Recognition: no theorem link
Machine Learning-Based Covariance Correction for Ensemble Kalman Filter with Limited Ensemble Size
Pith reviewed 2026-05-13 01:24 UTC · model grok-4.3
The pith
A multilayer perceptron predicts the covariance gap between small and large ensembles and scales the small-ensemble matrix to raise EnKF analysis accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
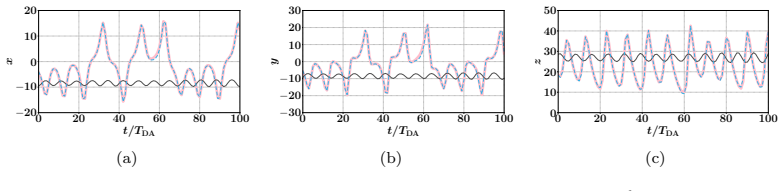
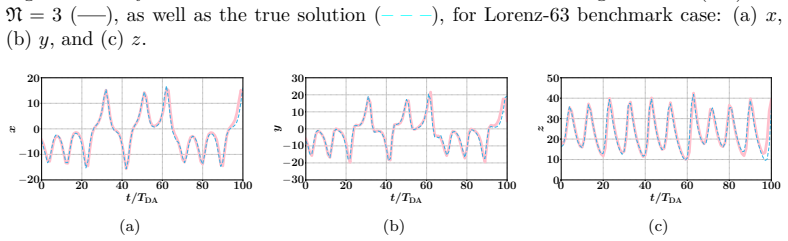
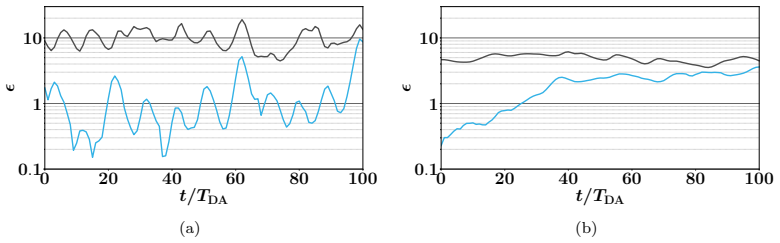
The authors build an MLP that learns the element-wise difference between the sample covariance obtained from a small ensemble and the sample covariance obtained from a sufficiently large ensemble. This learned difference is added back to the small-ensemble covariance via an element-wise scaling factor, yielding a corrected forecast-error covariance that is then used inside the standard EnKF update. Numerical tests on Lorenz-63 and Lorenz-96 show that the resulting analyses are consistently more accurate than those of the uncorrected small-ensemble EnKF while the run-time cost remains that of the small ensemble.
What carries the argument
The MLP that outputs the covariance-difference correction term, which is then applied by element-wise scaling to the limited-ensemble forecast covariance.
If this is right
- The corrected small-ensemble EnKF yields lower analysis error than the standard small-ensemble EnKF at identical computational cost.
- The method remains stable across different observation densities and noise levels in the Lorenz-63 and Lorenz-96 test beds.
- The scaling correction can be inserted into any existing EnKF implementation without changing the ensemble size or the core update equations.
- Training the MLP once on representative forecast-error pairs allows repeated use in subsequent assimilation cycles.
Where Pith is reading between the lines
- Operational centers could retrain the MLP periodically on recent forecast-error statistics to track changes in model error.
- The same correction idea might be tested on other ensemble-based filters that also suffer from sampling noise in covariance estimates.
- If the MLP generalizes across model resolutions, the approach could relax the need to increase ensemble size when moving to finer grids.
Load-bearing premise
The covariance estimated from a large ensemble is treated as an accurate stand-in for the true forecast-error covariance.
What would settle it
Run the same assimilation cycle with an ensemble size so large that its sample covariance converges, then check whether the MLP-corrected small-ensemble covariance produces analysis errors that match those of the converged large ensemble within sampling noise.
