Recognition: no theorem link
Toward Stable Value Alignment: Introducing Independent Modules for Consistent Value Guidance
Pith reviewed 2026-05-13 06:57 UTC · model grok-4.3
The pith
SVGT stabilizes LLM value alignment by isolating normative representations in a dedicated module and steering outputs via bridge tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
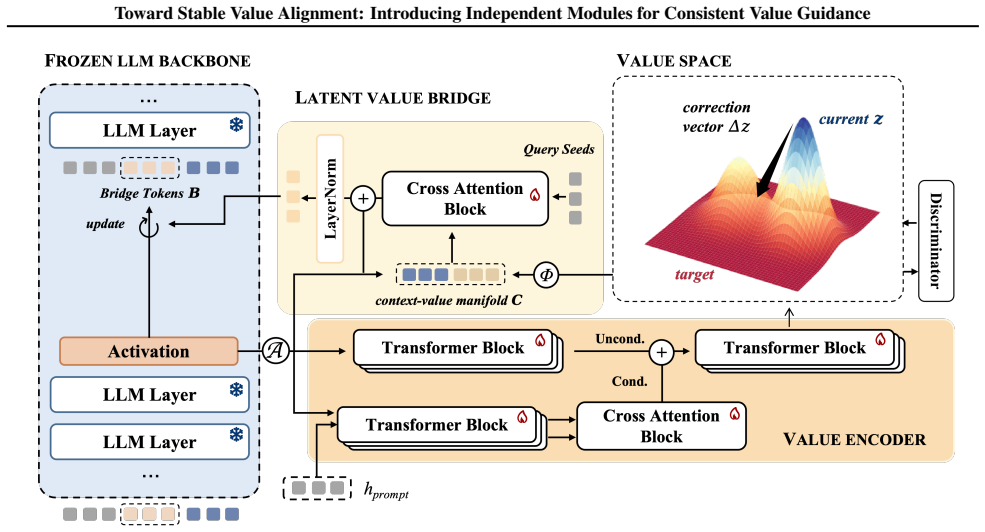
SVGT addresses unstable value alignment by maintaining normative representations in a dedicated value space isolated from the backbone and transducing these signals into learnable latent Bridge Tokens that serve as dynamic anchors to steer the generative trajectory, thereby ensuring robust adherence without disrupting the backbone's internal representations.
What carries the argument
Independent value module with bridge tokens: a separate space that holds stable value representations and converts them into explicit steering tokens for the generative process.
If this is right
- Harmful output scores fall by more than 70 percent on safety benchmarks while fluency is preserved.
- Value guidance remains consistent across diverse contexts without altering backbone parameters.
- The same architecture applies to multiple model backbones with comparable gains.
- Alignment becomes an add-on module rather than an integrated training step.
Where Pith is reading between the lines
- Value modules could be exchanged or updated independently for different ethical priorities on the same backbone.
- The separation might make it easier to diagnose and correct alignment failures in deployed systems.
- The pattern suggests extending modular guidance to multi-turn or multi-agent settings where stability is critical.
Load-bearing premise
Value signals can be isolated in a dedicated module and then successfully transduced into tokens that reliably influence the backbone's behavior.
What would settle it
Ablation experiments in which the independent module or bridge tokens are removed yet harmful scores remain unchanged on the same safety benchmarks would falsify the stability claim.
Figures












read the original abstract
Aligning large language models (LLMs) with human values typically relies on post-training or inference-time steering that directly manipulates the backbone's parameters or representation space. However, a critical gap exists: the model's residual stream is highly dynamic, in which values exist as fragile, low-dimensional properties, inherently incompatible with the stability required for consistent value expression. In this paper, we propose the Stable Value Guidance Transformer (SVGT), which addresses this gap through an independent value module incorporating two key designs: (1) independent value modeling, maintaining normative representations in a dedicated value space isolated from the backbone, and (2) explicit behavioral guidance, transducing these stable signals into learnable latent Bridge Tokens. These tokens serve as dynamic value anchors to explicitly steer the generative trajectory, ensuring robust adherence across diverse contexts without disrupting the backbone's internal representations. Experiments across multiple backbones and safety benchmarks show that SVGT generally reduces harmful scores by over 70% while maintaining generation fluency, demonstrating the efficacy of architecturally grounded value modeling. Our code is available at https://github.com/Clervils/SVGT.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the Stable Value Guidance Transformer (SVGT), which augments LLMs with an independent value module that maintains normative representations in a dedicated space isolated from the backbone residual stream and transduces them via learnable Bridge Tokens to steer generation. It claims this yields over 70% reduction in harmful scores across multiple backbones and safety benchmarks while preserving fluency, addressing the fragility of values in dynamic residual streams.
