Evolutionary Task Discovery: Advancing Reasoning Frontiers via Skill Composition and Complexity Scaling
Pith reviewed 2026-05-13 01:10 UTC · model grok-4.3
The pith
Evolutionary Task Discovery synthesizes novel reasoning tasks by composing skills and scaling complexity to improve large language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvoTD treats data synthesis as a directed search over a dual-axis manifold of Algorithmic Skills and Complexity Attributes. Structured evolutionary operators, including a Crossover operator that synthesizes novel skill compositions and a Parametric Mutation operator that scales structural constraints such as input size and tree depth, navigate this space. A dynamic Zone of Proximal Development filter ensures generated tasks remain within the model's learnable region. The result is training data that expands the reasoning frontier and produces substantial performance gains that hold across different model architectures, pretraining regimes, and scales.
What carries the argument
The dual-axis manifold of algorithmic skills and complexity attributes, navigated by a crossover operator for skill composition and a parametric mutation operator for scaling constraints, together with a dynamic zone of proximal development filter that selects learnable tasks.
If this is right
- Reasoning benchmarks improve when models train on tasks produced by the evolutionary process rather than standard or random synthesis.
- The gains appear across multiple model families and sizes, indicating the method is not tied to one architecture.
- Diversity in generated tasks stays higher than in unstructured approaches, reducing the risk of repetitive training data.
- The same operators can be reused to build curricula that scale with model capability.
Where Pith is reading between the lines
- The method could be paired with reinforcement learning from verifiable rewards to create combined training loops that alternate between task discovery and reward optimization.
- Similar evolutionary search might extend to domains like code generation or mathematical proof construction where skill composition also matters.
- Automating the definition of new skill primitives beyond the current operators could let the system discover entirely unexpected task types.
- If the filter works reliably, it offers a general recipe for keeping synthetic data effective as models grow larger.
Load-bearing premise
The crossover and parametric mutation operators plus the learnability filter can keep generating new task combinations that stay diverse and push reasoning boundaries instead of repeating similar patterns.
What would settle it
Running the same models on reasoning benchmarks after training on EvoTD data versus training on data from unstructured mutation methods shows no measurable difference in final performance.
Figures


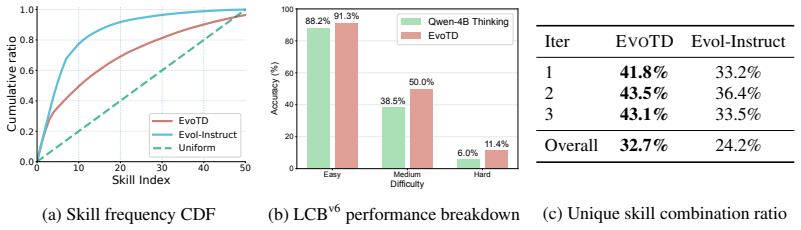




















read the original abstract
The reasoning frontier of Large Language Models (LLMs) has advanced significantly through modern post-training paradigms (e.g., Reinforcement Learning from Verifiable Rewards (RLVR)). However, the efficacy of these methods remains fundamentally constrained by the diversity and complexity of the training data. One practical solution is data synthesis; yet, prevalent methods relying on unstructured mutation or exploration suffer from homogeneity collapse, failing to systematically expand the reasoning frontier. To overcome this, we propose Evoutionary Task Discovery (EvoTD), a framework that treats data synthesis as a directed search over a dual-axis manifold of Algorithmic Skills and Complexity Attributes. We introduce structured evolutionary operators to navigate this space: a Crossover operator that synthesizes novel skill compositions to enhance diversity, and a Parametric Mutation operator that scales structural constraints (e.g., input size, tree depth) to drive robust generalization. Crucially, we integrate a dynamic Zone of Proximal Development filter, ensuring tasks lie within the learnable region of the model. Empirically, EvoTD delivers substantial reasoning gains that generalize consistently across model architectures, pretraining regimes, and scales, demonstrating that structured evolutionary curricula can effectively support reasoning improvement. We release our code on https://github.com/liqinye/EvoTD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Evolutionary Task Discovery (EvoTD), a framework that treats LLM data synthesis as directed evolutionary search over a dual-axis manifold of algorithmic skills and complexity attributes. It introduces a Crossover operator for novel skill compositions, a Parametric Mutation operator for scaling structural constraints such as input size and tree depth, and a dynamic Zone of Proximal Development (ZPD) filter to keep generated tasks within the model's learnable region. The central empirical claim is that EvoTD produces diverse tasks yielding substantial reasoning gains that generalize consistently across model architectures, pretraining regimes, and scales, outperforming unstructured synthesis methods by avoiding homogeneity collapse. Code is released at the provided GitHub link.
