Recognition: 2 theorem links
· Lean TheoremBeyond World-Frame Action Heads: Motion-Centric Action Frames for Vision-Language-Action Models
Pith reviewed 2026-05-13 06:02 UTC · model grok-4.3
The pith
VLA models gain robustness by learning local motion frames instead of predicting world-frame actions directly.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
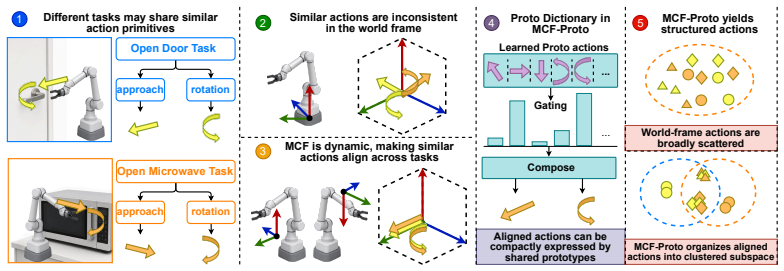
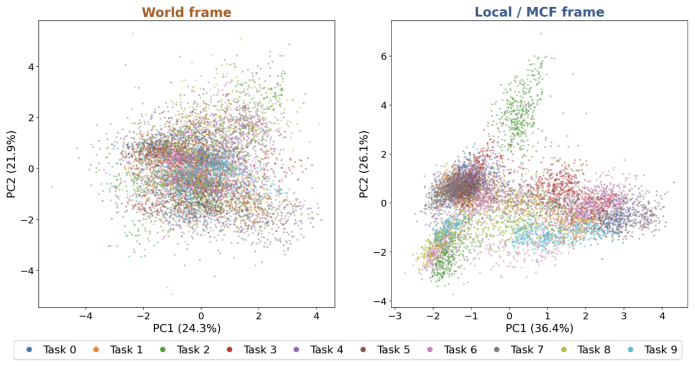
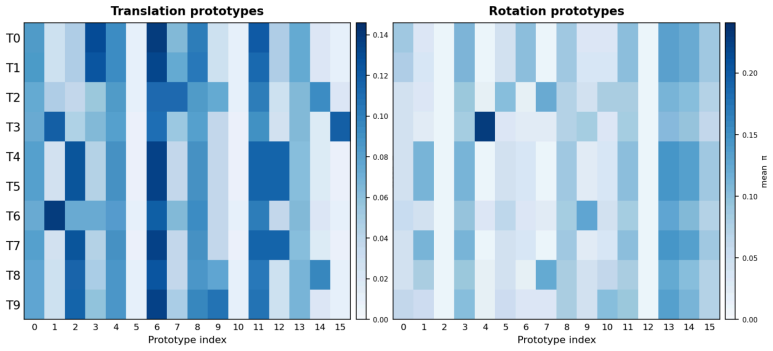
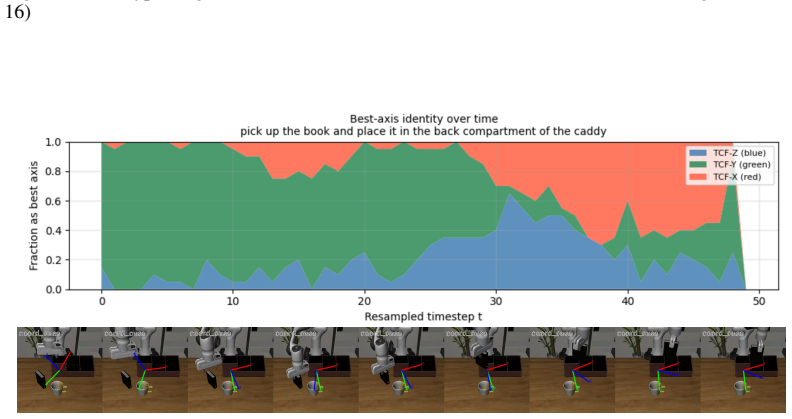
By predicting a rotation R_t in SO(3) at each step, composing actions from a set of prototypes inside the transformed local frame, and mapping the result back to world coordinates for end-to-end training, the policy induces stable emergent geometric structure whose axes match demonstrated end-effector motion; actions become substantially more compact with variation captured by fewer dominant directions organized by shared prototypes; and robustness improves under geometric perturbations.
