Recognition: 2 theorem links
· Lean TheoremMartingale-Consistent Self-Supervised Learning
Pith reviewed 2026-05-13 06:46 UTC · model grok-4.3
The pith
A martingale consistency constraint makes self-supervised predictions match their expected value after refinement.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a martingale-consistent SSL framework that closes the gap between invariance-based training and the requirement that coarse-view predictions equal the expected refined-view predictions, using practical prediction- and latent-space objectives together with an unbiased two-sample Monte Carlo estimator based on stochastic refinement, and demonstrate improved robustness and calibration under partial observation on synthetic and real benchmarks.
What carries the argument
Martingale consistency constraint (the requirement that the prediction from a coarse view equals the expected prediction from any refined view), enforced via auxiliary objectives in prediction space or latent space.
If this is right
- Predictions can update as more data arrives without systematic drift across time-series, tabular, and image tasks.
- Representations remain stable and better calibrated when only partial information is observed at inference time.
- The same framework applies in both semi-supervised and fully unsupervised regimes.
- An unbiased Monte Carlo estimator allows the constraint to be trained without extra bias from sampling refinements.
Where Pith is reading between the lines
- The approach may extend naturally to streaming or online settings where new features arrive sequentially.
- It could be combined with existing contrastive losses to add coherence without replacing invariance entirely.
- Testing on modalities with natural refinement order, such as progressive image super-resolution or multi-resolution sensor data, would be a direct next step.
Load-bearing premise
That adding the martingale consistency objectives will produce representations that remain at least as useful as ordinary SSL when full information is present while gaining stability under partial views.
What would settle it
A head-to-head comparison on the paper's partial-observation benchmarks in which standard contrastive or reconstruction SSL achieves equal or superior calibration error and robustness metrics to the martingale-consistent version.
Figures






read the original abstract
Self-supervised learning (SSL) is often deployed under changing information, such as shorter histories, missing features, or partially observed images. In these settings, predictions from coarse and refined views should be coherent: before refinement, the coarse-view prediction should match the average prediction expected after refinement. Martingales formalize this coherence principle, but standard SSL objectives do not enforce it. Unlike invariance objectives that pull views together, martingale consistency constrains only the expected refined prediction, allowing predictions to update as information is revealed while preventing systematic drift. We introduce a martingale-consistent SSL framework that closes this gap, with practical prediction- and latent-space variants and an unbiased two-sample Monte Carlo estimator based on stochastic refinement. We evaluate the approach on synthetic and real time-series, tabular, and image benchmarks under partial-observation regimes, in both semi-self-supervised and fully label-free settings. Across these experiments, our framework improves robustness and calibration under partial observation, yielding more stable representations as information is revealed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a martingale-consistent self-supervised learning framework to enforce coherence between predictions from coarse and refined views in partial-observation settings. It introduces prediction-space and latent-space objectives together with an unbiased two-sample Monte Carlo estimator based on stochastic refinement, and reports empirical gains in robustness and calibration on synthetic and real time-series, tabular, and image benchmarks under both semi-supervised and fully label-free regimes.
Significance. If the central empirical claim holds, the work supplies a principled, non-invariance-based constraint for SSL under evolving information, which could improve stability in applications such as sequential decision-making and partial-image recognition without requiring additional labels. The explicit grounding in martingale theory and the provision of a practical estimator are strengths that distinguish the approach from standard contrastive or reconstruction objectives.
major comments (2)
- [Experiments] Experiments section: the reported gains are confined to partial-observation regimes; the manuscript does not present head-to-head results against standard SSL baselines on fully observed inputs, leaving the claim that the martingale constraints preserve (or do not degrade) performance when complete information is available unverified.
- [§3] §3 (method): the unbiasedness of the two-sample Monte Carlo estimator is asserted but the variance analysis and the precise stochastic refinement procedure are not detailed enough to confirm that the estimator remains low-variance across the reported benchmarks.
minor comments (2)
- [§3] Notation: the distinction between the prediction-space and latent-space martingale objectives should be made explicit in a single equation block rather than scattered across paragraphs.
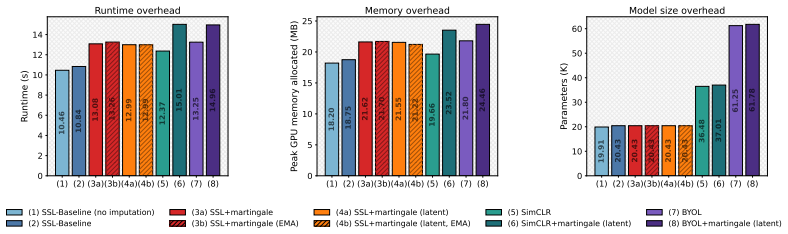
- [Figures] Figure captions: several plots lack error bars or mention of the number of random seeds, making it difficult to assess the statistical reliability of the reported improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions we will incorporate to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported gains are confined to partial-observation regimes; the manuscript does not present head-to-head results against standard SSL baselines on fully observed inputs, leaving the claim that the martingale constraints preserve (or do not degrade) performance when complete information is available unverified.
