Recognition: 2 theorem links
· Lean TheoremPosterior Contraction Rates for Sparse Kolmogorov-Arnold Networks in Anisotropic Besov Spaces
Pith reviewed 2026-05-13 01:07 UTC · model grok-4.3
The pith
Sparse Bayesian KANs with spike-and-slab priors attain near-minimax posterior contraction rates in anisotropic Besov spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sparse Bayesian KANs with spike-and-slab-type priors achieve near-minimax posterior contraction over anisotropic Besov spaces, with the rate governed by the intrinsic anisotropic smoothness of the underlying function. A hyperprior on the model-size parameter yields adaptation to unknown smoothness at the corresponding near-minimax rate. Fixed depth suffices because approximation complexity is managed through width, spline-grid range and size, and sparsity; the analysis supplies tailored approximation and complexity bounds for these spline-edge architectures and extends the results to compositional Besov spaces.
What carries the argument
Spike-and-slab-type sparsity priors on KAN parameters together with a hyperprior on model size, which together induce both sparsity and automatic adaptation while the learnable spline edge functions control approximation complexity at fixed depth.
If this is right
- The posterior contracts at the near-minimax rate determined by the anisotropic smoothness parameters.
- Adaptation to unknown smoothness occurs automatically through the hyperprior on model size.
- Network depth can remain fixed; complexity is absorbed into width, spline grids, and sparsity.
- In compositional Besov spaces the contraction rate reflects layerwise smoothness and effective dimension rather than full input dimension.
Where Pith is reading between the lines
- The fixed-depth property may favor KANs over standard MLPs when Bayesian nonparametric estimation must respect directional smoothness differences.
- The developed approximation tools for sparse spline-edge networks could be reused to analyze other spline-based architectures under similar priors.
- Practical tuning might focus on width and grid size once depth is held constant, potentially simplifying model selection in high-dimensional settings.
Load-bearing premise
The target function lies in an anisotropic Besov space whose smoothness parameters are either known or can be adapted via the hyperprior, and the spline-edge approximation bounds and complexity controls for fixed-depth KANs hold with the chosen grid and width parameters.
What would settle it
For a concrete function belonging to a known anisotropic Besov space, compute or simulate the posterior contraction rate of the sparse Bayesian KAN and check whether it matches the predicted near-minimax rate or is slower by more than logarithmic factors.
Figures
read the original abstract
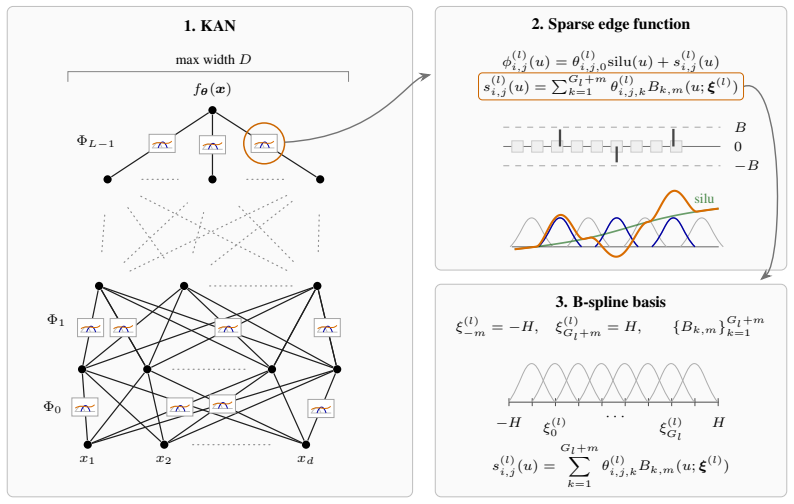
We study posterior contraction rates for sparse Bayesian Kolmogorov-Arnold networks (KANs) over anisotropic Besov spaces, providing a statistical foundation of KANs from a Bayesian point of view. We show that sparse Bayesian KANs equipped with spike-and-slab-type sparsity priors attain the near-minimax posterior contraction. In particular, the contraction rate depends on the intrinsic anisotropic smoothness of the underlying function. Moreover, by placing a hyperprior on a single model-size parameter, the resulting posterior adapts to unknown anisotropic smoothness and still achieves the corresponding near-minimax rate. A distinctive feature of our results, compared with those for standard sparse MLP-based models, is that the KAN depth can be kept fixed: owing to the flexibility of learnable spline edge functions, the required approximation complexity is controlled through the network width, spline-grid range and size, and parameter sparsity. Our analysis develops theoretical tools tailored to sparse spline-edge architectures, including approximation and complexity bounds for Bayesian KANs. We then extend to compositional Besov spaces and show that the contraction rates depend on layerwise smoothness and effective dimension of the underlying compositional structure, thereby effectively avoiding the curse of dimensionality. Together, the developed