Recognition: no theorem link
Towards Visually Grounded Multimodal Summarization via Cross-Modal Transformer and Gated Attention
Pith reviewed 2026-05-13 06:18 UTC · model grok-4.3
The pith
Aligning visual and language features at matching depths produces more accurate and grounded multimodal summaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
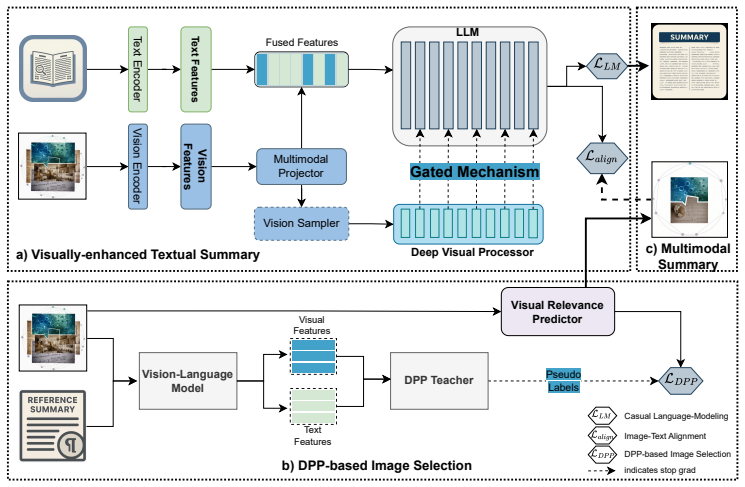
The central claim is that depth-aware fusion via the Deep Visual Processor and principled image selection via the Visual Relevance Predictor together yield summaries that are more accurate and visually grounded while also selecting more representative images than existing shallow-injection approaches.
What carries the argument
The Deep Visual Processor (DVP), which aligns visual encoder outputs with language model layers at corresponding depths to enable hierarchical cross-modal fusion and preserve semantic consistency.
If this is right
- Summaries become more accurate and better grounded in visual content.
- Image selection improves in both salience and diversity.
- Hierarchical fusion maintains semantic consistency across modalities.
- Multi-objective training with alignment and distillation losses boosts overall performance.
Where Pith is reading between the lines
- The depth-alignment idea could extend to other vision-language tasks such as visual question answering to reduce weak grounding.
- DPP-based distillation for selection may apply to other multimodal content curation problems.
- Gated attention combined with layer-wise fusion might scale to larger models where shallow injection causes greater mismatch.
Load-bearing premise
Aligning visual and language features at corresponding depths will preserve semantic consistency without introducing new representational mismatches.
What would settle it
An experiment showing that the Deep Visual Processor produces lower summary accuracy or poorer image selection scores than a shallow-injection baseline on standard multimodal summarization benchmarks would falsify the claim.
Figures





read the original abstract
Multimodal summarization requires models to jointly understand textual and visual inputs to generate concise, semantically coherent summaries. Existing methods often inject shallow visual features into deep language models, leading to representational mismatches and weak cross-modal grounding. We propose a unified framework that jointly performs text summarization and representative image selection. Our system, SPeCTrA-Sum (Sampler Perceiver with Cross-modal Transformer and gated Attention for Summarization), introduces two key innovations. First, a Deep Visual Processor (DVP) aligns the visual encoder with the language model at corresponding depths, enabling hierarchical, layer-wise fusion that preserves semantic consistency. Second, a lightweight Visual Relevance Predictor (VRP) selects salient and diverse images by distilling soft labels from a Determinantal Point Processes (DPP) teacher. SPeCTrA-Sum is trained using a multi-objective loss that combines autoregressive summarization, cross-modal alignment, and DPP-based distillation. Experiments show that our system produces more accurate, visually grounded summaries and selects more representative images, demonstrating the benefits of depth-aware fusion and principled image selection for multimodal summarization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPeCTrA-Sum, a multimodal summarization framework that performs joint text summarization and representative image selection. It introduces a Deep Visual Processor (DVP) for layer-wise alignment and hierarchical fusion between visual and language encoders, plus a Visual Relevance Predictor (VRP) that distills soft labels from a DPP teacher to select salient and diverse images. Training uses a multi-objective loss combining autoregressive summarization, cross-modal alignment, and DPP-based distillation. The central claim is that depth-aware fusion avoids representational mismatches of shallow injection and yields more accurate, visually grounded summaries with better image selection.
