Recognition: 2 theorem links
· Lean TheoremStop Marginalizing My Dreams: Model Inversion via Laplace Kernel for Continual Learning
Pith reviewed 2026-05-13 07:14 UTC · model grok-4.3
The pith
Modeling feature correlations via Laplace kernel improves data-free continual learning by generating higher-fidelity synthetic samples.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We show that modeling feature dependencies is a key ingredient for effective DFCIL. We introduce REMIX, a structured covariance modeling framework that enables scalable full-covariance modeling without the prohibitive cost of dense matrix inversion and log-determinant computation. By leveraging a Laplace kernel parameterization, REMIX captures structured feature dependencies using memory that scales linearly with the feature dimensionality, while requiring only an additional logarithmic factor in computation. Modeling these correlations produces more coherent synthetic samples and consistently improves performance across standard DFCIL benchmarks.
What carries the argument
Laplace kernel parameterization of the covariance matrix, which encodes feature correlations with linear memory cost instead of dense matrix operations.
If this is right
- Synthetic samples retain more task knowledge because correlations between features are preserved.
- Full-covariance modeling becomes practical for high-dimensional representations without quadratic memory.
- Performance gains appear consistently across standard data-free continual learning benchmarks.
- Diagonal assumptions are shown to be a limiting factor that must be removed for further progress.
Where Pith is reading between the lines
- The same kernel approach could be tested on other generative tasks that currently rely on diagonal noise assumptions.
- Alternative kernels might reveal different correlation structures that further improve retention.
- Combining this inversion method with replay buffers or regularization techniques might compound the gains.
Load-bearing premise
The Laplace kernel parameterization captures the relevant feature correlations without introducing artifacts or requiring task-specific tuning that would break scalability.
What would settle it
Reverting to diagonal covariance while keeping all other components of REMIX produces no drop in synthetic sample quality or benchmark accuracy.
Figures

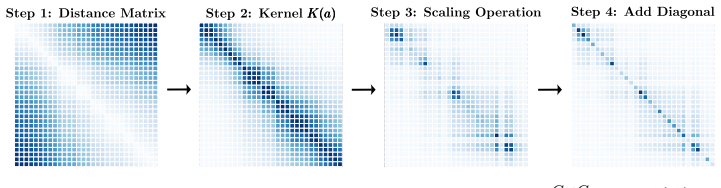


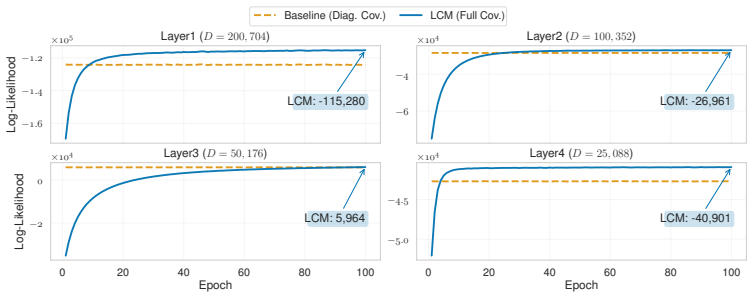




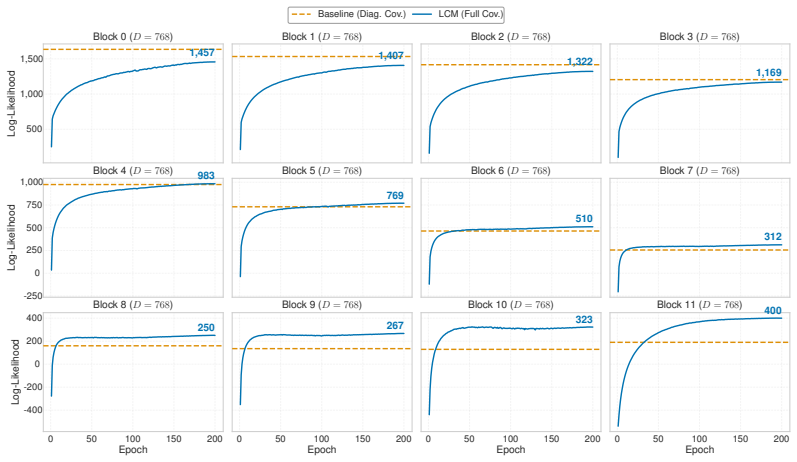
read the original abstract
Data-free continual learning (DFCIL) relies on model inversion to synthesize pseudo-samples and mitigate catastrophic forgetting. However, existing inversion methods are fundamentally limited by a simplifying assumption: they model feature distributions using diagonal covariance, effectively ignoring correlations that define the geometry of learned representations. As a result, synthesized samples often lack fidelity, limiting knowledge retention. In this work, we show that modeling feature dependencies is a key ingredient for effective DFCIL. We introduce REMIX, a structured covariance modeling framework that enables scalable full-covariance modeling without the prohibitive cost of dense matrix inversion and log-determinant computation. By leveraging a Laplace kernel parameterization, REMIX captures structured feature dependencies using memory that scales linearly with the feature dimensionality, while requiring only an additional logarithmic factor in computation. Modeling these correlations produces more coherent synthetic samples and consistently improves performance across standard DFCIL benchmarks. Our results demonstrate that moving beyond diagonal assumptions is essential for effective and scalable data-free continual learning. Our code is available at https://github. com/pkrukowski1/REMIX-Model-Inversion-via-Laplace-Kernel.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that data-free continual learning (DFCIL) is limited by diagonal-covariance assumptions in model inversion, which ignore feature correlations. It introduces REMIX, a Laplace-kernel parameterization that enables scalable structured full-covariance modeling with linear memory cost and only logarithmic extra compute, producing higher-fidelity synthetic samples and consistent benchmark gains. The central thesis is that moving beyond diagonal assumptions is essential for effective and scalable DFCIL.
