Recognition: no theorem link
OptArgus: A Multi-Agent System to Detect Hallucinations in LLM-based Optimization Modeling
Pith reviewed 2026-05-13 06:31 UTC · model grok-4.3
The pith
OptArgus deploys a conductor-plus-specialist multi-agent architecture and a new four-category hallucination taxonomy to detect structural errors in LLM-generated optimization models more reliably than single-agent baselines on a three-part benchmark.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Against a matched single-agent baseline, OptArgus produces fewer false alarms on clean artifacts, more accurate top-ranked localization on controlled single-error cases, and stronger detection on natural model outputs.
Load-bearing premise
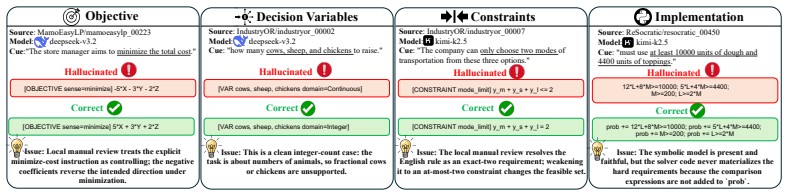
That the four-category hallucination taxonomy (objective, variable, constraint, implementation) comprehensively captures the structural inconsistencies that matter for optimization modeling correctness.
Figures


read the original abstract
Large language models (LLMs) are increasingly used to translate natural-language optimization problems into mathematical formulations and solver code, but matching the reference objective value is not a reliable test of correctness: an artifact may agree numerically while still changing the underlying optimization semantics. We formulate this issue as \emph{optimization-modeling hallucination detection}, namely structural consistency auditing over the problem description, symbolic model, and solver implementation. We develop, to our knowledge, the first fine-grained hallucination taxonomy specifically for optimization modeling, spanning objective, variable, constraint, and implementation failures. We use this taxonomy to design OptArgus, a multi-agent detector with conductor routing, specialist auditors, and evidence consolidation. To evaluate this setting, we introduce a three-part benchmark suite with $484$ clean artifacts, $1266$ controlled injected artifacts, and $6292$ natural LLM-generated artifacts. Against a matched single-agent baseline, OptArgus produces fewer false alarms on clean artifacts, more accurate top-ranked localization on controlled single-error cases, and stronger detection on natural model outputs. Together, these contributions turn optimization-modeling hallucination detection into a concrete empirical problem and suggest that modular, taxonomy-grounded auditing is a practical route to more reliable optimization modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a four-category taxonomy (objective, variable, constraint, implementation) for hallucinations in LLM-generated optimization models, proposes OptArgus as a multi-agent detector with conductor routing and specialist auditors, and presents a three-part benchmark (484 clean artifacts, 1266 controlled injected artifacts, 6292 natural LLM-generated artifacts) on which OptArgus outperforms a matched single-agent baseline in false-alarm rate, top-ranked localization, and detection strength.
Significance. If the central claims hold, the work converts optimization-modeling hallucination detection into a concrete empirical task and shows that taxonomy-grounded modular auditing can reduce false positives and improve localization relative to single-agent baselines. The introduced benchmark suite would be a reusable resource for the community.
major comments (2)
- [Evaluation] Evaluation section: the 1266 controlled injected artifacts are constructed by applying errors drawn exclusively from the four-category taxonomy, so reported gains in localization accuracy on single-error cases and stronger detection on natural outputs are measured against a taxonomy-defined benchmark; this does not test whether other structural inconsistencies (e.g., incorrect solver tolerances, duality violations, or scaling-induced instability) exist and would be missed by the specialist auditors.
- [Benchmark] Benchmark construction for the 6292 natural artifacts: detection strength is reported without an independent ground-truth process that could reveal missed hallucination categories, leaving open the possibility that the multi-agent advantage is inflated by systematic under-detection outside the taxonomy.
minor comments (2)
- [Abstract] The abstract states 'to our knowledge, the first fine-grained taxonomy'; a brief related-work paragraph should explicitly compare against any prior taxonomies in code generation or mathematical reasoning to support this claim.
