Recognition: 1 theorem link
· Lean TheoremShapeCodeBench: A Renewable Benchmark for Perception-to-Program Reconstruction of Synthetic Shape Scenes
Pith reviewed 2026-05-13 01:15 UTC · model grok-4.3
The pith
ShapeCodeBench establishes a renewable synthetic benchmark for turning rendered shape images into exact executable drawing programs using a four-primitive DSL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
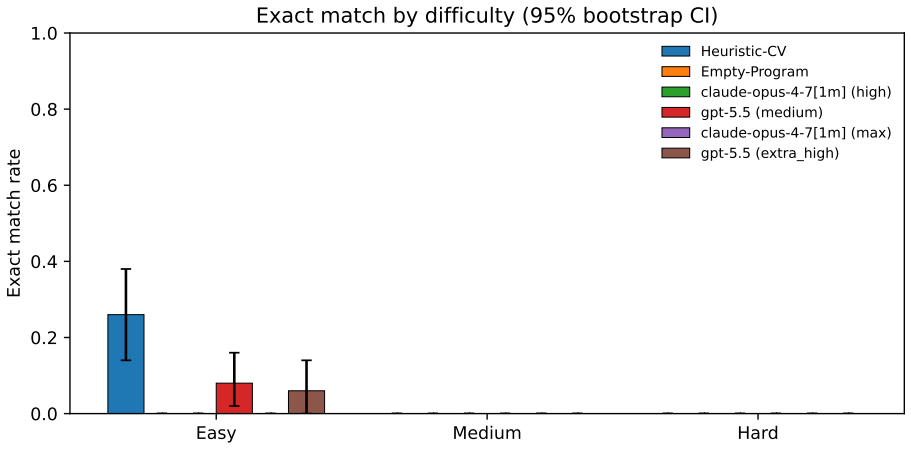
ShapeCodeBench is a benchmark for perception-to-program reconstruction in which a model receives a rendered image of shapes and must emit an executable drawing program in a four-primitive DSL on a 512 by 512 black-on-white canvas. The program is executed by a deterministic evaluator and compared to the target image using exact match, pixel accuracy, foreground IoU, parse success, and execution success. A frozen evaluation split containing 150 samples divided into easy, medium, and hard tiers is released, generated via seeded random number generator to support renewable held-out sets. Baselines including a classical heuristic and high-effort runs of Claude Opus and GPT-5.5 show competitive or
What carries the argument
ShapeCodeBench benchmark with its four-primitive DSL, seeded RNG generation for renewability, and multi-metric scoring of image-to-program reconstruction.
If this is right
- Exact match serves as a stricter success criterion than pixel-level or IoU metrics, forcing models to recover precise parameters rather than approximate appearances.
- Overlapping shapes expose a shared failure mode for both heuristic component separation and learned multimodal generation.
- The renewable nature of the benchmark allows repeated evaluation on fresh instances to track genuine generalization rather than memorization.
- Low exact-match performance across all tested systems indicates that parameter precision remains an open requirement for perception-to-program systems.
Where Pith is reading between the lines
- The benchmark format could be extended to real photographs or more complex drawing languages to test transfer from synthetic to natural scenes.
- Success on this task would imply progress toward vision models that can output editable symbolic representations rather than fixed pixel outputs.
- Tiered difficulty may help isolate whether failures stem from scene complexity, parameter estimation, or program structure.
Load-bearing premise
The four-primitive DSL together with the seeded generation procedure sufficiently captures the core difficulties of reconstructing accurate programs from visual shape scenes.
What would settle it
A model that reaches exact-match rates above 30 percent on the released frozen split while still performing poorly on newly generated held-out sets generated from the same seeded procedure would show whether the current low scores reflect a temporary gap or a deeper limitation of the benchmark design.