Significance. If the empirical claims hold, the work would establish that structured covariance modeling is a key missing ingredient in DFCIL and supply a practical, memory-efficient mechanism to incorporate it. The linear-memory kernel approach could become a standard building block for future inversion-based continual-learning methods.
major comments (2)
- [Abstract] Abstract: the assertion that REMIX performs 'scalable full-covariance modeling' and that 'moving beyond diagonal assumptions is essential' is undercut by the fact that the Laplace kernel imposes a specific positive-definite structure (typically of the form exp(−γ‖·‖)) rather than an arbitrary covariance matrix. Without an eigenvalue-spectrum or approximation-error analysis showing that this structure can recover general feature correlations, the broader claim that any departure from diagonal covariance is necessary does not follow.
- [Abstract] Abstract: the statement that REMIX 'consistently improves performance across standard DFCIL benchmarks' is presented without any quantitative numbers, tables, ablation results, or error analysis. Because these results are the sole empirical support for the central claim, their absence prevents verification of effect size, statistical significance, or whether gains arise from the kernel structure itself rather than from better-conditioned sampling.
minor comments (1)
- [Abstract] The GitHub link in the abstract contains an extraneous space ('https://github. com/pkrukowski1/REMIX-Model-Inversion-via-Laplace-Kernel'); this should be corrected for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below, clarifying the scope of our claims about the Laplace kernel and committing to revisions that strengthen the presentation of our empirical results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that REMIX performs 'scalable full-covariance modeling' and that 'moving beyond diagonal assumptions is essential' is undercut by the fact that the Laplace kernel imposes a specific positive-definite structure (typically of the form exp(−γ‖·‖)) rather than an arbitrary covariance matrix. Without an eigenvalue-spectrum or approximation-error analysis showing that this structure can recover general feature correlations, the broader claim that any departure from diagonal covariance is necessary does not follow.
Authors: We appreciate the referee's observation that the Laplace kernel induces a specific structured covariance rather than an arbitrary full matrix. REMIX is explicitly designed to parameterize structured (non-diagonal) covariances via the kernel, enabling dense feature correlations at linear memory cost; this is what we mean by 'scalable full-covariance modeling' in contrast to the diagonal assumption used in prior DFCIL work. The Laplace kernel is a standard positive-definite choice in Gaussian processes that can capture a range of correlation geometries through its length-scale parameters. While the current manuscript relies on empirical evidence that this structure produces higher-fidelity inversions and better retention, we agree that additional discussion of its approximation properties would be valuable. We will add a paragraph in the revised manuscript discussing the spectral properties of the Laplace kernel and its ability to model feature dependencies beyond the diagonal case. revision: partial
-
Referee: [Abstract] Abstract: the statement that REMIX 'consistently improves performance across standard DFCIL benchmarks' is presented without any quantitative numbers, tables, ablation results, or error analysis. Because these results are the sole empirical support for the central claim, their absence prevents verification of effect size, statistical significance, or whether gains arise from the kernel structure itself rather than from better-conditioned sampling.