Figures
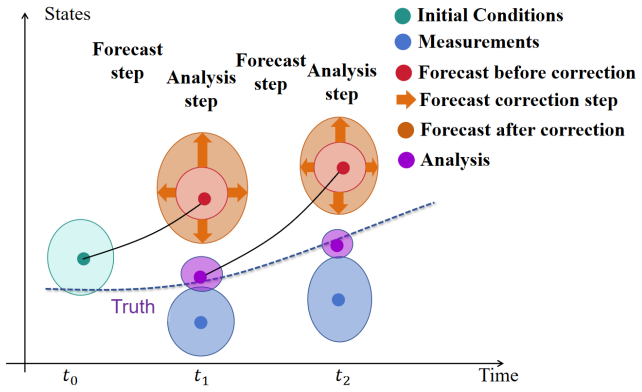
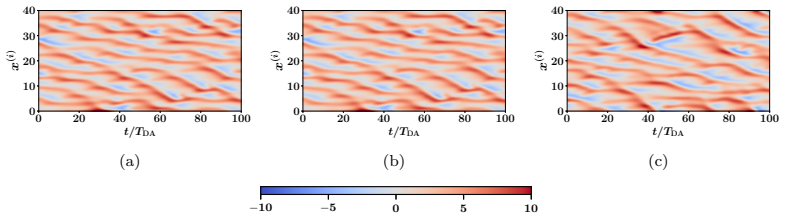
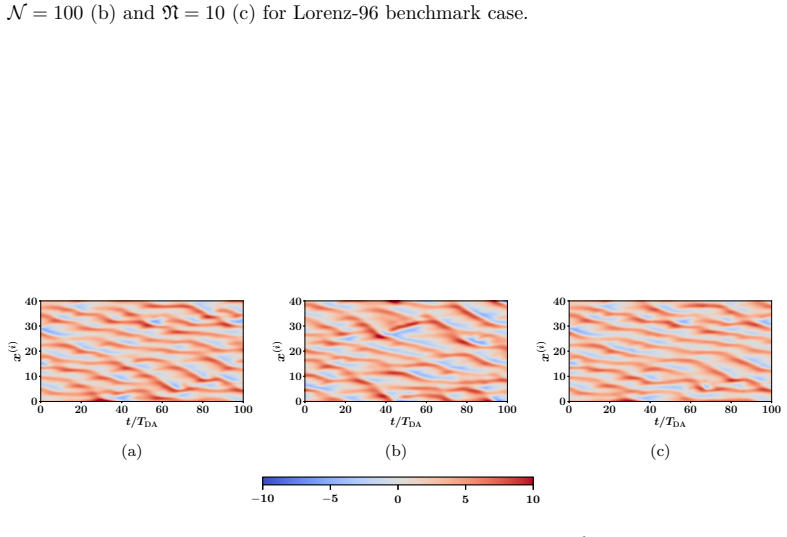
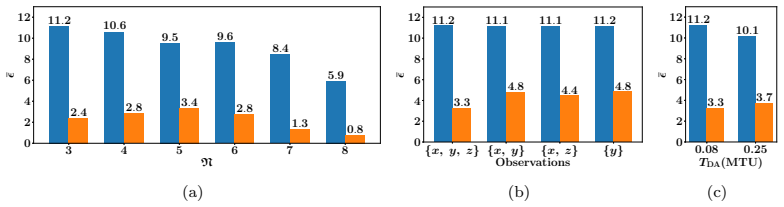
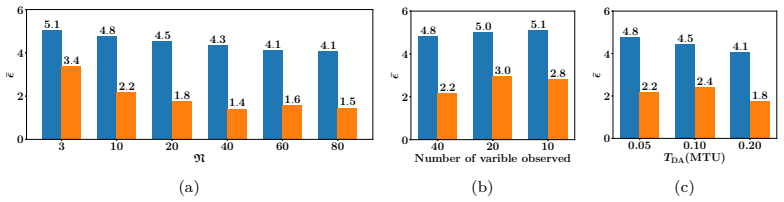
read the original abstract
Data assimilation (DA) integrates numerical model forecasts with observations to achieve the optimal state estimation. Ensemble-based methods, such as the ensemble Kalman filter (EnKF), are widely used for state estimation for high-dimensional and nonlinear dynamic systems. However, their performance strongly depends on the ensemble size, therefore causing a tradeoff problem between analysis accuracy and computational cost. To address this problem, this study presents a machine learning-based EnKF framework that maintains high accuracy with a relatively small ensemble size. Specifically, a multilayer perceptron (MLP) function is built to predict the difference between the forecast error covariances estimated from a limited ensemble and a sufficiently large ensemble, with the latter being assumed to be an accurate approximation of the underlying truth. This predicted covariance difference term is then incorporated into the EnKF algorithm via an element-wise scaling strategy, resulting in an amended forecast covariance matrix that better approximates the true uncertainty level and sequentially produces more accurate analysis results. To demonstrate the feasibility and robustness of the proposed algorithm, we perform a set of numerical experiments with the Lorenz-63 and Lorenz-96 systems under various configurations, and the results consistently indicate that the proposed algorithm can significantly outperform the standard EnKF with the same limited ensemble size, by achieving notably higher analysis accuracy while remaining computationally efficient. This approach provides a practical and feasible pathway to accurate and computationally efficient data assimilation for high-dimensional and nonlinear dynamic systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a machine learning-based covariance correction for the Ensemble Kalman Filter (EnKF) to mitigate performance degradation from limited ensemble sizes. A multilayer perceptron (MLP) is trained to predict the element-wise difference between forecast-error covariances estimated from a small ensemble and a large ensemble (treated as ground truth); this predicted difference is then applied via element-wise scaling to produce an amended covariance matrix for the EnKF update. Twin experiments on the Lorenz-63 and Lorenz-96 systems under various configurations report that the corrected EnKF consistently yields higher analysis accuracy than the standard EnKF at the same small ensemble size while preserving computational efficiency.