Significance. If the central claims are substantiated with controlled experiments, the work would be significant for LLM post-training research. It provides a structured evolutionary alternative to ad-hoc data synthesis, potentially enabling systematic expansion of the reasoning frontier. The public code release is a positive contribution for reproducibility. The significance depends on demonstrating that the proposed operators and filter deliver gains beyond what could be achieved by scaling data volume alone.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation section: The claim of consistent generalization across architectures and scales is load-bearing but lacks ablations that match total task count, skill coverage, and embedding diversity between EvoTD and baselines (e.g., random sampling or standard RLVR). Without these controls, observed gains could be explained by increased data scale rather than the Crossover, Parametric Mutation, and dynamic ZPD components.
- [Method] Method section (dual-axis manifold and ZPD filter): The dynamic ZPD filter is presented as crucial for preventing homogeneity collapse and ensuring tasks expand the frontier, yet no concrete metric, threshold, or model-specific quantification of the 'learnable region' is provided. This makes it impossible to verify that the filter systematically navigates the manifold or to reproduce the claimed avoidance of collapse.
minor comments (2)
- [Abstract] Abstract: 'Evoutionary' is a typographical error and should be corrected to 'Evolutionary'.
- [Experimental Evaluation] The manuscript would benefit from explicit diversity metrics (e.g., pairwise embedding distances or skill entropy) reported in tables comparing EvoTD outputs to baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for strengthening the experimental controls and methodological clarity. We address each major comment point by point below, outlining the revisions we will make to the next version of the paper.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The claim of consistent generalization across architectures and scales is load-bearing but lacks ablations that match total task count, skill coverage, and embedding diversity between EvoTD and baselines (e.g., random sampling or standard RLVR). Without these controls, observed gains could be explained by increased data scale rather than the Crossover, Parametric Mutation, and dynamic ZPD components.
Authors: We agree that isolating the contributions of the evolutionary operators from potential effects of data scale requires explicit controls. In the revised manuscript, we will add new ablation experiments that generate and train on exactly the same number of tasks for EvoTD and the baselines (random sampling and standard RLVR). We will also introduce quantitative metrics for skill coverage (proportion of distinct algorithmic skills represented) and embedding diversity (mean pairwise cosine similarity in a sentence-transformer embedding space). These additions will allow direct comparison showing that performance gains persist under matched scale and diversity conditions. We believe this strengthens the central claims without altering the reported results. revision: yes
-
Referee: [Method] Method section (dual-axis manifold and ZPD filter): The dynamic ZPD filter is presented as crucial for preventing homogeneity collapse and ensuring tasks expand the frontier, yet no concrete metric, threshold, or model-specific quantification of the 'learnable region' is provided. This makes it impossible to verify that the filter systematically navigates the manifold or to reproduce the claimed avoidance of collapse.
Authors: The referee is correct that the current description of the ZPD filter lacks sufficient operational detail for reproducibility. We will expand the Method section with a new subsection that defines the learnable region explicitly: for a given model, we compute success rates on a fixed 100-task validation set drawn from the manifold and set the ZPD bounds to the interval where success rate lies between 0.4 and 0.8, with the exact bounds updated every 500 generated tasks via a moving average. We will include the precise filtering equation, pseudocode, and model-specific threshold examples (e.g., for 7B and 70B models). This revision directly addresses the concern about verifiability and collapse avoidance. revision: yes
Circularity Check
No circularity: EvoTD is an independent empirical proposal
full rationale
The paper presents EvoTD as a new framework applying standard evolutionary operators (Crossover for skill composition, Parametric Mutation for complexity scaling) and a dynamic ZPD filter to navigate a dual-axis task manifold. No equations or derivations reduce to self-definition; the central claims rest on experimental results across architectures and scales rather than tautological fits or self-citation chains. The method is described as building on general evolutionary search principles without importing uniqueness theorems or ansatzes from prior author work as load-bearing. This is a standard self-contained empirical contribution.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The space of reasoning tasks can be represented as a navigable dual-axis manifold of Algorithmic Skills and Complexity Attributes.
- domain assumption Structured evolutionary operators (Crossover and Parametric Mutation) combined with a Zone of Proximal Development filter can avoid homogeneity collapse and expand the reasoning frontier.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
treats data synthesis as a directed search over a dual-axis manifold of Algorithmic Skills and Complexity Attributes... Crossover operator... Parametric Mutation... dynamic Zone of Proximal Development filter
-
IndisputableMonolith/Foundation/DimensionForcing.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
8-tick period... D=3... φ-powers
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/V1/2024.ACL-LONG.211. URL https://doi.org/10.18653/v1/2024. acl-long.211. Erik Hemberg, Stephen Moskal, and Una-May O’Reilly. Evolving code with a large language model. Genet. Program. Evolvable Mach., 25(2):21, 2024. doi: 10.1007/S10710-024-09494-2. URL https://doi.org/10.1007/s10710-024-09494-2. John H. Holland. Genetic algorithms and the ...
