Recognition: 2 theorem links
· Lean TheoremConstrained Stochastic Spectral Preconditioning Converges for Nonconvex Objectives
Pith reviewed 2026-05-13 05:25 UTC · model grok-4.3
The pith
Proximal spectral gradient methods converge for nonconvex constrained problems under heavy-tailed noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
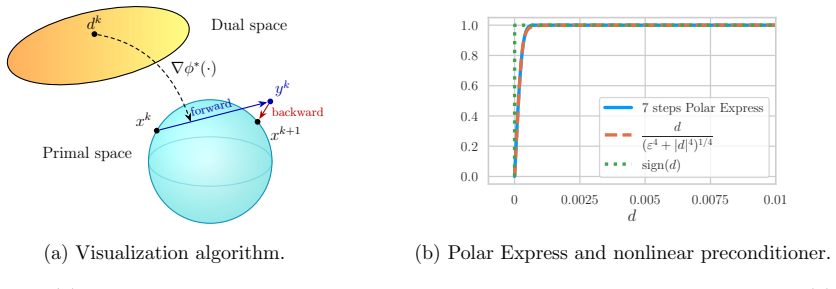
We develop proximal preconditioned gradient methods with a focus on spectral gradient methods providing a proximal extension to the Muon and Scion optimizers. We introduce a family of stochastic algorithms that can handle a wide variety of convex and nonconvex constraints and study its convergence under heavy-tailed noise, through a novel analysis tailored to the geometry of the proposed methods. We further propose a variance-reduced version, which achieves faster convergence under standard noise assumptions. Finally, we show that the polynomial iterations used in Muon are more accurately captured by a nonlinear preconditioner than by the ideal matrix sign, leading to a convergence analysis.
What carries the argument
Proximal spectral preconditioning, which applies a spectral transformation to the gradient before taking a proximal step to enforce constraints while preserving the geometry needed for the convergence bounds.
If this is right
- Stochastic optimization over nonconvex constraint sets now has provable convergence guarantees.
- The methods remain stable when gradient estimates contain heavy tails, which occur in many practical sampling schemes.
- Variance reduction yields strictly faster convergence rates while retaining the same proximal structure.
- Practical polynomial implementations of spectral steps align with the nonlinear preconditioner model rather than the ideal sign function.
Where Pith is reading between the lines
- The geometric analysis may transfer to other preconditioned proximal methods that share similar update structures.
- These algorithms could be tested on constrained deep-learning tasks such as training with hard architectural constraints.
- Extensions to adaptive spectral preconditioners or different noise models remain open but follow the same geometric template.
Load-bearing premise
The geometry-tailored bounds hold only when the heavy-tailed noise and proximal mapping satisfy particular regularity conditions that close the analysis.
What would settle it
Running the algorithm on a simple nonconvex constrained problem with explicitly heavy-tailed stochastic gradients and observing failure to converge to a stationary point would disprove the claimed convergence result.
Figures





read the original abstract
In this work, we develop proximal preconditioned gradient methods with a focus on spectral gradient methods providing a proximal extension to the Muon and Scion optimizers. We introduce a family of stochastic algorithms that can handle a wide variety of convex and nonconvex constraints and study its convergence under heavy-tailed noise, through a novel analysis tailored to the geometry of the proposed methods. We further propose a variance-reduced version, which achieves faster convergence under standard noise assumptions. Finally, we show that the polynomial iterations used in Muon are more accurately captured by a nonlinear preconditioner than by the ideal matrix sign, leading to a convergence analysis that more faithfully reflects practical implementations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops proximal extensions of spectral preconditioned gradient methods (as proximal versions of Muon and Scion) for stochastic optimization. It introduces a family of algorithms that accommodate convex and nonconvex constraints, establishes convergence under heavy-tailed noise via a novel geometry-tailored analysis, proposes a variance-reduced variant achieving faster rates under standard noise, and argues that nonlinear preconditioners more faithfully model the polynomial iterations used in Muon than the matrix sign function.