Significance. If the central claim holds, the method offers a practical route to accurate ensemble-based data assimilation in high-dimensional nonlinear systems without the full cost of large ensembles. The approach is computationally lightweight after training and demonstrates consistent gains in the reported low-dimensional tests. Credit is due for the reproducible experimental framework on standard chaotic benchmarks and for framing the correction as a learned mapping rather than an ad-hoc inflation. However, significance is limited by the dependence on large-ensemble runs for training targets and by the absence of tests in systems where even 'large' ensembles retain non-negligible sampling error.
major comments (2)
- Abstract and §3 (Methodology): The claim that the amended covariance 'better approximates the true uncertainty level' rests on the assumption that the large-ensemble covariance is a sufficiently accurate proxy for the underlying truth. No quantification of residual sampling error in the target covariance is provided, nor is sensitivity to the choice of large-ensemble size tested. If the target retains sampling error, the MLP simply reproduces that error, directly undermining the reported accuracy gains (see also the skeptic note on generalization to high-dimensional systems).
- §4 (Numerical Experiments): The abstract states 'consistent outperformance' and 'notably higher analysis accuracy,' yet the manuscript supplies no training details, hyperparameter choices, cross-validation procedure, or error-bar quantification on the analysis RMSE. Without these, the robustness of the central performance claim cannot be evaluated and the results remain high-level statements rather than statistically supported evidence.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important aspects of our methodology and experimental reporting that we will address to improve clarity and rigor. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: Abstract and §3 (Methodology): The claim that the amended covariance 'better approximates the true uncertainty level' rests on the assumption that the large-ensemble covariance is a sufficiently accurate proxy for the underlying truth. No quantification of residual sampling error in the target covariance is provided, nor is sensitivity to the choice of large-ensemble size tested. If the target retains sampling error, the MLP simply reproduces that error, directly undermining the reported accuracy gains (see also the skeptic note on generalization to high-dimensional systems).
