Recognition: no theorem link
ScaleMoGen: Autoregressive Next-Scale Prediction for Human Motion Generation
Pith reviewed 2026-05-13 06:20 UTC · model grok-4.3
The pith
ScaleMoGen generates human motions by autoregressively predicting discrete tokens from coarse to fine skeletal-temporal scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ScaleMoGen frames motion generation as autoregressive next-scale prediction: 3D motions are quantized into compositional discrete tokens across multiple skeletal-temporal scales of increasing granularity, and the model learns to generate motion by predicting the next-scale token maps. Motion tokenizers and quantizers are explicitly designed so that discrete tokens at every scale strictly preserve the skeletal hierarchy. Bitwise quantization and prediction are used to scale up the tokenizer vocabulary while preserving motion details and stabilizing optimization.
What carries the argument
scale-wise autoregressive prediction of next-scale token maps from multi-scale motion tokenizers that preserve skeletal hierarchy
Load-bearing premise
Quantizing 3D motions into compositional discrete tokens across multiple skeletal-temporal scales preserves the skeletal hierarchy and motion details without loss.
What would settle it
Generate motions on a held-out set of complex actions and measure whether the skeletal joint angles or bone lengths at the finest scale deviate from ground-truth values by more than the reported baseline error.
Figures





read the original abstract
We present ScaleMoGen, a scale-wise autoregressive framework for text-driven human motion generation. Unlike conventional autoregressive approaches that rely on standard next-token prediction, ScaleMoGen frames motion generation as a coarse-to-fine process. We quantize 3D motions into compositional discrete tokens across multiple skeletal-emporal scales of increasing granularity, learning to generate motion by autoregressively predicting next-scale token maps. To maintain structural integrity, our motion tokenizers and quantizers are explicitly designed so that discrete tokens at every scale strictly preserve the skeletal hierarchy. Additionally, we employ bitwise quantization and prediction, which efficiently scale up the tokenizer vocabulary to preserve motion details and stabilize optimization. Extensive experiments demonstrate that ScaleMoGen achieves state-of-the-art performance, establishing an FID of 0.030 (vs. 0.045 for MoMask) on HumanML3D and a CLIP Score of 0.693 (vs. 0.685 for MoMask++) on the SnapMoGen dataset. Furthermore, we demonstrate that our skeletal-temporal multi-scale representation naturally facilitates training-free, text-guided motion editing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScaleMoGen, a scale-wise autoregressive framework for text-driven human motion generation. Motions are quantized into compositional discrete tokens across multiple skeletal-temporal scales of increasing granularity; the model autoregressively predicts next-scale token maps while using bitwise quantization to enlarge vocabulary and stabilize optimization. Tokenizers are designed to preserve skeletal hierarchy at every scale. Experiments report SOTA results (FID 0.030 vs. MoMask 0.045 on HumanML3D; CLIP Score 0.693 vs. MoMask++ 0.685 on SnapMoGen) and demonstrate training-free text-guided editing.
Significance. If the multi-scale quantization and bitwise scheme function as described, the work supplies a concrete coarse-to-fine autoregressive alternative to standard next-token motion models, with measurable metric gains and a practical editing capability that prior single-scale tokenizers lack. The explicit hierarchy-preserving design and empirical comparisons constitute the primary strengths.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the reported FID improvement (0.030 vs. 0.045) and CLIP-score gain are presented without error bars, multiple random seeds, or explicit dataset-split details; this weakens the claim that the multi-scale construction is responsible for the gains rather than training-protocol differences.
- [§3.2] §3.2 (Motion Tokenizer): the statement that tokens at every scale 'strictly preserve the skeletal hierarchy' is load-bearing for the central claim yet lacks an explicit equation or algorithm showing how the compositional quantization enforces this property (e.g., no definition of the per-scale skeletal constraint or proof of invariance under bitwise operations).
minor comments (2)
- [§3.3] §3.3: clarify the exact vocabulary sizes chosen for bitwise quantization and report an ablation on the number of skeletal-temporal scales, as these are the two free parameters listed in the design.
