Recognition: 2 theorem links
· Lean TheoremSelection, Not Fusion: Radar-Modulated State Space Models for Radar-Camera Depth Estimation
Pith reviewed 2026-05-13 07:33 UTC · model grok-4.3
The pith
Radar modulates only the step size and readout inside Mamba's selective scan to achieve superior radar-camera depth estimation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Radar-Modulated Selection injects radar information into Mamba by perturbing the step size Δ and readout C with zero-initialized radar-derived values while leaving B and A as image-only quantities. The design guarantees equivalence to a pretrained image-only Mamba at the start of training and provides linear-cost cross-modal coupling inside the recurrence. When embedded in a Multi-View Scan Pyramid, the network reduces mean absolute depth error by 34.0 percent, 29.9 percent, and 29.9 percent over the previous best on nuScenes for the 0-50 m, 0-70 m, and 0-80 m ranges while achieving 26.8 ms single-frame latency.
What carries the argument
Radar-Modulated Selection, the process of adding zero-initialized perturbations from radar to the step size Δ and readout C parameters of Mamba's selective scan.
If this is right
- Cross-modal information is coupled at every recurrence step inside the scan at linear cost.
- The model automatically falls back to image-only behavior when radar data is absent or uninformative.
- Additional out-of-scan feature blending layers contribute no accuracy improvement beyond the in-scan modulation.
- Matching the fusion operator to radar's spatial reach at each pyramid scale improves overall performance.
Where Pith is reading between the lines
- The same selective perturbation pattern may transfer to other sequence models that must combine sparse metric measurements with dense visual data.
- If the zero-initialization property is preserved after training, the approach could simplify verification in safety-critical perception systems.
- Selection mechanisms in general may prove more effective than post-processing fusion for tasks that convert sparse sensor readings into dense outputs.
Load-bearing premise
Perturbing only the step size and readout with radar data is enough to extract useful cross-modal information while the zero initialization and image-only components prevent any degradation from uninformative radar.
What would settle it
Replacing radar inputs with zeros or noise during both training and testing and checking whether depth accuracy stays identical to the image-only baseline would falsify the claim that the modulation adds value without risk.
Figures

read the original abstract
Radar-camera depth estimation must turn an ultra-sparse, all-weather, metric radar signal into a dense per-pixel depth map. Existing methods -- concatenation, confidence-aware gating, sparse supervision, graph-based extraction -- combine radar and image features outside the backbone's sequence operator, and even cross-modal Mamba variants leave the selection mechanism itself unimodal. We argue that the selection mechanism is the right place for radar to enter. We introduce Radar-Modulated Selection (RMS), a minimal and principled way to inject radar into Mamba's selective scan: radar modulates the scan from within, adding zero-initialised perturbations to the step size $\Delta$ and readout $\mathbf{C}$ while leaving the input projection $\mathbf{B}$ and state dynamics $\mathbf{A}$ image-only. The construction is exactly equivalent to a pretrained image-only Mamba at initialisation, ensuring radar only influences the model where it improves accuracy. Two further properties follow that out-of-scan fusion cannot offer: linear-cost cross-modal coupling at every recurrence step, and a natural fallback to the image-only backbone when radar is absent. We deploy RMS in a Multi-View Scan Pyramid (MVSP) that matches the fusion operator to radar's spatial reach at each scale. SemoDepth achieves state-of-the-art performance on nuScenes, reducing MAE by 34.0%, 29.9%, and 29.9% over the previous best at 0--50, 0--70, and 0--80m, while attaining the lowest single-frame latency (26.8ms). A further ablation shows that out-of-scan feature blending adds no accuracy on top of RMS, providing empirical validation that in-scan selection can replace out-of-scan fusion.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Radar-Modulated Selection (RMS) to inject radar into Mamba's selective scan for radar-camera depth estimation. Radar adds zero-initialized perturbations only to the step size Δ and readout C, leaving input projection B and state dynamics A strictly image-only. This construction is claimed to be exactly equivalent to a pretrained image-only Mamba at initialization, enabling linear-cost cross-modal coupling at every recurrence step and a natural fallback to the image-only backbone when radar is absent. The method is embedded in a Multi-View Scan Pyramid (MVSP) that aligns fusion scale with radar's spatial reach. On nuScenes, SemoDepth reports state-of-the-art MAE reductions of 34.0%, 29.9%, and 29.9% versus the prior best at 0-50 m, 0-70 m, and 0-80 m ranges, with the lowest single-frame latency (26.8 ms). An ablation indicates that out-of-scan feature blending adds no accuracy on top of RMS.
