Recognition: no theorem link
Measuring What Matters Beyond Text: Evaluating Multimodal Summaries by Quality, Alignment, and Diversity
Pith reviewed 2026-05-13 07:04 UTC · model grok-4.3
The pith
MM-Eval integrates text quality, image-text alignment, and visual diversity into one calibrated framework for multimodal summaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
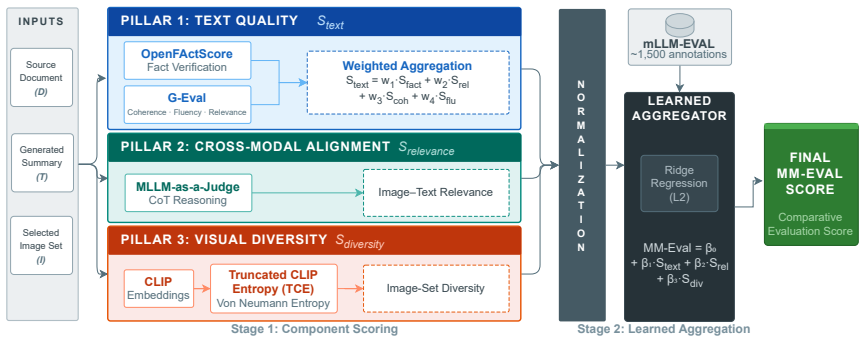
MM-Eval unifies evaluation of multimodal summaries through three components: text quality via OpenFActScore for factual consistency and G-Eval for coherence, fluency, and relevance; image-text relevance via an MLLM-as-a-judge method; and image-set diversity via Truncated CLIP Entropy. These are combined by a learned aggregation model trained on the mLLM-EVAL news benchmark so that the overall score tracks human preferences, revealing a text-dominant hierarchy in which factual consistency is the main driver while visual signals add complementary information.
What carries the argument
MM-Eval, the unified scoring framework that fuses specific text, alignment, and diversity metrics with a learned aggregation model trained to reproduce human judgments.
If this is right
- MM-Eval produces higher correlation with human judgments than heuristic ways of combining the same component scores.
- Factual consistency in the text part becomes the strongest single predictor of overall perceived quality.
- Image relevance and diversity scores supply additional information that improves the evaluation beyond text alone.
- The framework supports direct, reference-free comparisons among different multimodal summary systems.
Where Pith is reading between the lines
- The same aggregation approach could be tested on video or audio summaries to see whether the text-dominant pattern holds.
- Developers might first invest in text factuality improvements before refining image selection in their systems.
- The method could reduce the need for repeated human annotation by providing an automated yet human-aligned score.
- Extending the benchmark collection to more languages or domains would reveal how stable the learned weights remain.
Load-bearing premise
The mLLM-EVAL news benchmark and the learned aggregation model trained on it accurately reflect human preferences for multimodal summary quality across diverse domains and modalities.
What would settle it
Run a fresh human preference study on multimodal summaries drawn from non-news domains; if MM-Eval scores correlate with the new ratings no better than simple text-only baselines, the unified framework's advantage would be refuted.
Figures




read the original abstract
Multimodal Large Language Models (MLLMs) have facilitated Multimodal Summarization with Multimodal Output (MSMO), wherein systems generate concise textual summaries accompanied by salient visuals from multimodal sources. However, current MSMO evaluation remains fragmented: text quality, image-text alignment, and visual diversity are typically assessed in isolation using unimodal metrics, making it difficult to capture whether the modalities jointly support a faithful and useful summary. To address this gap, we introduce MM-Eval, a unified evaluation framework that integrates assessments of textual quality, cross-modal alignment, and visual diversity. MM-Eval comprises three components: (1) text quality, measured using OpenFActScore for factual consistency and G-Eval for coherence, fluency, and relevance; (2) image-text relevance, evaluated via an MLLM-as-a-judge approach; and (3) image-set diversity, quantified using Truncated CLIP Entropy. We calibrate MM-Eval through a learned aggregation model trained on the mLLM-EVAL news benchmark, aligning component contributions with human preferences. Our analysis reveals a text-dominant hierarchy in this setting, where factual consistency acts as a critical determinant of perceived overall quality, while visual relevance and diversity provide complementary signals. MM-Eval improves over heuristic aggregation baselines and provides an interpretable, reference-weak framework for comparative evaluation of multimodal summaries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MM-Eval, a unified evaluation framework for multimodal summarization with multimodal output (MSMO). It combines three components: text quality via OpenFActScore (factual consistency) and G-Eval (coherence, fluency, relevance); image-text relevance assessed by an MLLM-as-a-judge; and visual diversity via Truncated CLIP Entropy. These are aggregated through a learned model calibrated on the mLLM-EVAL news benchmark to align with human preferences. The work reports a text-dominant hierarchy in this setting, with factual consistency as the primary driver, and demonstrates improvement over heuristic aggregation baselines while providing an interpretable, reference-weak approach.