What carries the argument
The Motion-Centric Action Frame (MCF) together with prototype-based parameterization: the policy outputs a rotation to define the local frame, selects and combines prototypes inside it, and transforms the resulting action back to the world frame.
If this is right
- Local frames develop a stable geometric structure whose axes are strongly compatible with demonstrated end-effector motion without any explicit directional supervision.
- Actions in the learned representation become substantially more compact, with variation captured by fewer dominant directions and more regularly organized by shared prototypes.
- These structural properties produce improved robustness, especially under geometric perturbations.
- Adding lightweight geometric and compositional structure to the action head improves how VLA policies organize and generalize robotic manipulation behavior.
Where Pith is reading between the lines
- The emergent alignment suggests that the action head can discover motion-relevant directions from trajectory statistics alone, potentially reducing reliance on hand-engineered coordinate frames.
- Compact prototype-based representations could make it easier to transfer policies across robots or environments that share similar motion patterns but differ in absolute scale or orientation.
- The approach might generalize beyond manipulation to other continuous control domains where local frame prediction could induce useful structure without task-specific labels.
Load-bearing premise
That predicting only a rotation in SO(3) and composing actions from prototypes inside the resulting local frame will cause the learned axes to align with end-effector motion and deliver robustness gains when trained on standard demonstration trajectories alone.
What would settle it
Training an identical VLA backbone with the new head versus a standard world-frame head on the same datasets and measuring whether axis alignment with end-effector motion appears and whether success rates drop less under controlled rotations or translations of the scene.
Figures




read the original abstract
Vision-Language-Action (VLA) models have advanced rapidly with stronger backbones, broader pre-training, and larger demonstration datasets, yet their action heads remain largely homogeneous: most directly predict action commands in a fixed world coordinate frame. We propose \textbf{MCF-Proto}, a lightweight action head that equips VLA policies with a Motion-Centric Action Frame (MCF) and a prototype-based action parameterization. At each step, the policy predicts a rotation $R_t \in SO(3)$, composes actions in the transformed local frame from a set of prototypes, and maps them back to the world frame for end-to-end training, using only standard demonstrations without auxiliary supervision. This simple design induces stable emergent structure. Without explicit directional labels, the learned local frames develop a stable geometric structure whose axes are strongly compatible with demonstrated end-effector motion. Meanwhile, actions in the learned representation become substantially more compact, with variation captured by fewer dominant directions and more regularly organized by shared prototypes. These structural properties translate into improved robustness, especially under geometric perturbations. Our results suggest that adding lightweight geometric and compositional structure to the action head can materially improve how VLA policies organize and generalize robotic manipulation behavior. An anonymized code repository is provided in the supplementary material.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MCF-Proto, a lightweight action head for Vision-Language-Action (VLA) models. At each timestep the policy predicts a rotation R_t in SO(3), composes actions from a fixed set of prototypes inside the resulting local Motion-Centric Action Frame, and transforms the resulting action back to the world frame. Training uses only the standard world-frame action regression loss on ordinary demonstration trajectories, with no auxiliary supervision, directional labels, or stability regularizers. The central claim is that this architecture induces stable emergent geometric structure whose axes align with demonstrated end-effector motion, yields more compact action representations, and improves robustness under geometric perturbations.
Significance. If the empirical claims are substantiated, the work would demonstrate that a minimal geometric and compositional change to the action head can produce measurable improvements in organization and robustness of VLA policies without extra data or losses. The emergence of motion-aligned frames from standard end-to-end training would be a notable result for robotic manipulation.
major comments (2)
- [Section 3] Section 3 (MCF-Proto definition): the parameterization allows any R_t that permits prototype reconstruction of observed actions; no auxiliary term, orthogonality constraint, or stability regularizer is introduced, so the optimization has no explicit pressure to select motion-aligned frames. The manuscript must therefore supply either a formal argument or controlled ablations isolating the source of the claimed alignment.