Significance. If the stated convergence results hold with the claimed generality, the work would be a useful contribution to constrained nonconvex stochastic optimization, particularly for settings with heavy-tailed noise common in machine learning. The geometry-aware analysis and the practical observation on Muon modeling are potentially valuable; the variance-reduced extension is a standard but welcome addition. The overall significance is moderate and depends on whether the novel analysis closes without hidden restrictions on the constraint sets.
major comments (1)
- [§4] §4 (Convergence Analysis under Heavy-Tailed Noise), the descent inequality leading to Theorem 4.1: the argument absorbs heavy-tail moments by treating the proximal step as approximately non-expansive (or using a local curvature control derived from the preconditioner geometry). This property does not hold for arbitrary nonconvex constraint sets, where the proximal mapping can expand distances locally (e.g., indicator functions of nonconvex varieties). The claim of applicability to a 'wide variety of ... nonconvex constraints' is therefore load-bearing and requires either an explicit additional assumption (local convexity or bounded prox-Lipschitz constant) or a revised bound that does not rely on non-expansiveness.
minor comments (2)
- [Abstract] Abstract: the phrase 'novel analysis tailored to the geometry' is repeated without a one-sentence pointer to the key technical device (e.g., a specific inequality or Lyapunov function) that distinguishes it from standard prox-gradient analyses.
- [Notation] Notation section: the definition of the spectral preconditioner (likely Eq. (3) or (5)) should explicitly state whether it is applied before or after the proximal mapping, as this affects the interpretation of the 'nonlinear preconditioner' claim for Muon.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The single major comment raises an important point about the scope of the convergence analysis for nonconvex constraints, which we address directly below. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§4] §4 (Convergence Analysis under Heavy-Tailed Noise), the descent inequality leading to Theorem 4.1: the argument absorbs heavy-tail moments by treating the proximal step as approximately non-expansive (or using a local curvature control derived from the preconditioner geometry). This property does not hold for arbitrary nonconvex constraint sets, where the proximal mapping can expand distances locally (e.g., indicator functions of nonconvex varieties). The claim of applicability to a 'wide variety of ... nonconvex constraints' is therefore load-bearing and requires either an explicit additional assumption (local convexity or bounded prox-Lipschitz constant) or a revised bound that does not rely on non-expansiveness.
Authors: We agree that the descent inequality in the proof of Theorem 4.1 relies on controlling the expansion of the proximal mapping, which the manuscript justifies through local curvature properties induced by the spectral preconditioner. However, this control is not automatic for completely arbitrary nonconvex sets, as the referee correctly notes. To resolve the issue without weakening the heavy-tailed noise result, we will introduce an explicit additional assumption (new Assumption 4.3 in the revised version) requiring that the proximal operator satisfies a bounded prox-Lipschitz constant relative to the preconditioner geometry. This assumption is satisfied by the constraint sets used in the numerical experiments and by many practical nonconvex constraints (e.g., those with bounded curvature or when the preconditioner dominates local expansion). We will also add a short discussion clarifying the class of constraints for which the assumption holds, update the statement of Theorem 4.1 to reference the new assumption, and revise the proof to make the dependence explicit. No change is needed to the variance-reduced analysis or the Muon modeling section. revision: yes
Circularity Check
No circularity: novel analysis and preconditioner claims remain independent of fitted inputs or self-referential definitions
full rationale
The provided abstract and context describe a family of proximal preconditioned gradient methods with a novel geometry-tailored convergence analysis under heavy-tailed noise, plus a variance-reduced variant and a comparison of polynomial iterations to nonlinear preconditioners. No equations, parameter fits, or derivation steps are exhibited that reduce a claimed prediction or uniqueness result to a definition or self-citation by construction. The 'tailored to the geometry' phrasing does not, on the given text, equate the analysis bounds to quantities defined solely via the preconditioner itself; the central claims retain independent content from the method proposal and external noise assumptions. This is the expected honest non-finding for an abstract-level description lacking load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