Authors: We agree that the large-ensemble covariance is an approximation rather than the exact truth, and that residual sampling error could in principle be learned by the MLP. In the revised manuscript we will add a new subsection in §3 that quantifies convergence of the covariance estimate with ensemble size for the Lorenz systems (comparing 500-, 1000-, and 2000-member ensembles) and reports the Frobenius-norm difference between successive large-ensemble estimates. We will also include a sensitivity experiment in §4 that retrains the MLP using targets from different large-ensemble sizes and shows that the performance gain over the standard EnKF remains stable once the target ensemble exceeds ~800 members. These additions will make the approximation assumption explicit and testable. Regarding generalization, we note that the element-wise correction is dimension-independent in principle, but we will add a brief discussion of the computational scaling and a statement that high-dimensional tests remain future work. revision: partial
-
Referee: §4 (Numerical Experiments): The abstract states 'consistent outperformance' and 'notably higher analysis accuracy,' yet the manuscript supplies no training details, hyperparameter choices, cross-validation procedure, or error-bar quantification on the analysis RMSE. Without these, the robustness of the central performance claim cannot be evaluated and the results remain high-level statements rather than statistically supported evidence.
Authors: We accept that the current experimental section lacks the necessary details for reproducibility and statistical assessment. In the revised manuscript we will expand §4 with: (i) a complete description of the MLP training protocol (training-set size, optimizer, learning-rate schedule, number of epochs, early-stopping criterion); (ii) the hyperparameter selection procedure (grid search over hidden-layer sizes and regularization strengths, with validation loss reported); (iii) the cross-validation scheme used (5-fold cross-validation on the forecast-error covariance samples); and (iv) error bars on all RMSE curves computed as the standard deviation across 10 independent random seeds for both training and assimilation runs. We will also add a short statistical comparison (paired t-test) between the corrected and standard EnKF RMSE values to support the claim of consistent outperformance. revision: yes
Circularity Check
No significant circularity in the proposed ML covariance correction
full rationale
The paper trains an MLP to map the difference between limited-ensemble and large-ensemble forecast-error covariances (explicitly treating the large ensemble as a proxy for truth) and then applies the learned correction element-wise inside the EnKF update. This is a standard supervised-learning workflow whose output on unseen forecast states is not equivalent to its training inputs by construction. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation chain. Performance is evaluated empirically on Lorenz-63/96 twin experiments against the same large-ensemble reference used for training, which is an external benchmark rather than a tautology. The method therefore remains self-contained against its stated assumptions and does not reduce to its own data-generation procedure.
Axiom & Free-Parameter Ledger
free parameters (1)
- MLP weights and architecture
axioms (1)
- domain assumption Large-ensemble forecast error covariance approximates the true underlying covariance
Reference graph
Works this paper leans on
-
[1]
Wiley Interdisciplinary Reviews Climate Change , volume=
Data assimilation in the geosciences An overview of methods, issues, and perspectives , author=. Wiley Interdisciplinary Reviews Climate Change , volume=. 2018 , publisher=
work page 2018
-
[2]
Atmospheric chemistry and physics , volume=
Data assimilation in atmospheric chemistry models: current status and future prospects for coupled chemistry meteorology models , author=. Atmospheric chemistry and physics , volume=. 2015 , publisher=
work page 2015
-
[3]
Part II: Recent years , author=
Assimilation of satellite data in numerical weather prediction. Part II: Recent years , author=. Quarterly Journal of the Royal Meteorological Society , volume=. 2022 , publisher=
work page 2022
-
[4]
Journal of Fluid Mechanics , volume=
Phase-resolved ocean wave forecast with ensemble-based data assimilation , author=. Journal of Fluid Mechanics , volume=. 2021 , publisher=
