Recognition: 2 theorem links
· Lean TheoremROMER: Expert Replacement and Router Calibration for Robust MoE LLMs on Analog Compute-in-Memory Systems
Pith reviewed 2026-05-13 07:21 UTC · model grok-4.3
The pith
ROMER restores routing balance in MoE LLMs on analog CIM by swapping experts and normalizing router logits after training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Noise calibrated from real analog CIM chips disrupts expert load balance in MoE LLMs and renders clean-trained routing decisions suboptimal; ROMER corrects this through post-training replacement of underactivated experts with high-frequency ones and percentile-based normalization of router logits, producing perplexity reductions of 58.6 percent, 58.8 percent, and 59.8 percent for DeepSeek-MoE, Qwen-MoE, and OLMoE respectively under the measured noise.
What carries the argument
Expert replacement to restore activation frequency balance together with percentile normalization of router logits to stabilize routing under noise.
If this is right
- MoE models trained on clean data can still reach near-clean performance on analog hardware after a lightweight calibration pass.
- Load balance among experts can be recovered by identifying and swapping in experts that activate frequently once noise is present.
- Router outputs become noise-tolerant when their logits are forced to match the percentile distribution observed under hardware noise.
- The same two-step procedure works across multiple MoE architectures without architecture-specific retraining.
- Post-training calibration can substitute for hardware-aware training loops in many deployment settings.
Where Pith is reading between the lines
- The dominant effect of analog noise appears to be a shift in which experts get chosen rather than outright corruption of individual weights.
- Routers trained with explicit noise simulation during initial training might need less or no later calibration.
- Hardware teams could use the same replacement logic to design CIM arrays whose noise profile favors balanced expert use.
- The approach may extend to other sparse activation schemes such as sparse attention or dynamic networks on analog substrates.
Load-bearing premise
The noise statistics measured on the authors' specific real chip capture the imperfections that will appear in other analog CIM deployments.
What would settle it
Evaluating a ROMER-calibrated model on a second analog CIM chip whose noise was never measured and observing that the perplexity improvement vanishes or becomes negative.
Figures




read the original abstract
Large language models (LLMs) with mixture-of-experts (MoE) architectures achieve remarkable scalability by sparsely activating a subset of experts per token, yet their frequent expert switching creates memory bandwidth bottlenecks that compute-in-memory (CIM) architectures are well-suited to mitigate. However, analog CIM systems suffer from inherent hardware imperfections that perturb stored weights, and its negative impact on MoE-based LLMs in noisy CIM environments remains unexplored. In this work, we present the first systematic investigation of MoE-based LLMs under noise model calibrated with real chip measurements, revealing that hardware noise critically disrupts expert load balance and renders clean-trained routing decisions consistently suboptimal. Based on these findings, we propose ROMER, a post-training calibration framework that (1) replaces underactivated experts with high-frequency ones to restore load balance, and (2) recalibrates router logits via percentile-based normalization to stabilize routing under noise. Extensive experiments across multiple benchmarks demonstrate that ROMER achieves up to 58.6\%, 58.8\%, and 59.8\% reduction in perplexity under real-chip noise conditions for DeepSeek-MoE, Qwen-MoE, and OLMoE, respectively, establishing its effectiveness and generalizability across diverse MoE architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ROMER, a post-training calibration framework for MoE LLMs deployed on analog compute-in-memory (CIM) hardware. It first shows via real-chip-calibrated noise that hardware imperfections disrupt expert load balance and make clean-trained routing suboptimal. ROMER then applies (1) replacement of under-activated experts by high-frequency ones and (2) percentile-based normalization of router logits. Experiments across DeepSeek-MoE, Qwen-MoE and OLMoE report perplexity reductions of 58.6–59.8 % under the measured noise.
Significance. If the results hold, the work is significant because it supplies the first systematic study of MoE routing under realistic analog CIM noise and demonstrates that lightweight post-training fixes can largely restore performance. Grounding the noise model in real-chip data and showing consistent gains across three distinct MoE families are clear strengths; the approach could materially ease deployment of large sparse models on energy-efficient analog accelerators.