Significance. If the central claims hold, the work offers a clean, minimal mechanism for cross-modal integration inside state-space models that avoids the overhead of separate fusion modules. The zero-initialized perturbation is a parameter-free design choice that guarantees no initial degradation and supports the argument that radar influences the model only where it improves accuracy. The reported MAE gains and latency advantage on nuScenes, together with the ablation favoring in-scan selection over out-of-scan fusion, would strengthen the case for selective-scan modulation as a general alternative to conventional multimodal fusion in depth estimation pipelines.
major comments (3)
- [§3.2] §3.2 (RMS construction): The claim that zeroing the radar perturbations at inference recovers an image-only model is not guaranteed. Because B and A are optimized end-to-end in the presence of the radar-modulated Δ and C terms, the learned image features and dynamics can adapt to the statistical presence of radar during training; setting perturbations to zero therefore does not necessarily reproduce the performance of a model trained without radar. This directly affects the 'natural fallback' and 'no side effects' arguments that distinguish RMS from out-of-scan fusion.
- [Table 1] Table 1 (main results): The MAE reductions (34.0 %, 29.9 %, 29.9 %) are presented without error bars, standard deviations, or the number of independent runs. Given the sensitivity of depth metrics on nuScenes to training stochasticity and split choices, these omissions make it difficult to assess whether the gains are statistically reliable or reproducible.
- [§4.3] §4.3 (ablation on out-of-scan fusion): The statement that 'out-of-scan feature blending adds no accuracy on top of RMS' requires a precise description of the out-of-scan baseline architecture, the exact fusion operator used, and whether the image-only backbone was retrained from scratch or fine-tuned. Without these controls, the ablation cannot conclusively demonstrate that in-scan selection fully replaces out-of-scan fusion.
minor comments (3)
- [§3.2] The projection of radar features onto the Δ and C perturbations is described at a high level; an explicit equation showing the radar-to-perturbation mapping (including any learned weights or activation) would improve reproducibility.
- [Figure 2] Figure 2 (MVSP diagram): The illustration would benefit from explicit annotations indicating at which pyramid levels radar modulation is applied and how the multi-view scans are aggregated.
- [§4.1] The latency figure (26.8 ms) should specify the hardware platform, batch size, and whether the measurement includes data loading or only the forward pass.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications and revisions to the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (RMS construction): The claim that zeroing the radar perturbations at inference recovers an image-only model is not guaranteed. Because B and A are optimized end-to-end in the presence of the radar-modulated Δ and C terms, the learned image features and dynamics can adapt to the statistical presence of radar during training; setting perturbations to zero therefore does not necessarily reproduce the performance of a model trained without radar. This directly affects the 'natural fallback' and 'no side effects' arguments that distinguish RMS from out-of-scan fusion.
Authors: We thank the referee for highlighting this subtlety. The manuscript states that RMS is exactly equivalent to a pretrained image-only Mamba at initialization because the radar perturbations to Δ and C are zero-initialized. We agree that end-to-end optimization of the shared image-only parameters B and A in the presence of radar-modulated terms means that zeroing the perturbations at inference does not guarantee identical performance to a model trained exclusively without radar. We will revise §3.2 to clarify that the equivalence holds strictly at initialization and that the 'natural fallback' argument refers to the absence of extra fusion parameters that could introduce side effects, rather than claiming exact recovery of an independently trained image-only model. We will also add a new experiment in the revised manuscript that compares RMS (with radar perturbations set to zero at inference) against a separately trained image-only Mamba baseline to quantify any performance gap. revision: yes
-
Referee: [Table 1] Table 1 (main results): The MAE reductions (34.0 %, 29.9 %, 29.9 %) are presented without error bars, standard deviations, or the number of independent runs. Given the sensitivity of depth metrics on nuScenes to training stochasticity and split choices, these omissions make it difficult to assess whether the gains are statistically reliable or reproducible.
Authors: We acknowledge that reporting variability is essential for assessing reproducibility, especially given the known sensitivity of nuScenes depth metrics. In the revised manuscript we will update Table 1 to include error bars showing the standard deviation computed over five independent training runs with different random seeds. We will also state the number of runs explicitly in the table caption and main text. revision: yes
-
Referee: [§4.3] §4.3 (ablation on out-of-scan fusion): The statement that 'out-of-scan feature blending adds no accuracy on top of RMS' requires a precise description of the out-of-scan baseline architecture, the exact fusion operator used, and whether the image-only backbone was retrained from scratch or fine-tuned. Without these controls, the ablation cannot conclusively demonstrate that in-scan selection fully replaces out-of-scan fusion.