Authors: We agree that the abstract would be strengthened by including quantitative highlights. The full manuscript contains tables and ablations (including comparisons to diagonal baselines, kernel ablations, and error bars across multiple runs) demonstrating consistent gains on standard DFCIL benchmarks. To address the referee's concern, we will revise the abstract to include specific quantitative statements referencing the magnitude of improvements and the experimental controls that isolate the contribution of the structured covariance. revision: yes
Circularity Check
No circularity: explicit new parameterization independent of target fits
full rationale
The paper introduces REMIX as a novel structured covariance framework that adopts a Laplace kernel parameterization to model feature dependencies scalably. This is an explicit design choice presented in the abstract and method, not a quantity derived from or fitted to the target data by construction. No self-citations are invoked as load-bearing for the core premise, no uniqueness theorems are imported, and no 'predictions' reduce to renamed fitted inputs. Empirical gains on DFCIL benchmarks are claimed from the new modeling approach rather than tautological redefinitions. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Laplace kernel parameterization captures the necessary feature dependencies for high-fidelity model inversion
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBy leveraging a Laplace kernel parameterization, REMIX captures structured feature dependencies using memory that scales linearly with the feature dimensionality... Kij(a) = exp(−|ai − aj|)
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclearthe resulting covariance parameterization takes the form Σ = diag(d) + diag(w)K(a)diag(w)
Reference graph
Works this paper leans on
-
[1]
Catastrophic interference in connectionist networks: The sequential learning problem
Michael McCloskey and Neal J Cohen. Catastrophic interference in connectionist networks: The sequential learning problem. InPsychology of learning and motivation, volume 24, pages 109–165. Elsevier, 1989
work page 1989
-
[2]
Yen-Chang Hsu, Yen-Cheng Liu, Anita Ramasamy, and Zsolt Kira. Re-evaluating con- tinual learning scenarios: A categorization and case for strong baselines.arXiv preprint arXiv:1810.12488, 2018
-
[3]
Georgios A Kaissis, Marcus R Makowski, Daniel Rückert, and Rickmer F Braren. Secure, privacy-preserving and federated machine learning in medical imaging.Nature Machine Intelligence, 2(6):305–311, 2020
work page 2020
-
[4]
Matthias De Lange, Rahaf Aljundi, Marc Masana, Sarah Parisot, Xu Jia, Aleš Leonardis, Gregory Slabaugh, and Tinne Tuytelaars. A continual learning survey: Defying forgetting in classification tasks.IEEE transactions on pattern analysis and machine intelligence, 44(7):3366– 3385, 2021
work page 2021
-
[5]
Zero-shot knowledge distillation in deep networks
Gaurav Kumar Nayak, Konda Reddy Mopuri, Vaisakh Shaj, Venkatesh Babu Radhakrishnan, and Anirban Chakraborty. Zero-shot knowledge distillation in deep networks. InInternational conference on machine learning, pages 4743–4751. PMLR, 2019
work page 2019
-
[6]
Dreaming to distill: Data-free knowledge transfer via deepinversion
Hongxu Yin, Pavlo Molchanov, Jose M Alvarez, Zhizhong Li, Arun Mallya, Derek Hoiem, Niraj K Jha, and Jan Kautz. Dreaming to distill: Data-free knowledge transfer via deepinversion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8715–8724, 2020
work page 2020
-
[7]
Always be dreaming: A new approach for data-free class-incremental learning
James Smith, Yen-Chang Hsu, Jonathan Balloch, Yilin Shen, Hongxia Jin, and Zsolt Kira. Always be dreaming: A new approach for data-free class-incremental learning. InProceedings of the IEEE/CVF international conference on computer vision, pages 9374–9384, 2021
work page 2021
-
[8]
R-dfcil: Relation-guided represen- tation learning for data-free class incremental learning
Qiankun Gao, Chen Zhao, Bernard Ghanem, and Jian Zhang. R-dfcil: Relation-guided represen- tation learning for data-free class incremental learning. InEuropean Conference on Computer Vision, pages 423–439. Springer, 2022
work page 2022
-
[9]
Model inversion with layer-specific modeling and alignment for data-free continual learning
Ruilin Tong, Haodong Lu, Yuhang Liu, and Dong Gong. Model inversion with layer-specific modeling and alignment for data-free continual learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[10]
icarl: Incremental classifier and representation learning
Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. icarl: Incremental classifier and representation learning. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 2001–2010, 2017
work page 2001
-
[11]
Podnet: Pooled outputs distillation for small-tasks incremental learning
Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled outputs distillation for small-tasks incremental learning. InEuropean conference on computer vision, pages 86–102. Springer, 2020
work page 2020
-
[12]
End-to-end incremental learning