Significance. If the empirical claims hold, the work would offer a concrete architectural fix for cross-modal grounding in summarization by replacing shallow feature injection with depth-matched fusion, plus a principled (DPP-distilled) approach to image selection. The multi-objective training and explicit distillation from a diversity-promoting teacher are positive design choices that could generalize beyond this task.
major comments (2)
- [§3.1] §3.1 (Deep Visual Processor): The motivation for DVP rests on the premise that visual-encoder layer d and language-model layer d encode semantically corresponding granularities, enabling 'hierarchical, layer-wise fusion that preserves semantic consistency.' No layer-wise similarity analysis, canonical correlation, or ablation isolating depth correspondence (versus other fusion hyperparameters) is reported; without this, the superiority claim over shallow injection cannot be evaluated and the central architectural contribution remains unverified.
- [§4] §4 (Experiments): The abstract and results section assert that the system 'produces more accurate, visually grounded summaries and selects more representative images,' yet supply no concrete metrics (ROUGE, CIDEr, image-relevance scores), baselines, or ablation tables isolating DVP depth-matching from VRP or the multi-objective loss. This absence makes it impossible to assess effect sizes or rule out that gains arise from other factors.
minor comments (2)
- [§3.2] Notation for the gated attention mechanism and the exact form of the cross-modal alignment loss term should be written out explicitly (currently only described at high level) to allow reproduction.
- [§3.3] The DPP teacher is introduced without stating the kernel or diversity parameter; these hyperparameters need to be reported for the distillation procedure to be reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for stronger empirical verification of the DVP design and clearer presentation of experimental results. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Deep Visual Processor): The motivation for DVP rests on the premise that visual-encoder layer d and language-model layer d encode semantically corresponding granularities, enabling 'hierarchical, layer-wise fusion that preserves semantic consistency.' No layer-wise similarity analysis, canonical correlation, or ablation isolating depth correspondence (versus other fusion hyperparameters) is reported; without this, the superiority claim over shallow injection cannot be evaluated and the central architectural contribution remains unverified.
Authors: We agree that explicit verification of the layer-wise correspondence assumption would strengthen the central claim. The DVP design draws from established observations in multimodal pretraining literature that corresponding encoder depths tend to align on semantic granularity, but the current version does not report direct analyses such as CCA or layer-wise similarity metrics. In revision we will add a dedicated analysis subsection (new §3.1.1) containing (i) layer-wise canonical correlation coefficients between the visual and language encoders on held-out data and (ii) an ablation table comparing depth-matched fusion against random-layer and shallow-injection baselines while holding other hyperparameters fixed. This will allow direct evaluation of whether the hierarchical alignment contributes beyond alternative fusion strategies. revision: yes
-
Referee: [§4] §4 (Experiments): The abstract and results section assert that the system 'produces more accurate, visually grounded summaries and selects more representative images,' yet supply no concrete metrics (ROUGE, CIDEr, image-relevance scores), baselines, or ablation tables isolating DVP depth-matching from VRP or the multi-objective loss. This absence makes it impossible to assess effect sizes or rule out that gains arise from other factors.
