Recognition: 2 theorem links
· Lean TheoremDebiased Model-based Representations for Sample-efficient Continuous Control
Pith reviewed 2026-05-13 07:04 UTC · model grok-4.3
The pith
DR.Q debiases model-based representations for off-policy actor-critic learning by maximizing mutual information with next states and applying faded prioritized replay.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
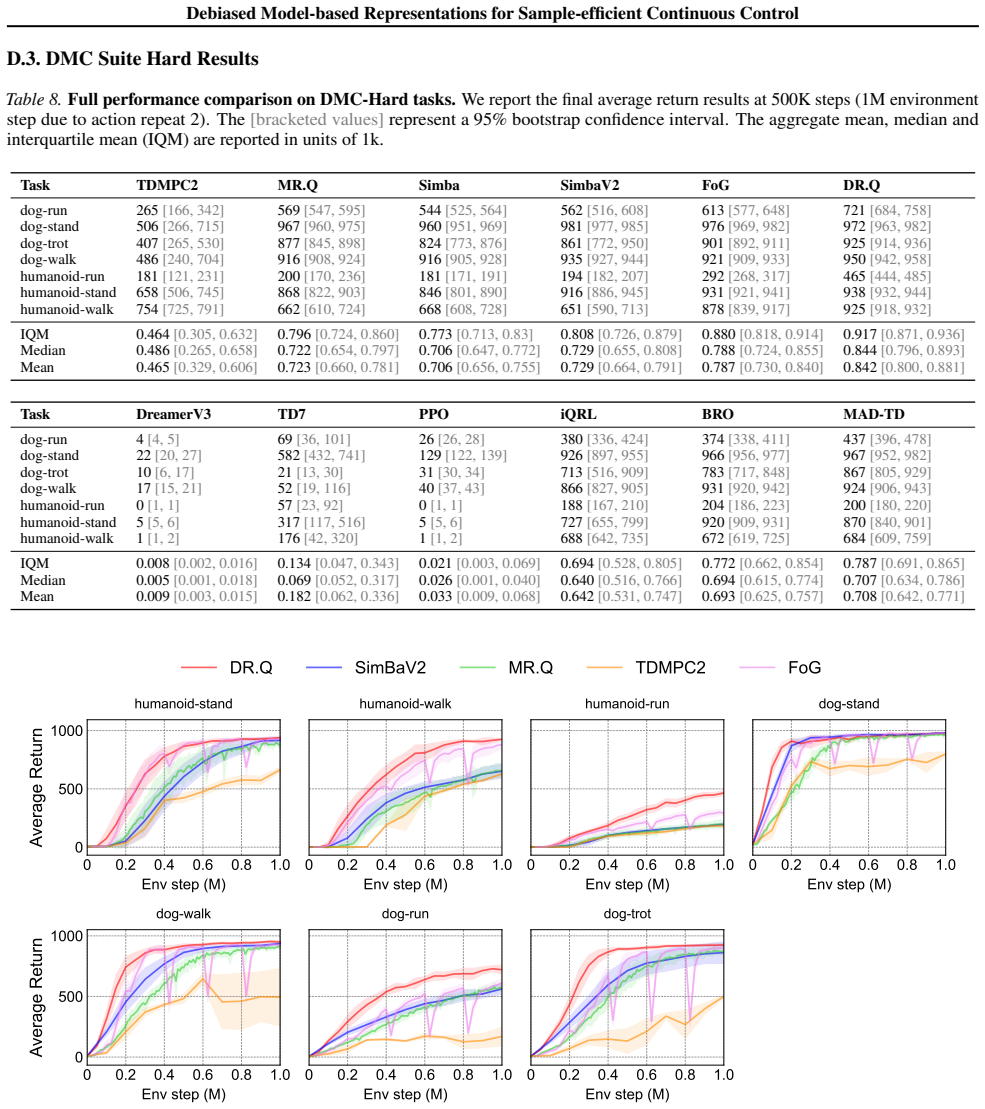
DR.Q explicitly maximizes the mutual information between the representations of the current state-action pair and the next state besides minimizing their deviations, and samples transitions with faded prioritized experience replay. This removes biases from both the learned representations and the downstream actor-critic learning, enabling the algorithm to match or surpass recent strong baselines on numerous continuous control benchmarks.
