Recognition: 2 theorem links
· Lean TheoremLOFT: Low-Rank Orthogonal Fine-Tuning via Task-Aware Support Selection
Pith reviewed 2026-05-13 06:04 UTC · model grok-4.3
The pith
LOFT unifies orthogonal PEFT by separating subspace choice from the rotation applied inside it and shows task-aware support selection improves the efficiency trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By viewing orthogonal adaptation as a multiplicative subspace rotation, LOFT provides a unified formulation that recovers coordinate-, butterfly-, Householder-, and principal-subspace-based orthogonal PEFT methods. This perspective exposes support selection as a central design axis rather than a byproduct of parameterization. First-order analysis shows that useful adaptation supports should be informed by the downstream training signal, motivating practical task-aware selection strategies that recover principal-subspace performance while improving the efficiency-performance trade-off under matched budgets.
What carries the argument
The low-rank orthogonal fine-tuning framework that separates the choice of adaptation subspace from the orthogonal transformation applied within the chosen subspace, with support selection driven by first-order analysis of the downstream training signal.
If this is right
- Existing orthogonal PEFT methods become instances of a single rotation-based formulation once subspace and transformation are separated.
- Support selection emerges as an independent design axis that can be optimized separately from the choice of orthogonal transformation.
- Gradient-informed supports improve the accuracy-to-parameter ratio across language understanding, visual transfer, mathematical reasoning, and multilingual adaptation.
- Principal-subspace orthogonal adaptation can be recovered while using fewer parameters when supports are chosen from the training signal.
- Further gains in orthogonal PEFT are expected to come from principled support-selection rules rather than new parameterizations.
Where Pith is reading between the lines
- The same separation of subspace and transformation might be applied to non-orthogonal low-rank methods to create hybrid adapters.
- Task-aware support selection could reduce the data needed to reach target accuracy by concentrating updates on directions already aligned with the task.
- Support size might be chosen adaptively per layer or per task rather than fixed globally, potentially improving scaling behavior on larger models.
- The framework offers a route to structure-preserving adapters that respect additional constraints such as sparsity or block structure.
Load-bearing premise
The first-order analysis correctly identifies supports that the downstream gradient signal would prefer and that selecting those supports reliably improves results without introducing new instabilities or overfitting.
What would settle it
A controlled experiment in which supports chosen without reference to the task gradient perform as well as or better than gradient-informed supports on the same benchmarks while keeping parameter count, memory, and compute fixed, or in which task-aware selection produces measurable training instability.
Figures

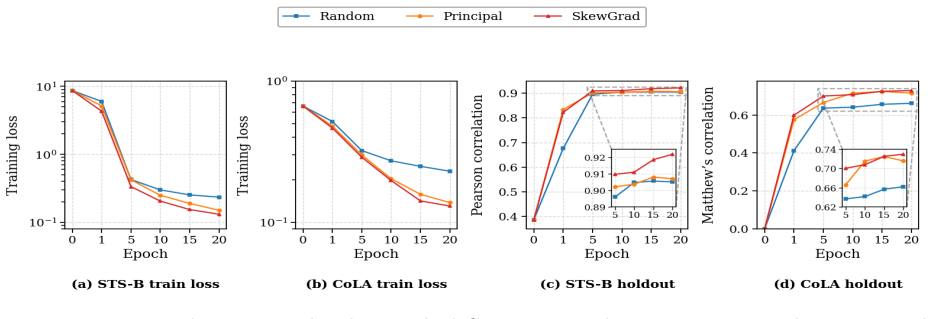



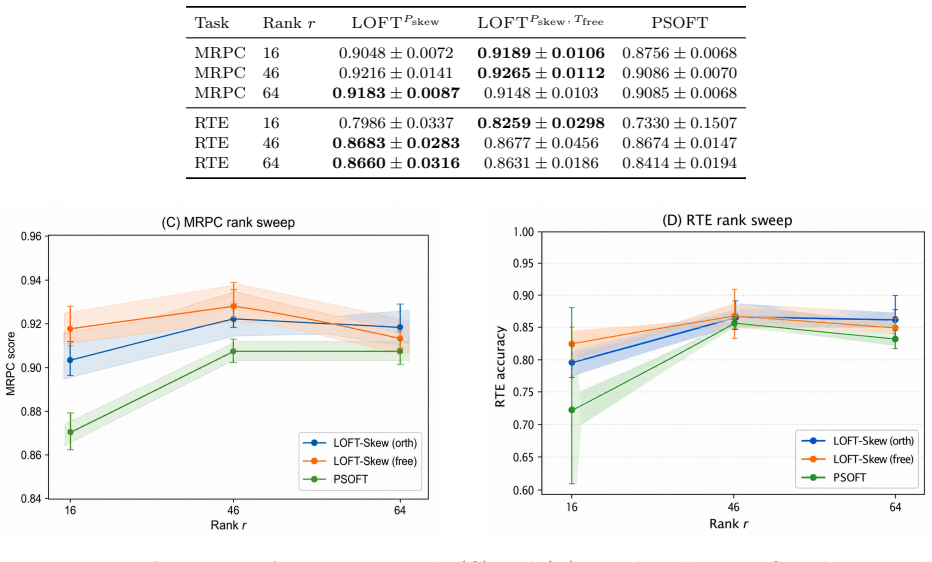
read the original abstract
Orthogonal parameter-efficient fine-tuning (PEFT) adapts pretrained weights through structure-preserving multiplicative transformations, but existing methods often conflate two distinct design choices: the subspace in which adaptation occurs and the transformation applied within that subspace. This paper introduces LOFT, a low-rank orthogonal fine-tuning framework that explicitly separates these two components. By viewing orthogonal adaptation as a multiplicative subspace rotation, LOFT provides a unified formulation that recovers representative orthogonal PEFT methods, including coordinate-, butterfly-, Householder-, and