Recognition: 2 theorem links
· Lean TheoremFIS-DiT: Breaking the Few-Step Video Inference Barrier via Training-Free Frame Interleaved Sparsity
Pith reviewed 2026-05-13 07:10 UTC · model grok-4.3
The pith
Video DiTs can be accelerated over twofold in few-step regimes by shifting sparsity optimization to the latent frame dimension without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
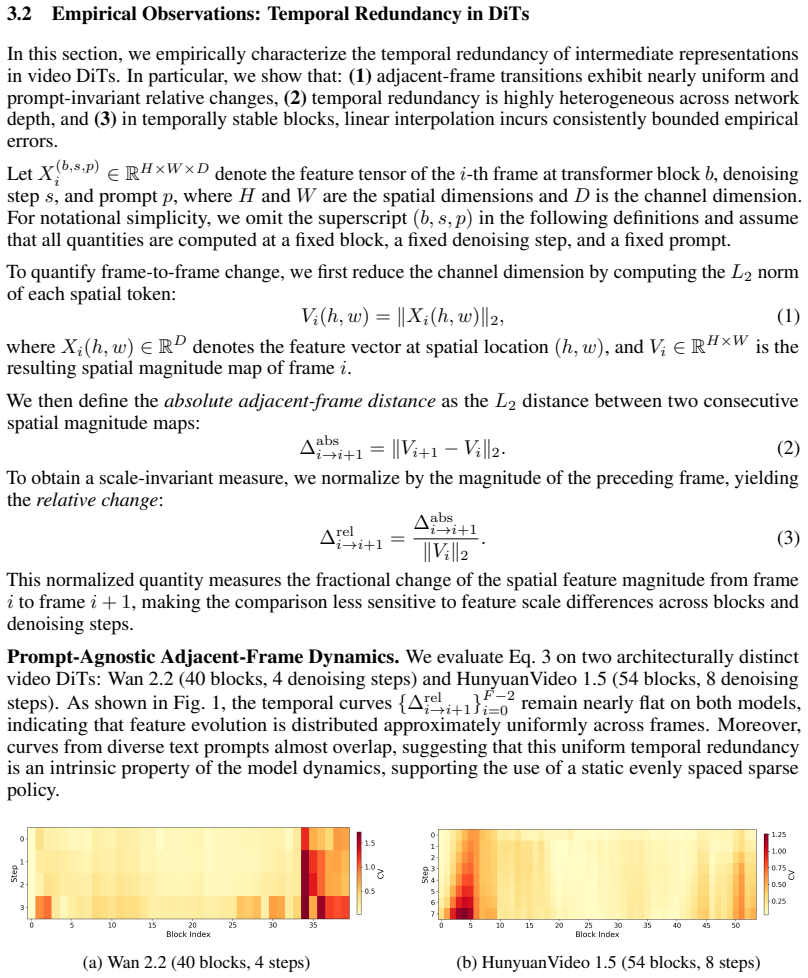
Frame Interleaved Sparsity (FIS) is an execution strategy that manipulates frame subsets across the model hierarchy in video diffusion transformers. It refreshes all latent positions without requiring full-scale block computation on every frame at every step. This is motivated by the claim that frame-wise sparsity permits reduced computation while each frame position remains equally vital to the global spatiotemporal context. On Wan 2.2 and HunyuanVideo 1.5 the approach delivers 2.11 to 2.41 times faster inference in few-step settings with negligible drops in VBench-Q and CLIP scores.
What carries the argument
Frame Interleaved Sparsity (FIS), an execution strategy that manipulates frame subsets across the model hierarchy to refresh all latent positions without full-scale block computation.
Load-bearing premise
The claimed intrinsic duality of frame-wise sparsity permitting reduced computation together with structural consistency where each frame position remains equally vital holds in the latent space of current video DiTs and can be exploited via simple subset manipulation without retraining.
What would settle it
Measuring a large drop in VBench-Q or CLIP scores when the frame-subset manipulation is applied during few-step inference on the same models would show the duality does not hold.