What carries the argument
The DR.Q objective that augments standard model-based representation training with a mutual-information maximization term between current state-action pairs and next states, together with faded prioritized experience replay for transition sampling.
If this is right
- Representations retain more predictive information about future states, improving downstream policy quality.
- Actor-critic updates suffer less from early-experience bias, raising sample efficiency.
- A single hyperparameter set works across diverse continuous-control tasks without per-environment retuning.
- The same debiasing pattern can be applied inside other model-based representation pipelines.
Where Pith is reading between the lines
- The mutual-information regularizer might also reduce representation collapse in purely model-free settings that lack explicit next-state prediction.
- Faded prioritized replay could be combined with other replay strategies such as hindsight experience replay to further stabilize long-horizon tasks.
- If the debiasing effect holds, similar information-maximization terms could be inserted into model-free representation learners to achieve comparable gains without building any dynamics model.
Load-bearing premise
That the added mutual-information term and faded prioritized replay together eliminate representation and critic biases without creating new overfitting or instability during training.
What would settle it
A controlled re-run on the same continuous-control benchmarks that shows DR.Q failing to match or exceed the reported baselines when all methods use only one hyperparameter configuration.
Figures















read the original abstract
Model-based representations recently stand out as a promising framework that embeds latent dynamics information into the representations for downstream off-policy actor-critic learning. It implicitly combines the advantages of both model-free and model-based approaches while avoiding the training costs associated with model-based methods. Nevertheless, existing model-based representation methods can fail to capture sufficient information about relevant variables and can overfit to early experiences in the replay buffer. These incur biases in representation and actor-critic learning, leading to inferior performance. To address this, we propose Debiased model-based Representations for Q-learning, tagged DR.Q algorithm. DR.Q explicitly maximizes the mutual information between the representations of the current state-action pair and the next state besides minimizing their deviations, and samples transitions with faded prioritized experience replay. We evaluate DR.Q on numerous continuous control benchmarks with a single set of hyperparameters, and the results demonstrate that DR.Q can match or surpass recent strong baselines, sometimes outperforming them by a large margin. Our code is available at https://github.com/dmksjfl/DR.Q.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DR.Q, a method for debiased model-based representations in off-policy actor-critic learning for continuous control. It augments standard model-based representation learning by explicitly maximizing mutual information between current state-action representations and next states (while minimizing deviations) and by sampling from the replay buffer with faded prioritized experience replay. The central empirical claim is that DR.Q matches or exceeds recent strong baselines on numerous continuous control benchmarks using a single hyperparameter set, with occasional large margins.
Significance. If the performance gains can be rigorously attributed to the proposed debiasing mechanisms rather than implementation details, the work would offer a practical way to combine model-free and model-based advantages in sample-efficient RL without incurring full model-based training costs. The single-hyperparameter-set evaluation is a positive feature for reproducibility and deployment.
