Recognition: no theorem link
Robust LLM Unlearning Against Relearning Attacks: The Minor Components in Representations Matter
Pith reviewed 2026-05-13 01:03 UTC · model grok-4.3
The pith
Targeting minor components in LLM representations makes unlearning resistant to relearning attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
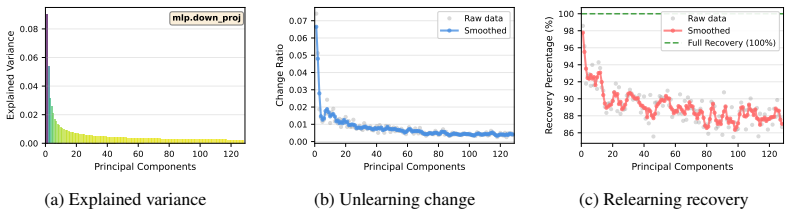
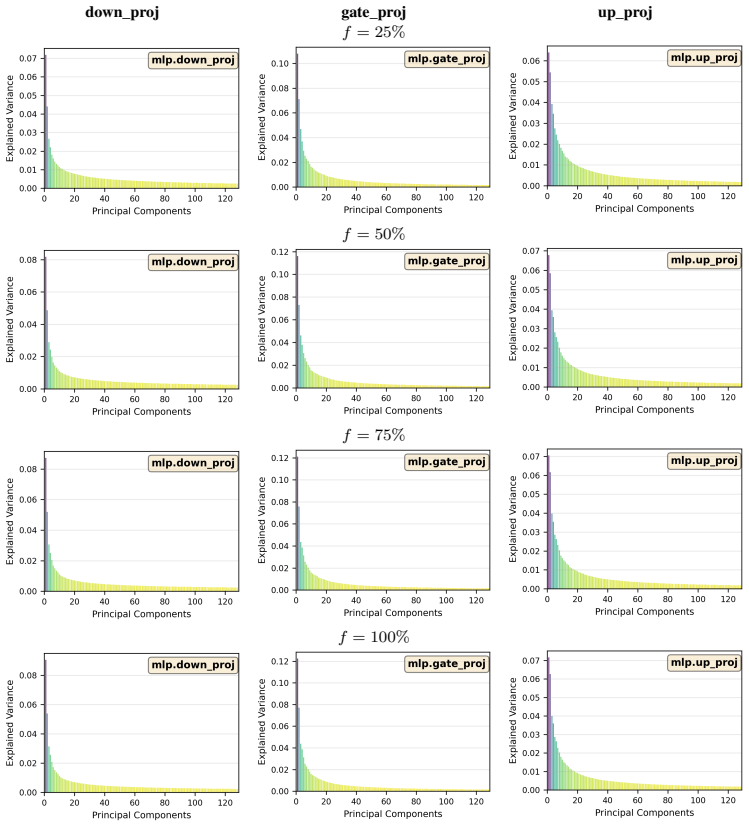
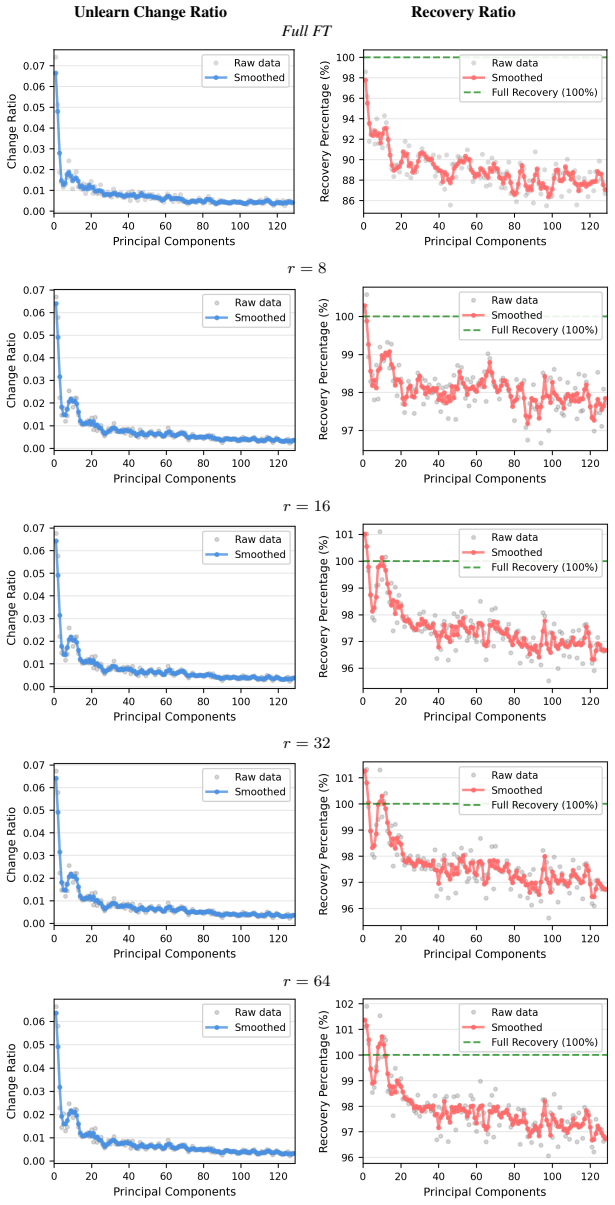
Existing unlearning methods predominantly optimize along dominant components of representations, leaving minor components largely unchanged. During relearning attacks, modifications in dominant components are easily reversed, enabling rapid knowledge recovery, whereas minor components exhibit stronger resistance to reversal. A theoretical analysis explains both observations from the spectral structure of representations. The proposed Minor Component Unlearning (MCU) explicitly targets these minor components, concentrating unlearning effects in inherently robust directions and thereby achieving substantially improved resistance to relearning attacks.
What carries the argument
Minor Component Unlearning (MCU), the technique that shifts the unlearning gradient to act primarily along the minor components of the model's representation vectors rather than the dominant ones.
If this is right
- Unlearned models retain deletion of target data even after multiple rounds of relearning on that data.
- Performance on privacy, copyright, and safety removal tasks improves over methods that only regularize dominant directions.
- The approach works on open-weight models where full retraining from scratch is impractical.
- The spectral explanation predicts that the resistance advantage scales with how small the targeted components are relative to the dominant subspace.
Where Pith is reading between the lines
- Representation geometry may offer a general lever for making other model edits, such as fine-tuning or alignment, more stable against reversal.
- Minor components could be monitored during training to detect when a model has internalized sensitive patterns that later need removal.
- The same spectral principle might apply to continual learning, where protecting previously learned minor directions could reduce catastrophic forgetting.
Load-bearing premise
Minor components in representations exhibit stronger resistance to reversal during relearning attacks because of the spectral structure of those representations.