Francisco M Castro, Manuel J Marín-Jiménez, Nicolás Guil, Cordelia Schmid, and Karteek Alahari. End-to-end incremental learning. InProceedings of the European conference on computer vision (ECCV), pages 233–248, 2018
work page 2018
-
[13]
Learning a unified classifier incrementally via rebalancing
Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a unified classifier incrementally via rebalancing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 831–839, 2019
work page 2019
-
[14]
Semantic drift compensation for class-incremental learning
Lu Yu, Bartlomiej Twardowski, Xialei Liu, Luis Herranz, Kai Wang, Yongmei Cheng, Shangling Jui, and Joost van de Weijer. Semantic drift compensation for class-incremental learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6982–6991, 2020. 10
work page 2020
-
[15]
Rainbow memory: Continual learning with a memory of diverse samples
Jihwan Bang, Heesu Kim, YoungJoon Yoo, Jung-Woo Ha, and Jonghyun Choi. Rainbow memory: Continual learning with a memory of diverse samples. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8218–8227, 2021
work page 2021
-
[16]
Gdumb: A simple approach that questions our progress in continual learning
Ameya Prabhu, Philip HS Torr, and Puneet K Dokania. Gdumb: A simple approach that questions our progress in continual learning. InEuropean conference on computer vision, pages 524–540. Springer, 2020
work page 2020
-
[17]
Adaptive aggregation networks for class- incremental learning
Yaoyao Liu, Bernt Schiele, and Qianru Sun. Adaptive aggregation networks for class- incremental learning. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, pages 2544–2553, 2021
work page 2021
-
[18]
Dipam Goswami, Yuyang Liu, Bartłomiej Twardowski, and Joost Van De Weijer. Fecam: Exploiting the heterogeneity of class distributions in exemplar-free continual learning.Advances in Neural Information Processing Systems, 36:6582–6595, 2023
work page 2023
-
[19]
Fetril: Feature translation for exemplar-free class-incremental learning
Grégoire Petit, Adrian Popescu, Hugo Schindler, David Picard, and Bertrand Delezoide. Fetril: Feature translation for exemplar-free class-incremental learning. InProceedings of the IEEE/CVF winter conference on applications of computer vision, pages 3911–3920, 2023
work page 2023
-
[20]
Task- recency bias strikes back: Adapting covariances in exemplar-free class incremental learning
Grzegorz Rype´s´c, Sebastian Cygert, Tomasz Trzci ´nski, and Bartłomiej Twardowski. Task- recency bias strikes back: Adapting covariances in exemplar-free class incremental learning. Advances in Neural Information Processing Systems, 37:63268–63289, 2024
work page 2024
-
[21]
Zhizhong Li and Derek Hoiem. Learning without forgetting.IEEE transactions on pattern analysis and machine intelligence, 40(12):2935–2947, 2017
work page 2017
-
[22]
Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual learning with deep generative replay.Advances in neural information processing systems, 30, 2017
work page 2017
-
[23]
Yulai Cong, Miaoyun Zhao, Jianqiao Li, Sijia Wang, and Lawrence Carin. Gan memory with no forgetting.Advances in neural information processing systems, 33:16481–16494, 2020
work page 2020
-
[24]
Fearnet: Brain-inspired model for incremental learning
Ronald Kemker and Christopher Kanan. Fearnet: Brain-inspired model for incremental learning. InInternational Conference on Learning Representations, 2018
work page 2018
-
[25]
Chenshen Wu, Luis Herranz, Xialei Liu, Joost Van De Weijer, Bogdan Raducanu, et al. Memory replay gans: Learning to generate new categories without forgetting.Advances in neural information processing systems, 31, 2018
work page 2018
-
[26]
Learning latent representations across multiple data domains using lifelong vaegan
Fei Ye and Adrian G Bors. Learning latent representations across multiple data domains using lifelong vaegan. InEuropean Conference on Computer Vision, pages 777–795. Springer, 2020
work page 2020
-
[27]
Gido M Van de Ven, Hava T Siegelmann, and Andreas S Tolias. Brain-inspired replay for continual learning with artificial neural networks.Nature communications, 11(1):4069, 2020
work page 2020
-
[28]
Theoretical insights into mem- orization in gans
Vaishnavh Nagarajan, Colin Raffel, and Ian J Goodfellow. Theoretical insights into mem- orization in gans. InNeural Information Processing Systems Workshop, volume 1, page 3, 2018
work page 2018
-
[29]
An image is worth 16x16 words: Transformers for image recognition at scale, 2021
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021
work page 2021
-
[30]
What do we learn from inverting clip models?, 2024
Hamid Kazemi, Atoosa Chegini, Jonas Geiping, Soheil Feizi, and Tom Goldstein. What do we learn from inverting clip models?, 2024
work page 2024
-
[31]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. pages 32–33, 2009
work page 2009
-
[32]
Jiayu Wu, Qixiang Zhang, and Guoxia Xu. Tiny imagenet challenge. 2017
work page 2017
-
[33]
Peter Welinder, Steve Branson, Takeshi Mita, Catherine Wah, Florian Schroff, Serge Belongie, and Pietro Perona. Caltech-ucsd birds 200. 09 2010. 11
work page 2010
-
[34]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machin...