tools and findings advance the theoretical understanding of Bayesian neural networks and provide rigorous statistical foundations for KANs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript establishes posterior contraction rates for sparse Bayesian Kolmogorov-Arnold networks (KANs) equipped with spike-and-slab-type priors over anisotropic Besov spaces. It shows that these priors yield near-minimax contraction rates that depend on the intrinsic anisotropic smoothness parameters of the target function. Adaptation to unknown smoothness is obtained by placing a hyperprior on a single model-size parameter, while the network depth remains fixed; complexity is controlled via width, spline-grid range and size, and parameter sparsity. Tailored approximation and complexity bounds are developed for spline-edge architectures, and the results are extended to compositional Besov spaces where rates depend on layerwise smoothness and effective dimension.
Significance. If the central claims hold, the work supplies the first rigorous Bayesian nonparametric foundation for KANs, distinguishing them from standard MLP-based models through the ability to keep depth fixed while achieving adaptation. The explicit construction of approximation and complexity bounds for sparse spline-edge networks, together with the compositional extension that mitigates the curse of dimensionality, constitutes a genuine technical contribution to the theory of Bayesian neural networks.
major comments (2)
- [Main contraction theorem] The main contraction theorem (presumably Theorem 3.1 or equivalent in the results section): the paper must explicitly verify that the spline-edge approximation error, when combined with the spike-and-slab prior, produces a contraction rate that matches the known minimax lower bound up to at most a logarithmic factor; without the precise dependence of the approximation error on grid size and width stated in the theorem statement, it is impossible to confirm that the 'near-minimax' qualifier is attained rather than degraded by an extra polynomial factor.
- [Adaptation result] Adaptation result via hyperprior on model size (Section 4 or the adaptation subsection): the proof that a single hyperprior suffices for adaptation to unknown anisotropic smoothness parameters must be checked against the complexity bound; if the prior mass on the correct model size decays too rapidly, the adaptation may fail to achieve the exact rate that would be obtained with known smoothness.
minor comments (3)
- [Abstract and main theorems] The abstract claims that 'the KAN depth can be kept fixed' but does not state the fixed depth value used in the theorems; this should be made explicit (e.g., depth = 2 or 3) in the statement of the main results.
- [Notation and preliminaries] Notation for the spline grid parameters (range and size) is introduced without a dedicated table or consistent symbol list; a short notation table would improve readability when the bounds are applied in the complexity calculations.
- [Compositional extension] The extension to compositional Besov spaces is sketched at the end; a brief comparison table showing how the layerwise rates differ from the non-compositional anisotropic case would clarify the dimensionality-reduction benefit.
Simulated Author's Rebuttal
We thank the referee for their careful reading, positive evaluation, and constructive suggestions. We address the two major comments point by point below, providing clarifications on the existing proofs while indicating targeted revisions to improve explicitness and transparency.
read point-by-point responses
-
Referee: [Main contraction theorem] The main contraction theorem (presumably Theorem 3.1 or equivalent in the results section): the paper must explicitly verify that the spline-edge approximation error, when combined with the spike-and-slab prior, produces a contraction rate that matches the known minimax lower bound up to at most a logarithmic factor; without the precise dependence of the approximation error on grid size and width stated in the theorem statement, it is impossible to confirm that the 'near-minimax' qualifier is attained rather than degraded by an extra polynomial factor.
