Recognition: 1 theorem link
· Lean TheoremCAST: Collapse-Aware multi-Scale Topology Fusion for Multimodal Coreset Selection
Pith reviewed 2026-05-13 06:14 UTC · model grok-4.3
The pith
CAST selects multimodal coresets that preserve cross-modal semantics more effectively through topology fusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAST constructs image- and text-modality topologies, derives a unified topology via local-collapse-aware refinement and cross-modal fusion, then applies multi-scale distribution matching in the diffusion wavelet domain along with local soft relational coverage to produce a coreset that approximates the original multimodal dataset in global structure, local details, and redundancy-aware coverage.
What carries the argument
Collapse-aware multi-scale topology fusion, which builds modality-specific topologies, refines them to avoid local collapse, fuses them cross-modally, and matches distributions at multiple scales.
If this is right
- The selected coreset maintains closer distributional equivalence to the full dataset than single-modality or scoring-based methods.
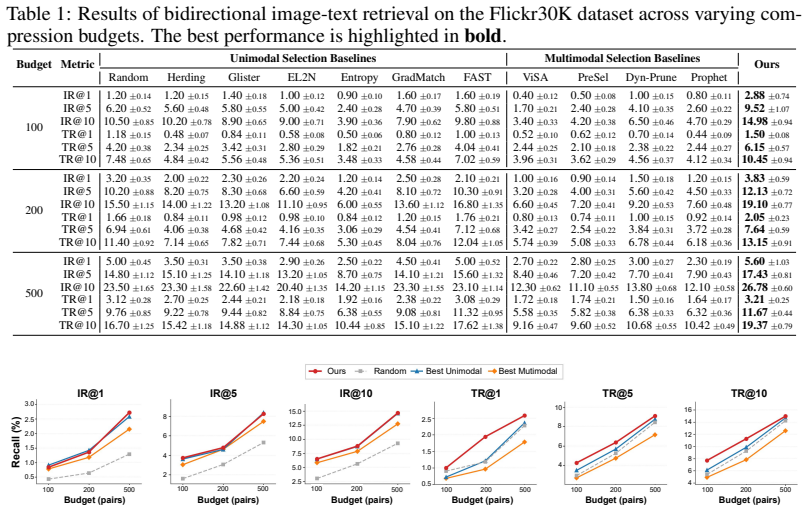
- Models trained on the CAST coreset achieve higher accuracy on Flickr30K and MS-COCO benchmarks.
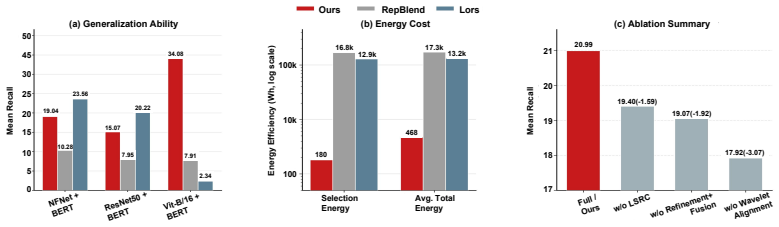
- The coreset generalizes better when transferred to different model architectures.
- Training requires lower energy than methods that rely on multimodal data synthesis.
- Global structure, local fine-grained details, and redundancy in dense regions are jointly addressed in the selection process.
Where Pith is reading between the lines
- The same topology fusion idea could be tested on video-audio or other paired multimodal data to check broader applicability.
- Multi-scale matching might surface which semantic resolutions matter most for a given dataset's utility.
- Widespread adoption would lower the total data volume and carbon cost of training large multimodal systems.
- Extending the relational coverage term to explicit bias metrics could help surface and reduce unwanted correlations in the original data.
Load-bearing premise
That constructing and fusing modality-specific topologies with collapse-aware refinement will capture fine-grained cross-modal semantics without introducing new biases or semantic loss.
What would settle it
If a coreset chosen by CAST on MS-COCO yields no measurable improvement in downstream task performance or multi-scale distribution match scores over random selection or prior baselines, the central claim would be falsified.