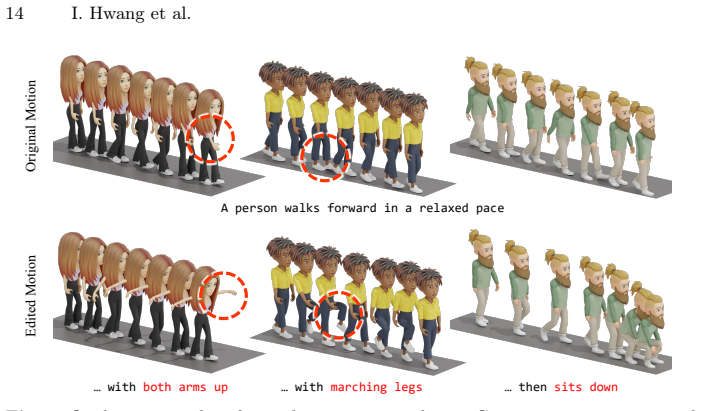
- [Figure 3 and §4.3] Figure 3 and §4.3: the qualitative editing examples would benefit from side-by-side comparison with a fine-tuned baseline to illustrate the training-free advantage.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and will revise the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported FID improvement (0.030 vs. 0.045) and CLIP-score gain are presented without error bars, multiple random seeds, or explicit dataset-split details; this weakens the claim that the multi-scale construction is responsible for the gains rather than training-protocol differences.
Authors: We agree that reporting error bars, multiple random seeds, and explicit dataset-split details would strengthen the statistical robustness of the results. In the revised version, we will add standard deviations computed over at least three independent runs with different seeds, clarify the exact train/validation/test splits used on HumanML3D and SnapMoGen, and include a brief discussion confirming that all baselines were re-evaluated under identical protocols. While the primary gains are attributable to the multi-scale architecture (as supported by our ablation studies), we acknowledge that these additions will better isolate the contribution of the proposed components from training variations. revision: yes
-
Referee: [§3.2] §3.2 (Motion Tokenizer): the statement that tokens at every scale 'strictly preserve the skeletal hierarchy' is load-bearing for the central claim yet lacks an explicit equation or algorithm showing how the compositional quantization enforces this property (e.g., no definition of the per-scale skeletal constraint or proof of invariance under bitwise operations).
Authors: We concur that an explicit mathematical formulation is needed to substantiate this key property. The preservation arises because each scale's tokenizer operates on a hierarchical skeletal graph where parent joints are quantized before children, and bitwise quantization is applied independently per scale without cross-scale mixing. In the revision, we will insert a formal definition in §3.2 (including the per-scale constraint equation and a short invariance argument under bitwise operations) together with a pseudocode outline of the quantization algorithm to make the enforcement mechanism fully transparent. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces ScaleMoGen as a new autoregressive framework that quantizes motions into multi-scale discrete tokens and predicts next-scale maps, with performance validated through direct empirical comparisons (FID, CLIP scores) against prior published methods on HumanML3D and SnapMoGen. No equations or derivations are presented that reduce predictions or results to fitted parameters defined by the same inputs, self-citations that bear the central claim, or ansatzes smuggled via prior author work. The quantization design is described as explicitly constructed to preserve hierarchy, but this is an architectural choice evaluated externally rather than a tautological self-definition. The approach is self-contained against benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of skeletal-temporal scales
- bitwise quantization vocabulary size
axioms (1)
- domain assumption Discrete tokens at every scale strictly preserve the skeletal hierarchy
invented entities (1)
-
compositional discrete tokens across multiple skeletal-temporal scales
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: SIGGRAPH Asia 2024 Conference Pa- pers (2024) 4
Athanasiou, N., Ceske, A., Diomataris, M., Black, M.J., Varol, G.: MotionFix: Text-driven 3d human motion editing. In: SIGGRAPH Asia 2024 Conference Pa- pers (2024) 4