- [Section 5] Section 5 (experimental results): the abstract and results claim improved robustness under geometric perturbations and more compact action representations, yet the provided text supplies no quantitative metrics, error bars, baseline comparisons, or precise description of how perturbations were generated. These details are load-bearing for the central claim and must be added.
minor comments (2)
- [Section 3] Notation: the number of prototypes, their initialization, and whether they are learned or fixed should be stated explicitly in the method section.
- [Abstract] The supplementary code repository is mentioned but no access instructions or anonymized link are provided.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below and will revise the manuscript to strengthen the presentation of the claimed emergence and empirical support.
read point-by-point responses
-
Referee: [Section 3] Section 3 (MCF-Proto definition): the parameterization allows any R_t that permits prototype reconstruction of observed actions; no auxiliary term, orthogonality constraint, or stability regularizer is introduced, so the optimization has no explicit pressure to select motion-aligned frames. The manuscript must therefore supply either a formal argument or controlled ablations isolating the source of the claimed alignment.
Authors: We agree that the current manuscript provides neither a formal proof that the learned R_t must align with motion nor controlled ablations that isolate the contribution of the prototype parameterization. In the revision we will add a dedicated ablation subsection containing: (i) a direct comparison of learned frame axes against the principal components of end-effector velocity in the demonstration data, (ii) training runs that disable the prototype layer while retaining the predicted rotation, and (iii) plots tracking the alignment metric over the course of training. These experiments will clarify whether the observed geometric structure arises specifically from the interaction between the rotation head and the prototype reconstruction objective. revision: yes
-
Referee: [Section 5] Section 5 (experimental results): the abstract and results claim improved robustness under geometric perturbations and more compact action representations, yet the provided text supplies no quantitative metrics, error bars, baseline comparisons, or precise description of how perturbations were generated. These details are load-bearing for the central claim and must be added.
Authors: The referee correctly notes that the main text as submitted lacks the quantitative numbers, error bars, and perturbation protocol. The supplementary material already contains the full tables (success rates with mean and standard deviation over five random seeds for MCF-Proto versus world-frame and other baselines) together with PCA-based compactness metrics. We will move the key tables and figures into the main body, add an explicit paragraph describing the perturbation generation procedure (random rotations drawn uniformly from SO(3) with maximum angle 30 degrees applied to the observation frame), and ensure all plots display error bars. revision: yes
Circularity Check
No circularity: architectural proposal with empirical emergence claims
full rationale
The paper introduces MCF-Proto as a lightweight action head that predicts R_t in SO(3) and composes prototype actions in the local frame before mapping back to world coordinates. All training uses only the standard end-to-end action regression loss on ordinary demonstration trajectories, with no auxiliary terms, constraints, or regularizers on frame alignment. The claimed stable geometric structure and axis compatibility with end-effector motion are presented strictly as observed outcomes of this training process rather than as quantities derived by construction, fitted parameters renamed as predictions, or results justified solely by self-citation. No equations or uniqueness theorems in the manuscript reduce the reported compactness, organization, or robustness gains to the input design itself; the central claims therefore remain independent of the inputs and are subject to external experimental validation.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Motion-Centric Action Frame