work page 2021
-
[5]
Journal of Fluid Mechanics , volume=
Phase-resolved ocean wave forecast with simultaneous current estimation through data assimilation , author=. Journal of Fluid Mechanics , volume=. 2022 , publisher=
work page 2022
-
[6]
Data assimilation schemes for ocean forecasting: state of the art , author=. State of the Planet , volume=. 2025 , publisher=
work page 2025
-
[7]
Reviews of Geophysics , volume=
Land data assimilation: Harmonizing theory and data in land surface process studies , author=. Reviews of Geophysics , volume=. 2024 , publisher=
work page 2024
-
[8]
Journal of Hydrometeorology , volume=
Global soil water estimates as landslide predictor: the effectiveness of SMOS, SMAP, and GRACE observations, land surface simulations, and data assimilation , author=. Journal of Hydrometeorology , volume=
-
[9]
Journal of Geophysical Research: Oceans , volume=
Sequential data assimilation with a nonlinear quasi-geostrophic model using Monte Carlo methods to forecast error statistics , author=. Journal of Geophysical Research: Oceans , volume=. 1994 , publisher=
work page 1994
-
[10]
The ensemble Kalman filter: Theoretical formulation and practical implementation , author=. Ocean dynamics , volume=. 2003 , publisher=
work page 2003
-
[11]
Ensemble-based data assimilation and the localisation problem , author=. Weather , volume=. 2010 , publisher=
work page 2010
-
[12]
Monthly Weather Review , volume=
Evaluating methods to account for system errors in ensemble data assimilation , author=. Monthly Weather Review , volume=
-
[13]
Spectral and spatial localization of background-error correlations for data assimilation , author=. Quarterly Journal of the Royal Meteorological Society: A journal of the atmospheric sciences, applied meteorology and physical oceanography , volume=. 2007 , publisher=
work page 2007
-
[14]
Journal of Geophysical Research: Atmospheres , volume=
Estimation of surface carbon fluxes with an advanced data assimilation methodology , author=. Journal of Geophysical Research: Atmospheres , volume=. 2012 , publisher=
work page 2012
-
[15]
Physica D: Nonlinear Phenomena , volume=
Sampling error mitigation through spectrum smoothing: First experiments with ensemble transform Kalman filters and Lorenz models , author=. Physica D: Nonlinear Phenomena , volume=. 2025 , publisher=
work page 2025
-
[16]
Journal of computational science , volume=
Combining data assimilation and machine learning to emulate a dynamical model from sparse and noisy observations: A case study with the Lorenz 96 model , author=. Journal of computational science , volume=. 2020 , publisher=
work page 2020
-
[17]
Journal of Advances in Modeling Earth Systems , volume=
An online paleoclimate data assimilation with a deep learning-based network , author=. Journal of Advances in Modeling Earth Systems , volume=. 2025 , publisher=
work page 2025
-
[18]
Deep data assimilation: integrating deep learning with data assimilation , author=. Applied Sciences , volume=. 2021 , publisher=
work page 2021
-
[19]
Journal of Computational Science , volume=
Fast data assimilation (FDA): Data assimilation by machine learning for faster optimize model state , author=. Journal of Computational Science , volume=. 2021 , publisher=
work page 2021
-
[20]
Towards implementing artificial intelligence post-processing in weather and climate: Proposed actions from the Oxford 2019 workshop , author=. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2021 , publisher=
work page 2019
-
[21]
Monthly Weather Review , volume=
Neural networks for postprocessing model output: ARPS , author=. Monthly Weather Review , volume=
-
[22]
Quarterly Journal of the Royal Meteorological Society , volume=
Predicting weather forecast uncertainty with machine learning , author=. Quarterly Journal of the Royal Meteorological Society , volume=. 2018 , publisher=
work page 2018
-
[23]
Deep learning for post-processing ensemble weather forecasts , author=. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences , volume=. 2021 , publisher=
work page 2021
-
[24]
Astronomy & Astrophysics , volume=
Photometric redshift estimation via deep learning-generalized and pre-classification-less, image based, fully probabilistic redshifts , author=. Astronomy & Astrophysics , volume=. 2018 , publisher=
work page 2018
-
[25]
