Recognition: 2 theorem links
· Lean TheoremTraining-Inference Consistent Segmented Execution for Long-Context LLMs
Pith reviewed 2026-05-13 06:43 UTC · model grok-4.3
The pith
Making training and inference use identical segment-level execution lets long-context LLMs match full attention performance with much lower memory costs at scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
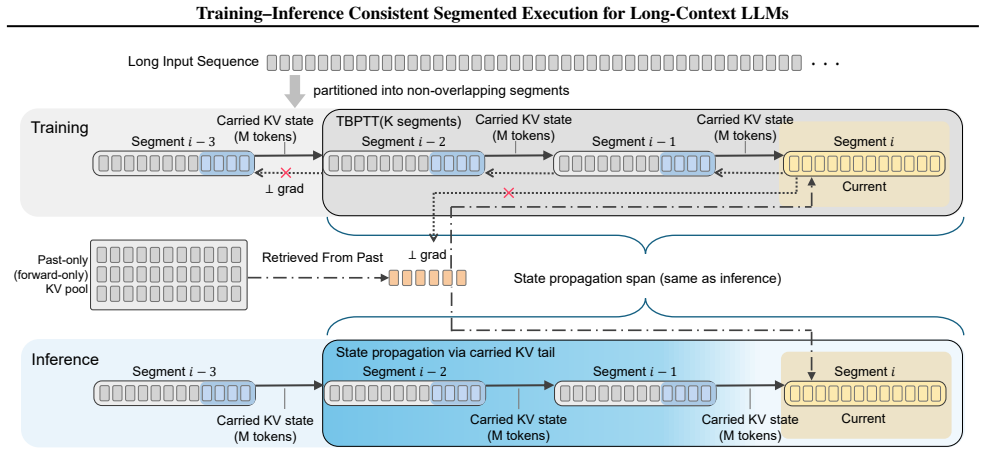
The central discovery is a training-inference consistent segment-level generation framework. Training restricts gradient propagation to KV states carried over from the immediately preceding segment but permits head-specific access to past KV states during the forward pass without involving them in gradients. This consistency yields performance on par with full-context attention across long-context benchmarks and improves scalability, including roughly 6x lower peak prefill memory at 128K compared to full attention with FlashAttention.
What carries the argument
The segment-level forward execution in which gradient flow is limited to KV states from the prior segment only while full historical KV access remains available in the forward pass.
If this is right
- Accuracy on long-context benchmarks stays comparable to full-context attention training.
- Peak prefill memory drops substantially at very long lengths, reaching approximately 6x reduction at 128K.
- Latency-memory trade-offs stay competitive with other strong inference-efficient methods.
- Practical scaling to contexts well beyond current limits becomes feasible under fixed hardware budgets.
Where Pith is reading between the lines
- The same consistency rule could be tested with a gradient window of two preceding segments to check whether very-long-range tasks improve further without prohibitive extra cost.
- The principle of aligning train and inference state transitions might extend directly to other bounded-context techniques such as sliding-window attention or ring attention.
- Once trained under fixed segment size, the resulting model could support variable segment lengths at inference time to match different hardware memory constraints.
Load-bearing premise
Restricting gradient updates to KV states from only the immediately previous segment remains sufficient for the model to learn dependencies that span many segments.
What would settle it
Train the same base model with this segmented gradient rule versus full attention on a long-context task whose correct answers require information crossing more than one segment boundary, then measure whether accuracy falls by a large margin.
Figures





read the original abstract
Transformer-based large language models face severe scalability challenges in long-context generation due to the computational and memory costs of full-context attention. Under practical computation and memory constraints, many inference-efficient long-context methods improve efficiency by adopting bounded-context or segment-level execution only during inference, while continuing to train models under full-context attention, resulting in a mismatch between training and inference execution and state-transition semantics. Based on this insight, we propose a training-inference consistent segment-level generation framework, in which training and inference follow the same segment-level forward execution semantics. During training, consistency with inference is enforced by restricting gradient propagation to KV states carried over from the immediately preceding segment, while permitting head-specific access to past KV states during the forward pass without involving them in gradient propagation. Across long-context benchmarks, our approach achieves performance comparable to full-context attention, while achieving competitive latency-memory trade-offs against strong inference-efficient baselines, and substantially improving scalability at very long context lengths (e.g., approximately 6x lower peak prefill memory at 128K compared to full-context attention with FlashAttention).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a training-inference consistent segmented execution framework for long-context LLMs. Training and inference both use segment-level forward execution; consistency is enforced by restricting gradient propagation during training exclusively to KV states carried over from the immediately preceding segment, while still permitting head-specific access to past KV states in the forward pass. The central empirical claim is that this yields performance comparable to full-context attention on long-context benchmarks, competitive latency-memory trade-offs versus strong inference-efficient baselines, and approximately 6x lower peak prefill memory at 128K context lengths relative to full-context attention with FlashAttention.