no independent evidence
-
Prototype-based action parameterization
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoespredicts a rotation R_t ∈ SO(3) to define a Motion-Centric Action Frame (MCF). Within this frame, actions are generated as soft combinations of a small shared prototype dictionary... mapped back to the world frame
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearactions expressed in the learned representation become substantially more compact, with variation captured by fewer dominant directions
Reference graph
Works this paper leans on
-
[1]
Learning from demonstrations with partially observable task parameters
Tohid Alizadeh, Sylvain Calinon, and Darwin G Caldwell. Learning from demonstrations with partially observable task parameters. In2014 IEEE International Conference on Robotics and Automation (ICRA), pages 3309–3314. IEEE, 2014
work page 2014
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A visio...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Pact: Perception-action causal transformer for autoregressive robotics pre-training
Rogerio Bonatti, Sai Vemprala, Shuang Ma, Felipe Frujeri, Shuhang Chen, and Ashish Kapoor. Pact: Perception-action causal transformer for autoregressive robotics pre-training. In2023 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pages 3621–3627. IEEE, 2023
work page 2023
-
[4]
RoboCat : A self-improving foundation agent for robotic manipulation
Konstantinos Bousmalis, Giulia Vezzani, Dushyant Rao, Coline Devin, Alex X Lee, Maria Bauzá, Todor Davchev, Yuxiang Zhou, Agrim Gupta, Akhil Raju, et al. Robocat: A self-improving generalist agent for robotic manipulation.arXiv preprint arXiv:2306.11706, 2023
-
[5]
RT-1: Robotics Transformer for Real-World Control at Scale
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Sylvain Calinon. A tutorial on task-parameterized movement learning and retrieval.Intelligent service robotics, 9(1):1–29, 2016
work page 2016
-
[7]
A task-parameterized probabilistic model with minimal intervention control
Sylvain Calinon, Danilo Bruno, and Darwin G Caldwell. A task-parameterized probabilistic model with minimal intervention control. In2014 IEEE International Conference on Robotics and Automation (ICRA), pages 3339–3344. IEEE, 2014
work page 2014
-
[8]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. Worldvla: Towards autoregressive action world model, 2025. URLhttps://arxiv.org/abs/2506.21539
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Shizhe Chen, Ricardo Garcia, Cordelia Schmid, and Ivan Laptev. Polarnet: 3d point clouds for language- guided robotic manipulation.arXiv preprint arXiv:2309.15596, 2023
-
[10]
Manipulation-oriented object perception in clutter through affordance coordinate frames
Xiaotong Chen, Kaizhi Zheng, Zhen Zeng, Cameron Kisailus, Shreshtha Basu, James Cooney, Jana Pavlasek, and Odest Chadwicke Jenkins. Manipulation-oriented object perception in clutter through affordance coordinate frames. In2022 IEEE-RAS 21st International Conference on Humanoid Robots (Humanoids), pages 186–193. IEEE, 2022
work page 2022
-
[11]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
work page 2025
-
[12]
From play to policy: Conditional behavior generation from uncurated robot data
Zichen Jeff Cui, Yibin Wang, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. From play to policy: Conditional behavior generation from uncurated robot data. InThe Eleventh International Conference on Learning Representations, 2023. URLhttps://openreview.net/forum?id=c7rM7F7jQjN
work page 2023
-
[13]
Deep object-centric representations for generalizable robot learning
Coline Devin, Pieter Abbeel, Trevor Darrell, and Sergey Levine. Deep object-centric representations for generalizable robot learning. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 7111–7118. IEEE, 2018
work page 2018
-
[14]
Deep se(3)- equivariant geometric reasoning for precise placement tasks
Ben Eisner, Yi Yang, Todor Davchev, Mel Vecerik, Jonathan Scholz, and David Held. Deep se(3)- equivariant geometric reasoning for precise placement tasks. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragki- adaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 26866–26886, 2024. URLhttps://proceedings.iclr....