Figures



read the original abstract
The training of large multimodal models fundamentally relies on massive image-text datasets, which inevitably incur prohibitive computational overhead. Dataset selection offers a promising paradigm by identifying a highly informative coreset. However, existing approaches suffer from two critical limitations: (i) single-modality-dominated sampling methods, which ignore the fine-grained cross-modal information imbalance inherent in multimodal datasets and thus lead to semantic loss in the other modality; and (ii) coarse-grained sample-scoring-based sampling methods, where the selected coreset tends to be biased toward the scoring model, making it difficult to guarantee distributional equivalence between the coreset and the original dataset. Meanwhile, existing distribution matching and discrete sampling strategies often fail to jointly account for global semantic structure, local fine-grained details, and redundancy-aware coverage in dense regions. To this end, we propose CAST, a Collapse-Aware multi-Scale Topology fusion framework for multimodal coreset selection. We first construct image- and text-modality topologies, and derive a unified topology via local-collapse-aware refinement and cross-modal fusion. We then introduce a multi-scale distribution matching criterion in the diffusion wavelet domain, encouraging the coreset to approximate the original dataset at multiple scales. Finally, we introduce a local soft relational coverage mechanism that extends pure geometric coverage to relation-aware indirect coverage, penalizing redundant selections in dense clusters. Extensive experiments on Flickr30K and MS-COCO show that CAST outperforms existing dataset selection baselines, showcasing great superiority in cross-architecture generalization and energy efficiency over state-of-the-art multimodal synthesis methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CAST, a Collapse-Aware multi-Scale Topology fusion framework for multimodal coreset selection. It constructs image- and text-modality topologies, derives a unified topology via local-collapse-aware refinement and cross-modal fusion, applies multi-scale distribution matching in the diffusion wavelet domain to encourage the coreset to approximate the original dataset at multiple scales, and introduces a local soft relational coverage mechanism to penalize redundant selections in dense clusters. The central claim is that CAST outperforms existing dataset selection baselines on Flickr30K and MS-COCO, with superiority in cross-architecture generalization and energy efficiency over state-of-the-art multimodal synthesis methods.
Significance. If the empirical claims hold under rigorous verification, the work would be significant for efficient training of large multimodal models. By jointly addressing cross-modal information imbalance through topology fusion and multi-scale distributional fidelity via diffusion wavelets, it offers a principled alternative to single-modality or coarse scoring approaches, potentially reducing computational overhead while preserving semantic structure. The local soft relational coverage extends geometric coverage in a relation-aware manner, which could influence future coreset methods if the wavelet-based matching is shown to avoid semantic loss.
major comments (2)
- [§3] §3 (Method, multi-scale distribution matching): The multi-scale distribution matching criterion in the diffusion wavelet domain is presented without a derivation, approximation error bound, or analysis of how the local-collapse-aware refinement and cross-modal fusion affect the eigenstructure of the diffusion operator. This is load-bearing for the distributional equivalence claim, as the skeptic correctly notes that wavelet coefficients may not faithfully represent the joint image-text distribution if the fused topology is irregular.
- [§4] §4 (Experiments): The abstract asserts outperformance on Flickr30K and MS-COCO with superiority in cross-architecture generalization and energy efficiency, but the provided text contains no quantitative metrics, baseline details, ablation studies isolating the wavelet matching or coverage components, or error analysis. This prevents verification of the central claim that the method reliably captures fine-grained cross-modal semantics without new biases.
minor comments (2)
- [Abstract] The abstract introduces 'local soft relational coverage' and 'diffusion wavelet domain' without reference to the specific equations or algorithmic steps that define them, which reduces clarity for readers unfamiliar with the graph construction details.
- [Abstract] No mention of the specific baselines used for comparison (e.g., which single-modality or synthesis methods) or the exact metrics for 'energy efficiency' (e.g., FLOPs, wall-clock time, or carbon footprint).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical foundations and experimental validation of CAST. We address each major comment below and will revise the manuscript to incorporate the suggested improvements where appropriate.
read point-by-point responses
-
Referee: [§3] §3 (Method, multi-scale distribution matching): The multi-scale distribution matching criterion in the diffusion wavelet domain is presented without a derivation, approximation error bound, or analysis of how the local-collapse-aware refinement and cross-modal fusion affect the eigenstructure of the diffusion operator. This is load-bearing for the distributional equivalence claim, as the skeptic correctly notes that wavelet coefficients may not faithfully represent the joint image-text distribution if the fused topology is irregular.