major comments (3)
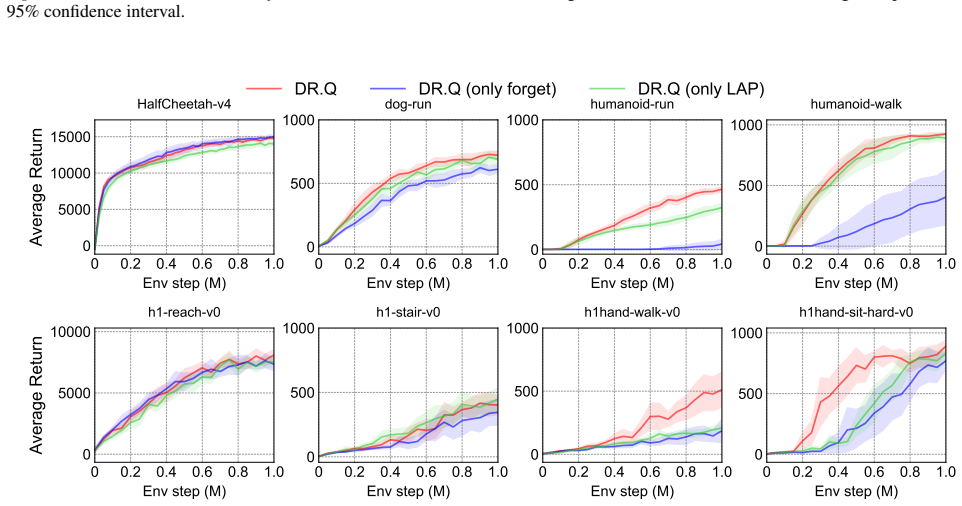
- [Experiments] Experiments section: No targeted ablation studies are presented that disable only the mutual information maximization term (or only the faded PER schedule) while holding all other components fixed. This makes it impossible to isolate whether observed gains arise from the claimed debiasing or from unmentioned differences in network architecture, optimizer, or other implementation choices.
- [§4] §4 (Results): The manuscript provides no diagnostics (e.g., probing classifiers, representation similarity metrics, or bias quantification) demonstrating that the learned representations actually capture more relevant variables or reduce actor-critic bias relative to baselines. Performance tables alone are insufficient to support the central debiasing claim.
- [Method and Experiments] Method and Experiments: Details on statistical significance (number of seeds, error bars, hypothesis testing) and exact experimental controls are not reported at the level needed to substantiate claims of consistent outperformance across benchmarks.
minor comments (2)
- [Abstract] Abstract: The phrase 'numerous continuous control benchmarks' should be accompanied by an explicit list of environments and quantitative margins of improvement.
- Ensure all performance figures include shaded error regions or standard-error bars and that the code repository contains the exact configurations used for the reported runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that the experimental section requires strengthening to better isolate the contributions of the proposed components and to provide more rigorous support for the debiasing claims. We address each major comment below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Experiments] Experiments section: No targeted ablation studies are presented that disable only the mutual information maximization term (or only the faded PER schedule) while holding all other components fixed. This makes it impossible to isolate whether observed gains arise from the claimed debiasing or from unmentioned differences in network architecture, optimizer, or other implementation choices.
Authors: We agree that targeted ablations are necessary to attribute performance gains specifically to the debiasing mechanisms. In the revised manuscript, we will add ablation experiments in the Experiments section that disable only the mutual information maximization term (while retaining faded PER and all other elements) and, separately, disable only the faded PER schedule (while retaining the MI term). All ablations will use identical network architectures, optimizers, and hyperparameters as the main results to ensure controlled comparisons. revision: yes
-
Referee: [§4] §4 (Results): The manuscript provides no diagnostics (e.g., probing classifiers, representation similarity metrics, or bias quantification) demonstrating that the learned representations actually capture more relevant variables or reduce actor-critic bias relative to baselines. Performance tables alone are insufficient to support the central debiasing claim.
Authors: We acknowledge that additional diagnostics are needed to substantiate the debiasing claim beyond aggregate performance. In the revised Section 4, we will include: (i) representation similarity metrics (e.g., cosine similarity between state-action and next-state representations), (ii) probing classifiers trained to predict relevant environment variables from the learned representations, and (iii) bias quantification measures comparing representation-induced errors against baselines. These will be presented with direct comparisons to show improved capture of relevant variables and reduced bias. revision: yes
-
Referee: [Method and Experiments] Method and Experiments: Details on statistical significance (number of seeds, error bars, hypothesis testing) and exact experimental controls are not reported at the level needed to substantiate claims of consistent outperformance across benchmarks.