Figures




read the original abstract
While the overall inference latency of Video Diffusion Transformers (DiTs) can be substantially reduced through model distillation, per-step inference latency remains a critical bottleneck. Existing acceleration paradigms primarily exploit redundancy across the denoising trajectory; however, we identify a limitation where these step-wise strategies encounter diminishing returns in few-step regimes. In such scenarios, the scarcity of temporal states prevents effective feature reuse or predictive modeling, creating a formidable barrier to further acceleration. To overcome this, we propose Frame Interleaved Sparsity DiT (FIS-DiT), a training-free and operator-agnostic framework that shifts the optimization focus from the temporal trajectory to the latent frame dimension. Our approach is motivated by an intrinsic duality within this dimension: the existence of frame-wise sparsity that permits reduced computation, coupled with a structural consistency where each frame position remains equally vital to the global spatiotemporal context. Leveraging this insight, we implement Frame Interleaved Sparsity (FIS) as an execution strategy that manipulates frame subsets across the model hierarchy, refreshing all latent positions without requiring full-scale block computation. Empirical evaluations on Wan 2.2 and HunyuanVideo 1.5 demonstrate that FIS-DiT consistently achieves 2.11--2.41$\times$ speedup with negligible degradation across VBench-Q and CLIP metrics, providing a scalable and robust pathway toward real-time high-definition video generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FIS-DiT, a training-free and operator-agnostic framework to accelerate few-step inference in Video Diffusion Transformers by shifting optimization to the latent frame dimension. It identifies diminishing returns in step-wise acceleration methods for few-step regimes and exploits an intrinsic duality of frame-wise sparsity (permitting reduced computation) together with structural consistency (each frame position remains equally vital). The FIS execution strategy manipulates frame subsets across the model hierarchy to refresh all latent positions without full-scale block computation. Empirical results on Wan 2.2 and HunyuanVideo 1.5 report 2.11--2.41× speedup with negligible degradation on VBench-Q and CLIP metrics.
Significance. If the results hold under scrutiny, the work offers a scalable pathway to real-time high-definition video generation by targeting per-step latency in few-step regimes where trajectory-based methods plateau. The training-free, operator-agnostic design and focus on the latent frame dimension rather than denoising steps are notable strengths that could complement existing distillation techniques without requiring retraining.
major comments (2)
- [§4 (Empirical Evaluations)] §4 (Empirical Evaluations): The reported 2.11--2.41× speedups on Wan 2.2 and HunyuanVideo 1.5 are presented without exact sparsity schedules, frame-subset sizes, hierarchy levels of application, error bars, or the number of runs, which are load-bearing for verifying the consistency and reproducibility of the speedup and quality claims.
- [§3 (Proposed Method)] §3 (Proposed Method): The central duality of frame-wise sparsity plus positional consistency is motivated conceptually but lacks quantitative support such as measurements of frame importance in latent space or ablations on subset manipulation, leaving the claim that simple training-free subset operations suffice without model-specific tuning unverified.
minor comments (1)
- [Abstract] Abstract: The phrase 'negligible degradation' is used without reference to specific delta values on VBench-Q or CLIP, which would clarify the quality-speedup tradeoff.
Simulated Author's Rebuttal
We appreciate the referee's detailed feedback on our manuscript. We address the major comments point-by-point below. Where revisions are needed for clarity and reproducibility, we will update the manuscript accordingly.
read point-by-point responses
-
Referee: [§4 (Empirical Evaluations)] §4 (Empirical Evaluations): The reported 2.11--2.41× speedups on Wan 2.2 and HunyuanVideo 1.5 are presented without exact sparsity schedules, frame-subset sizes, hierarchy levels of application, error bars, or the number of runs, which are load-bearing for verifying the consistency and reproducibility of the speedup and quality claims.
