Recognition: 1 theorem link
· Lean TheoremNavOL: Navigation Policy with Online Imitation Learning
Pith reviewed 2026-05-13 05:48 UTC · model grok-4.3
The pith
NavOL trains a diffusion navigation policy online by collecting optimal path labels from a privileged global planner on its own rollouts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
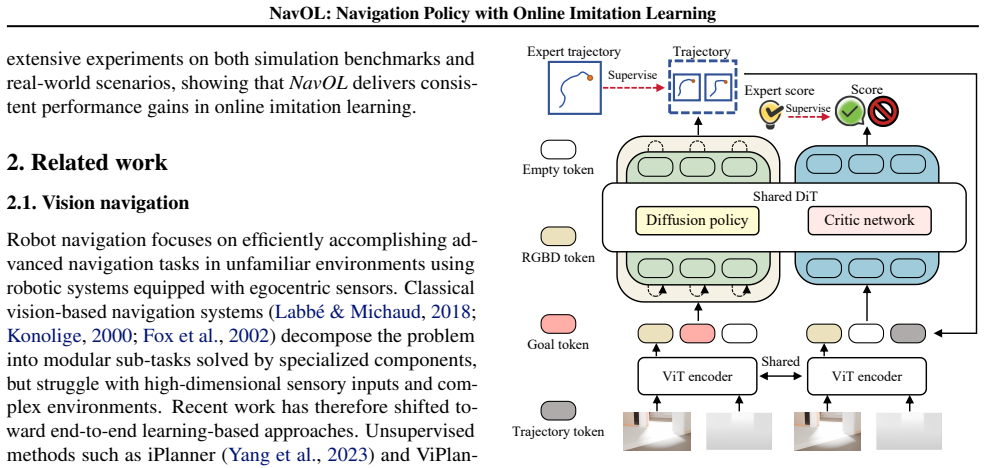
NavOL operates a continuous rollout-update loop. During rollout the diffusion policy acts from local observations in the simulator and receives optimal path segments from a privileged global planner to use as ground-truth trajectory labels; during update the policy is retrained on the newly collected observation-trajectory pairs. This removes any need for reward engineering, places training data exactly on the policy's own distribution, and thereby reduces compounding errors. The implementation on IsaacLab with fast parallel rendering and camera/start-goal randomization collects more than 2,000 trajectories per hour across 50 scenes and supports zero-shot indoor navigation benchmarks.
What carries the argument
The rollout-update loop that pairs a local-observation diffusion policy with privileged global-planner labels collected during the policy's own simulator rollouts.
Load-bearing premise
The global planner with privileged access provides optimal path segments that serve as effective and unbiased ground truth labels for training the local observation-based diffusion policy during its own rollouts.
What would settle it
If the same training loop is run but the global planner is replaced by a noisy or suboptimal label source and the performance advantage over offline imitation learning disappears, the central claim would be falsified.
Figures












read the original abstract
Learning robust navigation policies remains a core challenge in robotics. Offline imitation learning suffers from distribution shift and compounding errors at rollout, while reinforcement learning requires reward engineering and learns inefficiently. In this paper, we propose NavOL, an online imitation learning paradigm that interacts with a simulator and updates itself using expert demonstrations gathered online. Built upon a pretrained navigation diffusion policy that maps local observations to future waypoints, NavOL trains in a rollout update loop: during rollout, the policy acts in the simulator and queries a global planner which has privileged access to the global environment for the optimal path segment as ground truth trajectory labels; during update, the policy is trained on the online collected observation trajectory pairs. This online imitation loop removes the need for reward design, improves learning efficiency, and mitigates distribution shift by training on the policy own explored rollouts. Built on IsaacLab with fast, high-fidelity parallel rendering and domain randomization of camera pose and start-goal pairs, our system scales across 50 scenes on 8 RTX 4090 GPUs, collecting over 2,000 new trajectories per hour, each averaging more than 400 steps. We also introduce an indoor visual navigation benchmark with predefined start and goal positions for zero-shot generalization. Extensive evaluations on simulation benchmarks, including the NavDP benchmark and our proposed benchmark, as well as carefully designed real-world experiments, demonstrate the effectiveness of NavOL, showing consistent performance gains in online imitation learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes NavOL, an online imitation learning method for training a pretrained navigation diffusion policy that maps local observations to waypoints. In a rollout-update loop, the policy interacts with a simulator using local observations while a privileged global planner supplies optimal path segments as ground-truth labels for policy updates; this is claimed to mitigate distribution shift and compounding errors without reward engineering. The system scales via IsaacLab with parallel rendering and domain randomization across 50 scenes, and the authors introduce a new indoor visual navigation benchmark. Extensive evaluations on NavDP, the new benchmark, and real-world experiments are asserted to show consistent performance gains over baselines.