Authors: We agree that the current presentation would benefit from additional theoretical support. In the revision, we will add a derivation of the multi-scale distribution matching criterion grounded in the spectral properties of diffusion wavelets. We will also derive an approximation error bound and include analysis showing that the local-collapse-aware refinement and cross-modal fusion preserve the key eigenstructure of the diffusion operator, ensuring the wavelet coefficients faithfully capture the joint image-text distribution even for irregular fused topologies. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract asserts outperformance on Flickr30K and MS-COCO with superiority in cross-architecture generalization and energy efficiency, but the provided text contains no quantitative metrics, baseline details, ablation studies isolating the wavelet matching or coverage components, or error analysis. This prevents verification of the central claim that the method reliably captures fine-grained cross-modal semantics without new biases.
Authors: The full manuscript includes quantitative results, baseline comparisons, and initial ablations in Section 4, but we acknowledge the need for greater detail to allow full verification. We will expand the experiments section with comprehensive ablation studies that isolate the wavelet matching and local soft relational coverage components, include error bars and statistical analysis, and provide additional cross-architecture generalization and energy efficiency metrics with explicit comparisons to multimodal synthesis baselines. revision: partial
Circularity Check
No circularity: method described at algorithmic level with no equations or derivations
full rationale
The provided manuscript text (abstract and description) presents CAST as a sequence of high-level algorithmic steps—constructing modality-specific topologies, local-collapse-aware refinement, cross-modal fusion, multi-scale distribution matching in the diffusion wavelet domain, and local soft relational coverage—without any equations, parameter-fitting procedures, or claimed derivations. No self-definitional reductions, fitted inputs renamed as predictions, or load-bearing self-citations are exhibited. The performance claims rest on empirical results on Flickr30K and MS-COCO rather than a closed mathematical chain that reduces to its own inputs by construction, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multimodal datasets exhibit fine-grained cross-modal information imbalance that single-modality sampling misses.
- domain assumption A unified topology obtained via local-collapse-aware refinement and cross-modal fusion preserves semantic structure better than separate modalities.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean; IndisputableMonolith/Cost/FunctionalEquation.leanreality_from_one_distinction; washburn_uniqueness_aczel unclearWe first construct image- and text-modality topologies... local-collapse-aware refinement and cross-modal fusion... multi-scale distribution matching criterion in the diffusion wavelet domain
Reference graph
Works this paper leans on
-
[1]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Boran Zhao, Hetian Liu, Zihang Yuan, Li Zhu, Fan Yang, Lina Xie, Tian Xia, Wenzhe Zhao, and Pengju Ren. Adapsne: Adaptive fireworks-optimized and entropy-guided dataset sampling for edge dnn training.IEEE Transactions on Circuits and Systems I: Regular Papers, 2026
work page 2026
-
[3]
Shenshen Li, Kaiyuan Deng, Lei Wang, Hao Yang, Chong Peng, Peng Yan, Fumin Shen, Heng Tao Shen, and Xing Xu. Truth in the few: High-value data selection for efficient multi- modal reasoning.arXiv preprint arXiv:2506.04755, 2025
-
[4]
Noel Loo, Ramin Hasani, Alexander Amini, and Daniela Rus. Efficient dataset distillation using random feature approximation.Advances in Neural Information Processing Systems, 35: 13877–13891, 2022
work page 2022
-
[5]
Improved distribution matching for dataset condensation
Ganlong Zhao, Guanbin Li, Yipeng Qin, and Yizhou Yu. Improved distribution matching for dataset condensation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7856–7865, 2023
work page 2023
-
[6]
Generalizing dataset distillation via deep generative prior
George Cazenavette, Tongzhou Wang, Antonio Torralba, Alexei A Efros, and Jun-Yan Zhu. Generalizing dataset distillation via deep generative prior. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3739–3748, 2023. 10
work page 2023
-
[7]