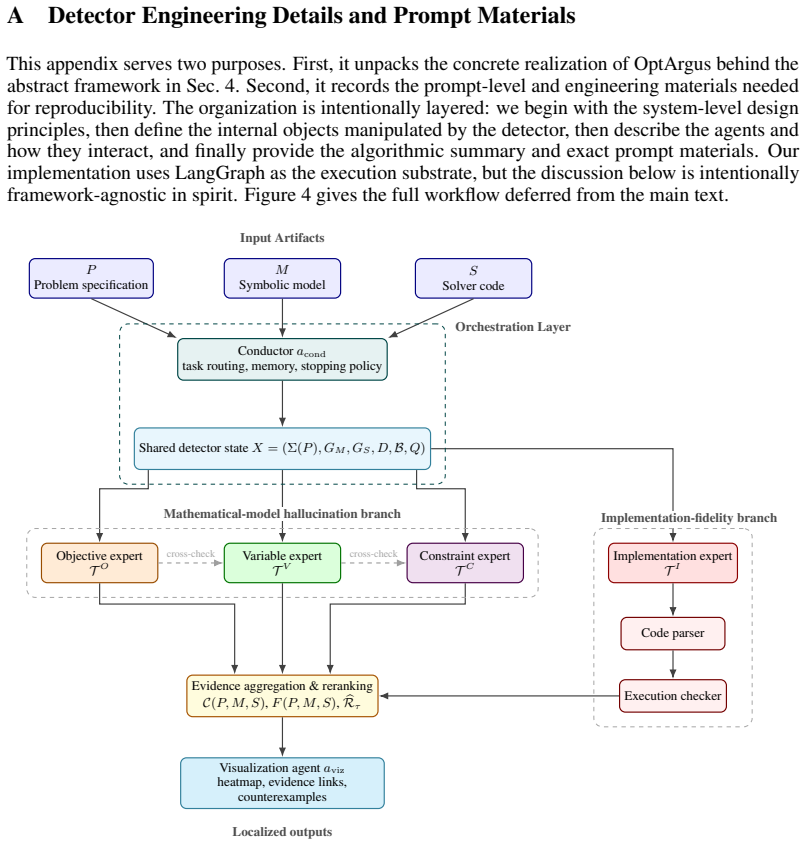
- [Methods] Methods description of the conductor routing and evidence consolidation steps would benefit from a small diagram or pseudocode to clarify the information flow between agents.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback. We address each major comment below, acknowledging valid points about benchmark scope while clarifying the design rationale and planned revisions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the 1266 controlled injected artifacts are constructed by applying errors drawn exclusively from the four-category taxonomy, so reported gains in localization accuracy on single-error cases and stronger detection on natural outputs are measured against a taxonomy-defined benchmark; this does not test whether other structural inconsistencies (e.g., incorrect solver tolerances, duality violations, or scaling-induced instability) exist and would be missed by the specialist auditors.
Authors: We agree that the controlled artifacts are generated exclusively from the four-category taxonomy by design, which enables controlled measurement of detection and localization performance within those categories. Issues such as solver tolerances, duality violations, or scaling instability are typically downstream effects or implementation details rather than primary structural hallucinations in the modeling phase. In the revision we will add an explicit discussion of the taxonomy scope, note these as candidate extensions for future work, and clarify that the evaluation targets modeling-level structural consistency as defined in the paper. revision: partial
-
Referee: [Benchmark] Benchmark construction for the 6292 natural artifacts: detection strength is reported without an independent ground-truth process that could reveal missed hallucination categories, leaving open the possibility that the multi-agent advantage is inflated by systematic under-detection outside the taxonomy.