Significance. If the gradient-restriction mechanism preserves the capacity to learn multi-segment dependencies, the work would resolve a fundamental train-inference mismatch in long-context modeling and deliver a practical route to scalable segment-level execution without performance degradation. The reported memory reduction at 128K would constitute a concrete engineering advance if the experimental controls are shown to be sound.
major comments (2)
- [§3 (Training Procedure)] The training procedure restricts gradients to KV states from only the immediately preceding segment (one-segment truncated back-propagation). This assumption is load-bearing for the claim of comparability to full-context attention, yet the manuscript provides no ablation that isolates the effect of this truncation window, no analysis of segment length or number of segments used in training, and no demonstration that dependencies spanning multiple segment boundaries remain learnable.
- [§4 (Experiments)] The experimental claims (comparable benchmark performance and 6x peak prefill memory reduction at 128K) are presented without reported variance, exact baseline implementations, segment counts during training, or controls that separate the gradient restriction from other implementation choices. These omissions make it impossible to verify that the observed results are attributable to the proposed consistency mechanism rather than other factors.
minor comments (2)
- [§3] Clarify in the method description whether the head-specific access to past KV states during the forward pass uses the same attention masking as standard full-context attention or introduces additional implementation details that affect semantics.
- [§3] Add explicit definitions or pseudocode for the segment boundary handling and KV carry-over mechanism to make the forward/backward pass semantics reproducible from the text alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for clarification and strengthening, particularly around the training procedure and experimental rigor. We address each major comment below and will revise the manuscript accordingly to improve transparency and address the concerns.
read point-by-point responses
-
Referee: [§3 (Training Procedure)] The training procedure restricts gradients to KV states from only the immediately preceding segment (one-segment truncated back-propagation). This assumption is load-bearing for the claim of comparability to full-context attention, yet the manuscript provides no ablation that isolates the effect of this truncation window, no analysis of segment length or number of segments used in training, and no demonstration that dependencies spanning multiple segment boundaries remain learnable.
Authors: We acknowledge that the current manuscript lacks explicit ablations isolating the truncation window and detailed analysis of segment configurations. The one-segment gradient restriction is chosen to enforce exact training-inference consistency with the segment-level forward pass used at inference time. In the revised version, we will add an ablation comparing one-segment versus two-segment gradient propagation on a subset of long-context tasks to quantify the impact. We will also specify the training segment length (4K tokens) and number of segments (e.g., 32 for 128K contexts) and include a brief analysis of performance sensitivity to segment size. For multi-segment dependency learnability, the forward pass permits head-specific access to all prior KV states while gradients flow only through the immediate predecessor; comparable benchmark performance to full-context models on tasks with cross-segment dependencies (e.g., LongBench) serves as evidence that such dependencies are captured via the carried KV states. We will add a short qualitative discussion or synthetic example illustrating information propagation across boundaries. revision: partial
-
Referee: [§4 (Experiments)] The experimental claims (comparable benchmark performance and 6x peak prefill memory reduction at 128K) are presented without reported variance, exact baseline implementations, segment counts during training, or controls that separate the gradient restriction from other implementation choices. These omissions make it impossible to verify that the observed results are attributable to the proposed consistency mechanism rather than other factors.