principal-subspace-based variants. More importantly, this perspective exposes support selection as a central design axis rather than a byproduct of a particular parameterization. We develop a first-order analysis showing that useful adaptation supports should be informed by the downstream training signal, motivating practical task-aware support selection strategies. Across language understanding, visual transfer, mathematical reasoning, and multilingual out-of-distribution adaptation, LOFT recovers principal-subspace orthogonal adaptation while gradient-informed supports improve the efficiency-performance trade-off under matched parameter, memory, and compute budgets. These results suggest that principled support selection is an important direction for improving orthogonal PEFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LOFT, a low-rank orthogonal fine-tuning framework that separates the adaptation subspace from the orthogonal transformation within it. It provides a unified formulation recovering coordinate-, butterfly-, Householder-, and principal-subspace orthogonal PEFT methods, develops a first-order analysis arguing that adaptation supports should be chosen using downstream training signals, and proposes task-aware support selection. Experiments across language understanding, visual transfer, mathematical reasoning, and multilingual OOD adaptation report improved efficiency-performance trade-offs under matched parameter, memory, and compute budgets.
Significance. The unification of orthogonal PEFT methods under a multiplicative subspace-rotation view is a clarifying contribution that treats support selection as an explicit design axis. If the first-order analysis is shown to reliably predict the benefits of gradient-informed supports and the empirical gains hold under controlled baselines, the work could shift focus in orthogonal PEFT toward data-dependent subspace choices rather than fixed parameterizations.
major comments (1)
- [First-order analysis section] The first-order Taylor expansion motivating gradient-informed support selection linearizes the loss around the pretrained weights under infinitesimal multiplicative orthogonal updates. The actual LOFT algorithm, however, applies finite low-rank orthogonal factors over multiple optimizer steps on the Stiefel manifold; higher-order curvature and successive rotation composition are not controlled or bounded. This gap means it is unclear whether reported gains trace to the task-aware support choice or to incidental effects of the low-rank orthogonal parameterization itself.
minor comments (2)
- [Abstract] The abstract states that LOFT 'recovers principal-subspace orthogonal adaptation' but does not detail the exact recovery mechanism or the precise baseline implementations used for comparison.
- [Experiments] Data exclusion rules, hyperparameter search ranges, and exact baseline configurations (including how coordinate-, butterfly-, and Householder variants are instantiated) should be stated more explicitly to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address the single major comment below by clarifying the intended role of the first-order analysis and committing to revisions that better isolate the contribution of task-aware support selection.
read point-by-point responses
-
Referee: [First-order analysis section] The first-order Taylor expansion motivating gradient-informed support selection linearizes the loss around the pretrained weights under infinitesimal multiplicative orthogonal updates. The actual LOFT algorithm, however, applies finite low-rank orthogonal factors over multiple optimizer steps on the Stiefel manifold; higher-order curvature and successive rotation composition are not controlled or bounded. This gap means it is unclear whether reported gains trace to the task-aware support choice or to incidental effects of the low-rank orthogonal parameterization itself.