On the generation of probabilistic forecasts from deterministic models , author=. Space weather , volume=. 2019 , publisher=
work page 2019
-
[26]
Journal of Advances in Modeling Earth Systems , volume=
Controlled abstention neural networks for identifying skillful predictions for regression problems , author=. Journal of Advances in Modeling Earth Systems , volume=. 2021 , publisher=
work page 2021
-
[27]
Monthly weather review , volume=
Analysis scheme in the ensemble Kalman filter , author=. Monthly weather review , volume=. 1998 , publisher=
work page 1998
-
[28]
Quarterly Journal of the Royal Meteorological Society , volume=
A consistent interpretation of the stochastic version of the Ensemble Kalman Filter , author=. Quarterly Journal of the Royal Meteorological Society , volume=. 2020 , publisher=
work page 2020
-
[29]
Data assimilation in the solar wind: Challenges and first results , author=. Space Weather , volume=. 2017 , publisher=
work page 2017
-
[30]
Quarterly Journal of the Royal Meteorological Society , volume=
Construction of correlation functions in two and three dimensions , author=. Quarterly Journal of the Royal Meteorological Society , volume=. 1999 , publisher=
work page 1999
-
[31]
Quarterly Journal of the Royal Meteorological Society , volume=
On-line machine-learning forecast uncertainty estimation for sequential data assimilation , author=. Quarterly Journal of the Royal Meteorological Society , volume=. 2024 , publisher=
work page 2024
-
[32]
Quarterly Journal of the Royal Meteorological Society , volume=
Evaluation of machine learning techniques for forecast uncertainty quantification , author=. Quarterly Journal of the Royal Meteorological Society , volume=. 2022 , publisher=
work page 2022
-
[33]
Journal of Fluid Mechanics , volume=
Ensemble Kalman method for learning turbulence models from indirect observation data , author=. Journal of Fluid Mechanics , volume=. 2022 , publisher=
work page 2022
-
[34]
Annual review of fluid mechanics , volume=
Turbulence modeling in the age of data , author=. Annual review of fluid mechanics , volume=. 2019 , publisher=
work page 2019
-
[35]
International Journal of Impact Engineering , pages=
Ensemble-based data assimilation for material model characterization in high-velocity impact , author=. International Journal of Impact Engineering , pages=. 2026 , publisher=
work page 2026
-
[36]
Estimation of state and material properties during heat-curing molding of composite materials using data assimilation: A numerical study , author=. Heliyon , volume=. 2018 , publisher=
work page 2018
-
[37]
Data assimilation for atmospheric, oceanic and hydrologic applications , pages=
Data assimilation for numerical weather prediction: a review , author=. Data assimilation for atmospheric, oceanic and hydrologic applications , pages=. 2009 , publisher=
work page 2009
-
[38]
Materials Today: Proceedings , volume=
A review of data assimilation techniques: Applications in engineering and agriculture , author=. Materials Today: Proceedings , volume=. 2022 , publisher=
work page 2022
-
[39]
Overview of global data assimilation developments in numerical weather-prediction centres , author=. Quarterly Journal of the Royal Meteorological Society: A journal of the atmospheric sciences, applied meteorology and physical oceanography , volume=. 2005 , publisher=
work page 2005
-
[40]
Reports on Progress in Physics , volume=
Data assimilation in ocean models , author=. Reports on Progress in Physics , volume=
-
[41]
Journal of Operational Oceanography , volume=
Status and future of data assimilation in operational oceanography , author=. Journal of Operational Oceanography , volume=. 2015 , publisher=
work page 2015
-
[42]
Deep uncertainty quantification: A machine learning approach for weather forecasting , author=. Proceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[43]
Journal of Advances in Modeling Earth Systems , volume=
Machine learning-based prediction of spatiotemporal uncertainties in global wind velocity reanalyses , author=. Journal of Advances in Modeling Earth Systems , volume=. 2020 , publisher=
work page 2020
-
[44]
arXiv preprint arXiv:2510.15284 , year=
Small Ensemble-based Data Assimilation: A Machine Learning-Enhanced Data Assimilation Method with Limited Ensemble Size , author=. arXiv preprint arXiv:2510.15284 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.