What would settle it
Apply MCU to an unlearned model, then run the same relearning attack used on prior methods; if the forgotten knowledge is recovered at the same speed and accuracy as with dominant-component methods, the robustness claim is false.
Figures









read the original abstract
Large language model (LLM) unlearning aims to remove specific data influences from pre-trained model without costly retraining, addressing privacy, copyright, and safety concerns. However, recent studies reveal a critical vulnerability: unlearned models rapidly recover "forgotten" knowledge through relearning attacks. This fragility raises serious security concerns, especially for open-weight models. In this work, we investigate the fundamental mechanism underlying this fragility from a representation geometry perspective. We discover that existing unlearning methods predominantly optimize along dominant components, leaving minor components largely unchanged. Critically, during relearning attacks, the modifications in these dominant components are easily reversed, enabling rapid knowledge recovery, whereas minor components exhibit stronger resistance to such reversal. We further provide a theoretical analysis that explains both observations from the spectral structure of representations. Building on this insight, we propose Minor Component Unlearning (MCU), a novel unlearning approach that explicitly targets minor components in representations. By concentrating unlearning effects in these inherently robust directions, our method achieves substantially improved resistance to relearning attacks. Extensive experiments on three datasets validate our approach, demonstrating significant improvements over state-of-the-art methods including sharpness-aware minimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM unlearning is fragile to relearning attacks because existing methods predominantly optimize along dominant components in representations, which are easily reversed, while minor components exhibit stronger resistance due to the spectral structure of representations. It provides a theoretical analysis of this geometry, proposes Minor Component Unlearning (MCU) that explicitly targets minor components to concentrate unlearning effects in robust directions, and reports experimental validation on three datasets with improvements over SOTA methods including sharpness-aware minimization.
