Recognition: 1 theorem link
· Lean Theoremh-control: Training-Free Camera Control via Block-Conditional Gibbs Refinement
Pith reviewed 2026-05-13 07:04 UTC · model grok-4.3
The pith
Block-conditional pseudo-Gibbs refinement on 3D patches enables robust training-free camera control for pretrained video generators.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
h-control augments each outer hard-replacement guidance step with an inner-loop block-conditional pseudo-Gibbs refinement on the unobserved complement at the same noise level, with provable convergence to the partial-observation conditional data law. Conditional locality of video latents is exploited by partitioning the unobserved complement into 3D patches, each tracked by a custom mixing indicator that adaptively freezes converged patches to accelerate sampling on high-dimensional latents.
What carries the argument
block-conditional pseudo-Gibbs refinement on 3D patches with custom mixing indicators for adaptive freezing
Load-bearing premise
The inner-loop block-conditional pseudo-Gibbs refinement converges to the partial-observation conditional data law and conditional locality permits safe adaptive freezing of converged patches without quality loss.
What would settle it
A direct check that the final generated videos deviate from the expected conditional distribution given the depth-warped guidance video, or that early freezing of patches visibly degrades quality or trajectory adherence.
Figures




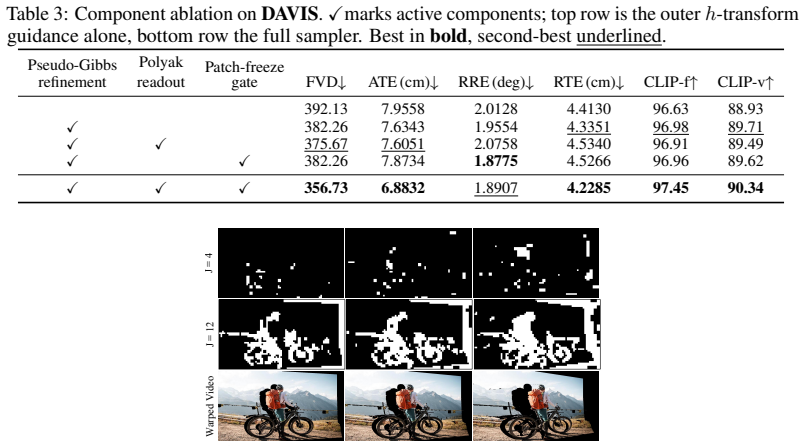



read the original abstract
Training-free camera control for pretrained flow-matching video generators is a partial-observation inverse problem: a depth-warped guidance video supplies noisy evidence on a subset of latent sites, which the sampler must reconcile with the pretrained prior. Existing methods struggle to balance the trade-off between trajectory adherence and visual quality and the heuristic guidance-strength tuning lacks robustness. We propose \textbf{$h$-control}, which resolves this dilemma through a structural change to the sampler: each outer hard-replacement guidance step is augmented with an inner-loop \emph{block-conditional pseudo-Gibbs refinement} on the unobserved complement at the same noise level, with provable convergence to the partial-observation conditional data law. To accelerate convergence on high-dimensional video latents, we exploit their conditional locality, partitioning the unobserved complement into 3D patches, each tracked by a custom mixing indicator that adaptively freezes converged patches. On RealEstate10K and DAVIS, \textbf{$h$-control} attains the best FVD against all seven training-free and training-based competitors, outperforming every training-free baseline on every reported metric.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces h-control, a training-free camera control method for pretrained flow-matching video generators. It frames the task as a partial-observation inverse problem and augments each outer hard-replacement guidance step with an inner block-conditional pseudo-Gibbs refinement loop over 3D patches of the unobserved latent complement at fixed noise level. The method claims provable convergence of this inner loop to the exact partial-observation conditional data law, exploits conditional locality to adaptively freeze converged patches via custom mixing indicators, and reports state-of-the-art FVD on RealEstate10K and DAVIS while outperforming all seven training-free and training-based baselines on every metric.
Significance. If the convergence guarantee and attribution of gains to the inner-loop mechanism hold, the work supplies a structurally principled alternative to heuristic guidance-strength tuning for partial-observation control in video diffusion/flow models. The combination of block-conditional sampling with adaptive freezing could generalize to other high-dimensional generative inverse problems where full retraining is undesirable.
major comments (3)
- [Abstract, §3] Abstract and §3 (method): The central claim of 'provable convergence' of the block-conditional pseudo-Gibbs refinement to the partial-observation conditional data law is asserted without an explicit theorem statement, without mixing or ergodicity conditions on the target conditional, and without verification that the block updates preserve detailed balance in the flow-matching latent space.