Daquan Zhou, Kai Wang, Jianyang Gu, Xiangyu Peng, Dongze Lian, Yifan Zhang, Yang You, and Jiashi Feng. Dataset quantization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17205–17216, 2023
work page 2023
-
[8]
Jin Cui, Boran Zhao, Jiajun Xu, Jiaqi Guo, Shuo Guan, and Pengju Ren. Fast: Topology-aware frequency-domain distribution matching for coreset selection.arXiv preprint arXiv:2511.19476, 2025
-
[9]
Bardia Safaei, Faizan Siddiqui, Jiacong Xu, Vishal M Patel, and Shao-Yuan Lo. Filter images first, generate instructions later: Pre-instruction data selection for visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14247–14256, 2025
work page 2025
-
[10]
Zhenyu Liu, Yunxin Li, Baotian Hu, Wenhan Luo, Yaowei Wang, and Min Zhang. Picking the cream of the crop: Visual-centric data selection with collaborative agents.arXiv preprint arXiv:2502.19917, 2025
-
[11]
Ljubiša Stankovi´c, Danilo Mandic, Miloš Dakovi´c, Bruno Scalzo, Miloš Brajovi´c, Ervin Sejdi´c, and Anthony G Constantinides. Vertex-frequency graph signal processing: A comprehensive review.Digital signal processing, page 102802, 2020
work page 2020
-
[12]
David I Shuman, Sunil K Narang, Pascal Frossard, Antonio Ortega, and Pierre Vandergheynst. The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains.IEEE signal processing magazine, 30(3):83–98, 2013
work page 2013
-
[13]
David K Hammond, Pierre Vandergheynst, and Rémi Gribonval. Wavelets on graphs via spectral graph theory.Applied and computational harmonic analysis, 30(2):129–150, 2011
work page 2011
-
[14]
Ruibo Chen, Yihan Wu, Lichang Chen, Guodong Liu, Qi He, Tianyi Xiong, Chenxi Liu, Junfeng Guo, and Heng Huang. Your vision-language model itself is a strong filter: Towards high- quality instruction tuning with data selection. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4156–4172, 2024
work page 2024
-
[15]
Data distillation: A survey.arXiv preprint arXiv:2301.04272, 2023
Noveen Sachdeva and Julian McAuley. Data distillation: A survey.arXiv preprint arXiv:2301.04272, 2023
-
[16]
Dataset condensation with distribution matching
Bo Zhao and Hakan Bilen. Dataset condensation with distribution matching. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 6514–6523, 2023
work page 2023
-
[17]
Dataset condensation with gradient matching.arXiv preprint arXiv:2006.05929, 2020
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. Dataset condensation with gradient matching. arXiv preprint arXiv:2006.05929, 2020
-
[18]
Dataset condensation via efficient synthetic-data param- eterization
Jang-Hyun Kim, Jinuk Kim, Seong Joon Oh, Sangdoo Yun, Hwanjun Song, Joonhyun Jeong, Jung-Woo Ha, and Hyun Oh Song. Dataset condensation via efficient synthetic-data param- eterization. InInternational Conference on Machine Learning, pages 11102–11118. PMLR, 2022
work page 2022
-
[19]
Scaling up dataset distillation to imagenet- 1k with constant memory
Justin Cui, Ruochen Wang, Si Si, and Cho-Jui Hsieh. Scaling up dataset distillation to imagenet- 1k with constant memory. InInternational Conference on Machine Learning, pages 6565–6590. PMLR, 2023
work page 2023
-
[20]
Dream: Efficient dataset distillation by representative matching
Yanqing Liu, Jianyang Gu, Kai Wang, Zheng Zhu, Wei Jiang, and Yang You. Dream: Efficient dataset distillation by representative matching. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 17314–17324, 2023
work page 2023
-
[21]
Low-rank similarity mining for multimodal dataset distillation.arXiv preprint arXiv:2406.03793, 2024
Yue Xu, Zhilin Lin, Yusong Qiu, Cewu Lu, and Yong-Lu Li. Low-rank similarity mining for multimodal dataset distillation.arXiv preprint arXiv:2406.03793, 2024
-
[22]
Xin Zhang, Ziruo Zhang, Jiawei Du, Zuozhu Liu, and Joey Tianyi Zhou. Beyond modal- ity collapse: Representations blending for multimodal dataset distillation.arXiv preprint arXiv:2505.14705, 2025
-
[23]
Xuan Qi, Luxi He, Dan Roth, and Xingyu Fu. Dataprophet: Demystifying supervision data generalization in multimodal llms.arXiv preprint arXiv:2603.19688, 2026. 11
-
[24]
Structures meet semantics: Multi- modal fusion via graph contrastive learning
Jiangfeng Sun, Sihao He, Zhonghong Ou, and Meina Song. Structures meet semantics: Multi- modal fusion via graph contrastive learning. InProceedings of the AAAI Conference on Artificial Intelligence, pages 25691–25699, 2026
work page 2026
-
[25]
Dexuan Ding, Lei Wang, Liyun Zhu, Tom Gedeon, and Piotr Koniusz. Learnable expansion of graph operators for multi-modal feature fusion.arXiv preprint arXiv:2410.01506, 2024