proximal preconditioned gradient methods... nonlinear preconditioner ∇ϕ*... anisotropic proximal mapping... gap Dϕ*(∇f(xk),−e∇g(xk))
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
reference function ϕ... strongly convex... even... ϕ(0)=0... domϕ bounded
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Dion: Distributed orthonormalized updates.arXiv preprint arXiv:2504.05295, 2025
K. Ahn, B. Xu, N. Abreu, Y. Fan, G. Magakyan, P. Sharma, Z. Zhan, and J. Langford. “Dion: Distributed orthonormalized updates”. In:arXiv preprint arXiv:2504.05295(2025)
-
[2]
The Polar Express: Optimal Matrix Sign Methods and Their Application to the Muon Algorithm
N. Amsel, D. Persson, C. Musco, and R. M. Gower. “The Polar Express: Optimal matrix sign methods and their application to the Muon algorithm”. In:arXiv preprint arXiv:2505.16932(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A descent lemma beyond Lipschitz gradient continuity: first-order methods revisited and applications
H. H. Bauschke, J. Bolte, and M. Teboulle. “A descent lemma beyond Lipschitz gradient continuity: first-order methods revisited and applications”. In:Mathematics of Operations Research42.2 (2017), pp. 330–348
work page 2017
-
[4]
H. H. Bauschke and P. L. Combettes.Convex analysis and monotone operator theory in Hilbert spaces. Springer, 2017
work page 2017
-
[5]
Beck.First-order methods in optimization
A. Beck.First-order methods in optimization. SIAM, 2017
work page 2017
-
[6]
signSGD: Com- pressed optimisation for non-convex problems
J. Bernstein, Y.-X. Wang, K. Azizzadenesheli, and A. Anandkumar. “signSGD: Com- pressed optimisation for non-convex problems”. In:International Conference on Machine Learning. 2018, pp. 560–569
work page 2018
-
[7]
R. Bhatia.Matrix Analysis. Springer Science & Business Media, 1997
work page 1997
-
[8]
Escaping saddle points without Lipschitz smoothness: the power of nonlinear preconditioning
A. Bodard and P. Patrinos. “Escaping saddle points without Lipschitz smoothness: the power of nonlinear preconditioning”. In:Advances in Neural Information Processing Systems. 2025, pp. 124173–124208
work page 2025
-
[9]
Preconditioned Spectral Descent for Deep Learning
D. Carlson, E. Collins, Y. -P. Hsieh, L. Carin, and V. Cevher. “Preconditioned Spectral Descent for Deep Learning”. In:Advances in Neural Information Processing Systems. 2015
work page 2015
-
[10]
F. L. Cesista, Y. Jiacheng, and K. Jordan.Squeezing 1-2% Efficiency Gains Out of Muon by Optimizing the Newton-Schulz coefficients. 2025.url: https://leloykun.github. io/ponder/muon-opt-coeffs/
work page 2025
-
[11]
Muon Optimizes Under Spectral Norm Constraints
L. Chen, J. Li, and Q. Liu. “Muon Optimizes Under Spectral Norm Constraints”. In: Transactions on Machine Learning Research(2026).issn: 2835-8856
work page 2026
-
[12]
Lion secretly solves constrained optimization: As Lyapunov predicts
L. Chen, B. Liu, K. Liang, and Q. Liu. “Lion secretly solves constrained optimization: As Lyapunov predicts”. In:arXiv preprint arXiv:2310.05898(2023)
-
[13]
Symbolic Discovery of Optimization Algorithms
X. Chen et al. “Symbolic Discovery of Optimization Algorithms”. In:Advances in Neural Information Processing Systems. 2023, pp. 49205–49233
work page 2023
-
[14]
Generalized-smooth nonconvex optimization is as efficient as smooth nonconvex optimization
Z. Chen, Y. Zhou, Y. Liang, and Z. Lu. “Generalized-smooth nonconvex optimization is as efficient as smooth nonconvex optimization”. In:International Conference on Machine Learning. 2023, pp. 5396–5427
work page 2023
-
[15]
Moreau’s decomposition in Banach spaces
P. L. Combettes and N. N. Reyes. “Moreau’s decomposition in Banach spaces”. In: Mathematical Programming139.1 (2013), pp. 103–114
work page 2013
-
[16]
High-probability Bounds for Non-Convex Stochastic Optimization with Heavy Tails
A. Cutkosky and H. Mehta. “High-probability Bounds for Non-Convex Stochastic Optimization with Heavy Tails”. In:Advances in Neural Information Processing Systems. 2021, pp. 4883–4895
work page 2021
-
[17]
Momentum improves normalized SGD
A. Cutkosky and H. Mehta. “Momentum improves normalized SGD”. In:International Conference on Machine Learning. 2020, pp. 2260–2268. 14
work page 2020
-
[18]
Momentum-Based Variance Reduction in Non-Convex SGD
A. Cutkosky and F. Orabona. “Momentum-Based Variance Reduction in Non-Convex SGD”. In:Advances in Neural Information Processing Systems. 2019
work page 2019
-
[19]
On Φ-Convexity in Extremal Problems
S. Dolecki and S. Kurcyusz. “On Φ-Convexity in Extremal Problems”. In:SIAM Journal on Control and Optimization16.2 (1978), pp. 277–300
work page 1978
-
[20]
Can SGD Handle Heavy-Tailed Noise?
