quoted equation shows the optimal rule being presupposed in the estimator definition, no self-citation is invoked as a uniqueness theorem, and no parameter fitted on one subset is relabeled as a prediction on another. The derivation chain therefore remains self-contained with independent mathematical content.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearaugmented inverse probability weighting U-statistic... optimal sampling rule that minimizes its variance
Reference graph
Works this paper leans on
-
[1]
VitalDB, a high-fidelity multi-parameter vital signs database in surgical patients , author =. Scientific Data , year =
-
[2]
Advances in Neural Information Processing Systems , volume =
Retiring Adult: New Datasets for Fair Machine Learning , author =. Advances in Neural Information Processing Systems , volume =
-
[3]
International Conference on Machine Learning , pages=
Active Statistical Inference , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[4]
The Annals of Statistics , number =
Ilmun Kim and Larry Wasserman and Sivaraman Balakrishnan and Matey Neykov , title =. The Annals of Statistics , number =
-
[5]
Theil-Sen Estimators in a Multiple Linear Regression Model , author =. 2008 , note =
work page 2008
-
[6]
Robust Sampling for Active Statistical Inference , author=. arXiv:2511.08991 , year=
-
[7]
D. G. Horvitz and D. J. Thompson , title =. Journal of the American Statistical Association , volume =. 1952 , publisher =
work page 1952
-
[8]
Some results on generalized difference estimation and generalized regression estimation for finite populations , author=. Biometrika , volume=. 1976 , publisher=
work page 1976
-
[9]
Journal of Causal Inference , volume=
Adaptive normalization for IPW estimation , author=. Journal of Causal Inference , volume=. 2023 , publisher=
work page 2023
-
[10]
Design based incomplete U-statistics , author=. Statistica Sinica , volume=. 2021 , publisher=
work page 2021
-
[11]
A new u-statistic with superior design sensitivity in matched observational studies , author=. Biometrics , volume=. 2011 , publisher=
work page 2011
-
[12]
Journal of the American Statistical Association , number=
U-Statistic Reduction: Higher-Order Accurate Risk Control and Statistical-Computational Trade-Off , author=. Journal of the American Statistical Association , number=. 2025 , publisher=
work page 2025
-
[13]
arXiv preprint arXiv:2311.01453 , year=
Ppi++: Efficient prediction-powered inference , author=. arXiv preprint arXiv:2311.01453 , year=
-
[14]
Semi-supervised distribution learning , author=. Biometrika , volume=. 2025 , publisher=
work page 2025
-
[15]
Neural Information Processing Systems , year=
Balanced Active Inference , author=. Neural Information Processing Systems , year=
- [16]
-
[17]
Metron-International Journal of Statistics , volume=
Gini’s Mean difference: a superior measure of variability for non-normal distributions , author=. Metron-International Journal of Statistics , volume=. 2003 , publisher=
work page 2003
-
[18]
Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach , author=. Biometrics , pages=. 1988 , publisher=
work page 1988
- [19]
-
[20]
The Annals of Mathematical Statistics , pages=
On a test of whether one of two random variables is stochastically larger than the other , author=. The Annals of Mathematical Statistics , pages=. 1947 , publisher=
work page 1947
-
[21]
The Annals of Mathematical Statistics , number =
Wassily Hoeffding , title =. The Annals of Mathematical Statistics , number =
- [22]
-
[23]
Ranking and empirical minimization of U-statistics , author=. 2008 , journal=
work page 2008
-
[24]
International Conference on Machine Learning , pages=
A theoretical analysis of contrastive unsupervised representation learning , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[25]
Advances in Neural Information Processing Systems , volume=
Regularized distance metric learning: Theory and algorithm , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Computers, Materials and Continua , volume=
Medical diagnosis using machine learning: a statistical review , author=. Computers, Materials and Continua , volume=. 2021 , publisher=
work page 2021
-
[27]
The Review of Financial Studies , volume=
Empirical asset pricing via machine learning , author=. The Review of Financial Studies , volume=. 2020 , publisher=
work page 2020
-
[28]
Annual Review of Political Science , volume=
Machine learning for social science: An agnostic approach , author=. Annual Review of Political Science , volume=. 2021 , publisher=
work page 2021
-
[29]
ACM computing surveys (CSUR) , volume=
A survey of deep active learning , author=. ACM computing surveys (CSUR) , volume=. 2021 , publisher=
work page 2021
-
[30]
arXiv preprint arXiv:2506.10908 , year=
Probably Approximately Correct Labels , author=. arXiv preprint arXiv:2506.10908 , year=
-
[31]
Active Hypothesis Testing under Computational Budgets with Applications to GWAS and LLM
Active Hypothesis Testing under Computational Budgets with Applications to GWAS and LLM , author=. arXiv preprint arXiv:2512.01423 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
arXiv preprint arXiv:2502.11032 , year=
Exact variance estimation for model-assisted survey estimators using U-and V-statistics , author=. arXiv preprint arXiv:2502.11032 , year=
-
[33]