-
[26]
Extracting and composing robust features with denoising autoencoders
Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. InProceedings of the 25th international conference on Machine learning, pages 1096–1103, 2008
work page 2008
-
[27]
A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
Arthur Gretton, Karsten M Borgwardt, Malte J Rasch, Bernhard Schölkopf, and Alexander Smola. A kernel two-sample test.The journal of machine learning research, 13(1):723–773, 2012
work page 2012
-
[28]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[29]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
Leland McInnes, John Healy, and James Melville. Umap: Uniform manifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[30]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hockenmaier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models. InProceedings of the IEEE international conference on computer vision, pages 2641–2649, 2015
work page 2015
-
[31]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[32]
Deep visual-semantic alignments for generating image descriptions
Andrej Karpathy and Li Fei-Fei. Deep visual-semantic alignments for generating image descriptions. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3128–3137, 2015
work page 2015
-
[33]
Herding dynamical weights to learn
Max Welling. Herding dynamical weights to learn. InProceedings of the 26th annual interna- tional conference on machine learning, pages 1121–1128, 2009
work page 2009
-
[34]
Glis- ter: Generalization based data subset selection for efficient and robust learning
Krishnateja Killamsetty, Durga Sivasubramanian, Ganesh Ramakrishnan, and Rishabh Iyer. Glis- ter: Generalization based data subset selection for efficient and robust learning. InProceedings of the AAAI conference on artificial intelligence, pages 8110–8118, 2021
work page 2021
-
[35]
Mansheej Paul, Surya Ganguli, and Gintare Karolina Dziugaite. Deep learning on a data diet: Finding important examples early in training.Advances in neural information processing systems, 34:20596–20607, 2021
work page 2021
-
[36]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks.Advances in neural information processing systems, 25, 2012
work page 2012
-
[37]
Grad-match: Gradient matching based data subset selection for efficient deep model training
Krishnateja Killamsetty, Sivasubramanian Durga, Ganesh Ramakrishnan, Abir De, and Rishabh Iyer. Grad-match: Gradient matching based data subset selection for efficient deep model training. InInternational Conference on Machine Learning, pages 5464–5474. PMLR, 2021
work page 2021
-
[38]
Suorong Yang, Peijia Li, Yujie Liu, Zhiming Xu, Peng Ye, Wanli Ouyang, Furao Shen, and Dongzhan Zhou. Multimodal-guided dynamic dataset pruning for robust and efficient data- centric learning.arXiv preprint arXiv:2507.12750, 2025
-
[39]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
work page 2019
-
[40]
High-performance large-scale image recognition without normalization
Andy Brock, Soham De, Samuel L Smith, and Karen Simonyan. High-performance large-scale image recognition without normalization. InInternational conference on machine learning, pages 1059–1071. PMLR, 2021. 12
work page 2021
-
[41]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[42]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[43]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[44]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[45]
Gqa: A new dataset for real-world visual reasoning and compositional question answering
Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709, 2019
work page 2019
-
[46]
Tanik Saikh, Tirthankar Ghosal, Amish Mittal, Asif Ekbal, and Pushpak Bhattacharyya. Sci- enceqa: A novel resource for question answering on scholarly articles.International Journal on Digital Libraries, 23(3):289–301, 2022
work page 2022
-
[47]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[48]
Towards vqa models that can read
Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8309–8318, 2019. doi: 10.1109/ CVPR.2019.00851
-
[49]
Evaluating object hallucination in large vision-language models
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. Evaluating object hallucination in large vision-language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 292–305, 2023. 13 A Technical appendices and supplementary material A.1 Details of Unified Graph Reconstruction As described ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.