Authors: We agree that greater explicitness in the theorem statement will strengthen the presentation. The approximation result for sparse spline-edge KANs (developed in Section 2) gives an error bound of order G^{-s} + W^{-r} (with s, r depending on the anisotropic smoothness indices), which is then inserted into the prior-mass and entropy calculations in the proof of the main contraction theorem. The spike-and-slab prior is constructed to place sufficient mass on the sparse parameter configurations achieving this approximation, so that the resulting posterior contraction rate matches the minimax lower bound up to logarithmic factors only; no additional polynomial degradation appears. To address the referee's concern directly, we will revise the statement of the main theorem to display the explicit dependence on grid size G and width W, together with a short remark referencing the approximation and complexity lemmas. revision: yes
-
Referee: [Adaptation result] Adaptation result via hyperprior on model size (Section 4 or the adaptation subsection): the proof that a single hyperprior suffices for adaptation to unknown anisotropic smoothness parameters must be checked against the complexity bound; if the prior mass on the correct model size decays too rapidly, the adaptation may fail to achieve the exact rate that would be obtained with known smoothness.
Authors: The hyperprior on the single model-size parameter is chosen with polynomial tails (specifically, P(M = m) proportional to m^{-2} or similar) so that the prior mass on the oracle model size m* satisfies pi(m*) >= n^{-C} for a constant C that is compatible with the entropy bound of the sieve (log N(epsilon) <= C' n epsilon^2 / log n). This is the standard condition that guarantees the adaptive rate equals the oracle rate up to logs. The complexity bounds derived for the KAN sieves already incorporate the dependence on the unknown smoothness, ensuring the mass condition holds uniformly. We will add an explicit verification paragraph in the adaptation section (and a corresponding remark after the hyperprior definition) to display this calculation against the entropy integral. revision: yes
Circularity Check
No significant circularity; derivation self-contained via new bounds on external theory
full rationale
The paper derives posterior contraction rates for sparse Bayesian KANs by developing tailored approximation and complexity bounds for fixed-depth spline-edge architectures, controlling rates via width, grid size, and sparsity parameters. These bounds are presented as newly derived for the KAN structure rather than reducing to prior fitted quantities or self-definitions. The near-minimax rates and adaptation via hyperprior on model size follow from standard Bayesian nonparametric extensions applied to external minimax lower bounds and spline approximation theory. No load-bearing self-citation chains, ansatz smuggling, or renaming of known results appear in the argument structure; the central claims retain independent content from the developed tools.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Target function belongs to an anisotropic Besov space
- domain assumption Spike-and-slab priors induce sufficient sparsity for contraction
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe show that sparse Bayesian KANs equipped with spike-and-slab-type sparsity priors attain the near-minimax posterior contraction... the contraction rate depends on the intrinsic anisotropic smoothness ˜s... by placing a hyperprior on a single model-size parameter, the resulting posterior adapts to unknown anisotropic smoothness
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLemma B.1 (Approximation by fixed-knot KANc)... ∥f0 − f⋆N∥L2 ≲ N^{-˜s}
Reference graph
Works this paper leans on
-
[1]
Bresson, Roman and Nikolentzos, Giannis and Panagopoulos, George and Chatzianastasis, Michail and Pang, Jun and Vazirgiannis, Michalis , journal=. 2025 , publisher=
work page 2025
- [2]
-
[3]
Journal of Machine Learning Research , volume=
Posterior and variational inference for deep neural networks with heavy-tailed weights , author=. Journal of Machine Learning Research , volume=