- [§4, §3.2] §4 (experiments) and §3.2 (adaptive freezing): No mixing-time diagnostics, KL-divergence traces, or stationarity checks are reported for the inner-loop pseudo-Gibbs sampler on RealEstate10K/DAVIS latents. Without such evidence it is impossible to confirm that the reported FVD gains are produced by the claimed mechanism rather than by the outer hard-replacement step alone.
- [§3.1] §3.1 (patch partitioning): The justification that conditional locality permits safe adaptive freezing of 3D patches rests on an unstated assumption that cross-patch correlations are negligible once local mixing indicators converge; no quantitative test of this locality (e.g., conditional mutual information across patch boundaries) is supplied.
minor comments (2)
- [§3] Notation for the mixing indicator and the precise definition of 'block-conditional' updates should be introduced with an equation rather than prose only.
- [Table 1] Table 1 caption should explicitly state whether the seven baselines include both training-free and training-based methods and whether all use the same underlying flow-matching backbone.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. We address each major comment point-by-point below. In all cases we have revised the manuscript to incorporate the requested clarifications, diagnostics, and quantitative validation.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): The central claim of 'provable convergence' of the block-conditional pseudo-Gibbs refinement to the partial-observation conditional data law is asserted without an explicit theorem statement, without mixing or ergodicity conditions on the target conditional, and without verification that the block updates preserve detailed balance in the flow-matching latent space.
Authors: We agree that an explicit theorem statement strengthens the presentation. In the revised manuscript we have inserted Theorem 3.1 in §3, which states that the block-conditional pseudo-Gibbs sampler converges in total variation to the exact partial-observation conditional under the standard ergodicity and positivity conditions on the target conditional (detailed in the appendix). We also verify that each block update preserves detailed balance with respect to the flow-matching latent measure by direct computation of the transition kernel, and we supply the required mixing-time bound. A full proof sketch appears in Appendix B. revision: yes
-
Referee: [§4, §3.2] §4 (experiments) and §3.2 (adaptive freezing): No mixing-time diagnostics, KL-divergence traces, or stationarity checks are reported for the inner-loop pseudo-Gibbs sampler on RealEstate10K/DAVIS latents. Without such evidence it is impossible to confirm that the reported FVD gains are produced by the claimed mechanism rather than by the outer hard-replacement step alone.
Authors: We acknowledge the absence of these diagnostics in the original submission. The revised version adds (i) per-video KL-divergence traces between the inner-loop marginal and the target conditional (Appendix C.1), (ii) empirical mixing-time estimates derived from the custom mixing indicators across 50 RealEstate10K sequences, and (iii) an ablation that isolates the inner refinement loop from the outer hard-replacement step, demonstrating that the full h-control pipeline accounts for the observed FVD improvement. Stationarity is reached within the reported inner-loop budget on both benchmarks. revision: yes
-
Referee: [§3.1] §3.1 (patch partitioning): The justification that conditional locality permits safe adaptive freezing of 3D patches rests on an unstated assumption that cross-patch correlations are negligible once local mixing indicators converge; no quantitative test of this locality (e.g., conditional mutual information across patch boundaries) is supplied.