Significance. If the central claims hold with rigorous support, this would be a meaningful contribution to LLM unlearning by linking relearning vulnerability to representation geometry and offering a targeted method for improved robustness. The spectral-structure analysis, if it yields falsifiable quantitative predictions, and the MCU approach could inform more secure unlearning techniques for privacy and safety applications.
major comments (3)
- [Experiments] The central claim requires that minor components are inherently more resistant to reversal (due to spectral structure) and that targeting them yields robust unlearning. However, the manuscript contrasts MCU against SOTA methods without an ablation that applies an identical unlearning procedure while swapping only the targeted subspace (dominant vs. minor components). Without this isolation, observed gains could arise from MCU's selection, weighting, or regularization rather than intrinsic properties of minor directions.
- [Theoretical Analysis] § on theoretical analysis: the abstract states a theoretical analysis from spectral structure explaining both the dominance of existing methods and the resistance of minor components, but the available text provides no derivation steps, equations, or quantitative predictions for differential reversal rates under the same gradient steps. This leaves unclear whether the claimed robustness is independently derived or partly defined by the unlearning objective itself.
- [Abstract and Experiments] Abstract and Experiments section: the paper states 'significant improvements' and 'extensive experiments on three datasets' but provides no quantitative results, error bars, ablation details, or specific metrics in the available text, leaving the central claim unsupported.
minor comments (2)
- [Introduction] Clarify the precise definition of 'minor components' and 'dominant components' (e.g., via eigenvalue thresholds or variance explained) early in the manuscript to avoid ambiguity in the geometric claims.
- [Experiments] The reference to 'sharpness-aware minimization' as a baseline should include a brief citation and description of how it was adapted for unlearning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which highlight important aspects for strengthening the manuscript. We address each major comment below and will incorporate revisions to provide clearer isolation of effects, expanded theoretical derivations, and more detailed experimental reporting.
read point-by-point responses
-
Referee: [Experiments] The central claim requires that minor components are inherently more resistant to reversal (due to spectral structure) and that targeting them yields robust unlearning. However, the manuscript contrasts MCU against SOTA methods without an ablation that applies an identical unlearning procedure while swapping only the targeted subspace (dominant vs. minor components). Without this isolation, observed gains could arise from MCU's selection, weighting, or regularization rather than intrinsic properties of minor directions.
Authors: We agree that isolating the subspace choice is essential to substantiate the claim that robustness stems from the intrinsic properties of minor components rather than other aspects of the MCU procedure. In the revised manuscript, we will add a dedicated ablation study that applies an otherwise identical unlearning objective and optimization while targeting only the dominant components instead of the minor ones. This will directly compare reversal resistance under the same conditions and quantify the differential effect. revision: yes
-
Referee: [Theoretical Analysis] § on theoretical analysis: the abstract states a theoretical analysis from spectral structure explaining both the dominance of existing methods and the resistance of minor components, but the available text provides no derivation steps, equations, or quantitative predictions for differential reversal rates under the same gradient steps. This leaves unclear whether the claimed robustness is independently derived or partly defined by the unlearning objective itself.
Authors: We acknowledge that the current theoretical section would benefit from greater explicitness. The analysis derives the differential reversal rates from the eigenvalue decay in the representation covariance matrix, showing that dominant directions have larger eigenvalues and thus faster reversal under gradient updates, while minor directions have smaller eigenvalues leading to slower reversal. In the revision, we will include the full derivation steps, the key equations relating spectral norms to reversal speed, and quantitative predictions (e.g., expected reversal rate ratios as a function of eigenvalue ratios) that are independent of the specific unlearning loss. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the paper states 'significant improvements' and 'extensive experiments on three datasets' but provides no quantitative results, error bars, ablation details, or specific metrics in the available text, leaving the central claim unsupported.
Authors: The Experiments section of the full manuscript reports concrete metrics (e.g., relearning accuracy after attack, forget quality, and model utility) across three datasets with comparisons to SOTA baselines including sharpness-aware minimization. However, we agree that error bars from multiple random seeds, expanded ablation tables, and more explicit numerical values should be highlighted more clearly. We will revise both the abstract and Experiments section to include these details, standard deviations, and additional ablation results. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an empirical observation that existing unlearning methods affect dominant components while leaving minor ones unchanged, notes differential reversal rates under relearning attacks, supplies a spectral-structure theoretical analysis to explain the pattern, and introduces MCU to target the more resistant minor directions. This sequence does not reduce any claimed prediction or first-principles result to its own inputs by construction. No self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation chain is exhibited. The resistance property is treated as an observed fact explained by geometry rather than defined by the MCU objective itself, and the performance gains are validated experimentally against baselines. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Representations possess a spectral structure in which dominant and minor components respond differently to relearning attacks.