Authors: We acknowledge that the experimental section as currently written does not present the quantitative results with sufficient clarity or granularity. While the manuscript does contain ROUGE, CIDEr, and image-relevance evaluations together with baseline comparisons, the tables and ablations isolating DVP depth-matching, VRP distillation, and the individual loss terms are not sufficiently detailed or prominently placed. In the revised version we will expand §4 with (i) a main results table reporting all primary metrics against strong baselines, (ii) a dedicated ablation table that systematically removes or replaces DVP, VRP, and loss components, and (iii) effect-size statistics and statistical significance tests. These additions will make the claimed improvements directly verifiable and will rule out confounding factors. revision: yes
Circularity Check
No significant circularity; claims rest on proposed architecture and experiments
full rationale
The paper introduces a new framework SPeCTrA-Sum with two explicit innovations: the Deep Visual Processor for layer-wise cross-modal alignment and the Visual Relevance Predictor using DPP distillation. These are presented as architectural choices trained via a multi-objective loss combining autoregressive summarization, alignment, and distillation. No equations or derivations reduce a claimed prediction to a fitted input by construction, nor do any load-bearing steps rely on self-citations that themselves assume the target result. The central claims about improved accuracy and image selection are tied to experimental outcomes rather than self-referential definitions or renamed known patterns. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ding, Xiaowen and Liu, Bing and Yu, Philip S , pages =. 2008 , booktitle =
work page 2008
-
[2]
Appel, Orestes and Chiclana, Francisco and Carter, Jenny and Fujita, Hamido , pages =. 2016 , journal =
work page 2016
-
[3]
Sarpiri, Mona Mona Mona Najafi and Gandomani, Taghi Javdani and Teymourzadeh, Mahsa and Motamedi, Akram , number =. 2018 , journal =
work page 2018
-
[4]
Wu, Chuhan and Wu, Fangzhao and Wu, Sixing and Yuan, Zhigang and Huang, Yongfeng , pages =. 2018 , journal =
work page 2018
-
[5]
Bajaj, Simran and Garg, Niharika and Singh, Sandeep Kumar , pages =. 2017 , journal =
work page 2017
-
[6]
Bajaj, Simran and Garg, Niharika and Singh, Sandeep Kumar , pages =. 2017 , booktitle =. doi:10.1016/j.procs.2017.11.467 , issn =
- [7]
-
[8]
ieeexplore.ieee.org , author =
- [9]
-
[10]
Gerani, Shima and Mehdad, Yashar and Carenini, Giuseppe and Ng, Raymond T and Nejat, Bita , pages =. 2014 , booktitle =
work page 2014
-
[11]
Naveed, Nasir and Gottron, Thomas and Rauf, Zahid , number =. 2018 , journal =
work page 2018
- [12]
-
[13]
doi:10.1016/j.eswa.2007.05.028 , keywords =
Elsevier , author =. doi:10.1016/j.eswa.2007.05.028 , keywords =
- [14]
-
[15]
Rafae, Abdul and Qayyum, Abdul and Moeenuddin, Muhammad and Karim, Asim and Sajjad, Hassan and Kamiran, Faisal , pages =. 2015 , booktitle =
work page 2015
- [16]
-
[17]