arXiv preprint arXiv:2506.07949 , year=
Cost-Optimal Active AI Model Evaluation , author=. arXiv preprint arXiv:2506.07949 , year=
-
[34]
International Conference on Machine Learning , pages=
Active Adaptive Experimental Design for Treatment Effect Estimation with Covariate Choice , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[35]
Can unconfident llm annotations be used for confident conclusions? , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
work page 2025
-
[36]
arXiv preprint arXiv:2501.18577 , year=
Prediction-powered inference with imputed covariates and nonuniform sampling , author=. arXiv preprint arXiv:2501.18577 , year=
-
[37]
Advances in Neural Information Processing Systems , volume=
On differentially private U statistics , author=. Advances in Neural Information Processing Systems , volume=
-
[38]
The Annals of Statistics , volume=
Distributed statistical inference for massive data , author=. The Annals of Statistics , volume=. 2021 , publisher=
work page 2021
-
[39]
Randomized incomplete U-statistics in high dimensions , author=. 2019 , journal=
work page 2019
-
[40]
Journal of Machine Learning Research , volume=
Scaling-up empirical risk minimization: optimization of incomplete U -statistics , author=. Journal of Machine Learning Research , volume=
-
[41]
Journal of Machine Learning Research , volume=
Distributed algorithms for U-statistics-based empirical risk minimization , author=. Journal of Machine Learning Research , volume=
-
[42]
Approximation theorems of mathematical statistics , author=. 2009 , publisher=
work page 2009
-
[43]
Annals of Statistics , volume=
Gaussian and bootstrap approximations for high-dimensional U-statistics and their applications , author=. Annals of Statistics , volume=. 2018 , publisher=
work page 2018
-
[44]
Journal of Machine Learning Research , year =
Yining Wang and Adams Wei Yu and Aarti Singh , title =. Journal of Machine Learning Research , year =
- [45]
-
[46]
Prediction-powered inference , author=. Science , volume=. 2023 , publisher=
work page 2023
-
[47]
Proceedings of the National Academy of Sciences , volume=
Cross-prediction-powered inference , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
work page 2024
-
[48]
Advances in Neural Information Processing Systems , volume=
Prediction-powered ranking of large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[49]
Anru Zhang and Lawrence D. Brown and T. Tony Cai , title =. The Annals of Statistics , number =
-
[50]
Advances in Neural Information Processing Systems , year=
Doubly Robust Self-Training , author=. Advances in Neural Information Processing Systems , year=
-
[51]
Advances in Neural Information Processing Systems , volume=
Empirical Bernstein inequalities for u-statistics , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Advances in Neural Information Processing Systems , volume=
Generalization guarantee of SGD for pairwise learning , author=. Advances in Neural Information Processing Systems , volume=
-
[53]
Learning to rank for information retrieval , author=. Foundations and trends. 2009 , publisher=
work page 2009
-
[54]
Seminars in nuclear medicine , volume=
Basic principles of ROC analysis , author=. Seminars in nuclear medicine , volume=. 1978 , organization=
work page 1978
-
[55]
International Conference on Machine Learning , pages=
One-pass AUC optimization , author=. International Conference on Machine Learning , pages=. 2013 , organization=
work page 2013
-
[56]
Journal of the American Statistical Association , volume=
Optimal subsampling for large sample logistic regression , author=. Journal of the American Statistical Association , volume=. 2018 , publisher=
work page 2018
-
[57]
The Journal of Machine Learning Research , volume=
A statistical perspective on algorithmic leveraging , author=. The Journal of Machine Learning Research , volume=. 2015 , publisher=
work page 2015
-
[58]
Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=
Multi-resolution subsampling for linear classification with massive data , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , pages=. 2025 , publisher=
work page 2025
-
[59]
International Conference on Artificial Intelligence and Statistics , pages=
Deep active learning: Unified and principled method for query and training , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
work page 2020
-
[60]
Enhancing Deep Batch Active Learning for Regression with Imperfect Data Guided Selection , volume =
Min, Yinjie and Xu, Furong and Li, Xinyao and Zou, Changliang and Zhou, Yongdao , booktitle =. Enhancing Deep Batch Active Learning for Regression with Imperfect Data Guided Selection , volume =
- [61]
-
[62]
Journal of Machine Learning Research , volume=
Monte carlo gradient estimation in machine learning , author=. Journal of Machine Learning Research , volume=
- [63]
-
[64]
Symposium on Monte Carlo Methods , editor =
Trotter, Hale F and Tukey, John W , title =. Symposium on Monte Carlo Methods , editor =
-
[65]
arXiv preprint arXiv:2204.14121 , year=
Inverse probability weighting: from survey sampling to evidence estimation , author=. arXiv preprint arXiv:2204.14121 , year=
-
[66]
Individual comparisons by ranking methods , author=. Biometrics Bulletin , volume=. 1945 , publisher=
work page 1945
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.