Authors: We agree that additional experimental details and controls are needed for verifiability. In the revision, we will report standard deviations over 3-5 runs for all benchmark scores, provide exact baseline implementation details (including FlashAttention version and hyperparameters) in an expanded appendix, and explicitly state the training segment counts and lengths. To isolate the gradient restriction, we will add a control comparing our consistent segmented training against a mismatched setup (full-context training followed by segmented inference) on a representative long-context task. Due to compute limits, the control will be performed at a reduced scale (32K contexts) but will still demonstrate the consistency benefit. These additions will make the attribution to the proposed mechanism clearer. revision: partial
Circularity Check
No circularity: method defined directly and validated empirically
full rationale
The paper defines a training-inference consistent segmented execution framework by explicitly restricting gradient flow to KV states from the immediately preceding segment while permitting forward-pass access to earlier states. This is a direct procedural definition rather than a derivation that reduces to its own inputs by construction. No equations are presented that rename fitted parameters as predictions, import uniqueness theorems via self-citation, or smuggle ansatzes. Performance comparability to full-context attention is asserted via benchmark results, not by algebraic equivalence to the training restriction itself. The central assumption about preserving long-range dependency learning is therefore an empirical claim open to falsification on the reported benchmarks, not a self-referential tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer attention can be executed segment-wise while still allowing head-specific access to past KV states in the forward pass.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclearTBPTT with truncation depth K computes the exact gradient of an inference-consistent objective
Reference graph
Works this paper leans on
-
[3]
The Claude 3 Model Family: Opus, Sonnet, Haiku , author =. 2024 , note =
work page 2024
-
[4]
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[5]
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[7]
International conference on algorithmic learning theory , pages=
On the computational complexity of self-attention , author=. International conference on algorithmic learning theory , pages=. 2023 , organization=
work page 2023
-
[8]
The Twelfth International Conference on Learning Representations,
Guangxuan Xiao and Yuandong Tian and Beidi Chen and Song Han and Mike Lewis , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[10]
The Twelfth International Conference on Learning Representations,
Tri Dao , title =. The Twelfth International Conference on Learning Representations,. 2024 , url =
work page 2024
-
[13]
The Thirteenth International Conference on Learning Representations,
Wenhao Wu and Yizhong Wang and Guangxuan Xiao and Hao Peng and Yao Fu , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[14]
Recurrent Memory Transformer , booktitle =
Aydar Bulatov and Yuri Kuratov and Mikhail Burtsev , editor =. Recurrent Memory Transformer , booktitle =. 2022 , timestamp =
work page 2022
-
[15]
Fu and Stefano Ermon and Atri Rudra and Christopher R
Tri Dao and Daniel Y. Fu and Stefano Ermon and Atri Rudra and Christopher R. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness , booktitle =. 2022 , timestamp =
work page 2022
-
[17]
FlexGen: High-Throughput Generative Inference of Large Language Models with a Single
Ying Sheng and Lianmin Zheng and Binhang Yuan and Zhuohan Li and Max Ryabinin and Beidi Chen and Percy Liang and Christopher R. FlexGen: High-Throughput Generative Inference of Large Language Models with a Single. International Conference on Machine Learning,. 2023 , url =
work page 2023
-
[19]
Abdi and Dongsheng Li and Chin
Huiqiang Jiang and Yucheng Li and Chengruidong Zhang and Qianhui Wu and Xufang Luo and Surin Ahn and Zhenhua Han and Amir H. Abdi and Dongsheng Li and Chin. MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention , booktitle =. 2024 , timestamp =
work page 2024
-
[21]
Forty-second International Conference on Machine Learning,
Yaofo Chen and Zeng You and Shuhai Zhang and Haokun Li and Yirui Li and Yaowei Wang and Mingkui Tan , title =. Forty-second International Conference on Machine Learning,. 2025 , url =
work page 2025
-
[22]
Matthew Raffel and Drew Penney and Lizhong Chen , editor =. Shiftable Context: Addressing Training-Inference Context Mismatch in Simultaneous Speech Translation , booktitle =. 2023 , url =
work page 2023
-
[25]
Rae and Anna Potapenko and Siddhant M
Jack W. Rae and Anna Potapenko and Siddhant M. Jayakumar and Chloe Hillier and Timothy P. Lillicrap , title =. 8th International Conference on Learning Representations,. 2020 , url =
work page 2020
-
[26]
The Tenth International Conference on Learning Representations,
Yuhuai Wu and Markus Norman Rabe and DeLesley Hutchins and Christian Szegedy , title =. The Tenth International Conference on Learning Representations,. 2022 , url =
work page 2022
-
[27]
The Thirteenth International Conference on Learning Representations,
Guangxuan Xiao and Jiaming Tang and Jingwei Zuo and Junxian Guo and Shang Yang and Haotian Tang and Yao Fu and Song Han , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
