Recognition: 1 theorem link
· Lean TheoremSafety-Oriented Evaluation of Language Understanding Systems for Air Traffic Control
Pith reviewed 2026-05-13 06:35 UTC · model grok-4.3
The pith
LLMs achieve high macro-F1 on ATC transcripts yet reach only 0.69 on a consequence-weighted Risk Score that flags high-impact semantic errors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
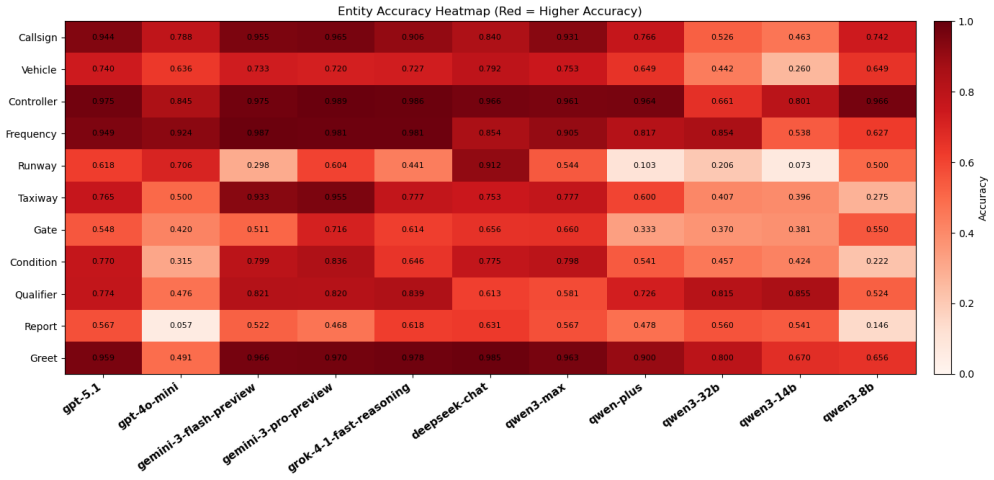
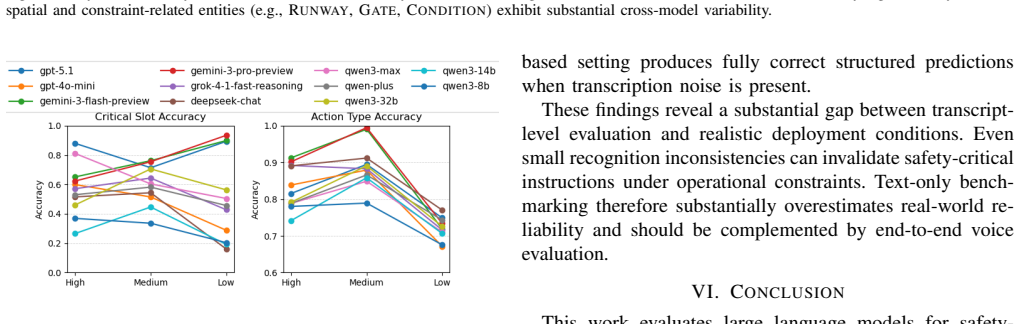
We define a Risk Score that sums semantic errors in ATC instructions after multiplying each by a consequence weight reflecting real operational impact. When applied to clean transcripts, the highest score any tested model reaches is 0.69 and most fall below 0.6, even though macro-F1 remains high. The distribution shows that high-consequence entity errors drive the low scores while lower-stakes action classification stays relatively robust.
What carries the argument
The Risk Score, a weighted sum of semantic parsing errors in which each error type is multiplied by an operational consequence factor specific to ATC.
If this is right
- Aggregate metrics such as macro-F1 cannot be trusted to certify reliability for ATC language systems.
- Model errors concentrate in high-impact entities, indicating that grounding improvements must target those specific components.
- Consequence-aware evaluation protocols are required before any responsible deployment of AI-assisted ATC tools.
- Stable action classification does not imply safe overall performance when identifier and constraint errors remain frequent.
Where Pith is reading between the lines
- Testing the same models on noisy or real-time radio transcripts would likely produce even lower Risk Scores.