work page 2024
-
[2]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Bae, J., Hwang, I., Lee, Y.Y., Guo, Z., Liu, J., Ben-Shabat, Y., Kim, Y.M., Kapa- dia, M.: Less is more: Improving motion diffusion models with sparse keyframes. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 11069–11078 (October 2025) 3
work page 2025
-
[3]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, X., Jiang, B., Liu, W., Huang, Z., Fu, B., Chen, T., Yu, G.: Executing your commands via motion diffusion in latent space. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 18000–18010 (2023) 1, 3, 10, 12
work page 2023
-
[4]
Ghosh, A., Zhou, B., Dabral, R., Wang, J., Golyanik, V., Theobalt, C., Slusallek, P., Guo, C.: Duetgen: Music driven two-person dance generation via hierarchical masked modeling. In: ACM SIGGRAPH (2025) 2, 3
work page 2025
-
[5]
Guo, C., Hwang, I., Wang, J., Zhou, B.: Snapmogen: Human motion generation from expressive texts. In: The Thirty-ninth Annual Conference on Neural Informa- tion Processing Systems (2025),https://openreview.net/forum?id=pdE9onSn2h 2, 3, 10, 11, 12, 18, 20
work page 2025
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Guo, C., Mu, Y., Javed, M.G., Wang, S., Cheng, L.: Momask: Generative masked modeling of 3d human motions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1900–1910 (2024) 2, 3, 10, 12
work page 1900
-
[7]
In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition
Guo, C., Zou, S., Zuo, X., Wang, S., Ji, W., Li, X., Cheng, L.: Generating diverse and natural 3d human motions from text. In: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition. pp. 5152–5161 (2022) 1, 2, 3, 10, 12, 20
work page 2022
-
[8]
In: European Conference on Computer Vision
Guo, C., Zuo, X., Wang, S., Cheng, L.: Tm2t: Stochastic and tokenized model- ing for the reciprocal generation of 3d human motions and texts. In: European Conference on Computer Vision. pp. 580–597. Springer (2022) 2, 3, 10, 12
work page 2022
-
[9]
In: Proceedings of the 28th ACM International Conference on Multimedia
Guo, C., Zuo, X., Wang, S., Zou, S., Sun, Q., Deng, A., Gong, M., Cheng, L.: Action2motion: Conditioned generation of 3d human motions. In: Proceedings of the 28th ACM International Conference on Multimedia. pp. 2021–2029 (2020) 3, 10
work page 2021
-
[10]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Han, J., Liu, J., Jiang, Y., Yan, B., Zhang, Y., Yuan, Z., Peng, B., Liu, X.: In- finity: Scaling bitwise autoregressive modeling for high-resolution image synthesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 15733–15744 (June 2025) 4 16 I. Hwang et al
work page 2025
-
[11]
In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2025) 2, 4
Han, S.H.K., et al.: Bad: Bidirectional auto-regressive diffusion for text-to-motion generation. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2025) 2, 4
work page 2025
-
[12]
Scaling Laws for Autoregressive Generative Modeling
Henighan, T., Kaplan, J., Katz, M., Chen, M., Hesse, C., Jackson, J., Jun, H., Brown, T.B., Dhariwal, P., Gray, S., et al.: Scaling laws for autoregressive genera- tive modeling. arXiv preprint arXiv:2010.14701 (2020) 13
work page internal anchor Pith review arXiv 2010
-
[13]
In: European Conference on Computer Vision (ECCV) (2024) 8
Heo, B., Park, S., Han, D., Yun, S.: Rotary position embedding for vision trans- former. In: European Conference on Computer Vision (ECCV) (2024) 8
work page 2024
-
[14]
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control (2022) 4
work page 2022
-
[15]
Ho, J., Salimans, T.: Classifier-free diffusion guidance (2022),https://arxiv.org/ abs/2207.1259820
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)