-
[2]
doi: 10.48550/ARXIV .2504.16891. URL https://doi.org/10.48550/arXiv.2504. 16891. 11 Alexander Novikov, Ngân Vu, Marvin Eisenberger, and et al. Alphaevolve: A coding agent for scientific and algorithmic discovery.CoRR, abs/2506.13131, 2025. doi: 10.48550/ARXIV .2506. 13131. URLhttps://doi.org/10.48550/arXiv.2506.13131. OpenAI. Openai GPT-5 system card.CoRR...
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[3]
A synthesized task:{task}
-
[4]
A list of target algorithmic skills:{skills}
-
[5]
A description for each skill:{skill_descriptions} EVALUATIONRULES • Answer “Yes” only if all listed skills are substantively involved in solving the task and interact in a unified way. • Answer “No” if the task looks like a glued combination of skills rather than a coherent multi-skill problem. • Answer “No” if any listed skill appears superficial, weakly...
-
[6]
A Python code snippet:{code}
-
[7]
A list of algorithmic skills:{skills}
-
[8]
Yes” only if every listed skill is genuinely used in the code’s core algorithmic logic. • Answer “No
A description for each skill:{skill_descriptions} EVALUATIONRULES 20 • Answer “Yes” only if every listed skill is genuinely used in the code’s core algorithmic logic. • Answer “No” if even one listed skill is not meaningfully applied. • Answer “No” if the code uses a different approach, even if the final output is correct. • Ignore helper boilerplate such...
work page 2024
-
[9]
TheATOMICalgorithmic skills needed to solve the problem
-
[10]
Thecomplexity attributes– all characteristics that affect the problem’s complexity/difficulty or could be varied to create mutations Your analysis must be precise, accurate, and adhere to the standardized terminology of the field. PART1: SKILLIDENTIFICATION 1.Holistic Analysis: You must consider both the problem statement and the provided solutions. • The...
-
[11]
Deduplicate: Merge overlapping or similar skills into a set of canonical, non-overlapping skills with clear, consolidated descriptions
-
[12]
Categorize: Group the resulting canonical skills into broader categories based on primary algorithmic concepts or data-structure families. INPUT You will be given a list of skills, where each skill has askillname and adescription. {skill_list} YOURTASK Step 1: Deduplicate into Canonical Skills (Mental Step) • First, mentally merge all synonymous, overlapp...
-
[13]
Examine existing combinations to understand what has already been done
-
[14]
Identify skills from the pool that naturally work with the target skill buthave not been combined yet
-
[15]
Create a code snippet where all chosen skills areessential and interconnectedto hide the true input while still producing the provided output. The key challenge is to ensure your skill combination is bothNEW(not in existing_combinations) andMEANINGFUL(skills genuinely complement each other, not forced). CODEREQUIREMENTS • The target skillmustbe the centra...
-
[16]
Analyzeexisting_combinationsto identify gaps
-
[17]
Propose a new skill combination with a clear justification
-
[18]
Devise a plan for how the skills interact to conceal the input
-
[19]
Implement the code snippet ensuring every skill is essential and requirements are met
-
[20]
Provide the hidden input that exercises the full combination. If there is previous failure information, address those issues explicitly in your new attempt. Figure 16: Abduction Task Crossover Prompt 35 Abduction Task Predictor Prompt TASK Provide One Possible Input of a Python Code Snippet Given the Code and Output Given the following Code Snippet and th...
-
[21]
Examining existing combinations to understand what has already been done
-
[22]
Identifying skills from the pool that would naturally work with the target skill but haven’t been combined yet
-
[23]
Creating a code snippet where all chosen skills are essential and interconnected to solve the problem The key challenge is to ensure your skill combination is both NEW (not in existing combinations) and MEANINGFUL (skills genuinely complement each other rather than being artificially forced together). CODEREQUIREMENTS • The target skill MUST be the centra...
-
[24]
First, analyze the existing combinations to understand patterns and identify gaps
-
[25]
Second, propose your new skill combination with clear justification
-
[26]
Third, devise a plan for how these skills will interact in your code
-
[27]
Fourth, implement the code snippet ensuring all skills are essential to the solution and following the code requirements
-
[28]
You are given an array of meeting times
Finally, create an input that exercises the full combination If there is previous failure information, address those issues explicitly in your new attempt. Figure 20: Deduction Task Crossover Prompt Deduction Task Predictor Prompt TASK 40 Deduce the Output of a Python Code Snippet Given the Code and Input Given the following Code Snippet and the Input, th...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.