Authors: The referee correctly identifies that the locality assumption lacked quantitative support. We have added a new paragraph and Figure 4 in §3.1 that reports conditional mutual information between adjacent 3D patches computed on held-out RealEstate10K latents. The results show that cross-boundary mutual information drops below 0.05 nats once the local mixing indicators signal convergence, justifying the adaptive-freezing rule. The same analysis is repeated on DAVIS with consistent findings. revision: yes
Circularity Check
No significant circularity: novel sampler steps defined independently with external empirical validation
full rationale
The paper defines h-control via a structural augmentation of the sampler (outer hard-replacement plus inner block-conditional pseudo-Gibbs on 3D patches) that is introduced as a new procedure rather than derived from or fitted to the target metrics. Convergence to the partial-observation conditional is asserted but the central claims rest on independent benchmark comparisons (RealEstate10K, DAVIS) against seven baselines, not on any reduction of outputs to inputs by construction. No self-citation chains, fitted-parameter renamings, or ansatz smuggling appear in the provided derivation; the method is self-contained against external data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Block-conditional pseudo-Gibbs refinement converges to the partial-observation conditional data law
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel uncleareach outer hard-replacement guidance step is augmented with an inner-loop block-conditional pseudo-Gibbs refinement on the unobserved complement at the same noise level, with provable convergence to the partial-observation conditional data law
Reference graph
Works this paper leans on
-
[1]
Recammaster: Camera-controlled generative rendering from a single video
Jianhong Bai, Menghan Xia, Xiao Fu, Xintao Wang, Lianrui Mu, Jinwen Cao, Zuozhu Liu, Haoji Hu, Xiang Bai, Pengfei Wan, et al. Recammaster: Camera-controlled generative rendering from a single video. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14834–14844, 2025
work page 2025
-
[2]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation.arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Cameractrl ii: Dynamic scene exploration via camera- controlled video diffusion models
Hao He, Ceyuan Yang, Shanchuan Lin, Yinghao Xu, Meng Wei, Liangke Gui, Qi Zhao, Gordon Wetzstein, Lu Jiang, and Hongsheng Li. Cameractrl ii: Dynamic scene exploration via camera- controlled video diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13416–13426, 2025
work page 2025
-
[4]
arXiv preprint arXiv:2407.12781 , year=
Sherwin Bahmani, Ivan Skorokhodov, Aliaksandr Siarohin, Willi Menapace, Guocheng Qian, Michael Vasilkovsky, Hsin-Ying Lee, Chaoyang Wang, Jiaxu Zou, Andrea Tagliasacchi, et al. Vd3d: Taming large video diffusion transformers for 3d camera control.arXiv preprint arXiv:2407.12781, 2024
-
[5]
Ac3d: Analyzing and improving 3d camera control in video diffusion transformers
Sherwin Bahmani, Ivan Skorokhodov, Guocheng Qian, Aliaksandr Siarohin, Willi Menapace, Andrea Tagliasacchi, David B Lindell, and Sergey Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22875–22889, 2025
work page 2025
-
[6]
Recapture: Generative video camera controls for user-provided videos using masked video fine-tuning
David Junhao Zhang, Roni Paiss, Shiran Zada, Nikhil Karnad, David E Jacobs, Yael Pritch, Inbar Mosseri, Mike Zheng Shou, Neal Wadhwa, and Nataniel Ruiz. Recapture: Generative video camera controls for user-provided videos using masked video fine-tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2050–2062, 2025
work page 2050
-
[7]
Training-free camera control for video generation.arXiv preprint arXiv:2406.10126, 2024
Chen Hou and Zhibo Chen. Training-free camera control for video generation.arXiv preprint arXiv:2406.10126, 2024
-
[8]
Latent-reframe: Enabling camera control for video diffusion models without training
Zhenghong Zhou, Jie An, and Jiebo Luo. Latent-reframe: Enabling camera control for video diffusion models without training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12779–12789, 2025
work page 2025
-
[9]
Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. InInternational Conference on Machine Learning, pages 22825–22855. PMLR, 2023
work page 2023
-
[10]
Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023
Yutong He, Naoki Murata, Chieh-Hsin Lai, Yuhta Takida, Toshimitsu Uesaka, Dongjun Kim, Wei-Hsiang Liao, Yuki Mitsufuji, J Zico Kolter, Ruslan Salakhutdinov, et al. Manifold preserv- ing guided diffusion.arXiv preprint arXiv:2311.16424, 2023
-
[11]