Liu, Jie and Fu, Xiaodong and Liu, Jin and Sun, Yunchuan , pages =. 2017 , journal =
work page 2017
-
[18]
Andrea, Alessia D ' and Ferri, Fernando and Grifoni, Patrizia , number =. 2015 , booktitle =
work page 2015
-
[19]
Chen, Ning and Lin, Jialiu and Hoi, Steven C.H. and Xiao, Xiaokui and Zhang, Boshen , number =. 2014 , booktitle =. doi:10.1145/2568225.2568263 , issn =
-
[20]
Poria, Soujanya and Cambria, Erik and Gelbukh, Alexander , pages =. 2016 , journal =
work page 2016
-
[21]
Maharani, Warih and Widyantoro, Dwi H and Khodra, Masayu Leylia , pages =. 2015 , journal =
work page 2015
- [22]
-
[23]
Khobragade, Shubhangi and Tiwari, Aditya and Patil, C Y and Narke, Vikram , pages =. 2016 , booktitle =
work page 2016
-
[24]
Jaeger, Stefan and Karargyris, Alexandros and Candemir, Sema and Folio, Les and Siegelman, Jenifer and Callaghan, Fiona and Xue, Zhiyun and Palaniappan, Kannappan and Singh, Rahul K and Antani, Sameer and. 2013 , journal =
work page 2013
-
[25]
Ahmad, Wan Siti Halimatul Munirah Wan and Zaki, Wan Mimi Diyana Wan and Fauzi, Mohammad Faizal Ahmad and Tan, Wooi Haw , pages =. 2016 , booktitle =
work page 2016
- [26]
-
[27]
Allahbakhsh, Mohammad and Ignjatovic, Aleksandar and Benatallah, Boualem and Bertino, Elisa and Foo, Norman and. 2013 , booktitle =
work page 2013
- [28]
-
[29]
Liu, Hugo and Singh, Push , number =. 2004 , journal =. doi:10.1023/B:BTTJ.0000047600.45421.6d , issn =
-
[30]
Aghakhani, Hojjat and Machiry, Aravind and Nilizadeh, Shirin and Kruegel, Christopher and Vigna, Giovanni , pages =. 2018 , booktitle =
work page 2018
-
[31]
Aghakhani, Hojjat and MacHiry, Aravind and Nilizadeh, Shirin and Kruegel, Christopher and Vigna, Giovanni , pages =. 2018 , booktitle =. doi:10.1109/SPW.2018.00022 , arxivId =
-
[32]
Mukherjee, Arjun and Liu, Bing and Wang, Junhui and Glance, Natalie and Jindal, Nitin , pages =. 2011 , booktitle =. doi:10.1145/1963192.1963240 , keywords =
-
[33]
Hu, Mengxiao and Xu, Guangxia and Ma, Chuang and Daneshmand, Mahmoud , pages =. 2019 , booktitle =
work page 2019
-
[34]
Wang, Zhuo and Hou, Tingting and Song, Dawei and Li, Zhun and Kong, Tianqi , number =. 2016 , journal =
work page 2016
-
[35]
academic.oup.com , author =
-
[36]
Xu, Guangxia and Qi, Jin and Huang, Deling and Daneshmand, Mahmoud , pages =. 2016 , booktitle =
work page 2016
-
[37]
Sharma, Abhishek and Raju, Daniel and Ranjan, Sutapa , pages =. 2017 , booktitle =
work page 2017
-
[38]
Heydari, Atefeh and Tavakoli, Mohammad ali and Salim, Naomie and Heydari, Zahra , number =. 2015 , journal =. doi:10.1016/j.eswa.2014.12.029 , issn =
- [39]
-
[40]
Mehmood, K and Essam, D and Shafi, K and Access, MK Malik - IEEE and 2019, Undefined , url =. 2019 , journal =
work page 2019
-
[41]
Li, Luyang and Qin, Bing and Ren, Wenjing and Liu, Ting , pages =. 2017 , journal =
work page 2017
-
[42]
dl.acm.org , author =
-
[43]
Chung, Junyoung and Gulcehre, Caglar and Cho, KyungHyun and Bengio, Yoshua , month =. 2014 , journal =
work page 2014
-
[44]
Araque, O and Corcuera-Platas, JF Sánchez-Rada , url =. 2017 , journal =
work page 2017
-
[45]