Figures



read the original abstract
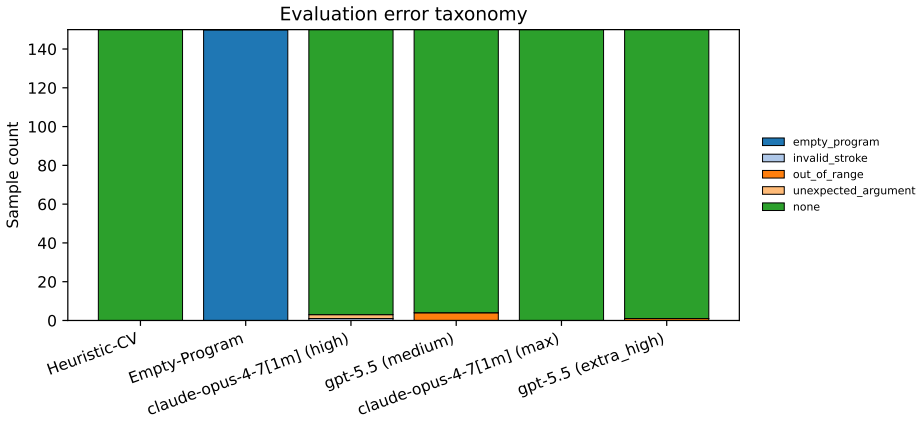
We introduce ShapeCodeBench, a synthetic benchmark for perception-to-program reconstruction: given a rendered raster image, a model must emit an executable drawing program that a deterministic evaluator re-renders and compares with the target. The v1 DSL has four primitives on a 512 x 512 black-on-white canvas, but every instance is generated from a seeded RNG, so fresh held-out sets can be created to reduce exact-instance contamination. We release a frozen eval_v1 split with 150 samples across easy, medium, and hard tiers, scored by exact match, pixel accuracy, foreground IoU, parse success, and execution success. We evaluate an empty-program floor, a classical computer-vision heuristic, Claude Opus 4.7 at high and max effort, and GPT-5.5 at medium and extra_high reasoning effort. The heuristic is competitive on easy scenes but collapses when overlaps fuse components; the strongest multimodal configuration preserves much of the foreground structure but still misses exact match because of small parameter errors. Best overall exact match remains low, so ShapeCodeBench is far from saturated. The benchmark code, frozen dataset, run artifacts, and paper sources are released to support independent replication and extension.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ShapeCodeBench, a synthetic benchmark for perception-to-program reconstruction: given a rendered raster image of shape scenes, models must output an executable drawing program in a v1 DSL with four primitives on a 512x512 black-on-white canvas. Instances are generated via seeded RNG to enable renewable fresh held-out sets that reduce exact-instance contamination. A frozen eval_v1 split of 150 samples across easy/medium/hard tiers is released and scored by exact match, pixel accuracy, foreground IoU, parse success, and execution success. Baselines evaluated include an empty-program floor, a classical computer-vision heuristic, Claude Opus 4.7 (high and max effort), and GPT-5.5 (medium and extra_high reasoning effort). Results show the heuristic competitive on easy scenes but failing on overlaps, while top multimodal models preserve foreground structure yet miss exact match due to small parameter errors; overall exact match remains low, so the benchmark is unsaturated.
Significance. If the benchmark design holds, it supplies a controlled, renewable, and contamination-resistant framework for evaluating structured visual reasoning and program synthesis, directly addressing a gap in existing perception-to-code tasks. The explicit release of benchmark code, frozen dataset, run artifacts, and paper sources is a clear strength that enables independent replication and extension. The empirical finding that even strong multimodal models achieve low exact-match rates while heuristics collapse on fused components provides a concrete, falsifiable signal that the task remains challenging and useful for driving progress.
minor comments (2)
- The paper would benefit from an explicit description (in §3 or the appendix) of how the easy/medium/hard tiers are defined in terms of scene parameters such as number of primitives, overlap count, or parameter ranges; this would make the difficulty scaling transparent without requiring inspection of the released code.
- Although run artifacts are released, the main text should include a concise summary of the exact prompting templates, temperature/reasoning-effort settings, and heuristic implementation details used for the reported Claude and GPT configurations; this is standard for reproducibility in model-evaluation papers even when code is available.
Simulated Author's Rebuttal
We thank the referee for the careful summary of ShapeCodeBench and for the positive assessment of its design as a renewable, contamination-resistant benchmark. We appreciate the recognition that the low exact-match rates highlight a challenging task and that the released artifacts support replication. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The paper introduces ShapeCodeBench as an empirical benchmark with a fixed DSL of four primitives, seeded RNG generation for renewability, a frozen 150-sample split, and standard metrics (exact match, pixel accuracy, IoU, parse/execution success). It reports evaluations on heuristics and multimodal models but contains no equations, derivations, fitted parameters, predictions, or self-citations that reduce any claim to its own inputs by construction. The central claims rest on the explicit construction of the benchmark and observed performance gaps, which are externally verifiable through the released code and dataset rather than internal self-reference.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearWe introduce ShapeCodeBench, a synthetic benchmark for perception-to-program reconstruction: given a rendered raster image, a model must emit an executable drawing program... The v1 DSL has four primitives on a 512 x 512 black-on-white canvas