work page 2025
-
[28]
Cheng-Ping Hsieh and Simeng Sun and Samuel Kriman and Shantanu Acharya and Dima Rekesh and Fei Jia and Boris Ginsburg , booktitle=. 2024 , url=
work page 2024
-
[29]
Forty-first International Conference on Machine Learning,
Yao Fu and Rameswar Panda and Xinyao Niu and Xiang Yue and Hannaneh Hajishirzi and Yoon Kim and Hao Peng , title =. Forty-first International Conference on Machine Learning,. 2024 , url =
work page 2024
-
[31]
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , booktitle =
Jingyang Yuan and Huazuo Gao and Damai Dai and Junyu Luo and Liang Zhao and Zhengyan Zhang and Zhenda Xie and Yuxing Wei and Lean Wang and Zhiping Xiao and Yuqing Wang and Chong Ruan and Ming Zhang and Wenfeng Liang and Wangding Zeng , editor =. Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention , booktitle =. 2025 , url =
work page 2025
-
[33]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Gulavani, and Ramachandran Ramjee
Agrawal, A., Panwar, A., Mohan, J., Kwatra, N., Gulavani, B. S., and Ramjee, R. SARATHI: efficient LLM inference by piggybacking decodes with chunked prefills. CoRR, abs/2308.16369, 2023. doi:10.48550/ARXIV.2308.16369. URL https://doi.org/10.48550/arXiv.2308.16369
-
[35]
The claude 3 model family: Opus, sonnet, haiku, 2024
Anthropic . The claude 3 model family: Opus, sonnet, haiku, 2024. Technical report
work page 2024
-
[36]
Longbench: A bilingual, multitask benchmark for long context understanding
Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., et al. Longbench: A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pp.\ 3119--3137, 2024
work page 2024
-
[37]
Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks
Bai, Y., Tu, S., Zhang, J., Peng, H., Wang, X., Lv, X., Cao, S., Xu, J., Hou, L., Dong, Y., et al. Longbench v2: Towards deeper understanding and reasoning on realistic long-context multitasks. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 3639--3664, 2025
work page 2025
-
[38]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Longformer: The long-document transformer. CoRR, abs/2004.05150, 2020. URL https://arxiv.org/abs/2004.05150
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[39]
Bulatov, A., Kuratov, Y., and Burtsev, M. Recurrent memory transformer. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022
work page 2022
-
[40]
Core context aware transformers for long context language modeling
Chen, Y., You, Z., Zhang, S., Li, H., Li, Y., Wang, Y., and Tan, M. Core context aware transformers for long context language modeling. In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=MAHPZNduS4
work page 2025
-
[41]
Dai, Z., Yang, Z., Yang, Y., Carbonell, J. G., Le, Q. V., and Salakhutdinov, R. Transformer-xl: Attentive language models beyond a fixed-length context. In Korhonen, A., Traum, D. R., and M \` a rquez, L. (eds.), Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume ...
-
[42]
Flashattention-2: Faster attention with better parallelism and work partitioning
Dao, T. Flashattention-2: Faster attention with better parallelism and work partitioning. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=mZn2Xyh9Ec
work page 2024
-
[43]
Y., Ermon, S., Rudra, A., and R \' e , C
Dao, T., Fu, D. Y., Ermon, S., Rudra, A., and R \' e , C. Flashattention: Fast and memory-efficient exact attention with io-awareness. In Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Or...
work page 2022
-
[44]
Data engineering for scaling language models to 128k context
Fu, Y., Panda, R., Niu, X., Yue, X., Hajishirzi, H., Kim, Y., and Peng, H. Data engineering for scaling language models to 128k context. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=TaAqeo7lUh
work page 2024
-
[45]
Sliding window attention training for efficient large language models
Fu, Z., Song, W., Wang, Y., Wu, X., Zheng, Y., Zhang, Y., Xu, D., Wei, X., Xu, T., and Zhao, X. Sliding window attention training for efficient large language models. CoRR, abs/2502.18845, 2025. doi:10.48550/ARXIV.2502.18845. URL https://doi.org/10.48550/arXiv.2502.18845
-
[46]
Lm-infinite: Zero-shot extreme length generalization for large language models
Han, C., Wang, Q., Peng, H., Xiong, W., Chen, Y., Ji, H., and Wang, S. Lm-infinite: Zero-shot extreme length generalization for large language models. In Duh, K., G \' o mez - Adorno, H., and Bethard, S. (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V...
-
[47]
What matters in transformers? not all attention is needed
He, S., Sun, G., Shen, Z., and Li, A. What matters in transformers? not all attention is needed. CoRR, abs/2406.15786, 2024. doi:10.48550/ARXIV.2406.15786. URL https://doi.org/10.48550/arXiv.2406.15786
-
[48]
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., and Ginsburg, B. RULER : What s the Real Context Size of Your Long - Context Language Models ? In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=kIoBbc76Sy
work page 2024
-
[49]
H., Li, D., Lin, C., Yang, Y., and Qiu, L
Jiang, H., Li, Y., Zhang, C., Wu, Q., Luo, X., Ahn, S., Han, Z., Abdi, A. H., Li, D., Lin, C., Yang, Y., and Qiu, L. Minference 1.0: Accelerating pre-filling for long-context llms via dynamic sparse attention. In Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J. M., and Zhang, C. (eds.), Advances in Neural Information Processing S...