Authors: We agree that additional details are necessary to ensure reproducibility. In the revised manuscript, we will add a dedicated subsection in §4 detailing the exact sparsity schedules (e.g., 50% frame sparsity with specific interleaving patterns), frame-subset sizes used (such as processing 4 out of 8 frames per block), the hierarchy levels (applied at layers 4-8 in the DiT), and report mean and standard deviation from 5 independent runs with error bars. This will strengthen the empirical claims. revision: yes
-
Referee: [§3 (Proposed Method)] §3 (Proposed Method): The central duality of frame-wise sparsity plus positional consistency is motivated conceptually but lacks quantitative support such as measurements of frame importance in latent space or ablations on subset manipulation, leaving the claim that simple training-free subset operations suffice without model-specific tuning unverified.
Authors: The motivation is indeed conceptual, grounded in the observed diminishing returns of step-wise methods in few-step regimes. To address this, we will include quantitative measurements in the revised §3, such as the average L2 norm differences between frames in latent space to demonstrate sparsity, and a small ablation study on different subset manipulation strategies (e.g., random vs. interleaved) showing consistent performance across models without per-model tuning. This supports that the training-free approach generalizes. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents FIS-DiT as a training-free, operator-agnostic execution strategy that exploits an observed intrinsic duality (frame-wise sparsity plus positional consistency) in the latent frame dimension of video DiTs. The central claim of 2.11-2.41x speedup rests on empirical results across Wan 2.2 and HunyuanVideo 1.5 using VBench-Q and CLIP metrics, with no equations, fitted parameters, self-definitional reductions, or load-bearing self-citations shown in the manuscript. The duality is introduced as motivation from observation rather than a derived or self-referential quantity, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frame-wise sparsity exists in the latent dimension that permits reduced computation while each frame position remains equally vital to the global context.
Reference graph
Works this paper leans on
-
[1]
Depth-aware video frame interpolation
Wenbo Bao, Wei-Sheng Lai, Chao Ma, Xiaoyun Zhang, Zhiyong Gao, and Ming-Hsuan Yang. Depth-aware video frame interpolation. InCVPR, 2019
work page 2019
-
[2]
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InCVPR, 2023
work page 2023
-
[3]
Token merging: Your vit but faster
Daniel Bolya, Cheng-Yang Fu, Xiaoliang Dai, Peizhao Zhang, Christoph Feichtenhofer, and Judy Hoffman. Token merging: Your vit but faster. InICLR, 2023
work page 2023
-
[4]
Token merging for fast stable diffusion
Daniel Bolya and Judy Hoffman. Token merging for fast stable diffusion. InCVPR Workshop, 2023
work page 2023
-
[5]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
Haoxin Chen, Menghan Xia, Yingqing He, Yong Zhang, Xiaodong Cun, Shaoshu Yang, Jinbo Xing, Yaofang Liu, Qifeng Chen, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter1: Open diffusion models for high-quality video generation.arXiv preprint arXiv:2310.19512, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Liang Chen, Haozhe Zhao, Tianyu Liu, Shuai Bai, Junyang Lin, Chang Zhou, and Baobao Chang. An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. InECCV, 2024
work page 2024
-
[7]
Diffrate: Differentiable compression rate for efficient vision transformers
Mengzhao Chen, Wenqi Shao, Peng Xu, Mingbao Lin, Kaipeng Zhang, Fei Chao, Rongrong Ji, Yu Qiao, and Ping Luo. Diffrate: Differentiable compression rate for efficient vision transformers. InICCV, 2023
work page 2023
-
[8]
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen. δ-dit: A training-free acceleration method tailored for diffusion transformers.arXiv preprint arXiv:2406.01125, 2024
-
[9]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. Flashattention: Fast and memory-efficient exact attention with io-awareness. InNeurIPS, 2022
work page 2022
-