Authors: The natural artifacts are assessed relative to the taxonomy because constructing fully independent ground truth across all conceivable error types would require large-scale expert annotation outside the current study scope. The reported gains are comparative (OptArgus vs. single-agent baseline) within the taxonomy-defined setting. We will revise the manuscript to include a dedicated limitations paragraph that explicitly states this boundary and notes that undetected categories outside the taxonomy remain possible. revision: partial
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Structural consistency between problem description, symbolic model, and solver implementation is a valid proxy for detecting optimization-modeling hallucinations
invented entities (2)
-
OptArgus multi-agent detector with conductor routing and specialist auditors
no independent evidence
-
Four-category hallucination taxonomy (objective, variable, constraint, implementation)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Extract a faithful semantic schema from the natural-language problem specification
-
[2]
Separate hard requirements from soft preferences
-
[3]
Summarize the objective intent, entities, parameters, index sets, and implementation-sensitive details.,→
-
[4]
Decide which specialist modules should actually be invoked for this case
-
[5]
Important rules: - Do not invent missing business rules
Produce routing guidance for the selected specialists. Important rules: - Do not invent missing business rules. - If the problem statement is underspecified, record an explicit assumption. - Stay neutral: you are not yet deciding whether the model is correct, only preparing the audit. - Keep the output faithful to the text because downstream experts will ...
-
[6]
Focus only on objective-function issues
-
[7]
Compare the natural-language objective intent against the symbolic model
-
[8]
Use the most specific hallucination type justified by the evidence
-
[9]
If the root cause is really a variable, constraint, or implementation issue, record it as an unresolved dependency rather than mislabeling it as an objective error.,→
-
[10]
Quote short evidence spans from the problem and symbolic model whenever possible
-
[11]
Use taxonomy-grounded examples when explaining why a pattern is suspicious
-
[12]
Do not emit downstream consequences of the same objective mistake as separate findings.,→
Emit atomic root-cause findings only. Do not emit downstream consequences of the same objective mistake as separate findings.,→
-
[13]
Those belong to the implementation expert.,→
Do not use solver-code-only issues to justify an objective finding in this module. Those belong to the implementation expert.,→
-
[14]
If the problem text states a clear objective sense such as`minimize cost`or`maximize profit`, and the symbolic model reverses that sense, prefer`Wrong Optimization Direction` even if other missing constraints are also present. ,→ ,→
-
[15]
If the problem text and symbolic model disagree on objective sense, prefer an objective finding even when the solver code happens to align with the problem text. A code path that merely compensates for a symbolic objective reversal should not suppress the primary objective diagnosis. ,→ ,→ ,→ 19
-
[16]
If the objective omits or misbinds one entity/index while the rest of the formulation is structurally similar, prefer`Wrong Index Range`,`Misaligned Time Indices`, or`Coefficient Misbinding`over a generic omission label. ,→ ,→
-
[17]
Unusual objectives are still valid if the text literally states them
Do not replace an explicitly stated`minimize`/`minimum`/`least`objective with a business-intuition`maximize`interpretation unless the text itself clearly contradicts the symbolic sense. Unusual objectives are still valid if the text literally states them. ,→ ,→ Output instructions: - Return at most {max_findings} findings, but prefer 0-3 unique root-cause...