Authors: We agree that explicit verification on fully observed inputs is important to confirm that the martingale constraints do not degrade performance when no refinement occurs. In the revised manuscript we will add head-to-head comparisons against standard SSL baselines on the fully observed versions of the synthetic, time-series, tabular, and image benchmarks. These new results will demonstrate that our objectives remain competitive (or equivalent) in the complete-information regime, as predicted by the theory that the martingale term becomes inactive when the coarse and refined views coincide. revision: yes
-
Referee: [§3] §3 (method): the unbiasedness of the two-sample Monte Carlo estimator is asserted but the variance analysis and the precise stochastic refinement procedure are not detailed enough to confirm that the estimator remains low-variance across the reported benchmarks.
Authors: We acknowledge that §3 would benefit from greater technical detail on the estimator. In the revision we will expand this section to include: (i) a self-contained proof of unbiasedness for the two-sample Monte Carlo estimator, (ii) a variance bound that depends on the stochastic refinement distribution and shows the estimator remains low-variance under the hyper-parameters used in the experiments, and (iii) a precise algorithmic description (including pseudocode) of the stochastic refinement procedure. These additions will allow readers to directly verify the estimator’s properties on the reported benchmarks. revision: yes
Circularity Check
No circularity: martingale constraint imported from external probability theory; new objectives do not reduce to fitted inputs
full rationale
The derivation begins from the standard definition of a martingale (external to the paper) and introduces two new loss terms (prediction-space and latent-space) plus a Monte Carlo estimator. No equation equates a claimed prediction to a parameter fitted on the same data by construction, no self-citation supplies a uniqueness theorem that forces the framework, and the empirical claims rest on benchmark comparisons rather than internal re-labeling of fitted quantities. The central claim therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The prediction process under successive refinements satisfies the martingale property (current prediction equals expected future prediction).
Reference graph
Works this paper leans on
-
[1]
D. Anguita, A. Ghio, L. Oneto, X. Parra, and J. Reyes. A public domain dataset for human activity recognition using smartphones. InProceedings of the 21th International European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, page 437–442, Bruges, 2013. ISBN 978-2-87419-081-0. URLhttps://hdl.handle.net/2117/20897
work page 2013
-
[2]
In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), pp
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint-embedding predictive architecture. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 15619–15629. IEEE, 2023. doi: 10.1109/cvpr52729.2023.01499. URL...
-
[3]
Scarf: Self-supervised contrastive learning using random feature corruption
Dara Bahri, Heinrich Jiang, Yi Tay, and Donald Metzler. Scarf: Self-supervised contrastive learning using random feature corruption. InInternational Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=CuV_qYkmKb3
work page 2022
-
[4]
VICReg: Variance-invariance-covariance regularization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. VICReg: Variance-invariance-covariance regularization for self-supervised learning. InInternational Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=xm6YD62D1Ub
work page 2022
-
[5]
Barry Becker and Ronny Kohavi. Adult, 1996. URLhttps://archive.ics.uci.edu/dataset/2
work page 1996
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In Hal Daumé III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 1597–1607. PMLR, 13–18 Jul 2020
work page 2020
-
[7]
An analysis of single-layer networks in unsupervised feature learning
Adam Coates, Andrew Ng, and Honglak Lee. An analysis of single-layer networks in unsupervised feature learning. In Geoffrey Gordon, David Dunson, and Miroslav Dudík, editors,Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 215–223, Fort Lauderdale,...
work page 2011
-
[8]
Marco Cuturi. Fast global alignment kernels. In Lise Getoor and Tobias Scheffer, editors,Proceedings of the 28th International Conference on Machine Learning (ICML-11), ICML ’11, pages 929–936, New York, NY , USA, June 2011. ACM. ISBN 978-1-4503-0619-5
work page 2011
-
[9]
Simmtm: A simple pre-training framework for masked time-series modeling
Jiaxiang Dong, Haixu Wu, Haoran Zhang, Li Zhang, Jianmin Wang, and Mingsheng Long. Simmtm: A simple pre-training framework for masked time-series modeling. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Ad- vances in Neural Information Processing Systems, volume 36, pages 29996–30025. Curran Asso- ciates, Inc., 2023. URL h...
work page 2023
-
[10]
Bootstrap your own latent - a new approach to self- supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, koray kavukcuoglu, Remi Munos, and Michal Valko. Bootstrap your own latent - a new approach to self- supervised learning. In H. Larochelle, M. Ranzato, R. Hadsell, M...