I. Fatkhullin, F. H¨ ubler, and G. Lan. “Can SGD Handle Heavy-Tailed Noise?” In:arXiv preprint arXiv:2508.04860(2025)
-
[21]
E. Gorbunov, A. Sadiev, M. Danilova, S. Horv´ ath, G. Gidel, P. Dvurechensky, A. Gas- nikov, and P. Richt´ arik. “High-Probability Convergence for Composite and Distributed Stochastic Minimization and Variational Inequalities with Heavy-Tailed Noise”. In: International Conference on Machine Learning. 2024, pp. 15951–16070
work page 2024
-
[22]
Shampoo: Preconditioned stochastic tensor opti- mization
V. Gupta, T. Koren, and Y. Singer. “Shampoo: Preconditioned stochastic tensor opti- mization”. In:International Conference on Machine Learning. 2018, pp. 1842–1850
work page 2018
-
[23]
R. A. Horn and C. R. Johnson.Topics in matrix analysis. Cambridge university press, 1994
work page 1994
-
[24]
From Gradient Clipping to Normalization for Heavy Tailed SGD
F. H¨ ubler, I. Fatkhullin, and N. He. “From Gradient Clipping to Normalization for Heavy Tailed SGD”. In:The 28th International Conference on Artificial Intelligence and Statistics. 2025, pp. 2413–2421
work page 2025
-
[25]
D. Jakoveti´ c, D. Bajovi´ c, A. K. Sahu, S. Kar, N. Miloˇ sevi´ c, and D. Stamenkovi´ c. “Nonlinear gradient mappings and stochastic optimization: A general framework with applications to heavy-tail noise”. In:SIAM Journal on Optimization33.2 (2023), pp. 394– 423
work page 2023
- [26]
-
[27]
Analyzing and improving the training dynamics of diffusion models
T. Karras, M. Aittala, J. Lehtinen, J. Hellsten, T. Aila, and S. Laine. “Analyzing and improving the training dynamics of diffusion models”. In:Conference on Computer Vision and Pattern Recognition. 2024, pp. 24174–24184
work page 2024
-
[28]
Revisiting gradient clipping: Stochastic bias and tight convergence guarantees
A. Koloskova, H. Hendrikx, and S. U. Stich. “Revisiting gradient clipping: Stochastic bias and tight convergence guarantees”. In:International Conference on Machine Learning. 2023, pp. 17343–17363
work page 2023
-
[29]
N. Kornilov, P. Zmushko, A. Semenov, M. Ikonnikov, A. Gasnikov, and A. Beznosikov. “Sign Operator for Coping with Heavy-Tailed Noise in Non-Convex Optimization: High Probability Bounds Under ( L0, L1)-Smoothness”. In:arXiv preprint arXiv:2502.07923 (2025)
-
[30]
D. Kovalev. “Understanding gradient orthogonalization for deep learning via non- Euclidean trust-region optimization”. In:arXiv preprint arXiv:2503.12645(2025)
-
[31]
Krizhevsky et al.Learning multiple layers of features from tiny images
A. Krizhevsky et al.Learning multiple layers of features from tiny images. 2009
work page 2009
-
[32]
T. T.-K. Lau, Q. Long, and W. Su. “PolarGrad: A Class of Matrix-Gradient Optimizers from a Unifying Preconditioning Perspective”. In:arXiv preprint arXiv:2505.21799 (2025)
-
[33]
Lower envelopes and lifting for structured nonconvex optimization
E. Laude. “Lower envelopes and lifting for structured nonconvex optimization”. PhD thesis. Technical University of Munich, 2021. 15
work page 2021
-
[34]
E. Laude and P. Patrinos. “Anisotropic proximal gradient”. In:Mathematical Program- ming214 (2025), pp. 801–845