Authors: We thank the referee for identifying this important distinction. The first-order Taylor expansion is presented as a motivational heuristic to argue that supports aligned with the downstream gradient are preferable to fixed or random choices; it is not intended as a rigorous bound that accounts for all higher-order curvature or iterative manifold updates. We agree that the practical LOFT procedure uses finite steps on the Stiefel manifold and that the linearization does not control these effects. In the revised manuscript we have added an explicit limitations paragraph in Section 3.2 stating the scope of the analysis. To directly address whether gains are attributable to task-aware selection rather than the low-rank orthogonal parameterization, we have inserted a controlled ablation that compares gradient-informed supports against random supports under identical LOFT parameterization, optimizer, and budget constraints. The new results show consistent advantages for the task-aware choice, supporting the claim that support selection is the operative factor. These changes clarify the analysis without overstating its theoretical reach. revision: partial
Circularity Check
No significant circularity: unified formulation and first-order analysis are self-contained
full rationale
The paper's core chain reframes orthogonal PEFT by explicitly separating the adaptation subspace from the multiplicative transformation applied inside it. This separation is presented as a modeling choice that recovers prior methods (coordinate, butterfly, Householder, principal-subspace) as special cases; it does not reduce any claimed performance gain to a quantity defined by the same fitted parameters. The first-order Taylor analysis of the loss under infinitesimal orthogonal updates is derived directly from the loss gradient and is used only to motivate why support selection should depend on the downstream signal; it is not invoked to prove the finite-step algorithm's superiority. No self-citations, uniqueness theorems, or ansatzes from prior author work are load-bearing for the central claims. Empirical results are reported under matched budgets and therefore constitute independent validation rather than a re-expression of the analysis inputs. The derivation therefore remains non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Orthogonal adaptation can be viewed as a multiplicative subspace rotation
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearLOFT ... W+ = W0 (I + P⊤r (Tr − Ir) Pr) ... ∇Et eL|Et=0 = Pr skew(W0⊤ G) P⊤r
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclearProposition 1 (Geometry Preservation) ... σi(W+) = σi(W) ∀i
Reference graph
Works this paper leans on
- [1]
-
[2]
arXiv preprint arXiv:2505.12378 , year=
Efficient Optimization with Orthogonality Constraint: a Randomized Riemannian Submanifold Method , author=. arXiv preprint arXiv:2505.12378 , year=
-
[3]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey , author=. arXiv preprint arXiv:2403.14608 , year=
work page internal anchor Pith review arXiv
- [4]
-
[5]
Hu, E. J. and Shen, Y. and Wallis, P. and Allen-Zhu, Z. and Li, Y. and Wang, S. and Wang, L. and Chen, W. , journal=. 2021 , doi=
work page 2021
-
[6]
and Blankevoort, Tijmen and Asano, Yuki M
Kopiczko, Dawid J. and Blankevoort, Tijmen and Asano, Yuki M. , booktitle=. 2024 , url=
work page 2024
-
[7]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , booktitle=. 2024 , url=
work page 2024
-
[8]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Orthogonal over-parameterized training , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[9]
The Twelfth International Conference on Learning Representations , year=
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization , author=. The Twelfth International Conference on Learning Representations , year=
-
[10]
Liu, Junkang and Shang, Fanhua and Zhou, Junchao and Liu, Hongying and Liu, Yuanyuan and Liu, Jin , journal=
-
[11]
Proceedings of the 41st International Conference on Machine Learning , series=
Parameter Efficient Quasi-Orthogonal Fine-Tuning via Givens Rotation , author=. Proceedings of the 41st International Conference on Machine Learning , series=. 2024 , publisher=
work page 2024
- [12]
-
[13]
Moreno Arcas, A. and Sanchis, A. and Civera, J. and Juan, A. , journal=. 2025 , doi=
work page 2025
-
[14]
Advances in Neural Information Processing Systems , volume=
Controlling text-to-image diffusion by orthogonal finetuning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2506.19847 , year=