-
[18]
Focus on whether the model created the right decision objects
-
[19]
Check dimensions, domains, sign restrictions, index sets, and variable-role couplings
-
[20]
Compare how variables are defined and how they are used in the symbolic objective and symbolic constraints.,→
-
[21]
If a suspicious issue is really caused by objective logic, missing constraints, or code-only divergence, record that as an unresolved dependency rather than forcing a variable label.,→
-
[22]
Use the taxonomy examples to explain why a pattern changes the meaning of the optimization problem.,→
-
[23]
Do not split one variable-design mistake into several paraphrases.,→
Emit atomic root-cause findings only. Do not split one variable-design mistake into several paraphrases.,→
-
[24]
Those belong to the implementation expert.,→
Do not use solver-code-only issues to justify a variable finding in this module. Those belong to the implementation expert.,→
-
[25]
Use`Relaxing a Discrete Variable into a Continuous Variable`only when the problem text or symbolic specification clearly requires whole numbers, binary decisions, counts, yes/no choices, trips, facilities, assignments, or other discrete decisions, but the symbolic model uses a continuous domain. ,→ ,→ ,→
-
[26]
Those are usually constraint or objective issues
Do not relabel wrong coefficients, wrong units, wrong percentages, or missing policy/share constraints as variable errors just because variables appear in those expressions. Those are usually constraint or objective issues. ,→ ,→
- [27]
-
[28]
Treat mixed domains inside one sibling decision family as strong evidence for a variable-domain hallucination. If one`trip`,`ride`,`shipment`,`facility`, or `units-to-produce`variable is continuous while parallel decision variables remain integer or binary, prefer a variable-domain label over a constraint label. ,→ ,→ ,→
-
[29]
In narrative transportation or production problems, phrases such as`how many`,`number of trips`,`quantity to produce`, or`must be a whole number`should strongly increase confidence that the decision is discrete. ,→ ,→
-
[30]
If the decision objects themselves are otherwise correct, do not use`Wrong Variable Object` as a fallback when the real issue is a domain relaxation. Prefer`Relaxing a Discrete Variable into a Continuous Variable`whenever the text clearly implies counts, trips, assignments, facilities, or whole-number quantities. ,→ ,→ ,→
-
[31]
Do not infer integrality from`how many`alone when the surrounding problem is a standard LP, blending, mixture, resource-allocation, or continuous-quantity formulation.,→
-
[32]
If the problem explicitly asks for an LP or otherwise frames the decision as continuous amounts, shares, mixtures, or allocations, abstain from a discrete-relaxation label unless there is a separate explicit integer / binary requirement. ,→ ,→
-
[33]
If your only evidence is a generic counting phrase but there are no strong indivisibility cues such as trips, facilities, yes/no selection, assignments, or explicit whole-number requirements, prefer abstention over a speculative domain hallucination. ,→ ,→
-
[34]
Do not flag`Omitted Index Set`merely because a small fixed family of scalar variables is used instead of a cleaner indexed notation. If the scalar variables faithfully cover the intended decision objects and there is no semantic loss, abstain. ,→ ,→
-
[35]
Do not flag a domain/sign/value-range error when the candidate explanation itself says the current integer/binary domain is already correct, or when the only complaint is that a bound is expressed in variable declarations rather than as a separate explicit constraint. ,→ ,→
-
[36]
If the symbolic model introduces a shadow/alias variable that represents the same business decision as an existing variable, prefer`Duplicate Variable Roles`even when downstream constraints or the objective also become miscounted. ,→ ,→
-
[37]
When a duplicated decision object later causes double counting in a cardinality/budget expression, treat the duplicate variable as the primary root cause and leave the aggregation consequence to dependencies unless there is an independently wrong pooled rule. ,→ ,→ Output instructions: - Return at most {max_findings} findings, but prefer 0-3 unique root-c...