major comments (3)
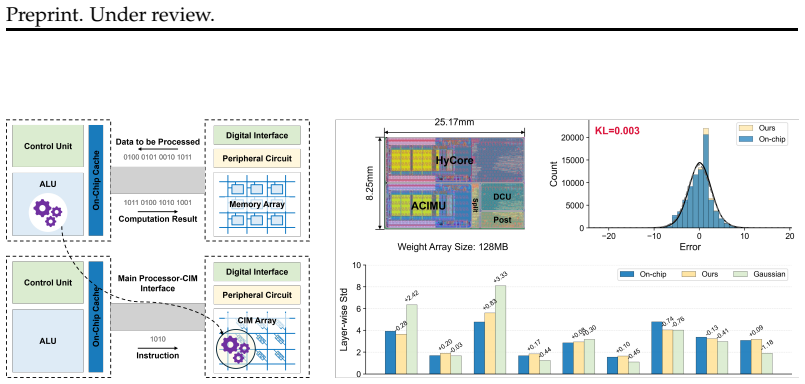
- [Abstract and §4] Abstract and §4 (noise model): the central transferability claim rests on a single real-chip noise distribution; no data are given on number of chips, process corners, temperature, or layer-wise variation statistics, so it is unclear whether the calibrated percentile normalization and expert replacement will generalize without retuning.
- [§5] §5 (experiments): the reported perplexity reductions are not accompanied by clean-input baselines, statistical significance tests, or variance across multiple noise realizations; without these it is impossible to verify that ROMER does not trade noise robustness for clean degradation.
- [§4.2] §4.2 (router calibration): the percentile value and activation-frequency threshold are free parameters tuned on the observed noise; the paper does not demonstrate that the same values remain effective under modest changes to the noise statistics, which directly affects the robustness claim.
minor comments (2)
- [Figures and §3] Figure captions and §3 should explicitly state whether the reported perplexity numbers are on the same test sets used for clean baselines.
- [§4.2] Notation for router logits before/after normalization should be introduced once and used consistently to avoid ambiguity in the calibration equations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing the strongest honest defense of our work while making revisions where they strengthen the claims without misrepresentation.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (noise model): the central transferability claim rests on a single real-chip noise distribution; no data are given on number of chips, process corners, temperature, or layer-wise variation statistics, so it is unclear whether the calibrated percentile normalization and expert replacement will generalize without retuning.
Authors: We acknowledge that the noise model is derived from measurements on a single representative analog CIM chip. This choice was made to ground the study in real hardware data rather than synthetic models. In the revised manuscript, we have expanded the discussion in §4 to explicitly state the assumptions of our noise model, note the absence of multi-chip or process-corner statistics, and clarify that practical deployment may benefit from device-specific recalibration. The consistent gains across three architecturally distinct MoE families nevertheless indicate that the core mechanisms of expert replacement and percentile normalization are effective for the dominant noise characteristics observed in analog CIM. revision: partial
-
Referee: [§5] §5 (experiments): the reported perplexity reductions are not accompanied by clean-input baselines, statistical significance tests, or variance across multiple noise realizations; without these it is impossible to verify that ROMER does not trade noise robustness for clean degradation.
Authors: We agree that these controls are essential for a complete evaluation. The revised §5 now includes clean-input perplexity for all three models, confirming that ROMER introduces no degradation (and in some cases slight improvement) relative to the uncalibrated baseline on noise-free inputs. We additionally report mean perplexity and standard deviation over five independent noise realizations drawn from the calibrated distribution, together with paired t-test p-values demonstrating statistical significance of the reported gains (p < 0.01). These additions directly address the concern that robustness is achieved at the expense of clean performance. revision: yes
-
Referee: [§4.2] §4.2 (router calibration): the percentile value and activation-frequency threshold are free parameters tuned on the observed noise; the paper does not demonstrate that the same values remain effective under modest changes to the noise statistics, which directly affects the robustness claim.