Reference graph
Works this paper leans on
-
[1]
Closure: Assessing systematic generalization of clevr models.arXiv preprint arXiv:1912.05783, 2019
Dzmitry Bahdanau, Shikhar Murty, Michael Noukhovitch, Thien Huu Nguyen, Harm de Vries, and Aaron Courville. Closure: Assessing systematic generalization of clevr models.arXiv preprint arXiv:1912.05783, 2019
-
[2]
Tony Beltramelli. pix2code: Generating code from a graphical user interface screenshot.arXiv preprint arXiv:1705.07962, 2017
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI, Daya Guo, et al. Deepseek-r1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Parametric visual program induction with function modularization
Xuguang Duan, Xin Wang, Pengchuan Zhao, Guangyao Shen, and Wenwu Zhu. Parametric visual program induction with function modularization. InInternational Conference on Machine Learning (ICML), 2022
work page 2022
-
[5]
Gabriel Grand, Lionel Wong, Matthew Bowers, Theo X. Olausson, Muxin Liu, Joshua B. Tenenbaum, and Jacob Andreas. Lilo: Learning interpretable libraries by compressing and documenting code.arXiv preprint arXiv:2310.19791, 2024. 12
-
[6]
Lawrence Zitnick, and Ross Girshick
Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C. Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InConference on Computer Vision and Pattern Recognition (CVPR), 2017
work page 2017
- [7]
-
[8]
Yikai Li, Jiayuan Mao, Xiuming Zhang, William T. Freeman, Joshua B. Tenenbaum, and Jiajun Wu. Multi-plane program induction with 3d box priors.arXiv preprint arXiv:2011.10007, 2020
-
[9]
Yikai Li, Jiayuan Mao, Xiuming Zhang, William T. Freeman, Joshua B. Tenenbaum, and Jiajun Wu. Perspective plane program induction from a single image.arXiv preprint arXiv:2006.14708, 2020
-
[10]
Lin et al. Vcode: a multimodal coding benchmark with svg as symbolic visual representation. arXiv preprint arXiv:2511.02778, 2025
-
[11]
Rltf: Reinforcement learning from unit test feedback.arXiv preprint arXiv:2307.04349, 2023
Jiate Liu, Yiqin Zhu, Kaiwen Xiao, Qiang Fu, Xiao Han, Wei Yang, and Deheng Ye. Rltf: Reinforcement learning from unit test feedback.arXiv preprint arXiv:2307.04349, 2023
-
[12]
Yunchao Liu, Jiajun Wu, Zhijian Wu, Daniel Ritchie, William T. Freeman, and Joshua B. Tenenbaum. Learning to describe scenes with programs. InInternational Conference on Learning Representations (ICLR), 2019
work page 2019
-
[13]
Turtlebench: A visual programming benchmark in turtle geometry
Sina Rismanchian et al. Turtlebench: A visual programming benchmark in turtle geometry. arXiv preprint arXiv:2411.00264, 2025
-
[14]
Image2struct: Benchmarking structure extraction for vision-language models
Jonathan Roberts et al. Image2struct: Benchmarking structure extraction for vision-language models. InNeurIPS Datasets and Benchmarks, 2024
work page 2024
-
[15]
Csgnet: Neural shape parser for constructive solid geometry.arXiv preprint arXiv:1712.08290, 2018
Gopal Sharma, Rishabh Goyal, Difan Liu, Evangelos Kalogerakis, and Subhransu Maji. Csgnet: Neural shape parser for constructive solid geometry.arXiv preprint arXiv:1712.08290, 2018
-
[16]
Design2code: How far are we from automating front-end engineering? InarXiv, 2024
Chenglei Si, Yanzhe Zhang, Zhengyuan Yang, Ruibo Liu, and Diyi Yang. Design2code: How far are we from automating front-end engineering? InarXiv, 2024
work page 2024
-
[17]
Livebench: A challenging, contamination-free llm benchmark,
Colin White, Samuel Dooley, Manley Roberts, Arka Pal, Ben Feuer, Siddhartha Jain, Ravid Shwartz-Ziv, Neel Jain, Khalid Saifullah, Sreemanti Dey, Shubh-Agrawal, Sandeep Singh Sandha, Siddartha Naidu, Chinmay Hegde, Yann LeCun, Tom Goldstein, Willie Neiswanger, and Micah Goldblum. Livebench: A challenging, contamination-limited LLM benchmark.arXiv preprint ...
-
[18]
Zhiyuan Zeng, Hamish Ivison, Yiping Wang, Lifan Yuan, Shuyue Stella Li, Zhuorui Ye, Siting Li, Jacqueline He, Runlong Zhou, Tong Chen, Chenyang Zhao, Yulia Tsvetkov, Simon Shaolei Du, Natasha Jaques, Hao Peng, Pang Wei Koh, and Hannaneh Hajishirzi. Rlve: Scaling up reinforcement learning for language models with adaptive verifiable environments.arXiv prep...
-
[19]
Zhou et al. Omni-i2c: A holistic benchmark for high-fidelity image-to-code generation.arXiv preprint arXiv:2603.17508, 2026. 13 A Reproducibility Details The main paper reports model identifiers and reasoning-effort settings; this appendix records the operational path used for the reported sweeps. The full step-by-step workflow is maintained in docs/REPRO...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.