Authors: We agree that more detailed reporting is required. In the revised manuscript, we will expand the Method and Experiments sections to explicitly state the number of random seeds (5 per task), include standard error bars on all learning curves and tables, and report statistical significance via paired t-tests between DR.Q and baselines. We will also provide fuller descriptions of experimental controls, including precise hyperparameter values, network dimensions, and training protocols. revision: yes
Circularity Check
DR.Q's MI maximization and faded PER defined independently of benchmark outcomes
full rationale
The paper introduces DR.Q via two explicit algorithmic choices—maximizing mutual information between current state-action representations and next states while minimizing deviations, plus faded prioritized experience replay—to address representation and actor-critic biases. These components are stated as design decisions separate from the final performance numbers. No equations or derivations reduce the claimed improvements to fitted parameters, self-citations, or inputs by construction. The evaluation on continuous control benchmarks is purely empirical. A score of 2 reflects only the normal presence of self-citations in related-work sections that do not carry the central claim.
Axiom & Free-Parameter Ledger
free parameters (1)
- single hyperparameter set
axioms (2)
- domain assumption Maximizing mutual information between current state-action representation and next state removes representation bias
- domain assumption Faded prioritized experience replay prevents overfitting to early experiences
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DR.Q explicitly maximizes the mutual information between the representations of the current state-action pair and the next state besides minimizing their deviations, and samples transitions with faded prioritized experience replay.
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.1. Minimizing E[∥Zsa − Zs′∥²₂] does not necessarily increase the mutual information I(Zsa; Zs′).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Bengio, Y ., Courville, A., and Vincent, P
URL https://openreview.net/forum? id=WFYbBOEOtv. Bengio, Y ., Courville, A., and Vincent, P. Representation learning: A review and new perspectives.IEEE transac- tions on pattern analysis and machine intelligence, 35(8): 1798–1828, 2013. Bhatt, A., Palenicek, D., Belousov, B., Argus, M., Ami- ranashvili, A., Brox, T., and Peters, J. Crossq: Batch normaliz...
work page 2013
-
[2]
URL https://openreview.net/forum? id=PczQtTsTIX. Brockman, G., Cheung, V ., Pettersson, L., Schneider, J., Schulman, J., Tang, J., and Zaremba, W. Openai gym. arXiv preprint arXiv:1606.01540, 2016. 9 Debiased Model-based Representations for Sample-efficient Continuous Control Buckman, J., Hafner, D., Tucker, G., Brevdo, E., and Lee, H. Sample-efficient re...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
PMLR, 2021. Grill, J.-B., Strub, F., Altch´e, F., Tallec, C., Richemond, P., Buchatskaya, E., Doersch, C., Avila Pires, B., Guo, Z., Gheshlaghi Azar, M., et al. Bootstrap your own latent-a new approach to self-supervised learning.Advances in neural information processing systems, 33:21271–21284, 2020. Guo, Z., Thakoor, S., Pˆıslar, M., Avila Pires, B., Al...
work page 2021
-
[4]
Soft Actor-Critic Algorithms and Applications
PMLR, 2020. Haarnoja, T., Zhou, A., Hartikainen, K., Tucker, G., Ha, S., Tan, J., Kumar, V ., Zhu, H., Gupta, A., Abbeel, P., et al. Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905, 2018. Hafner, D., Lillicrap, T., Fischer, I., Villegas, R., Ha, D., Lee, H., and Davidson, J. Learning latent dynamics for planning from pixels. ...
work page internal anchor Pith review arXiv 2020
-
[5]
Mastering Diverse Domains through World Models
URL https://openreview.net/forum? id=S1lOTC4tDS. Hafner, D., Pasukonis, J., Ba, J., and Lillicrap, T. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023. Hansen, N., Su, H., and Wang, X. TD-MPC2: Scalable, ro- bust world models for continuous control. InThe Twelfth International Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
URL https://openreview.net/forum? id=Oxh5CstDJU. Hansen, N. A., Su, H., and Wang, X. Temporal differ- ence learning for model predictive control. InInterna- tional Conference on Machine Learning, pp. 8387–8406. PMLR, 2022. Hessel, M., Modayil, J., Van Hasselt, H., Schaul, T., Os- trovski, G., Dabney, W., Horgan, D., Piot, B., Azar, M., and Silver, D. Rain...