work page 2024
-
[15]
LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Javier Felip, Janne Laaksonen, Antonio Morales, and Ville Kyrki. Manipulation primitives: A paradigm for abstraction and execution of grasping and manipulation tasks.Robotics and Autonomous Systems, 61 (3):283–296, 2013
work page 2013
-
[17]
Pete Florence, Corey Lynch, Andy Zeng, Oscar A Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. Implicit behavioral cloning. InConference on robot learning, pages 158–168. PMLR, 2022
work page 2022
-
[18]
Felix Frank, Alexandros Paraschos, Patrick van der Smagt, and Botond Cseke. Constrained probabilistic movement primitives for robot trajectory adaptation.IEEE Transactions on Robotics, 38(4):2276–2294, 2021
work page 2021
-
[19]
Rvt: Robotic view transformer for 3d object manipulation
Ankit Goyal, Jie Xu, Yijie Guo, Valts Blukis, Yu-Wei Chao, and Dieter Fox. Rvt: Robotic view transformer for 3d object manipulation. InConference on Robot Learning, pages 694–710. PMLR, 2023
work page 2023
-
[20]
Nora: A small open-sourced generalist vision language action model for embodied tasks,
Chia-Yu Hung, Qi Sun, Pengfei Hong, Amir Zadeh, Chuan Li, U-Xuan Tan, Navonil Majumder, and Soujanya Poria. Nora: A small open-sourced generalist vision language action model for embodied tasks,
- [21]
-
[22]
Auke Jan Ijspeert, Jun Nakanishi, Heiko Hoffmann, Peter Pastor, and Stefan Schaal. Dynamical movement primitives: learning attractor models for motor behaviors.Neural computation, 25(2):328–373, 2013
work page 2013
-
[23]
Bc-z: Zero-shot task generalization with robotic imitation learning
Eric Jang, Alex Irpan, Mohi Khansari, Daniel Kappler, Frederik Ebert, Corey Lynch, Sergey Levine, and Chelsea Finn. Bc-z: Zero-shot task generalization with robotic imitation learning. Inconference on Robot Learning, pages 991–1002. PMLR, 2022
work page 2022
-
[24]
Oussama Khatib. A unified approach for motion and force control of robot manipulators: The operational space formulation.IEEE Journal on Robotics and Automation, 3(1):43–53, 1987
work page 1987
-
[25]
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
Seungjae Lee, Yibin Wang, Haritheja Etukuru, H Jin Kim, Nur Muhammad Mahi Shafiullah, and Lerrel Pinto. Behavior generation with latent actions.arXiv preprint arXiv:2403.03181, 2024
-
[28]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
work page 2023
-
[29]
Manipulation task primitives for composing robot skills
J Daniel Morrow and Pradeep K Khosla. Manipulation task primitives for composing robot skills. In Proceedings of International Conference on Robotics and Automation, volume 4, pages 3354–3359. IEEE, 1997
work page 1997
-
[30]
Jun Nakanishi, Rick Cory, Michael Mistry, Jan Peters, and Stefan Schaal. Operational space control: A theoretical and empirical comparison.The International Journal of Robotics Research, 27(6):737–757, 2008
work page 2008
-
[31]
GR00T N1: An open foundation model for generalist humanoid robots
NVIDIA, Johan Bjorck, Nikita Cherniadev Fernando Castañeda, Xingye Da, Runyu Ding, Linxi "Jim" Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You L...
work page 2025
-
[32]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0
Abby O’Neill, Abdul Rehman, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024
work page 2024
-
[33]
Probabilistic movement primitives.Advances in neural information processing systems, 26, 2013
Alexandros Paraschos, Christian Daniel, Jan R Peters, and Gerhard Neumann. Probabilistic movement primitives.Advances in neural information processing systems, 26, 2013. 11
work page 2013
-
[34]
FAST: Efficient Action Tokenization for Vision-Language-Action Models
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. Fast: Efficient action tokenization for vision-language-action models, 2025. URL https://arxiv.org/abs/2501.09747
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Deep probabilistic move- ment primitives with a bayesian aggregator
Michael Przystupa, Faezeh Haghverd, Martin Jagersand, and Samuele Tosatto. Deep probabilistic move- ment primitives with a bayesian aggregator. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3704–3711. IEEE, 2023
work page 2023
-
[36]
FLOWER: Democratizing generalist robot policies with efficient vision-language-flow models