Significance. If the calibration proves robust beyond the single benchmark, MM-Eval would represent a meaningful advance in holistic MSMO evaluation by integrating fragmented unimodal metrics into a coherent, human-aligned score. The emphasis on component contributions and the text-dominant finding could inform system design priorities, while the reference-weak design supports practical deployment. The framework's interpretability is a clear strength relative to black-box alternatives.
major comments (2)
- Abstract: The learned aggregation model is central to the superiority claim over heuristic baselines, yet the manuscript provides no details on training procedure, validation splits, regularization, or sensitivity of the fitted weights; without these, it is impossible to determine whether reported gains reflect genuine improvement or post-hoc fitting to the mLLM-EVAL distribution.
- Abstract: The text-dominant hierarchy and component contribution analysis are derived exclusively from the news-only mLLM-EVAL benchmark; the absence of cross-domain human preference data or hold-out validation on other modalities/domains leaves open the possibility that the learned weights encode news-specific biases (e.g., heavy factual weighting) rather than general multimodal quality trade-offs.
minor comments (1)
- Abstract: The precise functional form of the aggregation model (linear weights, MLP, etc.) is not stated, which would aid reproducibility even at the high-level description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below, with revisions made to enhance reproducibility and transparency where possible.
read point-by-point responses
-
Referee: [—] Abstract: The learned aggregation model is central to the superiority claim over heuristic baselines, yet the manuscript provides no details on training procedure, validation splits, regularization, or sensitivity of the fitted weights; without these, it is impossible to determine whether reported gains reflect genuine improvement or post-hoc fitting to the mLLM-EVAL distribution.
Authors: We agree that the original manuscript provided insufficient detail on the learned aggregation model, which is central to our claims. In the revised version, we have expanded Section 3.4 and added a dedicated appendix subsection describing the full procedure: the model is a linear regressor trained via ordinary least squares with 5-fold cross-validation on the mLLM-EVAL benchmark (80/20 train/validation split per fold), L2 regularization (coefficient selected via grid search), and we now report the exact fitted weights, their standard deviations across folds, and a sensitivity analysis showing weight stability (variation under 8% across seeds and split ratios). These additions demonstrate that the reported gains arise from systematic calibration rather than post-hoc fitting. revision: yes
-
Referee: [—] Abstract: The text-dominant hierarchy and component contribution analysis are derived exclusively from the news-only mLLM-EVAL benchmark; the absence of cross-domain human preference data or hold-out validation on other modalities/domains leaves open the possibility that the learned weights encode news-specific biases (e.g., heavy factual weighting) rather than general multimodal quality trade-offs.