work page 2025
-
[35]
Dualities for non-Euclidean smoothness and strong convexity under the light of generalized conjugacy
E. Laude, A. Themelis, and P. Patrinos. “Dualities for non-Euclidean smoothness and strong convexity under the light of generalized conjugacy”. In:SIAM Journal on Optimization33.4 (2023), pp. 2721–2749
work page 2023
-
[36]
Optimization of inf-convolution regularized nonconvex composite problems
E. Laude, T. Wu, and D. Cremers. “Optimization of inf-convolution regularized nonconvex composite problems”. In:The 22nd International Conference on Artificial Intelligence and Statistics. 2019, pp. 547–556
work page 2019
-
[37]
The convex analysis of unitarily invariant matrix functions
A. S. Lewis. “The convex analysis of unitarily invariant matrix functions”. In:Journal of Convex Analysis2.1 (1995), pp. 173–183
work page 1995
-
[38]
Convex and Non-convex Optimization Under Generalized Smoothness
H. Li, J. Qian, Y. Tian, A. Rakhlin, and A. Jadbabaie. “Convex and Non-convex Optimization Under Generalized Smoothness”. In:Advances in Neural Information Processing Systems. 2023, pp. 40238–40271
work page 2023
-
[39]
Preconditioned stochastic gradient descent
X.-L. Li. “Preconditioned stochastic gradient descent”. In:IEEE transactions on neural networks and learning systems29.5 (2017), pp. 1454–1466
work page 2017
-
[40]
Communication Efficient Distributed Training with Distributed Lion
B. Liu, L. Wu, L. Chen, K. Liang, J. Zhu, C. Liang, R. Krishnamoorthi, and Q. Liu. “Communication Efficient Distributed Training with Distributed Lion”. In:Advances in Neural Information Processing Systems. 2024, pp. 18388–18415
work page 2024
-
[41]
Mars-m: When variance reduction meets matrices
Y. Liu, A. Yuan, and Q. Gu. “MARS-M: When variance reduction meets matrices”. In: arXiv preprint arXiv:2510.21800(2025)
-
[42]
Z. Liu and Z. Zhou. “Nonconvex stochastic optimization under heavy-tailed noises: Optimal convergence without gradient clipping”. In:arXiv preprint arXiv:2412.19529 (2024)
-
[43]
I. Loshchilov, C.-P. Hsieh, S. Sun, and B. Ginsburg. “nGPT: Normalized transformer with representation learning on the hypersphere”. In:arXiv preprint arXiv:2410.01131 (2024)
-
[44]
Dual space preconditioning for gradient descent
C. J. Maddison, D. Paulin, Y. W. Teh, and A. Doucet. “Dual space preconditioning for gradient descent”. In:SIAM Journal on Optimization31.1 (2021), pp. 991–1016
work page 2021
-
[45]
Spectral Normalization for Generative Adversarial Networks
T. Miyato, T. Kataoka, M. Koyama, and Y. Yoshida. “Spectral normalization for generative adversarial networks”. In:arXiv preprint arXiv:1802.05957(2018)
work page Pith review arXiv 2018
-
[46]
B. S. Mordukhovich.Variational Analysis and Generalized Differentiation I: Basic Theory. Vol. 330. Springer, 2006
work page 2006
-
[47]
Nesterov.Lectures on Convex Optimization
Y. Nesterov.Lectures on Convex Optimization. Springer, 2018
work page 2018
-
[48]
P., Cesista, F., Zahorodnii, A., Bernstein, J., and Isola, P
L. Newhouse, R. P. Hess, F. Cesista, A. Zahorodnii, J. Bernstein, and P. Isola. “Training transformers with enforced Lipschitz constants”. In:arXiv preprint arXiv:2507.13338 (2025)