Significance. If the empirical results hold under scrutiny, the work would offer a meaningful architectural alternative to post-training or direct steering methods for value alignment, potentially enabling more consistent normative guidance without altering backbone parameters. The public code release aids reproducibility and allows direct testing of the independent-module design.
major comments (2)
- [Abstract] Abstract: the central claim of 'generally reduces harmful scores by over 70%' is presented without any description of baselines, metrics, statistical tests, ablation controls, or variance across runs, rendering the efficacy of the independent value module and Bridge Tokens unverifiable from the provided text.
- Method description (Bridge Tokens): the architecture isolates normative representations but then explicitly inserts Bridge Tokens into the residual stream to steer trajectories; no measurement, ablation, or analysis is described that demonstrates these tokens maintain stable influence rather than being diluted or overwritten by subsequent dynamics, which directly undermines attribution of the reported harm reduction to architectural grounding.
minor comments (1)
- [Abstract] The abstract refers to 'multiple backbones and safety benchmarks' without naming them or providing even high-level dataset statistics, which reduces the reader's ability to assess generalizability.
Simulated Author's Rebuttal
We appreciate the referee's constructive feedback on our manuscript. Below, we provide point-by-point responses to the major comments and outline the revisions we will make to enhance clarity and rigor.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'generally reduces harmful scores by over 70%' is presented without any description of baselines, metrics, statistical tests, ablation controls, or variance across runs, rendering the efficacy of the independent value module and Bridge Tokens unverifiable from the provided text.
Authors: We agree that the abstract lacks sufficient detail to fully substantiate the claim. The main text (Section 4) specifies the baselines (vanilla and safety-aligned LLMs), metrics (harm scores from established benchmarks), statistical tests, and reports mean results with standard deviations over multiple runs. We will revise the abstract to concisely include references to these elements, such as 'across multiple backbones and benchmarks with averaged results over runs,' to improve verifiability while adhering to length constraints. revision: yes
-
Referee: [—] Method description (Bridge Tokens): the architecture isolates normative representations but then explicitly inserts Bridge Tokens into the residual stream to steer trajectories; no measurement, ablation, or analysis is described that demonstrates these tokens maintain stable influence rather than being diluted or overwritten by subsequent dynamics, which directly undermines attribution of the reported harm reduction to architectural grounding.
Authors: We recognize the importance of demonstrating the stability of Bridge Tokens' influence. Although the current manuscript focuses on end-to-end performance improvements, it does not include dedicated ablations for temporal stability or dilution effects. In the revised version, we will incorporate new experiments and analyses, including step-wise influence measurements and ablations removing Bridge Tokens mid-generation, to empirically show their sustained impact and support the architectural claims. revision: yes
Circularity Check
No significant circularity detected in architectural proposal or claims
full rationale
The paper proposes a new SVGT architecture consisting of an independent value module and Bridge Tokens to isolate and transduce value signals. Its central claims rest on this design choice plus empirical experiments across backbones showing harm reduction. No derivation reduces a result to its own inputs by construction, no parameters are fitted to a subset and then called predictions, and no load-bearing self-citations or uniqueness theorems appear in the text. The residual-stream fragility premise is stated as motivation rather than derived from the method itself, and the 70% reduction figure is presented as an experimental outcome rather than a mathematical identity. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM residual streams are highly dynamic and values exist as fragile low-dimensional properties incompatible with stable expression
invented entities (2)
-
independent value space
no independent evidence
-
Bridge Tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aligning Superintelligence with Human Interests: A Technical Research Agenda , author =. 2014 , url =
work page 2014
-
[2]
arXiv preprint arXiv:1906.01820 , year =
Risks from Learned Optimization in Advanced Machine Learning Systems , author =. CoRR , volume =. 2019 , url =. 1906.01820 , eprinttype =
-
[3]