Authors: We acknowledge this as a genuine limitation of the current study. The mLLM-EVAL benchmark is news-focused, and the text-dominant hierarchy reflects human preferences in that domain. We have revised the manuscript to explicitly qualify all claims about the hierarchy and weights as news-specific, added a dedicated paragraph in the Discussion section on potential domain biases, and outlined future work on cross-domain collection. However, we do not have access to human preference annotations from other domains (e.g., scientific articles or social media), so empirical hold-out validation across domains cannot be performed in this revision. revision: partial
- Cross-domain validation of the learned aggregation weights, as no human preference data from non-news domains is currently available
Circularity Check
Learned aggregation weights fitted to mLLM-EVAL benchmark make superiority claim dependent on training data
specific steps
-
fitted input called prediction
[Abstract]
"We calibrate MM-Eval through a learned aggregation model trained on the mLLM-EVAL news benchmark, aligning component contributions with human preferences. Our analysis reveals a text-dominant hierarchy in this setting... MM-Eval improves over heuristic aggregation baselines"
The aggregation weights are optimized to match human ratings on the mLLM-EVAL benchmark; the reported improvement over heuristics and the text-dominant hierarchy are therefore evaluated on the identical training distribution, making the superiority statistically forced rather than independently demonstrated.
full rationale
The paper trains an aggregation model on the mLLM-EVAL news benchmark to align component scores with human preferences, then reports that the resulting MM-Eval improves over heuristic baselines and reveals a text-dominant hierarchy. This improvement is measured on the same benchmark used for fitting, so the central claim of superiority reduces to performance on the fitted data by construction. Individual metrics (OpenFActScore, G-Eval, CLIP entropy) are external, but the unified framework's advantage and interpretability rest on the calibration step. No hold-out or cross-domain validation is referenced, producing partial circularity in the evaluation claims.
Axiom & Free-Parameter Ledger
free parameters (1)
- aggregation model weights
axioms (1)
- domain assumption Human preferences on the mLLM-EVAL news benchmark are representative of general multimodal summary quality judgments.
Reference graph
Works this paper leans on
-
[1]
Ding, Xiaowen and Liu, Bing and Yu, Philip S , pages =. 2008 , booktitle =
work page 2008
-
[2]
Appel, Orestes and Chiclana, Francisco and Carter, Jenny and Fujita, Hamido , pages =. 2016 , journal =
work page 2016
-
[3]
Sarpiri, Mona Mona Mona Najafi and Gandomani, Taghi Javdani and Teymourzadeh, Mahsa and Motamedi, Akram , number =. 2018 , journal =
work page 2018
-
[4]
Wu, Chuhan and Wu, Fangzhao and Wu, Sixing and Yuan, Zhigang and Huang, Yongfeng , pages =. 2018 , journal =
work page 2018
-
[5]
Bajaj, Simran and Garg, Niharika and Singh, Sandeep Kumar , pages =. 2017 , journal =
work page 2017
-
[6]
Bajaj, Simran and Garg, Niharika and Singh, Sandeep Kumar , pages =. 2017 , booktitle =. doi:10.1016/j.procs.2017.11.467 , issn =
- [7]
-
[8]
ieeexplore.ieee.org , author =
- [9]
-
[10]