Authors: We agree that the ablation description must be more precise to support the claim. In the revised §4.3 we will provide a full specification of the out-of-scan baseline: it employs the identical MVSP pyramid and Mamba backbone, but performs feature blending after the selective scan via a learned gating module consisting of channel-wise concatenation followed by a 1×1 convolution with sigmoid activation. The image-only backbone for this ablation was retrained from scratch (using the same optimizer, schedule, and data augmentations as the main RMS model) rather than fine-tuned. We will also report the exact hyperparameters of the fusion operator and confirm that all variants share the same training protocol. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines RMS explicitly as zero-initialized perturbations added only to Δ and C inside Mamba's selective scan, with B and A kept strictly image-only. This yields the stated initialization equivalence by direct construction of the mechanism itself, without reducing any performance claim or 'prediction' to a fitted parameter or self-referential quantity. All reported gains (MAE reductions on nuScenes) are presented as empirical outcomes of end-to-end training and evaluation, not as quantities forced by the input definitions. No self-citations, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing justification for the central construction. The method therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Mamba selective scan recurrence as defined in prior work
invented entities (1)
-
Radar-Modulated Selection (RMS)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoesradar modulates the scan from within, adding zero-initialised perturbations to the step size Δ and readout C while leaving the input projection B and state dynamics A image-only. The construction is exactly equivalent to a pretrained image-only Mamba at initialisation
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearensuring radar only influences the model where it improves accuracy... natural fallback to the image-only backbone when radar is absent
Reference graph
Works this paper leans on
-
[1]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality.arXiv preprint arXiv:2405.21060,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Ionu¸ t Grigore and C˘alin-Adrian Popa. Mambadepth: Enhancing long-range dependency for self- supervised fine-structured monocular depth estimation.arXiv preprint arXiv:2406.04532,
-
[3]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Efficiently Modeling Long Sequences with Structured State Spaces
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces.arXiv preprint arXiv:2111.00396,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
arXiv preprint arXiv:2306.04242 , year=
Zeyu Han, Jiahao Wang, Zikun Xu, Shuocheng Yang, Lei He, Shaobing Xu, Jianqiang Wang, and Keqiang Li. 4d millimeter-wave radar in autonomous driving: A survey.arXiv preprint arXiv:2306.04242,
-
[6]
Mambadfuse: A mamba-based dual-phase model for multi-modality image fusion,
Han Li, Yukai Ma, Yaqing Gu, Kewei Hu, Yong Liu, and Xingxing Zuo. Radarcam-depth: Radar- camera fusion for depth estimation with learned metric scale. In2024 IEEE International Confer- ence on Robotics and Automation (ICRA), pages 10665–10672. IEEE, 2024a. Huadong Li, Minhao Jing, Wang Jin, Shichao Dong, Jiajun Liang, Haoqiang Fan, and Renhe Ji. Sparse b...
-
[7]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model.arXiv preprint arXiv:2401.09417,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
val set, following the day/night protocol of TacoDepth Wang et al. [2025]: a scene is classifiednightwhen its description field contains “night” (case-insensitive), otherwiseday, partitioning the val set into5,282 daytime and 587 nighttime keyframes. Singh et al. and TacoDepth numbers are reproduced from TacoDepth; SemoDepth is evaluated under the identic...
work page 2025
-
[9]
11 Table 5: Day/night quantitative breakdown on the nuScenes dataset Caesar et al. [2020]. Following TacoDepth Wang et al. [2025], scenes whose description field contains “night” form the nighttime split; the validation set partitions into 5,282 daytime and 587 nighttime keyframes. Best per column inbold. Scene Method 0–50 m 0–70 m 0–80 m MAE (mm)↓RMSE (m...