[10]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. InNeurIPS, 2021
work page 2021
-
[11]
Dollar: Few-step video generation via distillation and latent reward optimization
Zihan Ding, Chi Jin, Difan Liu, Haitian Zheng, Krishna Kumar Singh, Qiang Zhang, Yan Kang, Zhe Lin, and Yuchen Liu. Dollar: Few-step video generation via distillation and latent reward optimization. InICCV, 2025
work page 2025
-
[12]
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. InICLR, 2024
work page 2024
-
[13]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P. Kingma, Ben Poole, Mohammad Norouzi, David J. Fleet, and Tim Salimans. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020
work page 2020
-
[15]
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. InNeurIPS, 2022
work page 2022
-
[16]
Real-time intermediate flow estimation for video frame interpolation
Zhewei Huang, Tianyuan Zhang, Wen Heng, Boxin Shi, and Shuchang Zhou. Real-time intermediate flow estimation for video frame interpolation. InECCV, 2022
work page 2022
-
[17]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Comprehensive benchmark suite for video generative models. InCVPR, 2024. 10
work page 2024
-
[18]
Super slomo: High quality estimation of multiple intermediate frames for video interpolation
Huaizu Jiang, Deqing Sun, Varun Jampani, Ming-Hsuan Yang, Erik Learned-Miller, and Jan Kautz. Super slomo: High quality estimation of multiple intermediate frames for video interpolation. InCVPR, 2018
work page 2018
-
[19]
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S. Ryoo, and Tian Xie. Adaptive caching for faster video generation with diffusion transformers. InICCV, 2025
work page 2025
-
[20]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InNeurIPS, 2022
work page 2022
-
[21]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Faster diffusion: Rethinking the role of the encoder for diffusion model inference
Senmao Li, Taihang Hu, Joost van de Weijer, Fahad Shahbaz Khan, Tao Liu, Linxuan Li, Shiqi Yang, Yaxing Wang, Ming-Ming Cheng, and Jian Yang. Faster diffusion: Rethinking the role of the encoder for diffusion model inference. InNeurIPS, 2024
work page 2024
-
[23]
Not all patches are what you need: Expediting vision transformers via token reorganizations
Youwei Liang, Chongjian Ge, Zhan Tong, Yibing Song, Jue Wang, and Pengtao Xie. Not all patches are what you need: Expediting vision transformers via token reorganizations. InICLR, 2022
work page 2022
-
[24]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InCVPR, 2025
work page 2025
-
[25]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps. InNeurIPS, 2022
work page 2022
-
[26]
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm- solver++: Fast solver for guided sampling of diffusion probabilistic models.arXiv preprint arXiv:2211.01095, 2022
-
[27]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
Zhengyao Lv, Chenyang Si, Junhao Song, Zhenyu Yang, Yu Qiao, Ziwei Liu, and Kwan-Yee K. Wong. Fastercache: Training-free video diffusion model acceleration with high quality. In ICLR, 2025
work page 2025
-
[29]
Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048, 2024
work page internal anchor Pith review arXiv 2024
-
[30]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InCVPR, 2024
work page 2024
-
[31]
Model reveals what to cache: Profiling-based feature reuse for video diffusion models
Xuran Ma, Yexin Liu, Yaofu Liu, Xianfeng Wu, Mingzhe Zheng, Zihao Wang, Ser-Nam Lim, and Harry Yang. Model reveals what to cache: Profiling-based feature reuse for video diffusion models. InICCV, 2025
work page 2025
-
[32]
Magcache: Fast video generation with magnitude-aware cache.arXiv preprint arXiv:2506.09045, 2025
Zehong Ma, Longhui Wei, Feng Wang, Shiliang Zhang, and Qi Tian. Magcache: Fast video generation with magnitude-aware cache.arXiv preprint arXiv:2506.09045, 2025
-
[33]
Token pooling in vision transformers for image classification
Dmitrii Marin, Jen-Hao Rick Chang, Anurag Ranjan, Anish Prabhu, Mohammad Rastegari, and Oncel Tuzel. Token pooling in vision transformers for image classification. InWACV, 2023
work page 2023
-
[34]
Improved denoising diffusion probabilistic models