The Alignment Problem: Machine Learning and Human Values , author =. 2020 , publisher =
work page 2020
- [4]
-
[5]
Transactions on Machine Learning Research (TMLR) , year =
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback , author =. Transactions on Machine Learning Research (TMLR) , year =
-
[6]
Dan Hendrycks and Mantas Mazeika and Thomas Woodside , journal =. An Overview of Catastrophic
-
[7]
Advances in Neural Information Processing Systems , volume =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems , volume =
-
[8]
Yuntao Bai and Saurav Kadavath and Sandipan Kundu and Amanda Askell and Jackson Kernion and Andy Jones and Anna Chen and Anna Goldie and Azalia Mirhoseini and Cameron McKinnon and others , journal =. Constitutional
-
[9]
Advances in Neural Information Processing Systems , year =
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author =. Advances in Neural Information Processing Systems , year =
-
[10]
Inverse Preference Learning: Preference-based
Joey Hejna and Dorsa Sadigh , booktitle =. Inverse Preference Learning: Preference-based
-
[11]
Hanze Dong and Wei Xiong and Deepanshu Goyal and Yihan Zhang and Winnie Chow and Rui Pan and Shizhe Diao and Jipeng Zhang and KaShun SHUM and Tong Zhang , journal =
-
[12]
A General Theoretical Paradigm to Understand Learning from Human Preferences , journal =
Mohammad Gheshlaghi Azar and Mark Rowland and Bilal Piot and Daniel Guo and Daniele Calandriello and Michal Valko and R. A General Theoretical Paradigm to Understand Learning from Human Preferences , journal =
-
[13]
A Unified Approach to Online and Offline
Shicong Cen and Jincheng Mei and Katayoon Goshvadi and Hanjun Dai and Tong Yang and Sherry Yang and Dale Schuurmans and Yuejie Chi and Bo Dai , booktitle =. A Unified Approach to Online and Offline
-
[14]
Kawin Ethayarajh and Winnie Xu and Niklas Muennighoff and Dan Jurafsky and Douwe Kiela , booktitle =
-
[15]
Yu Meng and Mengzhou Xia and Danqi Chen , booktitle =
-
[16]
International Conference on Learning Representations , year =
Safety Alignment Should be Made More Than Just a Few Tokens Deep , author =. International Conference on Learning Representations , year =
-
[17]
International Conference on Learning Representations , year =
Plug and Play Language Models: A Simple Approach to Controlled Text Generation , author =. International Conference on Learning Representations , year =
-
[18]
Annual Meeting of the Association for Computational Linguistics , pages =
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Annual Meeting of the Association for Computational Linguistics , pages =
-
[19]
International Conference on Learning Representations , year =
Fast Model Editing at Scale , author=. International Conference on Learning Representations , year =
-
[20]
International Conference on Machine Learning , year =
Controlled Decoding from Language Models , author =. International Conference on Machine Learning , year =
-
[21]
Advances in Neural Information Processing Systems , year =
Inference-Time Intervention: Eliciting Truthful Answers from a Language Model , author =. Advances in Neural Information Processing Systems , year =
-
[22]
Bill Yuchen Lin and Abhilasha Ravichander and Ximing Lu and Nouha Dziri and Melanie Sclar and Khyathi Chandu and Chandra Bhagavatula and Yejin Choi , booktitle =. The Unlocking Spell on Base
-
[23]
Yuhui Li and Fangyun Wei and Jinjing Zhao and Chao Zhang and Hongyang Zhang , booktitle=
-
[24]
Maxim Khanov and Jirayu Burapacheep and Yixuan Li , booktitle =
-
[25]
First Conference on Language Modeling (COLM) , year =
Tuning Language Models by Proxy , author =. First Conference on Language Modeling (COLM) , year =
-
[26]
Hanshi Sun and Momin Haider and Ruiqi Zhang and Huitao Yang and Jiahao Qiu and Ming Yin and Mengdi Wang and Peter Bartlett and Andrea Zanette , booktitle =. Fast Best-of-
-
[27]
Advances in Neural Information Processing Systems , year=
Aligner: Efficient Alignment by Learning to Correct , author=. Advances in Neural Information Processing Systems , year=
-
[28]
Advances in Neural Information Processing Systems , year=
Aligning Large Language Models with Representation Editing: A Control Perspective , author=. Advances in Neural Information Processing Systems , year=
-
[29]
Natural Language Processing and Chinese Computing , year =
Latent Feature Activation Steering for Enhancing Semantic Consistency in Large Language Models , author =. Natural Language Processing and Chinese Computing , year =
-
[30]
Advances in Neural Information Processing Systems , year =
Many-Shot Jailbreaking , author =. Advances in Neural Information Processing Systems , year =
-
[31]
Erik Miehling and Michael Desmond and Karthikeyan Natesan Ramamurthy and Elizabeth M. Daly and Kush R. Varshney and Eitan Farchi and Pierre Dognin and Jesus Rios and Djallel Bouneffouf and Miao Liu and Prasanna Sattigeri , title =. Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language ...