-
[49]
Nonlinearly Preconditioned Gradient Methods under Generalized Smoothness
K. Oikonomidis, J. Quan, E. Laude, and P. Patrinos. “Nonlinearly Preconditioned Gradient Methods under Generalized Smoothness”. In:International Conference on Machine Learning. 2025, pp. 47132–47154
work page 2025
-
[50]
Nonlinearly Preconditioned Gradient Meth- ods: Momentum and Stochastic Analysis
K. Oikonomidis, J. Quan, and P. Patrinos. “Nonlinearly Preconditioned Gradient Meth- ods: Momentum and Stochastic Analysis”. In:Advances in Neural Information Processing Systems. 2025, pp. 38957–38988. 16
work page 2025
-
[51]
Training Deep Learning Models with Norm-Constrained LMOs
T. Pethick, W. Xie, K. Antonakopoulos, Z. Zhu, A. Silveti-Falls, and V. Cevher. “Training Deep Learning Models with Norm-Constrained LMOs”. In:International Conference on Machine Learning. 2025, pp. 49069–49104
work page 2025
-
[52]
Generalized Gradient Norm Clipping & Non-Euclidean ( L0, L1)-Smoothness
T. Pethick, W. Xie, M. Erdogan, K. Antonakopoulos, A. Silveti-Falls, and V. Cevher. “Generalized Gradient Norm Clipping & Non-Euclidean ( L0, L1)-Smoothness”. In:Ad- vances in Neural Information Processing Systems. 2025, pp. 21170–21208
work page 2025
-
[53]
Multidimensional probability inequalities via spherical symmetry
I. Pinelis. “Multidimensional probability inequalities via spherical symmetry”. In:arXiv preprint arXiv:2210.04391(2022)
-
[54]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra. “Grokking: Generalization beyond overfitting on small algorithmic datasets”. In:arXiv preprint arXiv:2201.02177 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[55]
Muon is provably faster with momentum variance reduction.arXiv preprint arXiv:2512.16598, 2025
X. Qian, H. Rammal, D. Kovalev, and P. Richtarik. “Muon is Provably Faster with Momentum Variance Reduction”. In:arXiv preprint arXiv:2512.16598(2025)
-
[56]
A. Riabinin, E. Shulgin, K. Gruntkowska, and P. Richt´ arik. “Gluon: Making Muon & Scion Great Again! (Bridging Theory and Practice of lmo-based Optimizers for LLMs)”. In:arXiv preprint arXiv:2505.13416(2025)
-
[57]
R. T. Rockafellar.Convex Analysis. Princeton University Press, 1970
work page 1970
-
[58]
R. T. Rockafellar and R. J. Wets.Variational Analysis. New York: Springer, 1998
work page 1998
-
[59]
Lions and muons: Optimization via stochastic frank- wolfe.arXiv preprint arXiv:2506.04192, 2025
M.-E. Sfyraki and J. -K. Wang. “Lions and Muons: Optimization via stochastic Frank– Wolfe”. In:arXiv preprint arXiv:2506.04192(2025)
-
[60]
S. Shalev-Shwartz and S. Ben-David.Understanding machine learning: From theory to algorithms. Cambridge university press, 2014
work page 2014
-
[61]
Beyond the ideal: Analyzing the inexact muon update.arXiv preprint arXiv:2510.19933, 2025
E. Shulgin, S. AlRashed, F. Orabona, and P. Richt´ arik. “Beyond the ideal: Analyzing the inexact Muon update”. In:arXiv preprint arXiv:2510.19933(2025)
-
[62]
Entropic proximal mappings with applications to nonlinear programming