Authors: The chosen percentile (90th) and activation-frequency threshold were selected to counteract the logit perturbation and load-imbalance patterns measured on the real chip. In the revised version we have added a sensitivity study (new Figure in §4.2 and appendix) that perturbs the noise variance by ±20 % around the measured value. The same fixed parameters continue to yield perplexity reductions within 5 % of the peak reported figures, indicating that the calibration is not brittle to modest deviations from the exact observed statistics. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes an empirical post-training framework (expert replacement to restore load balance + percentile normalization of router logits) calibrated directly from real-chip noise statistics. These operations are defined from observed data distributions and do not reduce, by the paper's own equations, to quantities fitted on the target perplexity metric. No self-definitional loops, fitted-input-called-prediction patterns, or load-bearing self-citations appear in the abstract or described methodology. The reported perplexity reductions are experimental outcomes under the calibrated noise model rather than derivations that collapse to their inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- activation frequency threshold for expert replacement
- percentile value for router logit normalization
axioms (1)
- domain assumption Noise statistics measured on real chips are representative of the target analog CIM deployment environment.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ROMER... replaces underactivated experts with high-frequency ones... recalibrates router logits via percentile-based normalization... IQR=Q3(z)−Q1(z)... z^(cal)_i = z^(sorted)_i ± λ·IQR
-
IndisputableMonolith/Foundation/DimensionForcing.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
noise model calibrated with real chip measurements... σ_dev, σ_ADC, ∆... T=25°C / 80°C regimes
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[2]
Advances in neural information processing systems , volume=
Towards understanding the mixture-of-experts layer in deep learning , author=. Advances in neural information processing systems , volume=
-
[3]
Advances in Neural Information Processing Systems , volume=
Scaling vision with sparse mixture of experts , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Swin transformer: Hierarchical vision transformer using shifted windows , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[5]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
Adaptive mixtures of local experts , author=. Neural computation , volume=. 1991 , publisher=
work page 1991
- [7]
- [8]
- [9]
- [10]
- [11]
-
[12]
Proceedings of the IEEE/CVF Conference on CVPR , year =
Zhuang Liu and others , title =. Proceedings of the IEEE/CVF Conference on CVPR , year =
-
[13]
Vaswani, Ashish and others , journal=
-
[14]
and Crafton, Brian and Raychowdhury, Arijit and Fang, Yan , booktitle=
Lele, Ashwin Sanjay and Chang, Muya and Spetalnick, Samuel D. and Crafton, Brian and Raychowdhury, Arijit and Fang, Yan , booktitle=. 2023 , volume=
work page 2023
-
[15]
Chen, Xuan-Jun and Kuan, Cynthia and Yang, Chia-Lin , booktitle=. 2023 , volume=
work page 2023
-
[16]
Chen, Jia and Tu, Fengbin and Shao, Kunming and Tian, Fengshi and Huo, Xiao and Tsui, Chi-Ying and Cheng, Kwang-Ting , booktitle=. 2023 , volume=
work page 2023
-
[17]
Lee, Mingyen and Tang, Wenjun and Chen, Yiming and Wu, Juejian and Zhong, Hongtao and Xu, Yixin and Liu, Yongpan and Yang, Huazhong and Narayanan, Vijaykrishnan and Li, Xueqing , booktitle=. 2023 , volume=
work page 2023
-
[18]
2025 Design, Automation & Test in Europe Conference (DATE) , pages=
HyIMC: Analog-Digital Hybrid In-Memory Computing SoC for High-Quality Low-Latency Speech Enhancement , author=. 2025 Design, Automation & Test in Europe Conference (DATE) , pages=. 2025 , organization=
work page 2025
-
[19]
Device Characteristic-Aware Quantization for eFlash-Based In-Memory Computing SoC , author=. 2024 IEEE International Conference on Integrated Circuits, Technologies and Applications (ICTA) , pages=. 2024 , organization=
work page 2024
-
[20]
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , volume=
An End-to-End In-Memory Computing System Based on a 40-nm eFlash-Based IMC SoC: Circuits, Toolchains, and Systems Co-Design Framework , author=. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , volume=. 2024 , publisher=
work page 2024
-
[21]
A 40nm 5-16Tops/W@ INT8 eFlash In-Memory Computing SoC Chip with Noise Suppression and Compensation Techniques to Improve the Accuracy , author=. 2023 IEEE International Conference on Integrated Circuits, Technologies and Applications (ICTA) , pages=. 2023 , organization=
work page 2023
-
[22]
IEEE Transactions on Circuits and Systems II: Express Briefs , volume=
A mini tutorial of processing in memory: From principles, devices to prototypes , author=. IEEE Transactions on Circuits and Systems II: Express Briefs , volume=. 2022 , publisher=
work page 2022
-
[23]
Enhancing Robustness of Implicit Neural Representations Against Weight Perturbations , year=
Zhou, Wenyong and others , booktitle=. Enhancing Robustness of Implicit Neural Representations Against Weight Perturbations , year=
-
[24]
A Hardware-Aware Neural Architecture Search Pareto Front Exploration for In-Memory Computing , year=
Guan, Ziyi and others , booktitle=. A Hardware-Aware Neural Architecture Search Pareto Front Exploration for In-Memory Computing , year=
-
[25]
A Time- and Energy-Efficient CNN with Dense Connections on Memristor-Based Chips , year=
Zhou, Wenyong and others , booktitle=. A Time- and Energy-Efficient CNN with Dense Connections on Memristor-Based Chips , year=
-
[26]