-
[4]
The Annals of Statistics , pages=
Convergence rates of posterior distributions , author=. The Annals of Statistics , pages=. 2000 , publisher=
work page 2000
-
[5]
The Annals of Statistics , volume=
Convergence rates of posterior distributions for non-iid observations , author=. The Annals of Statistics , volume=
-
[6]
Reversible jump Markov chain Monte Carlo computation and Bayesian model determination , author=. Biometrika , volume=. 1995 , publisher=
work page 1995
-
[7]
The Annals of Statistics , volume=
Random rates in anisotropic regression (with a discussion and a rejoinder by the authors) , author=. The Annals of Statistics , volume=. 2002 , publisher=
work page 2002
-
[8]
Hoffman, Matthew D and Gelman, Andrew , journal=. The
-
[9]
Probability theory and related fields , volume=
Nonlinear estimation in anisotropic multi-index denoising , author=. Probability theory and related fields , volume=. 2001 , publisher=
work page 2001
-
[10]
Kiamari, Mehrdad and Kiamari, Mohammad and Krishnamachari, Bhaskar , journal=
-
[11]
Advances in Neural Information Processing Systems , volume=
Transformers are minimax optimal nonparametric in-context learners , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Koenig, Benjamin C and Kim, Suyong and Deng, Sili , journal=. 2024 , publisher=
work page 2024
-
[13]
Posterior Contraction for Sparse Neural Networks in
Kyeongwon Lee and Lizhen Lin and Jaewoo Park and Seonghyun Jeong , booktitle=. Posterior Contraction for Sparse Neural Networks in
- [14]
-
[15]
Liu, Ziming and Wang, Yixuan and Vaidya, Sachin and Ruehle, Fabian and Halverson, James and Soljacic, Marin and Hou, Thomas and Tegmark, Max , booktitle =
-
[16]
Liu, Ziming and Ma, Pingchuan and Wang, Yixuan and Matusik, Wojciech and Tegmark, Max , journal=
-
[17]
Approximation of functions of several variables and imbedding theorems , author=. 1975 , publisher=
work page 1975
-
[18]
International Conference on Learning Representations , year=
Learnability of convolutional neural networks for infinite dimensional input via mixed and anisotropic smoothness , author=. International Conference on Learning Representations , year=
-
[19]
On the frequentist properties of
Rousseau, Judith , journal=. On the frequentist properties of. 2016 , publisher=
work page 2016
- [20]
-
[21]
Deep learning is adaptive to intrinsic dimensionality of model smoothness in anisotropic
Suzuki, Taiji and Nitanda, Atsushi , booktitle=. Deep learning is adaptive to intrinsic dimensionality of model smoothness in anisotropic
-
[22]
International Conference on Machine Learning , pages=
Approximation and estimation ability of transformers for sequence-to-sequence functions with infinite dimensional input , author=. International Conference on Machine Learning , pages=
-
[23]
2024 IEEE Globecom Workshops (GC Wkshps) , pages=
Vaca-Rubio, Cristian J and Blanco, Luis and Pereira, Roberto and Caus, M. 2024 IEEE Globecom Workshops (GC Wkshps) , pages=. 2024 , organization=
work page 2024
-
[24]
Sub-Weibull distributions: Generalizing sub-Gaussian and sub-Exponential properties to heavier tailed distributions , author=. Stat , volume=. 2020 , publisher=
work page 2020
-
[25]
Ghosal, Subhashis and Van Der Vaart, Aad W , series=. Fundamentals of Nonparametric
-
[26]
Nonparametric regression using deep neural networks with
Schmidt-Hieber, Johannes , journal=. Nonparametric regression using deep neural networks with
-
[27]
Kratsios, Anastasis and Kim, Bum Jun and Furuya, Takashi , journal=. Approximation rates in. 2026 , publisher=
work page 2026
-
[28]
Fangzheng Xie and Yanxun Xu , title =. Bayesian Analysis , number =
-
[29]
International Conference on Learning Representations , year=
Adaptivity of deep ReLU network for learning in Besov and mixed smooth Besov spaces: optimal rate and curse of dimensionality , author=. International Conference on Learning Representations , year=
-
[30]
Asymptotic Properties for Bayesian Neural Network in Besov Space , year=
Lee, Kyeongwon and Lee, Jaeyong , volume=. Asymptotic Properties for Bayesian Neural Network in Besov Space , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.