-
[38]
Focus on semantic translation, missing skeletons, implicit rules, logic chains, aggregation/indexing, boundaries, strength, and scheduling-specific structure.,→
-
[39]
Compare the textual rules in the problem with the symbolic constraints
-
[40]
Look for situations where the model stays solvable but is semantically wrong
-
[41]
Use Appendix-B-style example cues to justify the label
-
[42]
If a problem is actually driven by wrong variables or implementation-only code divergence, record it as a dependency instead of forcing a constraint label.,→
-
[43]
Emit atomic root-cause findings only. Do not report both a cause and its obvious downstream consequence as separate findings unless they are independently actionable.,→
-
[44]
Those belong to the implementation expert.,→
Do not use solver-code-only issues to justify a constraint finding in this module. Those belong to the implementation expert.,→
-
[45]
When the missing rule is a percentage, share, quota, composition, or policy-style requirement linking otherwise correct variables, prefer a business-rule or implicit-rule label over a capacity/coverage skeleton label. ,→ ,→
-
[46]
Reserve`Missing Capacity or Coverage Skeleton`for genuinely missing resource, demand, coverage, flow, or capacity structures.,→
-
[47]
Reserve`Missing Default Business Rules`for missing policy constraints, ratio/share requirements, default eligibility rules, or other non-resource business logic that should still be hard constraints. ,→ ,→
-
[48]
If the only issue is a variable domain/type error and the relevant constraint is otherwise correctly stated, leave it to the variable expert instead of forcing a constraint subtype.,→
-
[49]
Use`Wrong Aggregation Level`only when the text requires an explicit pooled or combined limit over multiple variables or entities, but the symbolic model drops that pooled total, replaces it with separate per-variable bounds, or otherwise collapses the required aggregation structure. ,→ ,→ ,→
-
[50]
Do not use it merely because a constraint contains the word `total`
Prefer`Wrong Aggregation Level`only when the evidence really is about a single joint total such as`pooled total`,`combined total`,`joint budget`,`overall budget`, or an explicit `sum across`construction. Do not use it merely because a constraint contains the word `total`. ,→ ,→ ,→
-
[51]
Use`Missing Capacity or Coverage Skeleton`only when the entire resource/coverage family is absent, not when the family exists but the aggregation granularity is wrong.,→
-
[52]
If the model still has the right variables and a related resource theme but misses the single joint budget, total-hours, total-demand, or pooled-allocation equation, treat it as aggregation/index-coding rather than a generic missing skeleton. But do not relabel ordinary balance, recursion, nutrient minimum, demand minimum, or throughput constraints as agg...
-
[53]
Distinguish carefully between the three high-frequency families: `Wrong Aggregation Level`= a pooled total such as`X+Y`,`all trips`,`combined staff`, `overall budget`, or`sum across modes`is replaced by separate bounds or omitted.,→ `Missing Capacity or Coverage Skeleton`= the model omits an actual resource, demand, flow, nutrition, coverage, or throughpu...
-
[54]
Do not call a nutrient minimum, demand minimum, throughput minimum, flow balance, or total shipped/produced requirement a default business rule. Those are capacity/coverage-style structure unless the issue is specifically a pooled-total aggregation mistake. ,→ ,→
-
[55]
If another module already captures the root cause as an objective-sense reversal, a discrete-variable domain relaxation, or a code-only implementation mismatch, avoid emitting a generic constraint label that would outrank that root cause. ,→ ,→
-
[56]
Use`Missing Initial or Terminal Conditions`when the omitted rule is an explicit lower bound, upper bound, initial state, terminal state, starting inventory, ending inventory, or one-sided boundary condition on an otherwise correctly defined variable or flow. Missing`x <= U`,`x >= L`, start-of-horizon, or end-of-horizon conditions should not be labeled as ...
-
[57]
If the text says`at least`,`at most`,`minimum`,`maximum`,`starts with`,`ends with`, `initial`, or`terminal`, and the symbolic model drops that one-sided or endpoint condition, prefer`Missing Initial or Terminal Conditions`over`Missing Capacity or Coverage Skeleton` or`Missing Default Business Rules`. ,→ ,→ ,→
-
[58]
If a boundary-style constraint is partially present but attached to the wrong variable or wrong side, still prefer`Missing Initial or Terminal Conditions`when the core error is the loss of an explicit bound or endpoint condition. ,→ ,→
-
[59]
Do not upgrade an explicit one-way conditional such as`if A, then not B`into mutual exclusion unless the text clearly states`cannot both`,`either-or`,`incompatible in either direction`, or an equivalent symmetric prohibition. ,→ ,→
-
[60]
Use`Wrong Interpretation of the Rule`only for a clear semantic contradiction. If the current model is a plausible literal reading and the concern is merely an alternative stricter interpretation, abstain instead of emitting a hallucination finding. ,→ ,→ 22
-
[61]
If your own reasoning depends on phrases such as`may imply`,`could imply`,`might imply`, `potential ambiguity`, or`if that interpretation is intended`, that is usually evidence to abstain rather than to label. ,→ ,→
-
[62]
If the real failure is that the symbolic model duplicated or shadowed a decision variable and the pooled total is only downstream double counting, do not relabel that as`Wrong Aggregation Level`; leave it to the variable expert as`Duplicate Variable Roles`. ,→ ,→
-
[63]
Do not flag a percentage/share/quota rule merely because the symbolic model uses an algebraically rearranged linear form. If`omega <= 0.35(total)`is rewritten as an equivalent linear inequality such as`0.65*omega - 0.35*alpha <= 0`, abstain. ,→ ,→
-
[64]
If the omitted rule is a cardinality-style pooled count such as`at most 4 children`,`select at least 3 projects`, or`open no more than k facilities`, prefer`Wrong Aggregation Level` over`Missing Initial or Terminal Conditions`. ,→ ,→ Output instructions: - Return at most {max_findings} findings, but prefer 0-3 unique root-cause findings. - Prefer precise ...