HPD: Hybrid Projection Decomposition for Robust State Space Models on Analog CIM Hardware , year=
Feng, Yuannuo and Zhou, Wenyong and Lyu, Yuexi and Liu, Hanjie and Liu, Zhengwu and Wong, Ngai and Kang, Wang , booktitle=. HPD: Hybrid Projection Decomposition for Robust State Space Models on Analog CIM Hardware , year=
-
[27]
Extending Straight-Through Estimation for Robust Neural Networks on Analog CIM Hardware , year=
Feng, Yuannuo and Zhou, Wenyong and Lyu, Yuexi and Zhang, Yixiang and Liu, Zhengwu and Wong, Ngai and Kang, Wang , booktitle=. Extending Straight-Through Estimation for Robust Neural Networks on Analog CIM Hardware , year=
-
[28]
Learning fast samplers for diffusion models by differentiating through sample quality , author=
-
[29]
Progressive Distillation for Fast Sampling of Diffusion Models
Progressive distillation for fast sampling of diffusion models , author=. arXiv preprint arXiv:2202.00512 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Wang, Guangyao and others , journal=. NoiseGuard: A Comprehensive Framework with Noise Modeling, Noise-Aware Training and Noise Compensation for In-Memory Computing SoC , year=
-
[31]
Wu, Taiqiang and others , journal=
-
[32]
Zhou, Wenyong and others , booktitle=
- [33]
- [34]
-
[35]
International Conference on Learning Representations (ICLR) , year =
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer , author =. International Conference on Learning Representations (ICLR) , year =
-
[36]
Journal of Machine Learning Research , volume =
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity , author =. Journal of Machine Learning Research , volume =. 2022 , note =
work page 2022
-
[37]
International Conference on Learning Representations (ICLR) , year =
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding , author =. International Conference on Learning Representations (ICLR) , year =
-
[38]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Scaling Vision with Sparse Mixture of Experts , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[39]
Proceedings of the 38th International Conference on Machine Learning (ICML) , year =
BASE Layers: Simplifying Training of Large, Sparse Models , author =. Proceedings of the 38th International Conference on Machine Learning (ICML) , year =
-
[40]
arXiv preprint arXiv:2112.06905 , year =
GLaM: Efficient Scaling of Language Models with Mixture-of-Experts , author =. arXiv preprint arXiv:2112.06905 , year =
-
[41]
Mixtral of Experts , author =. arXiv preprint arXiv:2401.04088 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Qwen Technical Report , author =. arXiv preprint arXiv:2309.16609 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in Neural Information Processing Systems (NeurIPS) , year =
BinaryNet: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1 , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[44]
Nature Communications , volume =
Accurate Deep Neural Network Inference Using Computational Memory , author =. Nature Communications , volume =. 2020 , doi =
work page 2020
-
[45]
IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , pages =
Mitigating Non-Idealities in Memristor-Based Crossbar Neural Networks via Training with Hardware Variations , author =. IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , pages =. 2020 , doi =
work page 2020
-
[46]
IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , volume =
Crossbar-Aware Neural Network Training: A Hardware/Algorithm Co-Optimization Approach , author =. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems , volume =. 2021 , doi =
work page 2021
-
[47]
Design Automation Conference (DAC) , pages =
Tolerating Analog Noise in Crossbar-Based Neural Accelerators via Error-Correcting Codes , author =. Design Automation Conference (DAC) , pages =. 2020 , doi =
work page 2020
-
[48]
Proceedings of the 55th Annual Design Automation Conference (DAC) , pages =
ARES: A Framework for Quantifying the Resilience of Deep Neural Networks , author =. Proceedings of the 55th Annual Design Automation Conference (DAC) , pages =. 2018 , doi =
work page 2018
-
[49]
IEEE International Symposium on Circuits and Systems (ISCAS) , pages =
Fault Injection Attack on Deep Neural Network Hardware , author =. IEEE International Symposium on Circuits and Systems (ISCAS) , pages =. 2018 , doi =
work page 2018
-
[50]
Sparse DNNs with Improved Adversarial Robustness , author =. Advances in Neural Information Processing Systems (NeurIPS) Workshop on Machine Learning and Physical Sciences , year =
-
[51]
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding , author =. arXiv preprint arXiv:1510.00149 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages =
Efficient Hardware Acceleration of Sparse Matrix Operations for Deep Learning , author =. IEEE International Symposium on High Performance Computer Architecture (HPCA) , pages =. 2019 , doi =
work page 2019
-
[53]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning , author=. Nature , volume=. 2025 , publisher=
work page 2025
-
[54]
Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , year =
Zhou, Yanqi and others , title =. Advances in Neural Information Processing Systems 35 (NeurIPS 2022) , year =
work page 2022
-
[55]
arXiv preprint arXiv:2502.05370 , year =
Yu, Hanfei and others , title =. arXiv preprint arXiv:2502.05370 , year =
-
[56]
2026 Design, Automation and Test in Europe Conference (DATE) , year =
Yuannuo, Feng and others , title =. 2026 Design, Automation and Test in Europe Conference (DATE) , year =
work page 2026
-
[57]
IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , year =
Yayue, Hou and others , title =. IEEE/ACM International Conference on Computer-Aided Design (ICCAD) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.