Significance. If the central claims hold, NavOL provides a practical route to efficient, reward-free policy improvement for visual navigation by closing the loop between local-observation rollouts and online expert labeling. The scalable simulation infrastructure (50 scenes, >2000 trajectories/hour on 8 GPUs) and the new zero-shot benchmark are concrete contributions that could support further work in sim-to-real navigation.
major comments (2)
- [rollout-update loop] Rollout-update loop (abstract and method description): The central claim that online imitation mitigates distribution shift rests on the assumption that privileged global-planner paths constitute unbiased, realizable ground-truth labels for a policy that only receives local camera observations. Because the planner has full-map access, the supplied trajectories may encode feasibility or optimality information unavailable under the stated camera-pose and start-goal randomization; this risks training the diffusion policy toward behaviors it cannot reproduce at deployment, reintroducing the very shift the method aims to solve. A direct test (e.g., oracle labels generated from local observations only) is needed to substantiate the claim.
- [evaluation sections] Evaluation sections (NavDP and proposed benchmark results): The abstract and summary assert 'consistent performance gains' and 'extensive evaluations,' yet the provided text supplies no numerical metrics, baseline comparisons, success rates, or error bars. Without these data, it is impossible to assess whether the reported gains are statistically meaningful or whether they survive the potential label bias identified above.
minor comments (2)
- [abstract] Abstract: The abstract states performance gains without any quantitative values, which is atypical for an empirical robotics paper and reduces immediate readability.
- [method] Implementation details: The diffusion-policy pretraining procedure, exact loss formulation, and hyperparameter choices for the online update step are referenced but not fully specified, hindering reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments. We address each major point below, clarifying our method and committing to revisions where appropriate to strengthen the manuscript.
read point-by-point responses
-
Referee: [rollout-update loop] Rollout-update loop (abstract and method description): The central claim that online imitation mitigates distribution shift rests on the assumption that privileged global-planner paths constitute unbiased, realizable ground-truth labels for a policy that only receives local camera observations. Because the planner has full-map access, the supplied trajectories may encode feasibility or optimality information unavailable under the stated camera-pose and start-goal randomization; this risks training the diffusion policy toward behaviors it cannot reproduce at deployment, reintroducing the very shift the method aims to solve. A direct test (e.g., oracle labels generated from local observations only) is needed to substantiate the claim.
Authors: We acknowledge the referee's concern regarding potential label bias from privileged global-planner information. In NavOL, the planner supplies optimal path segments only during the online collection phase to label states actually visited by the policy's local-observation rollouts; the diffusion policy itself never receives map information and must infer waypoints from camera images alone. This setup is intended to align training and deployment distributions more closely than offline imitation. We agree that an explicit comparison would strengthen the claim and will add an ablation in the revised manuscript that replaces global-planner labels with locally computable heuristics (e.g., straight-line or local obstacle-avoidance paths) to quantify any performance gap attributable to privileged information. revision: yes
-
Referee: [evaluation sections] Evaluation sections (NavDP and proposed benchmark results): The abstract and summary assert 'consistent performance gains' and 'extensive evaluations,' yet the provided text supplies no numerical metrics, baseline comparisons, success rates, or error bars. Without these data, it is impossible to assess whether the reported gains are statistically meaningful or whether they survive the potential label bias identified above.
Authors: The full manuscript contains quantitative results in Sections 4.2–4.4, including tables that report success rates, SPL, navigation time, and collision metrics for NavOL against baselines (behavior cloning, DAgger, and RL variants) on the NavDP benchmark and the new indoor zero-shot benchmark. All metrics are averaged over multiple random seeds with standard deviations and error bars shown in figures. Real-world experiments similarly report success rates across trials. We will revise the abstract and introduction to explicitly cite these numerical results and ensure the key tables are referenced early in the paper so readers can immediately evaluate statistical significance and robustness to the label-bias concern. revision: yes
Circularity Check
No circularity: empirical online imitation procedure with external global planner labels
full rationale
The paper describes an empirical training loop (rollout with privileged global planner providing path labels, followed by supervised update of the diffusion policy on collected observation-trajectory pairs) without any mathematical derivation, fitted parameters renamed as predictions, or self-referential definitions. The central claim rests on simulation and real-world evaluations rather than any closed-form reduction or self-citation chain that would force the result by construction. The privileged planner is an external component whose outputs serve as supervision; this is a methodological choice open to the bias critique raised in the skeptic note, but it does not constitute circularity under the defined criteria.