-
[32]
Krause, Ben and Gotmare, Akhilesh Deepak and McCann, Bryan and Keskar, Nitish Shirish and Joty, Shafiq and Socher, Richard and Rajani, Nazneen Fatema , booktitle =
-
[33]
Liu, Alisa and Sap, Maarten and Lu, Ximing and Swayamdipta, Swabha and Bhagavatula, Chandra and Smith, Noah A. and Choi, Yejin , booktitle =
-
[34]
Prashant Trivedi and Souradip Chakraborty and Avinash Reddy and Vaneet Aggarwal and Amrit Singh Bedi and George K. Atia , booktitle =. Align-Pro: A Principled Approach to Prompt Optimization for
-
[35]
Findings of the Empirical Methods in Natural Language Processing , pages =
A Survey on Training-Free Alignment of Large Language Models , author =. Findings of the Empirical Methods in Natural Language Processing , pages =
-
[36]
Alexander Wei and Nika Haghtalab and Jacob Steinhardt , booktitle =. Jailbroken: How Does
-
[37]
Advances in Neural Information Processing Systems , year =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[38]
Annual Meeting of the Association for Computational Linguistics , year =
Language Models Resist Alignment: Evidence From Data Compression , author =. Annual Meeting of the Association for Computational Linguistics , year =
-
[39]
A Mathematical Framework for Transformer Circuits , author =. 2021 , note =
work page 2021
-
[40]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex J Andonian and Yonatan Belinkov , booktitle=. Locating and Editing Factual Associations in
-
[41]
The Conference on Empirical Methods in Natural Language Processing , year =
Transformer Feed-Forward Layers Are Key-Value Memories , author=. The Conference on Empirical Methods in Natural Language Processing , year =
-
[42]
In-context Learning and Induction Heads
In-Context Learning and Induction Heads , author=. arXiv preprint arXiv:2209.11895 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Toy Models of Superposition , author=. arXiv preprint arXiv:2209.10652 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Locating and Editing Factual Associations in
Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov , journal =. Locating and Editing Factual Associations in
-
[45]
International Conference on Learning Representations , year =
Progress Measures for Grokking via Mechanistic Interpretability , author=. International Conference on Learning Representations , year =
-
[46]
Linearity of Relation Decoding in Transformer Language Models , booktitle =
-
[47]
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author =. 2023 , note =
work page 2023
-
[48]
International Conference on Machine Learning , year =
Kiho Park and Yo Joong Choe and Victor Veitch , title =. International Conference on Machine Learning , year =
-
[49]
Shai and Lucas Teixeira and Alexander Gietelink Oldenziel and Sarah Marzen and Paul M
Adam S. Shai and Lucas Teixeira and Alexander Gietelink Oldenziel and Sarah Marzen and Paul M. Riechers , title =. Advances in Neural Information Processing Systems , year =
-
[50]
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author =. arXiv preprint arXiv:2310.06824 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Advances in Neural Information Processing Systems , year =
Andy Arditi and Oscar Obeso and Aaquib Syed and Daniel Paleka and Nina Panickssery and Wes Gurnee and Neel Nanda , title =. Advances in Neural Information Processing Systems , year =
-
[52]
Adly Templeton and Tom Conerly and Jonathan Marcus and Jack Lindsey and Trenton Bricken and Brian Chen and Adam Pearce and Craig Citro and Emmanuel Ameisen and Andy Jones and Hoagy Cunningham and Nicholas L. Turner and Callum McDougall and Monte MacDiarmid and Alex Tamkin and Esin Durmus and Tristan Hume and Francesco Mosconi and C. Daniel Freeman and The...