M. Teboulle. “Entropic proximal mappings with applications to nonlinear programming”. In:Mathematics of Operations Research17.3 (1992), pp. 670–690
work page 1992
-
[63]
Toward a Unified Theory of Gradient Descent under Generalized Smooth- ness
A. Tyurin. “Toward a Unified Theory of Gradient Descent under Generalized Smooth- ness”. In:International Conference on Machine Learning. 2025, pp. 60493–60514
work page 2025
-
[64]
Optimizing ( L0, L1)- Smooth Functions by Gradient Methods
D. Vankov, A. Rodomanov, A. Nedich, L. Sankar, and S. U. Stich. “Optimizing ( L0, L1)- Smooth Functions by Gradient Methods”. In:arXiv preprint arXiv:2410.10800(2024)
-
[65]
Villani.Optimal Transport: Old and New
C. Villani.Optimal Transport: Old and New. Springer, 2009
work page 2009
-
[66]
Convergence of AdaGrad for non-convex objectives: Simple proofs and relaxed assumptions
B. Wang, H. Zhang, Z. Ma, and W. Chen. “Convergence of AdaGrad for non-convex objectives: Simple proofs and relaxed assumptions”. In:Conference on Learning Theory. 2023, pp. 161–190
work page 2023
-
[67]
K. Wen, X. Dang, K. Lyu, T. Ma, and P. Liang.Fantastic Pretraining Optimizers and Where to Find Them 2.1: Hyperball Optimization. 2025.url: https://tinyurl.com/ muonh
work page 2025
-
[68]
Controlled llm training on spectral sphere.arXiv preprint arXiv:2601.08393, 2026
T. Xie et al. “Controlled LLM Training on Spectral Sphere”. In:arXiv preprint arXiv:2601.08393(2026)
-
[69]
MARS: Unleashing the Power of Variance Reduction for Training Large Models
H. Yuan, Y. Liu, S. Wu, Z. Xun, and Q. Gu. “MARS: Unleashing the Power of Variance Reduction for Training Large Models”. In:International Conference on Machine Learning. 2025, pp. 73553–73587. 17
work page 2025
-
[70]
Improved Analysis of Clipping Algorithms for Non-convex Optimization
B. Zhang, J. Jin, C. Fang, and L. Wang. “Improved Analysis of Clipping Algorithms for Non-convex Optimization”. In:Advances in Neural Information Processing Systems. 2020, pp. 15511–15521
work page 2020
-
[71]
Why gradient clipping accelerates training: A theoretical justification for adaptivity
J. Zhang, T. He, S. Sra, and A. Jadbabaie. “Why gradient clipping accelerates training: A theoretical justification for adaptivity”. In:arXiv preprint arXiv:1905.11881(2019)
-
[72]
AdaGrad meets Muon: Adaptive stepsizes for orthogonal updates
M. Zhang, Y. Liu, and H. Schaeffer. “AdaGrad meets Muon: Adaptive stepsizes for orthogonal updates”. In:arXiv preprint arXiv:2509.02981(2025). 18 A Preliminaries and helper results Lipschitz smoothness of a function f : E→R with constant L > 0 means that f is continuously differentiable and satisfies ∥∇f(x)− ∇f(¯x)∥ ≤L∥x−¯x∥ ∀x,¯x∈E. Lipschitz smoothness ...
-
[73]
kX i=1 (1−α) k−i(∇f(x i, ξi)− ∇f(x i)) # ≤E
◦σ , [37, Corollary 2.6] ensures that Φ − µ 2 ∥ · ∥2 F is convex, and using the reverse direction of [5, Theorem 5.17] yields the desired result. That Φ is lsc also follows from [37, Corollary 2.6]. Second, since Φ = ϕ◦σ is real orthogonal invariant from [37, Proposition 2.2], we have that Φ( −X) = Φ(( −Im)XI n) = Φ( X) for all X∈R m×n, thus Φ is even. Fu...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.