work page 2024
-
[50]
Keles, F. D., Wijewardena, P. M., and Hegde, C. On the computational complexity of self-attention. In International conference on algorithmic learning theory, pp.\ 597--619. PMLR, 2023
work page 2023
-
[51]
Efficient memory management for large language model serving with pagedattention
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C. H., Gonzalez, J., Zhang, H., and Stoica, I. Efficient memory management for large language model serving with pagedattention. In Flinn, J., Seltzer, M. I., Druschel, P., Kaufmann, A., and Mace, J. (eds.), Proceedings of the 29th Symposium on Operating Systems Principles, SOSP 2023, Koblenz, German...
-
[52]
Chunkkv: Semantic-preserving KV cache compression for efficient long-context LLM inference
Liu, X., Tang, Z., Dong, P., Li, Z., Li, B., Hu, X., and Chu, X. Chunkkv: Semantic-preserving KV cache compression for efficient long-context LLM inference. CoRR, abs/2502.00299, 2025. doi:10.48550/ARXIV.2502.00299. URL https://doi.org/10.48550/arXiv.2502.00299
-
[53]
W., Potapenko, A., Jayakumar, S
Rae, J. W., Potapenko, A., Jayakumar, S. M., Hillier, C., and Lillicrap, T. P. Compressive transformers for long-range sequence modelling. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020 . OpenReview.net, 2020. URL https://openreview.net/forum?id=SylKikSYDH
work page 2020
-
[54]
Shiftable context: Addressing training-inference context mismatch in simultaneous speech translation
Raffel, M., Penney, D., and Chen, L. Shiftable context: Addressing training-inference context mismatch in simultaneous speech translation. In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA , volume 202 of Proceedings of...
work page 2023
-
[55]
Flexgen: High-throughput generative inference of large language models with a single GPU
Sheng, Y., Zheng, L., Yuan, B., Li, Z., Ryabinin, M., Chen, B., Liang, P., R \' e , C., Stoica, I., and Zhang, C. Flexgen: High-throughput generative inference of large language models with a single GPU . In Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., and Scarlett, J. (eds.), International Conference on Machine Learning, ICML 2023, 23-...
work page 2023
-
[56]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Team, G., Georgiev, P., Lei, V. I., Burnell, R., Bai, L., Gulati, A., Tanzer, G., Vincent, D., Pan, Z., Wang, S., et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[59]
Retrieval head mechanistically explains long-context factuality
Wu, W., Wang, Y., Xiao, G., Peng, H., and Fu, Y. Retrieval head mechanistically explains long-context factuality. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=EytBpUGB1Z
work page 2025
-
[60]
N., Hutchins, D., and Szegedy, C
Wu, Y., Rabe, M. N., Hutchins, D., and Szegedy, C. Memorizing transformers. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=TrjbxzRcnf-
work page 2022
-
[61]
Efficient streaming language models with attention sinks
Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M. Efficient streaming language models with attention sinks. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=NG7sS51zVF
work page 2024
-
[62]
Duoattention: Efficient long-context LLM inference with retrieval and streaming heads
Xiao, G., Tang, J., Zuo, J., Guo, J., Yang, S., Tang, H., Fu, Y., and Han, S. Duoattention: Efficient long-context LLM inference with retrieval and streaming heads. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net, 2025. URL https://openreview.net/forum?id=cFu7ze7xUm
work page 2025
-
[63]
Native sparse attention: Hardware-aligned and natively trainable sparse attention
Yuan, J., Gao, H., Dai, D., Luo, J., Zhao, L., Zhang, Z., Xie, Z., Wei, Y., Wang, L., Xiao, Z., Wang, Y., Ruan, C., Zhang, M., Liang, W., and Zeng, W. Native sparse attention: Hardware-aligned and natively trainable sparse attention. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Proceedings of the 63rd Annual Meeting of the Association...
work page 2025
-
[64]
Infllm-v2: Dense-sparse switchable attention for seamless short-to-long adaptation
Zhao, W., Zhou, Z., Su, Z., Xiao, C., Li, Y., Li, Y., Zhang, Y., Zhao, W., Li, Z., Huang, Y., Sun, A., Han, X., and Liu, Z. Infllm-v2: Dense-sparse switchable attention for seamless short-to-long adaptation. CoRR, abs/2509.24663, 2025. doi:10.48550/ARXIV.2509.24663. URL https://doi.org/10.48550/arXiv.2509.24663
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.