work page 2021
-
[35]
0−ρ C−1 1 , andϵhas diagonal covariance D= diag(1,1−ρ 2 1, . . . ,1−ρ 2 C−1). It follows that the covariance and precision matrices admit the factorization K=L −1DL−⊤,Q=K −1 =L ⊤D−1L. Explicit Form of the Precision Matrix.The inverse covariance Q is given by Q=L ⊤D−1L, where D−1 1,1 = 1,D −1 k,k = 1 1−ρ 2 k−1 ,1< k≤C. For diagonal entries: •i= 1: ...
-
[36]
Obtain target featuresS feat at layerLusing CFS
-
[37]
Initialize ˆol as Gaussian noise scaled by stored input statistics
-
[38]
Optimize ˆol via gradient descent so that its forward pass through the frozen block matches the target
-
[39]
Use the optimized ˆol as the target for the preceding layerl−1. This sequential procedure decomposes a highly non-convex global objective into a series of well- conditioned local problems. Layer-wise Optimization Objective.At each blockl >0, we optimize ˆol using L(l) layer =α matchL(l) match +α statL(l) stat +α inL(l) in
-
[40]
Feature Matching Loss (L(l) match).The formulation of the deterministic matching loss depends strictly on the depth of the layer being optimized. 15 At the topmost layer ( l=L ), the optimization aims to align the generated features directly with the target class label y. Therefore, the matching objective utilizes a standard CE loss: L(L) match = Lce(ˆoL,...
-
[41]
Distribution Statistic Loss (L(l) stat): We regularize intermediate activations to match the feature statistics observed on real data by modeling their distribution with the proposed LCM and minimizing the exact Gaussian Negative Log-Likelihood (NLL). Given a batch of generated features {ˆol,i}N i=1 ∈R C, the objective under the multivariate Gaussian dist...
-
[42]
Input Statistic Prior (L(l) in ):Due to the strong non-linearity of deep networks, directly optimizing the input tensor ˆol to match downstream targets can lead to adversarial or out-of-distribution activa- tions. Although such features may satisfy the feature-matching objective, they often lack meaningful structure and can destabilize subsequent inversio...
-
[43]
Local Classification Loss (Llce).The local classification loss is a standard CE objective applied exclusively to real samples from the current task. By restricting supervision toXnew, the model learns new classes without being biased by imperfections in synthetic data: Llce = 1 |Xnew| X (x,y)∈(Xnew,Ynew) Lce softmax(fhead(ffeat(x;θ);ϕ new)), y
-
[44]
Hard Knowledge Distillation (Lhkd).To explicitly preserve knowledge from previous tasks, we apply hard knowledge distillation on synthetic samples. This term enforces consistency between the outputs of the current model and the frozen teacher by penalizing deviations in logits: Lhkd = 1 |Xold| |Y1:t| X x∈Xold ∥fhead(ffeat(x;θ 1:t);ϕ 1:t)−f head(ffeat(x;θ)...
-
[45]
Relational Knowledge Distillation ( Lrkd).While Lhkd constrains absolute predictions, it can overly restrict the feature space. To counterbalance this effect, we introduce relational knowledge distillation, which preserves the geometric structure of the feature space by matching angular rela- tionships between features. Let u and v be learnable projection...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.