Hong, S., Kim, C., Yoon, S., Nam, J., Cha, S., Noh, J.: Salad: Skeleton-aware latent diffusion for text-driven motion generation and editing. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR). pp. 7158–7168 (June 2025) 3, 4, 10, 11, 12, 13, 14, 18
work page 2025
-
[17]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Huang, Y., Yang, H., Luo, C., Wang, Y., Xu, S., Zhang, Z., Zhang, M., Peng, J.: Stablemofusion: Towards robust and efficient diffusion-based motion genera- tion framework. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 224–232 (2024) 10, 12
work page 2024
-
[18]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Workshops
Hwang, I., Bae, J., Lim, D., Kim, Y.M.: Goal-driven human motion synthesis in diverse task. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Workshops. pp. 2920–2930 (June 2025) 3
work page 2025
-
[19]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Hwang, I., Bae, J., Lim, D., Kim, Y.M.: Motion synthesis with sparse and flexible keyjoint control. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 13203–13213 (October 2025) 3
work page 2025
-
[20]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV)
Hwang,I.,Zhou,B.,Kim,Y.M.,Wang,J.,Guo,C.:Scenemi:Motionin-betweening for modeling human-scene interaction. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). pp. 6034–6045 (October 2025) 3
work page 2025
-
[21]
Advances in Neural Information Processing Systems36, 20067–20079 (2023) 2, 3
Jiang, B., Chen, X., Liu, W., Yu, J., Yu, G., Chen, T.: Motiongpt: Human motion as a foreign language. Advances in Neural Information Processing Systems36, 20067–20079 (2023) 2, 3
work page 2023
-
[22]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Kim, J., Kim, J., Choi, S.: Flame: Free-form language-based motion synthesis & editing. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 8255–8263 (2023) 4
work page 2023
-
[23]
ACM Transactions on Graphics (TOG)41(4), 1–12 (2022) 2
Li, P., Aberman, K., Zhang, Z., Hanocka, R., Sorkine-Hornung, O.: Ganimator: Neural motion synthesis from a single sequence. ACM Transactions on Graphics (TOG)41(4), 1–12 (2022) 2
work page 2022
-
[24]
Li, Z., Cheng, K., Ghosh, A., Bhattacharya, U., Gui, L., Bera, A.: Simmotionedit: Text-based human motion editing with motion similarity prediction (2025) 4
work page 2025
-
[25]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Lu, S., Wang, J., Lu, Z., Chen, L.H., Dai, W., Dong, J., Dou, Z., Dai, B., Zhang, R.: Scamo: Exploring the scaling law in autoregressive motion generation model. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 27872–27882 (2025) 1, 13
work page 2025
-
[26]
In: Proceedings of the IEEE/CVF international conference on computer vision
Mahmood, N., Ghorbani, N., Troje, N.F., Pons-Moll, G., Black, M.J.: Amass: Archive of motion capture as surface shapes. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5442–5451 (2019) 10
work page 2019
-
[27]
In: International Conference on Learning Representations (2022) 4 ScaleMoGen 17
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: SDEdit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations (2022) 4 ScaleMoGen 17
work page 2022
-
[28]
Rethinking diffusion for text-driven human motion generation.arXiv preprint arXiv:2411.16575, 2024
Meng, Z., Xie, Y., Peng, X., Han, Z., Jiang, H.: Rethinking diffusion for text-driven human motion generation. arXiv preprint arXiv:2411.16575 (2024) 1, 3, 10, 12
-
[29]
In: European Conference on Computer Vision
Petrovich, M., Black, M.J., Varol, G.: Temos: Generating diverse human motions from textual descriptions. In: European Conference on Computer Vision. pp. 480–
-
[30]
Springer (2022) 1, 3
work page 2022
-
[31]