-
[7]
Horgan, D., Quan, J., Budden, D., Barth-Maron, G., Hes- sel, M., van Hasselt, H., and Silver, D
URL https://openreview.net/forum? id=OXRZeMmOI7a. Horgan, D., Quan, J., Budden, D., Barth-Maron, G., Hes- sel, M., van Hasselt, H., and Silver, D. Distributed prioritized experience replay. InInternational Confer- ence on Learning Representations, 2018. URL https: //openreview.net/forum?id=H1Dy---0Z. Janner, M., Fu, J., Zhang, M., and Levine, S. When to t...
work page 2018
-
[8]
Deep Variational Bayes Filters: Unsupervised Learning of State Space Models from Raw Data
URL https://openreview.net/forum? id=VhmTXbsdtx. Karl, M., Soelch, M., Bayer, J., and Van der Smagt, P. Deep variational bayes filters: Unsupervised learning of state space models from raw data.arXiv preprint arXiv:1605.06432, 2016. Krinner, M., Aljalbout, E., Romero, A., and Scaramuzza, D. Accelerating model-based reinforcement learn- ing with state-spac...
work page Pith review arXiv 2016
-
[9]
Lyle, C., Zheng, Z., Khetarpal, K., Martens, J., van Hasselt, H
URL https://openreview.net/forum? id=7joG3i2pUR. Lyle, C., Zheng, Z., Khetarpal, K., Martens, J., van Hasselt, H. P., Pascanu, R., and Dabney, W. Normalization and effective learning rates in reinforcement learning.Ad- vances in Neural Information Processing Systems, 37: 106440–106473, 2024. Lyu, J., Ma, X., Yan, J., and Li, X. Efficient continuous contro...
-
[10]
Nauman, M., Ostaszewski, M., Jankowski, K., Miło ´s, P., and Cygan, M
IEEE, 2016. Nauman, M., Ostaszewski, M., Jankowski, K., Miło ´s, P., and Cygan, M. Bigger, regularized, optimistic: scal- ing for compute and sample efficient continuous con- trol. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https: //openreview.net/forum?id=fu0xdh4aEJ. Nauman, M., Cygan, M., Sferrazza, C., Kum...
-
[11]
URL https://openreview.net/forum? id=WuEiafqdy9H. Oord, A. v. d., Li, Y ., and Vinyals, O. Representation learn- ing with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. Ota, K., Oiki, T., Jha, D., Mariyama, T., and Nikovski, D. Can increasing input dimensionality improve deep reinforcement learning? InInternational conference on mach...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[12]
Sun, R., Zang, H., Li, X., and Islam, R
PMLR, 2021. Sun, R., Zang, H., Li, X., and Islam, R. Learning latent dy- namic robust representations for world models. InForty- first International Conference on Machine Learning,
work page 2021
-
[13]
URL https://openreview.net/forum? id=C4jkx6AgWc. Tassa, Y ., Doron, Y ., Muldal, A., Erez, T., Li, Y ., Casas, D. d. L., Budden, D., Abdolmaleki, A., Merel, J., Lefrancq, 13 Debiased Model-based Representations for Sample-efficient Continuous Control A., et al. Deepmind control suite.arXiv preprint arXiv:1801.00690, 2018. Todorov, E., Erez, T., and Tassa,...
work page internal anchor Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.