Recognition: no theorem link
Choosing features for classifying multiword expressions
Pith reviewed 2026-05-13 06:28 UTC · model grok-4.3
The pith
Selecting reliable features for classifying multiword expressions yields schemes more useful for computational applications across languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The author outlines an enhanced classification for multiword expressions by choosing features that allow reliable assignment to classes, informed by previous works that take various languages into account, in order to increase suitability for computational use.
What carries the argument
The selection of features for multiword expression classification, where each feature is assessed by how reliably it supports consistent class assignment.
If this is right
- Resulting classifications become more fruitful for computational use.
- The classification gains greater suitability across many languages.
- Class assignments for expressions achieve higher reliability.
- Computational systems can apply the categories with more consistent outcomes.
Where Pith is reading between the lines
- Improved classifications could support more accurate phrase handling in translation or parsing systems.
- The feature selection approach might extend to categorizing other variable linguistic constructions.
- Direct comparison of classification performance on held-out language data would test the gain in reliability.
Load-bearing premise
Features for multiword expressions vary in reliability for class assignment, and prior multilingual works can guide the choice of better ones.
What would settle it
Apply the enhanced classification to multiword expressions in several languages and check whether class assignments show greater consistency or yield better results in computational tasks than earlier classifications.
Figures
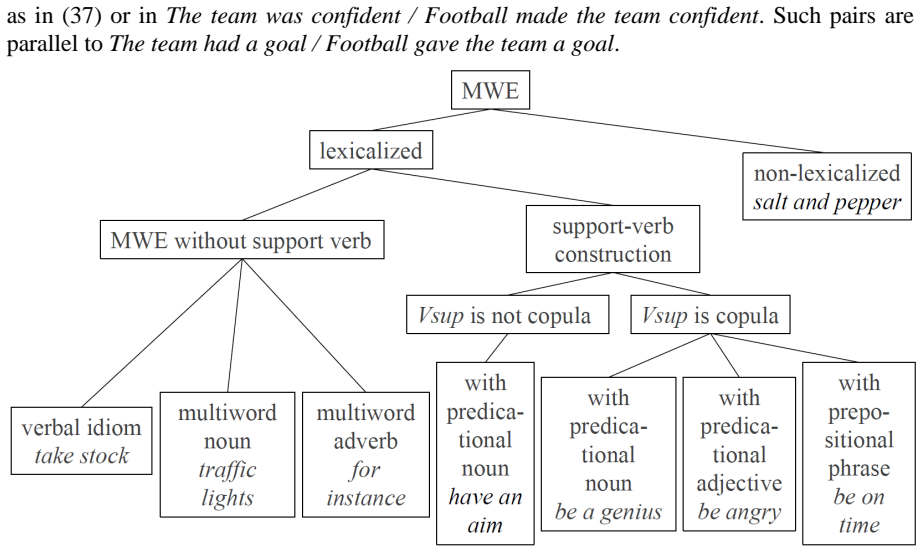
read the original abstract
Multiword expressions (MWEs) are a heterogeneous set with a glaring need for classifications. Designing a satisfactory classification involves choosing features. In the case of MWEs, many features are a priori available. Not all features are equal in terms of how reliably MWEs can be assigned to classes. Accordingly, resulting classifications may be more or less fruitful for computational use. I outline an enhanced classification. In order to increase its suitability for many languages, I use previous works taking into account various languages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript outlines an enhanced classification for multiword expressions (MWEs) by selecting features from prior works across multiple languages. It argues that not all a priori available features are equally reliable for assigning MWEs to classes and that the resulting classifications therefore vary in their fruitfulness for computational applications. The central contribution is conceptual: a synthesis intended to increase cross-linguistic suitability.
Significance. If the feature-selection criteria and the resulting taxonomy can be shown to be more reliable and more portable than existing schemes, the work could supply a practical foundation for MWE-aware NLP pipelines in parsing, translation, and semantic analysis. At present the contribution remains a high-level proposal without concrete feature lists, reliability metrics, or empirical comparisons, so its significance is prospective rather than demonstrated.
major comments (2)
- The manuscript never states the concrete set of features ultimately chosen or the explicit reliability criteria used to rank them. Without this information the central claim that the classification is 'enhanced' cannot be evaluated.
- No comparison—qualitative or quantitative—is provided against any of the prior classifications referenced in the abstract. It is therefore impossible to verify the assertion that the new synthesis is more fruitful for computational use.
minor comments (1)
- The abstract would benefit from a single concrete example illustrating one feature, its reliability assessment, and the class to which it assigns a sample MWE.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where the manuscript can be strengthened. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: The manuscript never states the concrete set of features ultimately chosen or the explicit reliability criteria used to rank them. Without this information the central claim that the classification is 'enhanced' cannot be evaluated.