Axiom & Free-Parameter Ledger
free parameters (1)
- diffusion policy training hyperparameters
axioms (1)
- domain assumption The simulator with domain randomization produces rollouts representative enough for zero-shot generalization to real-world navigation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
during rollout, the policy acts in the simulator and queries a global planner which has privileged access to the global environment for the optimal path segment as ground truth trajectory labels
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cai, W., Peng, J., Yang, Y ., Zhang, Y ., Wei, M., Wang, H., Chen, Y ., Wang, T., and Pang, J. Navdp: Learning sim-to-real navigation diffusion policy with privileged information guidance.arXiv preprint arXiv:2505.08712,
-
[2]
Matterport3D: Learning from RGB-D Data in Indoor Environments
Chang, A., Dai, A., Funkhouser, T., Halber, M., Niessner, M., Savva, M., Song, S., Zeng, A., and Zhang, Y . Matter- port3d: Learning from rgb-d data in indoor environments. arXiv preprint arXiv:1709.06158,
-
[3]
Learning to explore using active neural slam,
Chaplot, D. S., Gandhi, D., Gupta, S., Gupta, A., and Salakhutdinov, R. Learning to explore using active neural slam.arXiv preprint arXiv:2004.05155,
-
[4]
The one ring: a robotic indoor navigation generalist.arXiv preprint arXiv:2412.14401,
Eftekhar, A., Hendrix, R., Weihs, L., Duan, J., Caglar, E., Salvador, J., Herrasti, A., Han, W., VanderBil, E., Kemb- havi, A., et al. The one ring: a robotic indoor navigation generalist.arXiv preprint arXiv:2412.14401,
-
[5]
Diffuseloco: Real-time legged locomotion control with diffusion from offline datasets,
Huang, X., Chi, Y ., Wang, R., Li, Z., Peng, X. B., Shao, S., Nikolic, B., and Sreenath, K. Diffuseloco: Real-time legged locomotion control with diffusion from offline datasets.arXiv preprint arXiv:2404.19264,
-
[6]
A gradient method for realtime robot control
10 NavOL: Navigation Policy with Online Imitation Learning Konolige, K. A gradient method for realtime robot control. InProceedings. 2000 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2000)(Cat. No. 00CH37113), volume 1, pp. 639–646. IEEE,
work page 2000
-
[7]
Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding
Ku, A., Anderson, P., Patel, R., Ie, E., and Baldridge, J. Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding.arXiv preprint arXiv:2010.07954,
-
[8]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
Makoviychuk, V ., Wawrzyniak, L., Guo, Y ., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
doi: 10.1109/LRA.2023.3270034. NVIDIA. Isaac Sim. URL https://github.com/ isaac-sim/IsaacSim. Puig, X., Undersander, E., Szot, A., Cote, M. D., Yang, T.- Y ., Partsey, R., Desai, R., Clegg, A. W., Hlavac, M., Min, S. Y ., et al. Habitat 3.0: A co-habitat for humans, avatars and robots.arXiv preprint arXiv:2310.13724,
-
[10]
Salimpour, S., Pe ˜na-Queralta, J., Paez-Granados, D., Heikkonen, J., and Westerlund, T. Sim-to-real transfer for mobile robots with reinforcement learning: from nvidia isaac sim to gazebo and real ros 2 robots.arXiv preprint arXiv:2501.02902,
-
[11]
Gnm: A general navigation model to drive any robot
Shah, D., Sridhar, A., Bhorkar, A., Hirose, N., and Levine, S. Gnm: A general navigation model to drive any robot. arXiv preprint arXiv:2210.03370,
-
[12]
Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846, 2023
Shah, D., Sridhar, A., Dashora, N., Stachowicz, K., Black, K., Hirose, N., and Levine, S. Vint: A foundation model for visual navigation.arXiv preprint arXiv:2306.14846,
-
[13]
Shi, H., Deng, X., Li, Z., Chen, G., Wang, Y ., and Nie, L. Dagger diffusion navigation: Dagger boosted diffusion policy for vision-language navigation.arXiv preprint arXiv:2508.09444,
-
[14]
Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames,
Wijmans, E., Kadian, A., Morcos, A., Lee, S., Essa, I., Parikh, D., Savva, M., and Batra, D. Dd-ppo: Learning near-perfect pointgoal navigators from 2.5 billion frames. arXiv preprint arXiv:1911.00357,
-
[15]
iplanner: Im- perative path planning.arXiv preprint arXiv:2302.11434,
11 NavOL: Navigation Policy with Online Imitation Learning Yang, F., Wang, C., Cadena, C., and Hutter, M. iplanner: Im- perative path planning.arXiv preprint arXiv:2302.11434,
-
[16]
Zeng, K.-H., Zhang, Z., Ehsani, K., Hendrix, R., Salvador, J., Herrasti, A., Girshick, R., Kembhavi, A., and Weihs, L. Poliformer: Scaling on-policy rl with transformers results in masterful navigators.arXiv preprint arXiv:2406.20083,
-
[17]
Zhang, X., Chang, M., Kumar, P., and Gupta, S. Diffu- sion meets dagger: Supercharging eye-in-hand imitation learning.arXiv preprint arXiv:2402.17768,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.