- Retraining with a loss function that directly penalizes high-consequence errors could narrow the gap between F1 and Risk Score.
- The same weighting approach could be transferred to other safety-critical instruction domains such as medical or maritime communications.
Load-bearing premise
The numerical weights assigned to different error types accurately reflect their relative safety impacts in live air traffic operations.
What would settle it
Recompute the Risk Score after independent ATC experts rate the actual consequence severity of the same error instances and check whether the ordering of models changes substantially.
Figures

read the original abstract
Air Traffic Control (ATC) is a safety-critical domain in which incorrect interpretation of instructions may lead to severe operational consequences. While large language models (LLMs) demonstrate strong general performance, their reliability in operational ATC environments remains unclear. Existing evaluation approaches, largely based on aggregate metrics such as F1 or macro accuracy, treat all errors uniformly and fail to account for the asymmetric consequences of high-risk semantic mistakes (e.g., incorrect runway identifiers or movement constraints). To address this gap, we propose a safety-oriented, consequence-aware evaluation framework tailored to ATC operations. Our results reveal that while current LLMs achieve reasonable aggregate accuracy, their operational reliability is severely limited. Evaluated on clean transcripts, the peak Risk Score reaches only 0.69, with most models scoring below 0.6 despite high macro-F1 performance. Further analysis shows that errors concentrate in high-impact entities despite relatively stable action-type classification, indicating structural grounding deficiencies. These findings highlight the necessity of consequence-aware evaluation protocols for the responsible deployment of AI-assisted ATC systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a safety-oriented evaluation framework for LLMs in air traffic control (ATC) that replaces uniform error metrics with a consequence-weighted Risk Score. It evaluates multiple models on clean transcripts and reports that while macro-F1 scores are high, the highest Risk Score achieved is only 0.69 (most models below 0.6). The authors attribute the gap to structural grounding deficiencies, particularly errors on high-impact entities such as runway identifiers and movement constraints, and conclude that current LLMs are not yet reliable for operational ATC use.
Significance. If the Risk Score and its weighting scheme can be shown to be grounded, the work would usefully demonstrate that standard aggregate metrics are insufficient for safety-critical language understanding tasks. The observation that errors concentrate on high-consequence entities even when action classification is stable is a concrete, actionable finding that could inform both model development and evaluation protocols in ATC and similar domains.
major comments (2)
- [Abstract / Methods] Abstract and methods description: the central claim that operational reliability is 'severely limited' rests on the reported Risk Scores (peak 0.69). No equation, table, or appendix supplies the explicit consequence weights, the error taxonomy used to assign them, or any calibration against historical ATC incident data or expert panels. Without this information the numerical gap between macro-F1 and Risk Score cannot be reproduced or stress-tested.
- [Results] Results section: the paper states that errors concentrate in high-impact entities, yet provides no breakdown (e.g., per-entity Risk Score contribution or confusion matrices) that would allow readers to verify whether the low aggregate Risk Score is driven by a small number of high-weight error types or is distributed across many low-weight errors.
minor comments (2)
- [Experimental Setup] The dataset composition (number of transcripts, source of clean vs. noisy data, annotation protocol) is referenced only in passing; a table or appendix listing these statistics would improve reproducibility.
- [Methods] Notation for the Risk Score formula is introduced without an explicit equation number; adding one would help readers trace how individual error weights combine into the final score.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our safety-oriented evaluation framework for LLMs in ATC. The feedback highlights key areas for improving reproducibility and substantiation of our claims. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and methods description: the central claim that operational reliability is 'severely limited' rests on the reported Risk Scores (peak 0.69). No equation, table, or appendix supplies the explicit consequence weights, the error taxonomy used to assign them, or any calibration against historical ATC incident data or expert panels. Without this information the numerical gap between macro-F1 and Risk Score cannot be reproduced or stress-tested.