Alex Nichol and Prafulla Dhariwal. Improved denoising diffusion probabilistic models. In ICML, 2021
work page 2021
-
[35]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 11
work page 2023
-
[36]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
Dynamicvit: Efficient vision transformers with dynamic token sparsification
Yongming Rao, Wenliang Zhao, Benlin Liu, Jiwen Lu, Jie Zhou, and Cho-Jui Hsieh. Dynamicvit: Efficient vision transformers with dynamic token sparsification. InNeurIPS, 2021
work page 2021
-
[38]
Film: Frame interpolation for large motion
Fitsum Reda, Janne Kontkanen, Eric Tabellion, Deqing Sun, Caroline Pantofaru, and Brian Curless. Film: Frame interpolation for large motion. InECCV, 2022
work page 2022
-
[39]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[40]
Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova
Michael S. Ryoo, AJ Piergiovanni, Anurag Arnab, Mostafa Dehghani, and Anelia Angelova. Tokenlearner: What can 8 learned tokens do for images and videos? InNeurIPS, 2021
work page 2021
-
[41]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. InICLR, 2022
work page 2022
-
[42]
Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang. Fora: Fast- forward caching in diffusion transformer acceleration.arXiv preprint arXiv:2407.01425, 2024
-
[43]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Weiss, Niru Maheswaranathan, and Surya Ganguli
Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InICML, 2015
work page 2015
-
[45]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InICML, 2023
work page 2023
-
[46]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021
work page 2021
-
[47]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Fu-Yun Wang, Zhaoyang Huang, Xiaoyu Shi, Weikang Bian, Guanglu Song, Yu Liu, and Hongsheng Li. Animatelcm: Accelerating the animation of personalized diffusion models and adapters with decoupled consistency learning.arXiv preprint arXiv:2402.00769, 2024
-
[49]
Precisecache: Precise feature caching for efficient and high-fidelity video generation,
Jiangshan Wang, Kang Zhao, Jiayi Guo, Jiayu Wang, Hang Guo, Chenyang Zhu, Xiu Li, and Xiangyu Yue. Precisecache: Precise feature caching for efficient and high-fidelity video generation.arXiv preprint arXiv:2603.00976, 2026
-
[50]
Videolcm: Video latent consistency model,
Xiang Wang, Shiwei Zhang, Han Zhang, Yu Liu, Yingya Zhang, Changxin Gao, and Nong Sang. Videolcm: Video latent consistency model.arXiv preprint arXiv:2312.09109, 2023
-
[51]
Lavie: High-quality video gener- ation with cascaded latent diffusion models
Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, Yuwei Guo, Tianxing Wu, Chenyang Si, Yum- ing Jiang, Cunjian Chen, Chen Change Loy, Bo Dai, Dahua Lin, Yu Qiao, and Ziwei Liu. Lavie: High-quality video generation with cascaded latent diffusion models.arXiv preprint arXiv:2309.15103, 2023
-
[52]
Dynamicrafter: Animating open-domain images with video diffusion priors
Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Gongye Liu, Xintao Wang, Ying Shan, and Tien-Tsin Wong. Dynamicrafter: Animating open-domain images with video diffusion priors. InECCV, 2024
work page 2024
-
[53]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Xiaotao Gu, Yuxuan Zhang, Weihan Wang, Yean Cheng, Ting Liu, Bin Xu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. InICLR, 2025. 12
work page 2025
-
[54]
A-vit: Adaptive tokens for efficient vision transformer
Hongxu Yin, Arash Vahdat, Jose Alvarez, Arun Mallya, Jan Kautz, and Pavlo Molchanov. A-vit: Adaptive tokens for efficient vision transformer. InCVPR, 2022
work page 2022
-
[55]
Real-time video generation with pyramid attention broadcast
Xuanlei Zhao, Xiaolong Jin, Kai Wang, and Yang You. Real-time video generation with pyramid attention broadcast. InICLR, 2025
work page 2025
-
[56]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Magicvideo: Efficient video generation with latent diffusion models
Daquan Zhou, Weimin Wang, Hanshu Yan, Weiwei Lv, Yizhe Zhu, and Jiashi Feng. Magicvideo: Efficient video generation with latent diffusion models.arXiv preprint arXiv:2211.11018, 2022. 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.