Gerani, Shima and Mehdad, Yashar and Carenini, Giuseppe and Ng, Raymond T and Nejat, Bita , pages =. 2014 , booktitle =
work page 2014
-
[11]
Naveed, Nasir and Gottron, Thomas and Rauf, Zahid , number =. 2018 , journal =
work page 2018
- [12]
-
[13]
doi:10.1016/j.eswa.2007.05.028 , keywords =
Elsevier , author =. doi:10.1016/j.eswa.2007.05.028 , keywords =
- [14]
-
[15]
Rafae, Abdul and Qayyum, Abdul and Moeenuddin, Muhammad and Karim, Asim and Sajjad, Hassan and Kamiran, Faisal , pages =. 2015 , booktitle =
work page 2015
- [16]
-
[17]
Liu, Jie and Fu, Xiaodong and Liu, Jin and Sun, Yunchuan , pages =. 2017 , journal =
work page 2017
-
[18]
Andrea, Alessia D ' and Ferri, Fernando and Grifoni, Patrizia , number =. 2015 , booktitle =
work page 2015
-
[19]
Chen, Ning and Lin, Jialiu and Hoi, Steven C.H. and Xiao, Xiaokui and Zhang, Boshen , number =. 2014 , booktitle =. doi:10.1145/2568225.2568263 , issn =
-
[20]
Poria, Soujanya and Cambria, Erik and Gelbukh, Alexander , pages =. 2016 , journal =
work page 2016
-
[21]
Maharani, Warih and Widyantoro, Dwi H and Khodra, Masayu Leylia , pages =. 2015 , journal =
work page 2015
- [22]
-
[23]
Khobragade, Shubhangi and Tiwari, Aditya and Patil, C Y and Narke, Vikram , pages =. 2016 , booktitle =
work page 2016
-
[24]
Jaeger, Stefan and Karargyris, Alexandros and Candemir, Sema and Folio, Les and Siegelman, Jenifer and Callaghan, Fiona and Xue, Zhiyun and Palaniappan, Kannappan and Singh, Rahul K and Antani, Sameer and. 2013 , journal =
work page 2013
-
[25]
Ahmad, Wan Siti Halimatul Munirah Wan and Zaki, Wan Mimi Diyana Wan and Fauzi, Mohammad Faizal Ahmad and Tan, Wooi Haw , pages =. 2016 , booktitle =
work page 2016
- [26]
-
[27]
Allahbakhsh, Mohammad and Ignjatovic, Aleksandar and Benatallah, Boualem and Bertino, Elisa and Foo, Norman and. 2013 , booktitle =
work page 2013
- [28]
-
[29]
Liu, Hugo and Singh, Push , number =. 2004 , journal =. doi:10.1023/B:BTTJ.0000047600.45421.6d , issn =
-
[30]
Aghakhani, Hojjat and Machiry, Aravind and Nilizadeh, Shirin and Kruegel, Christopher and Vigna, Giovanni , pages =. 2018 , booktitle =
work page 2018
-
[31]
Aghakhani, Hojjat and MacHiry, Aravind and Nilizadeh, Shirin and Kruegel, Christopher and Vigna, Giovanni , pages =. 2018 , booktitle =. doi:10.1109/SPW.2018.00022 , arxivId =
-
[32]
Mukherjee, Arjun and Liu, Bing and Wang, Junhui and Glance, Natalie and Jindal, Nitin , pages =. 2011 , booktitle =. doi:10.1145/1963192.1963240 , keywords =
-
[33]
Hu, Mengxiao and Xu, Guangxia and Ma, Chuang and Daneshmand, Mahmoud , pages =. 2019 , booktitle =
work page 2019
-
[34]
Wang, Zhuo and Hou, Tingting and Song, Dawei and Li, Zhun and Kong, Tianqi , number =. 2016 , journal =
work page 2016
-
[35]
academic.oup.com , author =
-
[36]
Xu, Guangxia and Qi, Jin and Huang, Deling and Daneshmand, Mahmoud , pages =. 2016 , booktitle =
work page 2016
-
[37]
Sharma, Abhishek and Raju, Daniel and Ranjan, Sutapa , pages =. 2017 , booktitle =
work page 2017
-
[38]
Heydari, Atefeh and Tavakoli, Mohammad ali and Salim, Naomie and Heydari, Zahra , number =. 2015 , journal =. doi:10.1016/j.eswa.2014.12.029 , issn =
- [39]
-
[40]
Mehmood, K and Essam, D and Shafi, K and Access, MK Malik - IEEE and 2019, Undefined , url =. 2019 , journal =
work page 2019
-
[41]
Li, Luyang and Qin, Bing and Ren, Wenjing and Liu, Ting , pages =. 2017 , journal =
work page 2017
-
[42]