work page 2020
-
[11]
Penalized discriminant analysis.The Annals of Statistics, 23(1), February 1995
Trevor Hastie, Andreas Buja, and Robert Tibshirani. Penalized discriminant analysis.The Annals of Statistics, 23(1), February 1995. ISSN 0090-5364. doi: 10.1214/aos/1176324456. URL http: //dx.doi.org/10.1214/aos/1176324456
-
[12]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), page 770–778. IEEE,
-
[13]
Deep Residual Learning for Image Recognition , url =
doi: 10.1109/cvpr.2016.90. URLhttp://dx.doi.org/10.1109/CVPR.2016.90. 10
-
[14]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, and Ross Girshick. Masked autoencoders are scalable vision learners. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), page 15979–15988. IEEE, 2022. doi: 10.1109/cvpr52688.2022.01553. URL http://dx.doi. org/10.1109/CVPR52688.2022.01553
-
[15]
Statlog (german credit data), 1994
Hans Hofmann. Statlog (german credit data), 1994. URL https://archive.ics.uci.edu/dataset/ 144
work page 1994
-
[16]
Learning multiple layers of features from tiny images
Alex Krizhevsky and Geoffrey Hinton. Learning multiple layers of features from tiny images. Technical Report 0, University of Toronto, Toronto, Ontario, 2009. URL https://www.cs.toronto.edu/~kriz/ learning-features-2009-TR.pdf
work page 2009
-
[17]
Ti-mae: Self-supervised masked time series autoencoders, 2023
Zhe Li, Zhongwen Rao, Lujia Pan, Pengyun Wang, and Zenglin Xu. Ti-mae: Self-supervised masked time series autoencoders, 2023. URLhttps://arxiv.org/abs/2301.08871
-
[18]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. URLhttps://openreview.net/forum?id=Bkg6RiCqY7
work page 2019
-
[19]
Sérgio Moro, Paulo Cortez, and Paulo Rita. A data-driven approach to predict the success of bank telemarketing.Decision Support Systems, 62:22–31, 2014. ISSN 0167-9236. doi: 10.1016/j.dss.2014.03
-
[20]
URLhttp://dx.doi.org/10.1016/j.dss.2014.03.001
-
[21]
Nacereddine Hammami Mouldi Bedda. Spoken arabic digit, 2008. URL https://archive.ics.uci. edu/dataset/195
work page 2008
-
[22]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding, 2018. URLhttps://arxiv.org/abs/1807.03748
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[23]
Sebastian Pölsterl. scikit-survival: A library for time-to-event analysis built on top of scikit-learn.Journal of Machine Learning Research, 21(212):1–6, 2020. URL http://jmlr.org/papers/v21/20-729.html
work page 2020
-
[24]
Subtab: Subsetting features of tabular data for self-supervised representation learning
Talip Ucar, Ehsan Hajiramezanali, and Lindsay Edwards. Subtab: Subsetting features of tabular data for self-supervised representation learning. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 18853–18865. Curran Associates, Inc., 2021. URL https://p...
work page 2021
-
[25]
Tobias Uelwer, Jan Robine, Stefan Sylvius Wagner, Marc Höftmann, Eric Upschulte, Sebastian Konietzny, Maike Behrendt, and Stefan Harmeling. A survey on self-supervised methods for visual representation learning.Machine Learning, 114(4), March 2025. ISSN 1573-0565. doi: 10.1007/s10994-024-06708-7. URLhttp://dx.doi.org/10.1007/s10994-024-06708-7
-
[26]
Williams, Marc Toussaint, and Amos J
Ben H. Williams, Marc Toussaint, and Amos J. Storkey. Extracting motion primitives from natural handwriting data. In Stefanos Kollias, Andreas Stafylopatis, Włodzisław Duch, and Erkki Oja, editors, Artificial Neural Networks – ICANN 2006, pages 634–643, Berlin, Heidelberg, 2006. Springer Berlin Heidelberg. ISBN 978-3-540-38873-9
work page 2006
-
[27]
Cambridge University Press, 1991
David Williams.Probability with Martingales. Cambridge University Press, 1991
work page 1991
-
[28]
Mind: Multimodal integration with neighbourhood-aware distributions
Hanwen Xing and Christopher Yau. Mind: Multimodal integration with neighbourhood-aware distributions
-
[29]
URLhttp://dx.doi.org/10.1101/2025.09.15.676314
doi: 10.1101/2025.09.15.676314. URLhttp://dx.doi.org/10.1101/2025.09.15.676314
-
[30]
Vime: Extending the success of self- and semi-supervised learning to tabular domain
Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar. Vime: Extending the success of self- and semi-supervised learning to tabular domain. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 11033–11043. Curran Associates, Inc., 2020. URL https://procee...
work page 2020
-
[31]
Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. Ts2vec: Towards universal representation of time series.Proceedings of the AAAI Conference on Artificial Intelligence, 36(8):8980–8987, 2022. ISSN 2159-5399. doi: 10.1609/aaai.v36i8.20881. URL http://dx.doi.org/10.1609/AAAI.V36I8.20881. 11 Appendix A Impact ...
-
[32]
The two candidate estimators are the naive single-sample plug-in bLsingle :=∥u−v a∥2 2 ,(17) and the two-independent-sample construction bLtwo := (u−v a)⊤ (u−v b),(18) where va, vb are conditionally independent refinement samples. We train two model families on S-SIM—one with each estimator—and evaluate each frozen model with its native estimator; the dia...
-
[33]
backbone. We write the resulting coarse and refined representations generically as zF1 :=f θ(X⊙M), z F2 :=f θ(X),(26) with temporal and tabular models implemented using a mask-aware encoder, while for images the mask is applied to the pixels before the encoder is called. Base framework.The core benchmark families use two objective types. In the reconstruc...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.