-
[53]
International Conference on Machine Learning , year =
Juno Kim and Taiji Suzuki , title =. International Conference on Machine Learning , year =
-
[54]
International Conference on Machine Learning , year =
Yotam Wolf and Noam Wies and Oshri Avnery and Yoav Levine and Amnon Shashua , title =. International Conference on Machine Learning , year =
-
[55]
International Conference on Machine Learning , year =
Wenbo Pan and Zhichao Liu and Qiguang Chen and Xiangyang Zhou and Haining Yu and Xiaohua Jia , title =. International Conference on Machine Learning , year =
-
[56]
Proceedings of the ICML Workshop on Machine Unlearning for Generative AI , year=
On the Fragility of Latent Knowledge: Layer-wise Influence under Unlearning in Large Language Model , author=. Proceedings of the ICML Workshop on Machine Unlearning for Generative AI , year=
-
[57]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation Engineering: A Top-Down Approach to AI Transparency , author =. arXiv preprint arXiv:2310.01405 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[58]
Annual Meeting of the Association for Computational Linguistics , year =
Nina Rimsky and Nick Gabrieli and Julian Schulz and Meg Tong and Evan Hubinger and Alexander Matt Turner , title =. Annual Meeting of the Association for Computational Linguistics , year =
-
[59]
Steering Language Models With Activation Engineering
Steering Language Models with Activation Engineering , author =. arXiv preprint arXiv:2308.10248 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[60]
Advances in Neural Information Processing Systems , year=
Analysing the Generalisation and Reliability of Steering Vectors , author=. Advances in Neural Information Processing Systems , year=
-
[61]
Advances in Experimental Social Psychology , volume =
Universals in the Content and Structure of Values: Theoretical Advances and Empirical Tests in 20 Countries , author =. Advances in Experimental Social Psychology , volume =. 1992 , publisher =
work page 1992
-
[62]
The Neural Bases of Cognitive Conflict and Control in Moral Judgment , author =. Neuron , volume =
- [63]
-
[64]
Personality and Social Psychology Review , volume =
Action, Outcome, and Value: A Dual-System Framework for Morality , author =. Personality and Social Psychology Review , volume =
-
[65]
A Within-Study Cross-Validation of the Values-as-Ideals Measure: Levels of Value Orientation Explain Variability in Well-Being , author =. Heliyon , volume =
-
[66]
Lvmin Zhang and Anyi Rao and Maneesh Agrawala , title =
-
[67]
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , title =. 2023 , booktitle =
work page 2023
- [68]
-
[69]
Advances in Neural Information Processing Systems , year =
Flamingo: a Visual Language Model for Few-Shot Learning , author =. Advances in Neural Information Processing Systems , year =
-
[70]
Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
Adding Conditional Control to Text-to-Image Diffusion Models , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) , year =
-
[71]
International Conference on Learning Representations , year =
Renrui Zhang and Jiaming Han and Chris Liu and Aojun Zhou and Pan Lu and Yu Qiao and Hongsheng Li and Peng Gao , title =. International Conference on Learning Representations , year =
-
[72]
International Conference on Machine Learning , year =
Curriculum Learning , author =. International Conference on Machine Learning , year =
-
[73]
International Conference on Learning Representations , year =
Let's Verify Step by Step , author =. International Conference on Learning Representations , year =
-
[74]
Deeply-Supervised Nets , author =. Proceedings of the Eighteenth International Conference on Artificial Intelligence and Statistics , year =
-
[75]
Language Models are Unsupervised Multitask Learners , author=. OpenAI Blog , year =
-
[76]
Qwen2 Technical Report , author=. arXiv preprint arXiv:2407.10671 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
The LLaMA 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Mistral 7B , author =. arXiv preprint arXiv:2310.06825 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Jiaming Ji and Mickel Liu and Josef Dai and Xuehai Pan and Chi Zhang and Ce Bian and Boyuan Chen and Ruiyang Sun and Yizhou Wang and Yaodong Yang , booktitle =
-
[80]
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models , author=. arXiv preprint arXiv:2404.01318 , year =
work page internal anchor Pith review arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.