Authors: We agree that the explicit Risk Score equation, consequence weights, error taxonomy, and calibration details must be provided to enable reproduction. In the revised manuscript we will add a new subsection in Methods that includes the full Risk Score formula (weighted sum of per-entity errors), a table of consequence weights assigned to each entity type (derived from ATC expert input), and the complete error taxonomy. We will also add a limitations paragraph noting that while weights reflect expert consultation, direct calibration against historical incident data is not included and is identified as future work. These additions will allow readers to reproduce the macro-F1 to Risk Score gap and perform stress tests. revision: yes
-
Referee: [Results] Results section: the paper states that errors concentrate in high-impact entities, yet provides no breakdown (e.g., per-entity Risk Score contribution or confusion matrices) that would allow readers to verify whether the low aggregate Risk Score is driven by a small number of high-weight error types or is distributed across many low-weight errors.
Authors: We agree that a quantitative breakdown is required to support the concentration claim. The revised Results section will include a new table showing per-entity Risk Score contributions (highlighting that runway identifiers and movement constraints account for the majority of the aggregate penalty) and confusion matrices restricted to high-impact entities. This will demonstrate that the low Risk Score is driven by a small set of high-weight error types rather than uniform distribution across low-weight errors. revision: yes
Circularity Check
No circularity detected in derivation or metric application
full rationale
The paper introduces a new consequence-aware Risk Score metric and applies it to evaluate LLM performance on ATC transcripts, reporting peak value of 0.69. No equations, self-citations, or derivations reduce this score or the reliability claim to quantities fitted from the same data or to self-referential definitions. The framework is self-contained as an evaluation protocol; the low Risk Score is an output of applying the defined weights to observed errors rather than a tautological input. Minor self-citation (if present) is not load-bearing on the central result.
Axiom & Free-Parameter Ledger
free parameters (1)
- consequence weights for error types
axioms (1)
- domain assumption Semantic errors in ATC instructions carry asymmetric safety consequences
invented entities (1)
-
Risk Score
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearScorei = r(ai) · (∑ s∈S(ai) wai,s mi,s / ∑ s∈S(ai) wai,s) with ρ(ai) ∈ {1.0,0.6,0.2} for HIGH/MEDIUM/LOW
Reference graph
Works this paper leans on
-
[1]
OpenAI, “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radfordet al., “Robust speech recognition via large-scale weak supervision,”arXiv preprint arXiv:2212.04356, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
X. Cheng, Z. Yao, Z. Zhu, Y . Li, H. Li, and Y . Zou, “C 2A-SLU: Cross and contrastive attention for improving asr robustness in spoken language understanding,” inProc. Interspeech 2023, 2023, pp. 695– 699
work page 2023
-
[4]
MoE-SLU: Towards asr-robust spoken language understanding via mixture-of-experts,
X. Cheng, Z. Zhu, X. Zhuang, Z. Chen, Z. Huang, and Y . Zou, “MoE-SLU: Towards asr-robust spoken language understanding via mixture-of-experts,” inFindings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 2024, pp. 14 868–14 879
work page 2024
-
[5]
L. Dong, Z. An, P. Wu, J. Zhang, L. Lu, and Z. Ma, “CIF-PT: Bridging speech and text representations for spoken language understanding via continuous integrate-and-fire pre-training,” inFindings of the Associa- tion for Computational Linguistics: ACL 2023, Toronto, Canada, 2023, pp. 8894–8907
work page 2023
-
[6]
Z. Chen, H. Huang, A. Andrusenko, O. Hrinchuk, K. C. Puvvada, J. Li, S. Ghosh, J. Balam, and B. Ginsburg, “SALM: Speech-augmented language model with in-context learning for speech recognition and translation,” arXiv preprint arXiv:2310.09424, 2023
-
[7]
The ATCOSIM corpus of non-prompted clean air traffic control speech,