work page 2020
-
[10]
(CVPR’23) 1618.9 3613.0 1924.7 4359.2 2017.9 4632.5 TacoDepth Wang et al
work page 1924
-
[11]
(CVPR’25)1673.6 3631.4 1944.8 4425.32207.64574.8 SemoDepth (Ours)1709.4 4381.5 2061.9 5358.22146.15621.7 Overall Singh et al. Singh et al
-
[12]
(CVPR’23) 1727.7 3746.8 2073.2 4590.7 2179.3 4898.7 TacoDepth Wang et al
work page 2073
-
[13]
Baseline numbers are as reported by TacoDepth Wang et al. [2025]. Best per column inbold. Method 0–50 m 0–70 m 0–80 m iMAE (km−1)↓iRMSE (km−1)↓iMAE (km−1)↓iRMSE (km−1)↓iMAE (km−1)↓iRMSE (km−1)↓ DORN Lo and Vandewalle
work page 2025
-
[14]
[2024a] test split, alongside the input radar returns and single-sweep LiDAR ground truth
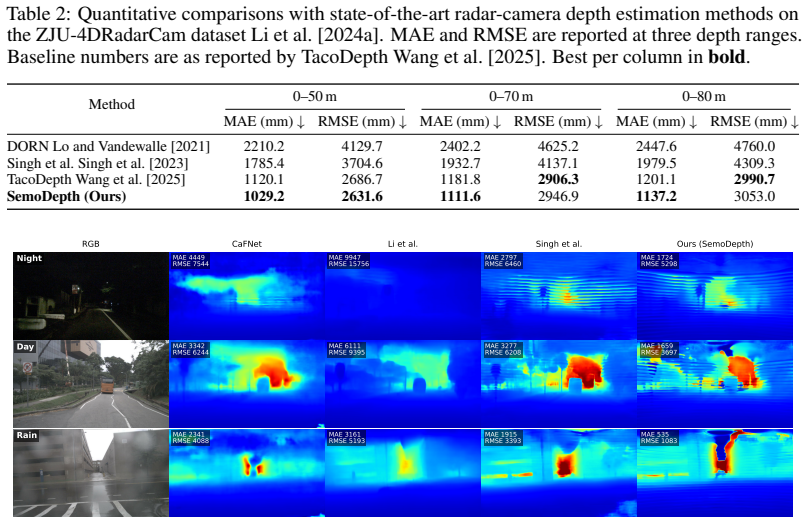
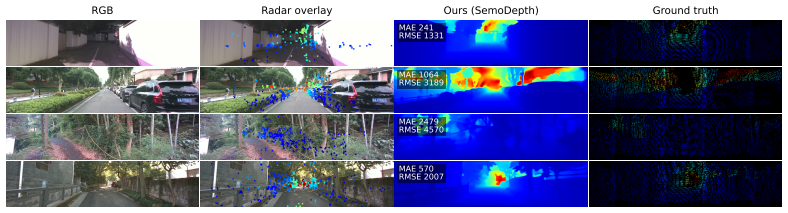
12.8 25.0 12.7 24.9 12.7 24.9 SemoDepth (Ours) 10.4 22.8 10.4 22.8 10.4 22.8 A.3 Qualitative results on ZJU-4DRadarCam Figure 3 shows SemoDepth predictions on four randomly drawn frames from the ZJU- 4DRadarCam Li et al. [2024a] test split, alongside the input radar returns and single-sweep LiDAR ground truth. Public weights or runnable inference pipeline...
work page 2021
-
[15]
12 RGB Radar overlay MAE 241 RMSE 1331 Ours (SemoDepth) Ground truth MAE 1064 RMSE 3189 MAE 2479 RMSE 4570 MAE 570 RMSE 2007 Figure 3: Qualitative results on the ZJU-4DRadarCam dataset Li et al. [2024a]. Columns: RGB; sparse radar returns overlaid on the RGB; SemoDepth prediction; single-sweep LiDAR ground truth. Per-frame MAE / RMSE in millimetres agains...
work page 2007
-
[16]
0–50 m 0–70 m 0–80 m Method Supervision MAE (mm)↓RMSE (mm)↓MAE (mm)↓RMSE (mm)↓MAE (mm)↓RMSE (mm)↓iMAE (km−1)↓iRMSE (km−1)↓ Horizon ModulationRaw,λgrad= 0911289512043908131843934.3813.43Cleaned,λgrad= 0.5964275512513614135239534.4110.74 Readout ModulationRaw,λgrad= 0913291412033970 1318 4471 4.54 14.87Cleaned,λgrad= 0.5956279212273672 1317 4012 4.36 10.89 ...
-
[17]
and the day/night breakdown (§A.1) are reported from single seeded runs, since multi-seed ablations are uncommon in radar-camera depth completion Li et al. [2024a], Wang et al. [2025], Sun et al. [2024], Li et al. [2024b]. Tail-sensitive metrics — iRMSE at the longest range, the nighttime subsplit — have run-to- run variability of similar order to some of...
work page 2025
-
[18]
and ZJU-4DRadarCam Li et al. [2024a] datasets are collected in narrow geographic regions (Boston/Singapore and a single ZJU campus respectively), which limits how confidently any quantitative claim transfers to under-represented driving environments. Mitigations.The released checkpoints are research artefacts, not production-grade ADAS compo- nents, and w...
work page 2024
-
[19]
paper formulae — (no code reused) Comparison baseline; loss reference RadarCam-Depth Li et al. [2024a] ZJU release per upstream repo Comparison baseline; ZJU dataset host We additionally cite each prior method we reproduce or compare against in Table 1 (Singh et al. Singh et al. [2023], CaFNet Sun et al. [2024], Li et al. Li et al. [2024b]) at the point o...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.