Qiu, Zeju and Liu, Weiyang and Weller, Adrian and Sch. arXiv preprint arXiv:2506.19847 , year=
-
[16]
Artificial intelligence , year=
-
[17]
Tastan, Nurbek and Laskaridis, Stefanos and Takac, Martin and Nandakumar, Karthik and Horvath, Samuel , booktitle=. 2026 , url=
work page 2026
-
[18]
Wang, A. and Singh, A. and Michael, J. and Hill, F. and Levy, O. and Bowman, S. R. , journal=. 2018 , doi=
work page 2018
-
[19]
International Conference on Learning Representations , year=
Efficient Orthogonal Fine-Tuning with Principal Subspace Adaptation , author=. International Conference on Learning Representations , year=
-
[20]
Bridging the gap between low-rank and orthogonal adaptation via
Yuan, Shen and Liu, Haotian and Xu, Hongteng , journal=. Bridging the gap between low-rank and orthogonal adaptation via
-
[21]
Advances in Neural Information Processing Systems , year=
Spectral Adapter: Fine-Tuning in Spectral Space , author=. Advances in Neural Information Processing Systems , year=
-
[22]
A Large-Scale Study of Representation Learning with the Visual Task Adaptation Benchmark , author=. arXiv preprint arXiv:1910.04867 , year=
-
[23]
International Conference on Learning Representations , year=
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. International Conference on Learning Representations , year=
-
[24]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Measuring Mathematical Problem Solving With the
Hendrycks, Dan and Burns, Collin and Kadavath, Saurav and Arora, Akul and Basart, Steven and Tang, Eric and Song, Dawn and Steinhardt, Jacob , journal=. Measuring Mathematical Problem Solving With the. 2021 , doi=
work page 2021
-
[26]
and Li, Zhenguo and Weller, Adrian and Liu, Weiyang , booktitle=
Yu, Longhui and Jiang, Weisen and Shi, Han and Yu, Jincheng and Liu, Zhengying and Zhang, Yu and Kwok, James T. and Li, Zhenguo and Weller, Adrian and Liu, Weiyang , booktitle=. 2024 , url=
work page 2024
-
[27]
2024 , howpublished=
work page 2024
-
[28]
Ben Zaken, Elad and Goldberg, Yoav and Ravfogel, Shauli , booktitle =. 2022 , publisher =. doi:10.18653/v1/2022.acl-short.1 , url =
-
[29]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =. 2021 , publisher =. doi:10.18653/v1/2021.acl-long.353 , url =
-
[30]
doi: 10.18653/v1/2021.emnlp-main.243
The Power of Scale for Parameter-Efficient Prompt Tuning , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , publisher =. doi:10.18653/v1/2021.emnlp-main.243 , url =
-
[31]
Advances in Neural Information Processing Systems , volume =
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning , author =. Advances in Neural Information Processing Systems , volume =. 2022 , url =
work page 2022
-
[32]
Karimi Mahabadi, Rabeeh and Henderson, James and Ruder, Sebastian , booktitle =. 2021 , url =
work page 2021
-
[33]
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , booktitle =. 2023 , url =
work page 2023
-
[34]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =. 2023 , url =
work page 2023
-
[35]
Valipour, Mojtaba and Rezagholizadeh, Mehdi and Kobyzev, Ivan and Ghodsi, Ali , journal =. 2022 , url =
work page 2022
-
[36]
International Conference on Learning Representations , year=
Measuring the Intrinsic Dimension of Objective Landscapes , author=. International Conference on Learning Representations , year=
-
[37]
Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing , pages=. 2021 , publisher=
work page 2021
-
[38]
Lingam, Vijay Chandra and Tejaswi, Atula and Vavre, Aditya and Shetty, Aneesh and Gudur, Gautham Krishna and Ghosh, Joydeep and Dimakis, Alex and Choi, Eunsol and Bojchevski, Aleksandar and Sanghavi, Sujay , booktitle=
-
[39]
International Conference on Machine Learning , pages=
A kernel-based view of language model fine-tuning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[40]
International Conference on Machine Learning , pages=
LoRA Training in the NTK Regime has No Spurious Local Minima , author=. International Conference on Machine Learning , pages=. 2024 , organization=
work page 2024
-
[41]
Advances in Neural Information Processing Systems , volume=
Neural tangent kernel: Convergence and generalization in neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
A spectral condition for feature learning
A Spectral Condition for Feature Learning , author =. arXiv preprint arXiv:2310.17813 , year =
-
[43]
Zhao, Jiawei and Zhang, Zhenyu and Chen, Beidi and Wang, Zhangyang and Anandkumar, Anima and Tian, Yuandong , booktitle=. 2024 , organization=
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.