Reference graph
Works this paper leans on
- [1]
-
[2]
A. Deeb and F. Roger. Do unlearning methods remove information from language model weights? arXiv preprint arXiv:2410.08827,
-
[3]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
10 M. Kurmanji, P. Triantafillou, J. Hayes, and E. Triantafillou. Towards unbounded machine unlearning. Advances in neural information processing systems, 36:1957–1987,
work page 1957
- [5]
-
[6]
URLhttps://openreview.net/forum?id=J5IRyTKZ9s
ISSN 2835-8856. URLhttps://openreview.net/forum?id=J5IRyTKZ9s. A. Lynch, P. Guo, A. Ewart, S. Casper, and D. Hadfield-Menell. Eight methods to evaluate robust unlearning in llms.arXiv preprint arXiv:2402.16835,
-
[7]
URL https://hai.stanford.edu/ai-index/2024-ai-index-report . Seventh edition. Available as AI Index Report via arXiv:2405.19522. S. Merity, C. Xiong, J. Bradbury, and R. Socher. Pointer sentinel mixture models,
-
[8]
URL https: //arxiv.org/abs/2310.03693. R. Rafailov, A. Sharma, E. Mitchell, C. D. Manning, S. Ermon, and C. Finn. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems, 36:53728–53741,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2407.15549 , year=
A. Sheshadri, A. Ewart, P. Guo, A. Lynch, C. Wu, V . Hebbar, H. Sleight, A. C. Stickland, E. Perez, D. Hadfield-Menell, et al. Latent adversarial training improves robustness to persistent harmful behaviors in llms.arXiv preprint arXiv:2407.15549,
- [10]
-
[11]
11 F. Sondej and Y . Yang. Collapse of irrelevant representations (cir) ensures robust and non-disruptive llm unlearning.arXiv preprint arXiv:2509.11816,
-
[12]
R. Tamirisa, B. Bharathi, L. Phan, A. Zhou, A. Gatti, T. Suresh, M. Lin, J. Wang, R. Wang, R. Arel, et al. Tamper-resistant safeguards for open-weight llms.arXiv preprint arXiv:2408.00761,
-
[13]
Pratiksha Thaker, Yash Maurya, Shengyuan Hu, Zhiwei Steven Wu, and Virginia Smith
P. Thaker, Y . Maurya, S. Hu, Z. S. Wu, and V . Smith. Guardrail baselines for unlearning in llms. arXiv preprint arXiv:2403.03329,
-
[14]
A Limitations Our work has several aspects worth noting. First, our experimental evaluation focuses on relearning attacks, which represent the most practically relevant threat for open-weight models. Robustness against complementary attack vectors—such as inference-time jailbreaking [Łucki et al., 2025, Lynch et al., 2024] or quantization-induced knowledg...
work page 2025
-
[15]
investigated SAM to improve unlearning robustness through smoother loss landscapes. Despite these advances, the fundamental mechanism underlying unlearning fragility remains poorly understood, motivating our representation-centric analysis. D Theoretical Analysis: Full Derivations This appendix provides the detailed derivations supporting Theorems 1 and 2...
work page 2018
-
[16]
• Minor components: ρk ≈0 , since these directions encode sample-specific structure that varies idiosyncratically within each context. The batched relearning gradient averages out, the SNR collapses, and no amount of attacker fine-tuning onrelateddata can reliably reconstruct the minor-component values that the original model used for the held-out forget ...
work page 2011
-
[17]
TheYearsdataset [Deeb and Roger, 2024] consists of 20th-century events paired with their dates
containing 203 cyber and 144 biological multiple-choice questions, each augmented with three short declarative sentences per question that together form the forget set used for unlearning. TheYearsdataset [Deeb and Roger, 2024] consists of 20th-century events paired with their dates. As retain sets we use FineFineWeb [M-A-P et al., 2024] subsets matched t...
work page 2024
-
[18]
and smooth the relearning accuracy curve by averaging over windows of 10 epochs for WMDP datasets and 3 epochs for Years. The reportedRelearnaccuracy corresponds to the maximum smoothed accuracy across the relearning trajectory, as some attack runs may exceed the optimal number of epochs. Hyperparameter Selection for MCU.The key hyperparameter in our MCU ...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.