K. Hofbauer, S. Petrik, and H. Hering, “The ATCOSIM corpus of non-prompted clean air traffic control speech,” inProceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08). Marrakech, Morocco: European Language Resources Association (ELRA), May 2008. [Online]. Available: https://aclanthology.org/L08-1507/
work page 2008
-
[8]
Automatic speech recognition benchmark for air- traffic communications,
J. Zuluaga-Gomez, P. Motlicek, Q. Zhan, K. Vesely, and R. Braun, “Automatic speech recognition benchmark for air- traffic communications,” arXiv:2006.10304, 2020. [Online]. Available: https://arxiv.org/abs/2006.10304
-
[9]
Applying large-scale weakly-supervised au- tomatic speech recognition to air traffic control,
R. Prabhavalkaret al., “Applying large-scale weakly-supervised au- tomatic speech recognition to air traffic control,” inProceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 6249–6253
work page 2021
-
[10]
Adapting automatic speech recognition for accented air traffic control communications,
M. Y . Z. Wee, J. J. H. Wong, L. Lim, J. Y . W. Tan, P. Gupta, D. Lim, E. H. Tew, A. K. S. Han, and Y . Z. Lim, “Adapting automatic speech recognition for accented air traffic control communications,” arXiv:2502.20311, 2025. [Online]. Available: https://arxiv.org/abs/2502.20311
-
[11]
V .-P. Thai, D. Aradhya, C.-M. Chan, Y . Chang, P.-D. Thinh, and S. Alam, “Speech-to-route: Learning-based airport taxi route inference from progressive air traffic control instructions,” SSRN, 2025, available at SSRN: https://ssrn.com/abstract=5871919. [Online]. Available: https://ssrn.com/abstract=5871919
work page 2025
-
[12]
Text2traffic: Retrieval-enhanced in-context learning for complex air traffic scenario generation,
Y . Guleria, D.-T. Pham, A. L. K. Yun, T. N. M. Nadirsha, K. Fennedy, C. Ma, and S. Alam, “Text2traffic: Retrieval-enhanced in-context learning for complex air traffic scenario generation,”Journal of Aerospace Information Systems, 2026, published online Mar. 16,
work page 2026
-
[13]
Available: https://doi.org/10.2514/1.D0566
[Online]. Available: https://doi.org/10.2514/1.D0566
-
[14]
Towards end-to-end speech recognition with recurrent neural networks,
A. Graves and N. Jaitly, “Towards end-to-end speech recognition with recurrent neural networks,”ICML, 2014
work page 2014
-
[15]
A. Graves, S. Fern ´andez, F. Gomez, and J. Schmidhuber, “Connection- ist temporal classification: Labelling unsegmented sequence data with recurrent neural networks,” inICML, 2006
work page 2006
-
[16]
Towards understanding ASR error correction for medical conversations,
A. Mani, S. Palaskar, and S. Konam, “Towards understanding ASR error correction for medical conversations,” inProceedings of the First Workshop on Natural Language Processing for Medical Conversations. Online: Association for Computational Linguistics, Jul. 2020, pp. 7–11. [Online]. Available: https://aclanthology.org/2020.nlpmc-1.2/
work page 2020
-
[18]
Available: https://arxiv.org/abs/2003.07692
[Online]. Available: https://arxiv.org/abs/2003.07692
-
[19]
ECLM: Entity level language model for spoken language understanding with chain of intent,
S. Yin, P. Huang, J. Chen, H. Huang, and Y . Xu, “ECLM: Entity level language model for spoken language understanding with chain of intent,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, Jul. 2025, pp. 21 851–21 862. [Online]. A...
work page 2025
-
[20]
Not all errors are equal: Learning text generation metrics using stratified error synthesis,
W. Xu, Y .-L. Tuan, Y . Lu, M. Saxon, L. Li, and W. Y . Wang, “Not all errors are equal: Learning text generation metrics using stratified error synthesis,” inFindings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 2022, pp. 6559–6574
work page 2022
-
[21]
Beyond accuracy: Behavioral testing of nlp models with checklist,
M. T. Ribeiro, T. Wu, C. Guestrin, and S. Singh, “Beyond accuracy: Behavioral testing of nlp models with checklist,” inProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 2020, pp. 4902–4912
work page 2020
-
[22]
H. Guan, P. Hou, P. Hong, L. Wang, W. Zhang, X. Du, Z. Zhou, and L. Zhou, “A clinically-informed framework for evaluating vision- language models in radiology report generation: Taxonomy of errors and risk-aware metric,” medRxiv preprint, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.