Authors: We agree that the current version presents the classification primarily at a conceptual level. In the revised manuscript we will add an explicit enumeration of the selected features, drawn from the referenced prior multi-language studies, together with the reliability criteria (e.g., cross-linguistic consistency of assignment and demonstrated utility in downstream computational tasks) used to rank and retain them. revision: yes
-
Referee: No comparison—qualitative or quantitative—is provided against any of the prior classifications referenced in the abstract. It is therefore impossible to verify the assertion that the new synthesis is more fruitful for computational use.
Authors: The manuscript is framed as a high-level synthesis rather than an empirical study. To address the concern we will insert a new qualitative comparison section that contrasts the proposed feature-based taxonomy with the main prior schemes cited in the abstract, focusing on gains in cross-linguistic portability and computational applicability. Quantitative benchmarking lies outside the scope of this conceptual paper, but we will include illustrative examples showing how the selected features improve class assignment reliability. revision: partial
Circularity Check
No significant circularity
full rationale
The manuscript is a conceptual outline of an enhanced MWE classification synthesized from prior multi-language studies. Its central claim asserts that feature reliability varies and cross-linguistic synthesis improves computational utility. No equations, fitted parameters, predictions, or self-referential definitions appear. The argument draws on external prior works without reducing any load-bearing step to a self-citation chain, tautology, or renaming of known results. The derivation is self-contained against external benchmarks and exhibits no circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Previous works on MWEs across languages provide a basis for choosing reliable features that improve computational usefulness.
Reference graph
Works this paper leans on
-
[1]
Corpus Linguistics or Computer -aided Armchair Linguistics. In Jan Svartik (ed.), Directions in Corpus Linguistics: Proceedings of Nobel Symposium 82, Stockholm, 4 -8 August 1991, 35-
work page 1991
-
[2]
SMIL, Journal of Linguistic Calculus 1978(3-4)
Syntax and lexicon: blessure ‘wound’, nœud ‘knot’, caresse ‘caress’... SMIL, Journal of Linguistic Calculus 1978(3-4). 55–72. Stockholm: Skriptor. Grégoire, Nicole
work page 1978
-
[3]
Revue Québécoise de Linguistique (RQL) 11(2)
Une classification des phrases « figées » du français. Revue Québécoise de Linguistique (RQL) 11(2). 151–185. Montréal: UQAM. Gross, Maurice. 1986 . Grammaire transformatio nnelle du français. Vol. 3, Syntaxe de l ’ adverbe. Paris : 28 ASSTRIL. Gross, Maurice
work page 1986
-
[4]
In Ronald Asher (ed.), The Encyclopaedia of language and linguistics, v ol
The lexicon-grammar of a language: Application to Fren ch. In Ronald Asher (ed.), The Encyclopaedia of language and linguistics, v ol. 4, 2195 –2205. Oxford/NewYork/Seoul/Tokyo: Pergamon. Gross, Maurice.1996. Les formes être Prép X du français. Lingvisticae Investigationes 20(2). 217–270. Gross, Maurice
work page 1996
-
[5]
Reuse of verb theoretical linguistic descriptions
Automatic construction and validation of Fren ch large lexical resources. Reuse of verb theoretical linguistic descriptions. In Proceedings of the Language Resources and Evaluation Conference, 627–636. Granada. Jespersen, Otto . 1942,
work page 1942
-
[6]
Noun Argument Structure for Prop Bank
Annotation Guidelines for NomBank. Noun Argument Structure for Prop Bank. https://nlp.cs.nyu.edu/meyers/nombank/nombank-specs-2007.pdf (January 2016). Unpublished manuscript. Meyers, Adam, Ruth Reeves, Catherine Macleod, Rachel Szekely, Veronika Zielinska, Brian You ng & Ralph Grishman
work page 2007
-
[7]
Lisboa: Instituto Nacional de Investigação Científica
Sintaxe dos P redicados Nominais com Estar (Linguística 12). Lisboa: Instituto Nacional de Investigação Científica. Ranchhod, Elisabete & Michele De Gioia, 1996, Comparative Romance Syntax. Frozen Adverbs in Italian and in Portuguese. Lingvisticae Investigationes 20(1). 33–85. Rassi, Amanda, Cristina Santos -Turati, Jorge Baptista, Nuno Mamede & Oto Vale
work page 1996
-
[8]
Berkeley, California: International Computer Science Institute
FrameNet II: Extended Theory and Practice . Berkeley, California: International Computer Science Institute. Sag, Ivan Andrew, Timothy Baldwin, Francis Bond, Ann Copestake & Dan Flickinger. 2002 . Multiword expressions: A pain in the neck for NLP. In Proceedings of the 3rd International Conference on Intelligent Text Processing and Computational Linguistic...
work page 2002
-
[9]
109–121. Stathi, Katerina. 2007 . A corpus -based analysis of adjectival modification in German idioms. In Christiane Fellbaum (ed.), Idioms and collocations. Corpus-based linguistic and lexicographic studies , 81–108. London/New York: Continuum. Tesnière, Lucien
work page 2007
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.