Moritz Reuss, Hongyi Zhou, Marcel Rühle, Ömer Erdinç Ya˘gmurlu, Fabian Otto, and Rudolf Lioutikov. FLOWER: Democratizing generalist robot policies with efficient vision-language-flow models. In9th An- nual Conference on Robot Learning, 2025. URLhttps://openreview.net/forum?id=JeppaebLRD
work page 2025
-
[37]
Elmar Rückert and Andrea d’Avella. Learned parametrized dynamic movement primitives with shared synergies for controlling robotic and musculoskeletal systems.Frontiers in computational neuroscience, 7: 138, 2013
work page 2013
-
[38]
Hyunwoo Ryu, Hong-in Lee, Jeong-Hoon Lee, and Jongeun Choi. Equivariant descriptor fields: Se (3)-equivariant energy-based models for end-to-end visual robotic manipulation learning.arXiv preprint arXiv:2206.08321, 2022
-
[39]
Nur Muhammad Shafiullah, Zichen Cui, Ariuntuya Arty Altanzaya, and Lerrel Pinto. Behavior transform- ers: Cloning k modes with one stone.Advances in neural information processing systems, 35:22955–22968, 2022
work page 2022
-
[40]
Mohit Sharma, Jacky Liang, Jialiang Zhao, Alex LaGrassa, and Oliver Kroemer. Learning to compose hierarchical object-centric controllers for robotic manipulation.arXiv preprint arXiv:2011.04627, 2020
-
[41]
William Shen, Ge Yang, Alan Yu, Jansen Wong, Leslie Pack Kaelbling, and Phillip Isola. Distilled feature fields enable few-shot language-guided manipulation.arXiv preprint arXiv:2308.07931, 2023
-
[42]
Cliport: What and where pathways for robotic manipula- tion
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipula- tion. InConference on robot learning, pages 894–906. PMLR, 2022
work page 2022
-
[43]
Perceiver-actor: A multi-task transformer for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Perceiver-actor: A multi-task transformer for robotic manipulation. InConference on Robot Learning, pages 785–799. PMLR, 2023
work page 2023
-
[44]
Neural descriptor fields: Se (3)-equivariant object representations for manipulation
Anthony Simeonov, Yilun Du, Andrea Tagliasacchi, Joshua B Tenenbaum, Alberto Rodriguez, Pulkit Agrawal, and Vincent Sitzmann. Neural descriptor fields: Se (3)-equivariant object representations for manipulation. In2022 International Conference on Robotics and Automation (ICRA), pages 6394–6400. IEEE, 2022
work page 2022
-
[45]
Se (3)-equivariant relational rearrangement with neural descriptor fields
Anthony Simeonov, Yilun Du, Yen-Chen Lin, Alberto Rodriguez Garcia, Leslie Pack Kaelbling, Tomás Lozano-Pérez, and Pulkit Agrawal. Se (3)-equivariant relational rearrangement with neural descriptor fields. InConference on Robot Learning, pages 835–846. PMLR, 2023
work page 2023
-
[46]
Interactive post-training for vision-language- action models, 2025
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Krähenbühl. Interactive post-training for vision-language- action models, 2025. URLhttps://arxiv.org/abs/2505.17016
-
[47]
Octo: An Open-Source Generalist Robot Policy
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Unified vision-language-action model, 2025
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model, 2025. URL https://arxiv.org/abs/2506. 19850
work page 2025
-
[49]
Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. arXiv preprint arXiv:2312.13139, 2023
work page internal anchor Pith review arXiv 2023
-
[50]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipula- tion with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Beast: Efficient tokenization of b-splines encoded action sequences for imitation learning, 2025
Hongyi Zhou, Weiran Liao, Xi Huang, Yucheng Tang, Fabian Otto, Xiaogang Jia, Xinkai Jiang, Simon Hilber, Ge Li, Qian Wang, Ömer Erdinç Ya ˘gmurlu, Nils Blank, Moritz Reuss, and Rudolf Lioutikov. Beast: Efficient tokenization of b-splines encoded action sequences for imitation learning, 2025. URL https://arxiv.org/abs/2506.06072. 12
-
[52]
Vima: General robot manipulation with multimodal prompts
Y Zhu et al. Vima: General robot manipulation with multimodal prompts. InInternational Conference on Learning Representations (ICLR), 2023
work page 2023
-
[53]
Yifeng Zhu, Zhenyu Jiang, Peter Stone, and Yuke Zhu. Learning generalizable manipulation policies with object-centric 3d representations.arXiv preprint arXiv:2310.14386, 2023
-
[54]
pick up the book and place it in the black compartment of the caddy
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. Anonymous Code Repository An anonymized code repository for reproducing the experiment...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.