In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision
Petrovich, M., Black, M.J., Varol, G.: Tmr: Text-to-motion retrieval using con- trastive 3d human motion synthesis. In: Proceedings of the IEEE/CVF Interna- tional Conference on Computer Vision. pp. 9488–9497 (2023) 10
work page 2023
-
[32]
In: Computer Vision – ECCV 2024 (2024) 2, 4
Pinyoanuntapong, E., Saleem, M.U., Wang, P., Lee, M., Das, S., Chen, C.: Bamm: Bidirectional autoregressive motion model. In: Computer Vision – ECCV 2024 (2024) 2, 4
work page 2024
-
[33]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pinyoanuntapong, E., Wang, P., Lee, M., Chen, C.: Mmm: Generative masked motion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1546–1555 (2024) 2, 3, 10, 12
work page 2024
-
[34]
Journal of Machine Learning Research21(140), 1–67 (2020), http://jmlr.org/papers/v21/20-074.html7
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text- to-text transformer. Journal of Machine Learning Research21(140), 1–67 (2020), http://jmlr.org/papers/v21/20-074.html7
work page 2020
- [35]
-
[36]
Tevet, G., Raab, S., Gordon, B., Shafir, Y., Cohen-Or, D., Bermano, A.H.: Human motion diffusion model. arXiv preprint arXiv:2209.14916 (2022) 1, 3, 10, 12, 13, 14, 18
work page internal anchor Pith review arXiv 2022
-
[37]
Tian, K., Jiang, Y., Yuan, Z., PENG, B., Wang, L.: Visual autoregressive model- ing: Scalable image generation via next-scale prediction. In: The Thirty-eighth Annual Conference on Neural Information Processing Systems (2024),https: //openreview.net/forum?id=gojL67CfS84, 20
work page 2024
-
[38]
Advances in neural information processing systems30(2017) 1, 3
Van Den Oord, A., Vinyals, O., et al.: Neural discrete representation learning. Advances in neural information processing systems30(2017) 1, 3
work page 2017
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Wang, Y., Guo, L., Li, Z., Huang, J., Wang, P., Wen, B., Wang, J.: Training- free text-guided image editing with visual autoregressive model. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 17577– 17586 (October 2025) 4, 10
work page 2025
-
[40]
Neural In- formation Processing Systems (NeurIPS) (2024) 2, 3, 10, 12, 13, 18
Yuan, W., Shen, W., HE, Y., Dong, Y., Gu, X., Dong, Z., Bo, L., Huang, Q.: Mogents: Motion generation based on spatial-temporal joint modeling. Neural In- formation Processing Systems (NeurIPS) (2024) 2, 3, 10, 12, 13, 18
work page 2024
-
[41]
arXiv preprint arXiv:2301.06052 (2023) 2, 3, 10, 12, 18
Zhang, J., Zhang, Y., Cun, X., Huang, S., Zhang, Y., Zhao, H., Lu, H., Shen, X.: T2m-gpt: Generating human motion from textual descriptions with discrete representations. arXiv preprint arXiv:2301.06052 (2023) 2, 3, 10, 12, 18
-
[42]
Motiondiffuse: Text-driven human motion generation with diffusion model
Zhang, M., Cai, Z., Pan, L., Hong, F., Guo, X., Yang, L., Liu, Z.: Motiondif- fuse: Text-driven human motion generation with diffusion model. arXiv preprint arXiv:2208.15001 (2022) 1, 3, 10, 12
- [43]
-
[44]
Advances in Neural Information Processing Systems36, 13981–13992 (2023) 2, 4
Zhang, M., Li, H., Cai, Z., Ren, J., Yang, L., Liu, Z.: Finemogen: Fine-grained spatio-temporal motion generation and editing. Advances in Neural Information Processing Systems36, 13981–13992 (2023) 2, 4
work page 2023
-
[45]
Zhao, Y., Xiong, Y., Krähenbühl, P.: Image and video tokenization with binary spherical quantization. arXiv preprint arXiv:2406.07548 (2024) 2, 6 18 I. Hwang et al. In the supplementary materials, we evaluate sampling efficiency (Section A), and provide implementation details on the model architecture and algorithm (Section B). We further analyze the prop...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.