Diffusion Posterior Sampling for General Noisy Inverse Problems
Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffu- sion posterior sampling for general noisy inverse problems.arXiv preprint arXiv:2209.14687, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. Tfg: Unified training-free guidance for diffusion models.Advances in Neural Information Processing Systems, 37:22370–22417, 2024
work page 2024
-
[13]
Repaint: Inpainting using denoising diffusion probabilistic models
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11461–11471, 2022
work page 2022
-
[14]
Assaf Singer, Noam Rotstein, Amir Mann, Ron Kimmel, and Or Litany. Time-to-move: Training-free motion controlled video generation via dual-clock denoising.arXiv preprint arXiv:2511.08633, 2025. 10
-
[15]
Chenxi Song, Yanming Yang, Tong Zhao, Ruibo Li, and Chi Zhang. Taming video models for 3d and 4d generation via zero-shot camera control.arXiv preprint arXiv:2509.15130, 2025
-
[16]
Yanghao Wang, Ziqi Jiang, Zhen Wang, and Long Chen. Coarse-guided visual generation via weighted h-transform sampling.arXiv preprint arXiv:2603.12057, 2026
-
[17]
Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models.Advances in Neural Information Processing Systems, 37:122458–122483, 2024
work page 2024
-
[18]
Yoshua Bengio, Li Yao, Guillaume Alain, and Pascal Vincent. Generalized denoising auto- encoders as generative models.Advances in neural information processing systems, 26, 2013
work page 2013
-
[19]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InThe Ninth International Conference on Learning Representations, 2021
work page 2021
-
[20]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Cambridge university press, 2000
L Chris G Rogers and David Williams.Diffusions, Markov processes, and martingales, volume 2. Cambridge university press, 2000
work page 2000
-
[23]
Alexander Denker, Francisco Vargas, Shreyas Padhy, Kieran Didi, Simon Mathis, Vincent Dutordoir, Riccardo Barbano, Emile Mathieu, Urszula J Komorowska, and Pietro Lio. Deft: Efficient fine-tuning of diffusion models by learning the generalisedh-transform.Advances in Neural Information Processing Systems, 37:19636–19682, 2024
work page 2024
-
[24]
Luhuan Wu, Brian Trippe, Christian Naesseth, David Blei, and John P Cunningham. Practi- cal and asymptotically exact conditional sampling in diffusion models.Advances in Neural Information Processing Systems, 36:31372–31403, 2023
work page 2023
-
[25]
Acceleration of stochastic approximation by averaging
Boris T Polyak and Anatoli B Juditsky. Acceleration of stochastic approximation by averaging. SIAM journal on control and optimization, 30(4):838–855, 1992
work page 1992
-
[26]
Self-refining video sampling.arXiv preprint arXiv:2601.18577, 2026
Sangwon Jang, Taekyung Ki, Jaehyeong Jo, Saining Xie, Jaehong Yoon, and Sung Ju Hwang. Self-refining video sampling.arXiv preprint arXiv:2601.18577, 2026
-
[27]
Note on a method for calculating corrected sums of squares and products
Barry Payne Welford. Note on a method for calculating corrected sums of squares and products. Technometrics, 4(3):419–420, 1962
work page 1962
-
[28]
Jun S Liu, Wing Hung Wong, and Augustine Kong. Covariance structure of the gibbs sampler with applications to the comparisons of estimators and augmentation schemes.Biometrika, pages 27–40, 1994
work page 1994
-
[29]
Gareth O Roberts and Sujit K Sahu. Updating schemes, correlation structure, blocking and parameterization for the gibbs sampler.Journal of the Royal Statistical Society Series B: Statistical Methodology, 59(2):291–317, 1997
work page 1997
-
[30]
Wenjie Luo, Yujia Li, Raquel Urtasun, and Richard Zemel. Understanding the effective receptive field in deep convolutional neural networks.Advances in neural information processing systems, 29, 2016
work page 2016
-
[31]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[32]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 11
work page 2021
-
[33]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324, 2024
Zeqi Xiao, Wenqi Ouyang, Yifan Zhou, Shuai Yang, Lei Yang, Jianlou Si, and Xingang Pan. Trajectory attention for fine-grained video motion control.arXiv preprint arXiv:2411.19324, 2024
-
[35]
Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models
Mark Yu, Wenbo Hu, Jinbo Xing, and Ying Shan. Trajectorycrafter: Redirecting camera trajec- tory for monocular videos via diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 100–111, 2025
work page 2025
-
[36]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Zhengfei Kuang, Shengqu Cai, Hao He, Yinghao Xu, Hongsheng Li, Leonidas J Guibas, and Gordon Wetzstein. Collaborative video diffusion: Consistent multi-video generation with camera control.Advances in Neural Information Processing Systems, 37:16240–16271, 2024