dl.acm.org , author =
-
[43]
Chung, Junyoung and Gulcehre, Caglar and Cho, KyungHyun and Bengio, Yoshua , month =. 2014 , journal =
work page 2014
-
[44]
Araque, O and Corcuera-Platas, JF Sánchez-Rada , url =. 2017 , journal =
work page 2017
-
[45]
Fern. 2018 , booktitle =. doi:10.1007/978-3-030-03928-8
-
[46]
Luo, Zhiyi and Huang, Shanshan and Xu, Frank F and Lin, Bill Yuchen and Shi, Hanyuan and Zhu, Kenny , pages =. 2018 , booktitle =
work page 2018
- [47]
-
[48]
Mirtalaie, Monireh Alsadat and Hussain, Omar Khadeer and Chang, Elizabeth and Hussain, Farookh Khadeer , pages =. 2018 , journal =
work page 2018
-
[49]
Sinha, Anusha and Arora, Nishant and Singh, Shipra and Cheema, Mohita and Nazir, Akthar , number =. 2018 , journal =
work page 2018
- [50]
-
[51]
S., Neha and A., Anala , number =. 2018 , journal =. doi:10.5120/ijca2018917316 , keywords =
-
[52]
Dematis, Ioannis and Karapistoli, Eirini and Vakali, Athena , pages =. 2018 , booktitle =
work page 2018
- [53]
-
[54]
Bailey, James and Manoukian, Thomas and Ramamohanarao, Kotagiri , pages =. 2002 , booktitle =. doi:10.1007/3-540-45681-3
-
[55]
Deepa, N Vamsha and Krishna, Nanditha and Kumar, G Hemanth , pages =. 2017 , booktitle =
work page 2017
-
[56]
Naveed, N and Gottron, T and Staab, S , pages =. 2013 , booktitle =
work page 2013
-
[57]
Ott, Myle and Choi, Yejin and Cardie, Claire and Hancock, Jeffrey T , pages =. 2011 , booktitle =
work page 2011
-
[58]
Naveed, Nasir and Gottron, Thomas and Sizov, Sergej and Staab, Steffen , publisher =. 2012 , booktitle =
work page 2012
-
[59]
Wang, Zhuo and Gu, Songmin and Zhao, Xiangnan and Xu, Xiaowei , number =. 2018 , journal =
work page 2018
-
[60]
Xu, Guangxia and Hu, Mengxiao and Ma, Chuang and Daneshmand, Mahmoud , volume =. 2019 , booktitle =. doi:10.1109/ICC.2019.8761650 , issn =
-
[61]
Li, Xiaomeng and Chen, Hao and Qi, Xiaojuan and Dou, Qi and Fu, Chi-Wing and Heng, Pheng-Ann , number =. 2018 , journal =
work page 2018
- [62]
- [63]
-
[64]
Wu, Zhiang and Zhang, Lu and Wang, Youquan and Cao, Jie , pages =. 2018 , booktitle =. doi:10.1007/978-1-4939-7131-2
-
[65]
Saad, Mohd Nizam and Muda, Zurina and Ashaari, Noraidah Sahari and Hamid, Hamzaini Abdul , pages =. 2014 , booktitle =
work page 2014
- [66]
-
[67]
Ziegler, Cai-Nicolas and McNee, Sean M. and Konstan, Joseph A. and Lausen, Georg , pages =. 2005 , booktitle =
work page 2005
-
[68]
Chen, Tao and Xu, Ruifeng and He, Yulan and Wang, Xuan , pages =. 2017 , journal =
work page 2017
-
[69]
Kermany, Daniel and Zhang, Kang and Goldbaum, Michael , volume =. 2018 , journal =
work page 2018
- [70]
-
[71]
Syed, Afraz Z and Aslam, Muhammad and Martinez-Enriquez, Ana Maria , pages =. 2010 , booktitle =
work page 2010
-
[72]
Rehman, Zia Ul and Bajwa, Imran Sarwar , pages =. 2016 , booktitle =
work page 2016
-
[73]
Zotin, Aleksandr and Hamad, Yousif and Simonov, Konstantin and Kurako, Mikhail , pages =. 2019 , journal =
work page 2019
- [74]
- [75]
-
[76]
Singh, Manisha and Kumar, Lokesh and Sinha, Sapna , pages =. 2018 , booktitle =
work page 2018
-
[77]
Singh, Manisha and Kumar, Lokesh and Sinha, Sapna , pages =. 2018 , booktitle =. doi:10.1007/978-981-10-6602-3
-
[78]
Zhao, Jichang and Dong, Li and Wu, Junjie and Xu, Ke , pages =. 2012 , booktitle =. doi:10.1145/2339530.2339772 , keywords =
- [79]
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.