Fern. 2018 , booktitle =. doi:10.1007/978-3-030-03928-8
-
[46]
Luo, Zhiyi and Huang, Shanshan and Xu, Frank F and Lin, Bill Yuchen and Shi, Hanyuan and Zhu, Kenny , pages =. 2018 , booktitle =
work page 2018
- [47]
-
[48]
Mirtalaie, Monireh Alsadat and Hussain, Omar Khadeer and Chang, Elizabeth and Hussain, Farookh Khadeer , pages =. 2018 , journal =
work page 2018
-
[49]
Sinha, Anusha and Arora, Nishant and Singh, Shipra and Cheema, Mohita and Nazir, Akthar , number =. 2018 , journal =
work page 2018
- [50]
-
[51]
S., Neha and A., Anala , number =. 2018 , journal =. doi:10.5120/ijca2018917316 , keywords =
-
[52]
Dematis, Ioannis and Karapistoli, Eirini and Vakali, Athena , pages =. 2018 , booktitle =
work page 2018
- [53]
-
[54]
Bailey, James and Manoukian, Thomas and Ramamohanarao, Kotagiri , pages =. 2002 , booktitle =. doi:10.1007/3-540-45681-3
-
[55]
Deepa, N Vamsha and Krishna, Nanditha and Kumar, G Hemanth , pages =. 2017 , booktitle =
work page 2017
-
[56]
Naveed, N and Gottron, T and Staab, S , pages =. 2013 , booktitle =
work page 2013
-
[57]
Ott, Myle and Choi, Yejin and Cardie, Claire and Hancock, Jeffrey T , pages =. 2011 , booktitle =
work page 2011
-
[58]
Naveed, Nasir and Gottron, Thomas and Sizov, Sergej and Staab, Steffen , publisher =. 2012 , booktitle =
work page 2012
-
[59]
Wang, Zhuo and Gu, Songmin and Zhao, Xiangnan and Xu, Xiaowei , number =. 2018 , journal =
work page 2018
-
[60]
Xu, Guangxia and Hu, Mengxiao and Ma, Chuang and Daneshmand, Mahmoud , volume =. 2019 , booktitle =. doi:10.1109/ICC.2019.8761650 , issn =
-
[61]
Li, Xiaomeng and Chen, Hao and Qi, Xiaojuan and Dou, Qi and Fu, Chi-Wing and Heng, Pheng-Ann , number =. 2018 , journal =
work page 2018
- [62]
- [63]
-
[64]
Wu, Zhiang and Zhang, Lu and Wang, Youquan and Cao, Jie , pages =. 2018 , booktitle =. doi:10.1007/978-1-4939-7131-2
-
[65]
Saad, Mohd Nizam and Muda, Zurina and Ashaari, Noraidah Sahari and Hamid, Hamzaini Abdul , pages =. 2014 , booktitle =
work page 2014
- [66]
-
[67]
Ziegler, Cai-Nicolas and McNee, Sean M. and Konstan, Joseph A. and Lausen, Georg , pages =. 2005 , booktitle =
work page 2005
-
[68]
Chen, Tao and Xu, Ruifeng and He, Yulan and Wang, Xuan , pages =. 2017 , journal =
work page 2017
-
[69]
Kermany, Daniel and Zhang, Kang and Goldbaum, Michael , volume =. 2018 , journal =
work page 2018
- [70]
-
[71]
Syed, Afraz Z and Aslam, Muhammad and Martinez-Enriquez, Ana Maria , pages =. 2010 , booktitle =
work page 2010
-
[72]
Rehman, Zia Ul and Bajwa, Imran Sarwar , pages =. 2016 , booktitle =
work page 2016
-
[73]
Zotin, Aleksandr and Hamad, Yousif and Simonov, Konstantin and Kurako, Mikhail , pages =. 2019 , journal =
work page 2019
- [74]
- [75]
-
[76]
Singh, Manisha and Kumar, Lokesh and Sinha, Sapna , pages =. 2018 , booktitle =
work page 2018
-
[77]
Singh, Manisha and Kumar, Lokesh and Sinha, Sapna , pages =. 2018 , booktitle =. doi:10.1007/978-981-10-6602-3
-
[78]
Zhao, Jichang and Dong, Li and Wu, Junjie and Xu, Ke , pages =. 2012 , booktitle =. doi:10.1145/2339530.2339772 , keywords =
- [79]
- [80]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.