-
[65]
Compare the symbolic model against the code, not just the code against the problem text
-
[66]
Treat the symbolic model as the source of truth for this module. Emit an implementation finding only when the code changes the mathematical object, drops indices, uses the wrong API/domain, or otherwise breaks symbolic-to-code fidelity. ,→ ,→
-
[67]
Record a dependency or note instead.,→
If the symbolic formulation itself is already wrong and the code faithfully mirrors it, do not report an implementation hallucination for that issue. Record a dependency or note instead.,→
-
[68]
Check objective sense, variable domains, loop/index expansion, omitted constraints, solver compatibility, and post-solve reporting.,→
-
[69]
When the symbolic model says`minimize`but the code materializes`maximize`, negates objective coefficients, flips the reported objective sign, or sets the wrong solver API sense, prefer `Wrong Objective Sense in Code`. ,→ ,→
-
[70]
A pure code-level objective-sense reversal is still an implementation hallucination even if the objective terms themselves look numerically similar.,→ 23
-
[71]
Do not flag`Wrong Objective Sense in Code`when the code uses a standard, internally consistent sign-handling convention that still matches the symbolic objective. For example, `minimize`with direct positive coefficients and an inactive post-solve sign flip is not an objective-sense error. ,→ ,→ ,→
-
[72]
Likewise,`maximize`implemented via negated coefficients plus an active post-solve sign correction is not an objective-sense error if it faithfully matches the symbolic objective.,→
-
[73]
Be especially careful with`scipy.optimize.milp`or similar minimization-oriented APIs. A pattern of`c = -c_ref`, followed by solving, followed by`objective_value = -result.fun`for a maximize objective is a standard faithful wrapper, not a hallucination. ,→ ,→
-
[74]
A dead branch such as`if "minimize" == "maximize": objective_value = -objective_value`inside an otherwise ordinary minimization implementation is not, by itself,`Wrong Objective Sense in Code`. If the branch never executes and the solver call already matches the symbolic sense, abstain. ,→ ,→ ,→
-
[75]
Do not flag`Wrong Bounds in Code`or`Omitted Constraint Materialization`when the only difference is an equivalent presentation style, such as encoding a lower/upper bound in the solver`Bounds`object instead of duplicating it as a separate linear row, or encoding an equality as a pair of matching`>=`and`<=`rows. ,→ ,→ ,→
-
[76]
If the candidate explanation itself admits that the implementation already matches the symbolic model, that no divergence exists, or that no fix is needed, abstain instead of emitting an implementation finding. ,→ ,→
- [77]
-
[78]
Use short evidence spans from code and symbolic text
-
[79]
Emit atomic root-cause findings only. Do not restate a symbolic modeling error unless the code introduces an additional independent divergence.,→
-
[80]
If the problem text and symbolic model already disagree on objective direction, do not let a code path that matches the textual objective suppress the upstream objective diagnosis. In that situation, only emit`Wrong Objective Sense in Code`if the code also diverges from the symbolic model in an independently actionable way. ,→ ,→ ,→
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.