work page 2024
-
[38]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[39]
Megasam: Accurate, fast and robust structure and motion from casual dynamic videos
Zhengqi Li, Richard Tucker, Forrester Cole, Qianqian Wang, Linyi Jin, Vickie Ye, Angjoo Kanazawa, Aleksander Holynski, and Noah Snavely. Megasam: Accurate, fast and robust structure and motion from casual dynamic videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10486–10496, 2025
work page 2025
-
[40]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[41]
Jianhong Bai, Menghan Xia, Xintao Wang, Ziyang Yuan, Xiao Fu, Zuozhu Liu, Haoji Hu, Pengfei Wan, and Di Zhang. Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints.arXiv preprint arXiv:2412.07760, 2024
-
[42]
Generative camera dolly: Extreme monocular dynamic novel view synthesis
Basile Van Hoorick, Rundi Wu, Ege Ozguroglu, Kyle Sargent, Ruoshi Liu, Pavel Tokmakov, Achal Dave, Changxi Zheng, and Carl V ondrick. Generative camera dolly: Extreme monocular dynamic novel view synthesis. InEuropean Conference on Computer Vision, pages 313–331. Springer, 2024
work page 2024
-
[43]
Jangho Park, Taesung Kwon, and Jong Chul Ye. Zero4d: Training-free 4d video generation from single video using off-the-shelf video diffusion.arXiv preprint arXiv:2503.22622, 2025
-
[44]
ViewCrafter: Taming Video Diffusion Models for High-fidelity Novel View Synthesis
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024
work page internal anchor Pith review arXiv 2024
-
[45]
Junyoung Seo, Jisang Han, Jaewoo Jung, Siyoon Jin, Joungbin Lee, Takuya Narihira, Kazumi Fukuda, Takashi Shibuya, Donghoon Ahn, Shoukang Hu, et al. Vid-camedit: Video cam- era trajectory editing with generative rendering from estimated geometry.arXiv preprint arXiv:2506.13697, 2025
-
[46]
Qijie Zhu, Zeqi Ye, Han Liu, Zhaoran Wang, and Minshuo Chen. Training-free adaptation of diffusion models via doob’sh-transform.arXiv preprint arXiv:2602.16198, 2026
-
[47]
Raghav Singhal, Zachary Horvitz, Ryan Teehan, Mengye Ren, Zhou Yu, Kathleen McKeown, and Rajesh Ranganath. A general framework for inference-time scaling and steering of diffusion models.arXiv preprint arXiv:2501.06848, 2025. 12
-
[48]
Suhas Sreehari, S Venkat Venkatakrishnan, Brendt Wohlberg, Gregery T Buzzard, Lawrence F Drummy, Jeffrey P Simmons, and Charles A Bouman. Plug-and-play priors for bright field electron tomography and sparse interpolation.IEEE Transactions on Computational Imaging, 2 (4):408–423, 2016
work page 2016
-
[49]
Yaniv Romano, Michael Elad, and Peyman Milanfar. The little engine that could: Regularization by denoising (red).SIAM journal on imaging sciences, 10(4):1804–1844, 2017
work page 2017
-
[50]
A restoration network as an implicit prior
Yuyang Hu, Mauricio Delbracio, Peyman Milanfar, and Ulugbek Kamilov. A restoration network as an implicit prior. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[51]
Fire: Fixed-points of restoration priors for solving inverse problems
Matthieu Terris, Ulugbek S Kamilov, and Thomas Moreau. Fire: Fixed-points of restoration priors for solving inverse problems. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 23185–23194, 2025
work page 2025
-
[52]
Brian DO Anderson. Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326, 1982
work page 1982
-
[53]
Pascal Vincent. A connection between score matching and denoising autoencoders.Neural computation, 23(7):1661–1674, 2011
work page 2011
-
[54]
Stereo Magnification: Learning View Synthesis using Multiplane Images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnifi- cation: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
work page 2018
-
[56]
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004. 13 A Extended Related Work and Positioning This appendix expands Section 5 with a technical positioning of h-control against the four research lines it sits...
work page 2004
-
[57]
provides a generative-modeling perspective on the same problem. The common requirement across this family is that at least one component — backbone, adapter, or refinement head — is fine-tuned to internalize the trajectory-to-video correspondence. Training-free controllers.TTM [ 14] and WorldForge [15] construct a warped guidance video by lifting the sour...
-
[58]
fine-tunes the base model to internalize the same drift.Position of h-control:we extend the global scalar λσt to aspatially non-uniformmask M and pair it with a novel inner refinement on the unobserved support, while keeping the conditioning entirely at inference time — no extra network and no fine-tuning. Sequential Monte Carlo and Feynman–Kac.Twisted Di...
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.